") FAIR和谷歌大腦的合作研究,專(zhuān)注于“反向翻譯”方法
FAIR和谷歌大腦的合作研究,專(zhuān)注于“反向翻譯”方法
FAIR和谷歌大腦的合作研究,專(zhuān)注于“反向翻譯”方法,用上億合成單語(yǔ)句子訓(xùn)練NMT模型,在WMT’14 英語(yǔ)-德語(yǔ)測(cè)試集上達(dá)到35 BLEU的最優(yōu)性能。論文在EMNLP 2018發(fā)表。
機(jī)器翻譯依賴于大型平行語(yǔ)料庫(kù),即源語(yǔ)和目的語(yǔ)中成對(duì)句子的數(shù)據(jù)集。但是,雙語(yǔ)語(yǔ)料是十分有限的,而單語(yǔ)語(yǔ)料更容易獲得。傳統(tǒng)上,單語(yǔ)語(yǔ)料被用于訓(xùn)練語(yǔ)言模型,大大提高了統(tǒng)計(jì)機(jī)器翻譯的流暢性。
進(jìn)展到神經(jīng)機(jī)器翻譯(NMT)的背景下,已經(jīng)有大量的工作研究如何改進(jìn)單語(yǔ)模型,包括語(yǔ)言模型融合、反向翻譯(back-translation/回譯)和對(duì)偶學(xué)習(xí)(dual learning)。這些方法具有不同的優(yōu)點(diǎn),結(jié)合起來(lái)能夠達(dá)到較高的精度。
Facebook AI Research和谷歌大腦的發(fā)表的新論文Understanding Back-Translation at Scale是這個(gè)問(wèn)題的最新成果。這篇論文專(zhuān)注于反向翻譯(BT),在半監(jiān)督設(shè)置中運(yùn)行,其中目標(biāo)語(yǔ)言的雙語(yǔ)和單語(yǔ)數(shù)據(jù)都是可用的。
反向翻譯首先在并行數(shù)據(jù)上訓(xùn)練一個(gè)中間系統(tǒng),該系統(tǒng)用于將目標(biāo)單語(yǔ)數(shù)據(jù)轉(zhuǎn)換為源語(yǔ)言。其結(jié)果是一個(gè)平行的語(yǔ)料庫(kù),其中源語(yǔ)料是合成的機(jī)器翻譯輸出,而目標(biāo)語(yǔ)料是人類(lèi)編寫(xiě)的真實(shí)文本。
然后,將合成的平行語(yǔ)料添加到真實(shí)的雙語(yǔ)語(yǔ)料(bitext)中,以訓(xùn)練將源語(yǔ)言轉(zhuǎn)換為目標(biāo)語(yǔ)言的最終系統(tǒng)。
雖然這種方法很簡(jiǎn)單,但已被證明對(duì)基于短語(yǔ)的翻譯、NMT和無(wú)監(jiān)督MT很有效。
具體到這篇論文,研究人員通過(guò)向雙語(yǔ)語(yǔ)料中添加了數(shù)億個(gè)反向翻譯得到的句子,對(duì)神經(jīng)機(jī)器翻譯的反向翻譯進(jìn)行了大規(guī)模的研究。
實(shí)驗(yàn)基于在WMT競(jìng)賽的公共雙語(yǔ)語(yǔ)料上訓(xùn)練的強(qiáng)大基線模型。該研究擴(kuò)展了之前的研究(Sennrich et al. , 2016a ; Poncelas et al. , 2018) 對(duì)反譯法的分析,對(duì)生成合成源句的不同方法進(jìn)行了全面的分析,并證明這種選擇很重要:從模型分布中采樣或噪聲beam輸出優(yōu)于單純的beam search,在幾個(gè)測(cè)試集中平均 BLEU高1.7。
作者的分析表明,基于采樣或noised beam search的合成數(shù)據(jù)比基于argmax inference的合成數(shù)據(jù)提供了更強(qiáng)的訓(xùn)練信號(hào)。
文章還研究了受控設(shè)置中添加合成數(shù)據(jù)和添加真實(shí)雙語(yǔ)數(shù)據(jù)的比較,令人驚訝的是,結(jié)果顯示合成數(shù)據(jù)有時(shí)能得到與真實(shí)雙語(yǔ)數(shù)據(jù)不相上下的準(zhǔn)確性。
實(shí)驗(yàn)中,最好的設(shè)置是在WMT ’14 英語(yǔ)-德語(yǔ)測(cè)試集上,達(dá)到了35 BLEU,訓(xùn)練數(shù)據(jù)只使用了WMT雙語(yǔ)語(yǔ)料庫(kù)和2.26億個(gè)合成的單語(yǔ)句子。這比在大型優(yōu)質(zhì)數(shù)據(jù)集上訓(xùn)練的DeepL系統(tǒng)的性能更好,提高了1.7 BLEU。在WMT ‘14英語(yǔ)-法語(yǔ)測(cè)試集上,我們的系統(tǒng)達(dá)到了45.6 BLEU。
合成源語(yǔ)句子
反向翻譯通常使用beam search或greed search來(lái)生成合成源句子。這兩種算法都是識(shí)別最大后驗(yàn)估計(jì)(MAP)輸出的近似算法,即在給定輸入條件下,估計(jì)概率最大的句子。Beam search通常能成功地找到高概率的輸出。
然而,MAP預(yù)測(cè)可能導(dǎo)致翻譯不夠豐富,因?yàn)樗偸莾A向于在模棱兩可的情況下選擇最有可能的選項(xiàng)。這在具有高度不確定性的任務(wù)中尤其成問(wèn)題,例如對(duì)話和說(shuō)故事。我們認(rèn)為這對(duì)于數(shù)據(jù)增強(qiáng)方案(如反向翻譯)來(lái)說(shuō)也是有問(wèn)題的。
Beam search和greed search都集中在模型分布的頭部,這會(huì)導(dǎo)致非常規(guī)則的合成源句子,不能正確地覆蓋真正的數(shù)據(jù)分布。
作為替代方法,我們考慮從模型分布中采樣,并向beam search輸出添加噪聲。
具體而言,我們用三種類(lèi)型的噪音來(lái)轉(zhuǎn)換源句子:以0.1的概率刪除單詞,以0.1的概率用填充符號(hào)代替單詞,以及交換在token上隨機(jī)排列的單詞。
模型和實(shí)驗(yàn)結(jié)果
我們使用fairseq工具包在pytorch中重新實(shí)現(xiàn)了Transformer 模型。所有的實(shí)驗(yàn)都是基于Big Transformer 架構(gòu),它的編碼器和解碼器都有6個(gè)block。所有實(shí)驗(yàn)都使用相同的超參數(shù)。
實(shí)驗(yàn)結(jié)果:不同反向翻譯生成方法的準(zhǔn)確性比較
實(shí)驗(yàn)評(píng)估首先比較了反向翻譯生成方法的準(zhǔn)確性,并分析了結(jié)果。

