 DeepMind終于公開了它聯合UCL的“高級深度強化學習課程”!
DeepMind終于公開了它聯合UCL的“高級深度強化學習課程”!
一直走在深度學習研究最前沿的DeepMind,終于公開了它聯合UCL的“高級深度強化學習課程”!18節課24小時,一天看完Deep RL及其2018最新進展。
今天,DeepMind 官推貼出一則告示,將 DeepMind 研究人員今年在 UCL 教授的深度強化學習課程“Advanced Deep Learning and Reinforcement Learning” 資源全部公開。
一共18節課,走過路過不能錯過。
深度強化學習是人工智能領域的一個新的研究熱點,從AlphaGo開始,DeepMind便在這一領域獨占鰲頭。
深度強化學習以一種通用的形式將深度學習的感知能力與強化學習的決策能力相結合,并能夠通過端對端的學習方式實現從原始輸入到輸出的直接控制。自提出以來, 在許多需要感知高維度原始輸入數據和決策控制的任務中都取得了實質性的突破。
2018年,南京大學的AI單機訓練一天,擊敗《星際爭霸》最高難度內置Bot,OpenAI 打 DOTA2 超越了Top 1%的人類玩家,深度強化學習不斷在進展。
結合算法的發展和實際應用場景,DeepMind在UCL教授的這門課程內容也是最前沿的。
還有關鍵一點,那就是視頻的質量和清晰度超贊啊(需要科學上網)。
DeepMind親授“高級深度強化學習課程”
這門課程是DeepMind與倫敦大學學院(UCL)的合作項目,由于DeepMind的研究人員去UCL授課,內容由兩部分組成,一是深度學習(利用深度神經網絡進行機器學習),二是強化學習(利用強化學習進行預測和控制),最后兩條線結合在一起,也就成了DeepMind的拿手好戲——深度強化學習。
關于深度強化學習,DeepMind一直在努力,比如最新發表的研究讓 AI 行動符合人類意圖。
這門課也是結合案例講解的,值得一提,最后一課“第18節:深度強化學習的經典案例”,講師是 David Silver,這位AlphaGo背后的英雄以及AlphaZero靈魂人物,他講的課程無論如何也應該聽一聽。
David Silver在UCL講課的視頻截圖
在深度學習部分,課程簡要介紹了神經網絡和使用TensorFlow的監督學習,然后講授卷積神經網絡、遞歸神經網絡、端到端并基于能量的學習、優化方法、無監督學習以及注意力和記憶。討論的應用領域包括對象識別和自然語言處理。
強化學習部分將涵蓋馬爾科夫決策過程、動態規劃、無模型預測和控制、價值函數逼近、策略梯度方法、學習與規劃的集成以及探索/開發困境。討論的可能應用包括學習玩經典的棋盤游戲和電子游戲。
總體來說,這是一門偏向實踐的課程,需要PyTorch和編碼基礎,學完以后,學生能夠在TensorFlow上熟練實現深度學習、強化學習以及深度強化學習相關的一系列算法。
因此,除了深度學習、強化學習和深度強化學習的基礎知識,深度神經網絡的訓練以及優化方法,這門課更加注重如何在TensorFlow中實現深度學習算法,以及如何在復雜動態環境中應用強化學習。
18節課一共24小時,一天看完深度強化學習進展
課程團隊
深度學習1:介紹基于機器學習的AI
深度學習2:介紹TensorFlow
深度學習3:神經網絡基礎
強化學習1:強化學習簡介
強化學習2:開發和利用
強化學習3:馬爾科夫決策過程和動態編程
強化學習4:無模型的預測和控制
深度學習4:圖像識別、端到端學習和Embeddings之外
強化學習5:函數逼近和深度強化學習
深度學習5:機器學習的優化方法
強化學習7:規劃和模型
深度學習6:NLP的深度學