圖1:在不同數(shù)量的反向翻譯數(shù)據(jù)上訓(xùn)練的模型的準(zhǔn)確性,這些數(shù)據(jù)分別通過(guò)greedy search、beam search (k = 5)和隨機(jī)采樣得到。
如圖1所示,sampling和beam+noise方法優(yōu)于MAP方法,BLEU要高0.8-1.1。在數(shù)據(jù)量最大的設(shè)置下,sampling和beam+noise方法比bitext-only (5M)要好1.7-2 BLEU。受限采樣(top10)的性能優(yōu)于beam 和 greedy,但不如非受限抽樣(sampling)或beam+noise。

圖2:對(duì)于不同的合成數(shù)據(jù),每個(gè)epoch的Training perplexity (PPL)。
圖2顯示,基于greedy或beam的合成數(shù)據(jù)與來(lái)自采樣、top10、 beam+noise和bitext的數(shù)據(jù)相比更容易擬合。
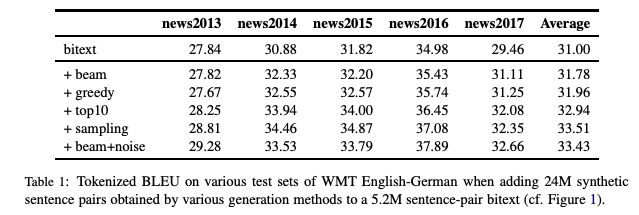
表1
表1展示了更廣泛的測(cè)試集的結(jié)果(newstest2013-2017)。 Sampling和beam+noise 的表現(xiàn)大致相同,其余實(shí)驗(yàn)采用sampling。
資源少 vs 資源多設(shè)置
接下來(lái),我們模擬了一個(gè)資源缺乏的設(shè)置,以進(jìn)一步嘗試不同的生成方法。

圖3:在80K、640K和5M句子對(duì)的bitext系統(tǒng)中添加來(lái)自beam search和sampling的合成數(shù)據(jù)時(shí),BLEU的變化
圖3顯示,對(duì)于數(shù)據(jù)量較大的設(shè)置(640K和5.2M bitext),sampling比beam更有效,而對(duì)于資源少的設(shè)置(80K bitext)則相反。
大規(guī)模的結(jié)果
最后,我們擴(kuò)展到非常大的設(shè)置,使用多達(dá)226M的單語(yǔ)句子,并且與先前的研究進(jìn)行了比較。
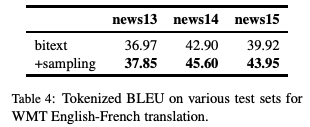
表4:WMT英語(yǔ)-法語(yǔ)翻譯任務(wù)中,不同測(cè)試集上的Tokenized BLEU
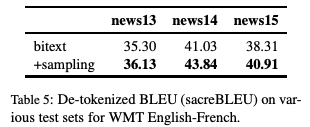
表5:WMT英語(yǔ)-法語(yǔ)翻譯任務(wù)中,不同測(cè)試集上的De-tokenized BLEU (sacreBLEU)

表6:WMT 英語(yǔ)-德語(yǔ) (En-De)和英語(yǔ)-法語(yǔ) (En-Fr)在newstest2014上的BLEU。
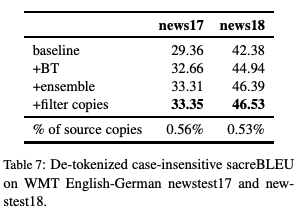
表7:WMT英語(yǔ)-德語(yǔ)newstest17和newstest18上的非標(biāo)記、不區(qū)分大小寫(xiě)的sacreBLEU。
結(jié)論
反向翻譯是一種非常有效的神經(jīng)機(jī)器翻譯數(shù)據(jù)增強(qiáng)技術(shù)。通過(guò)采樣或在beam輸出中添加噪聲來(lái)生成合成源句子,比通常使用的argmax inference 具有更高的精度。
特別是,在newstest2013-2017的WMT英德翻譯中,采樣和加入噪聲的beam比單純beam的平均表現(xiàn)好1.7 BLEU。這兩種方法都為資源缺乏的設(shè)置提供了更豐富的訓(xùn)練信號(hào)。
此外,這一研究還發(fā)現(xiàn),合成數(shù)據(jù)訓(xùn)練的模型可以達(dá)到真實(shí)雙語(yǔ)語(yǔ)料訓(xùn)練模型性能的83%。
最后,我們只使用公開(kāi)的基準(zhǔn)數(shù)據(jù),在WMT ‘14英語(yǔ)-德語(yǔ)測(cè)試集上實(shí)現(xiàn)了35 BLEU的新的最優(yōu)水平。
-
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14903 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24725
原文標(biāo)題:NLP重磅!谷歌、Facebook新研究:2.26億合成數(shù)據(jù)訓(xùn)練神經(jīng)機(jī)器翻譯創(chuàng)最優(yōu)!
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
電路反向研究。。
人類(lèi)首創(chuàng)能生成神經(jīng)細(xì)胞的“迷你大腦”,更精確模擬神經(jīng)網(wǎng)絡(luò)!
程序員的大腦有什么不同?
基于淺層句法信息的翻譯實(shí)例獲取方法研究
神奇大腦信號(hào)翻譯器 可將思想變語(yǔ)言
美國(guó)研制出大腦思維翻譯器欲將思想變語(yǔ)言
谷歌翻譯對(duì)比有道翻譯東北話,高下立見(jiàn)!
谷歌翻譯竟然預(yù)言世界末日?

谷歌翻譯加入離線AI翻譯功能,離線也能翻譯而且更準(zhǔn)確
DARPA專(zhuān)注于無(wú)需手術(shù)的神經(jīng)技術(shù)研究,讓身體健全的士兵擁有超能力技術(shù)
小扎邀請(qǐng)LeCun:FAIR誕生,與谷歌爭(zhēng)人才
谷歌大腦開(kāi)發(fā)人類(lèi)翻譯器 打破AI黑盒新方式
谷歌宣布Android Things轉(zhuǎn)為專(zhuān)注于智能音箱的平臺(tái)
谷歌希望為現(xiàn)實(shí)世界帶來(lái)更多機(jī)器人 專(zhuān)注于更簡(jiǎn)單的自動(dòng)化工作
手語(yǔ)識(shí)別、翻譯及生成研究綜述






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論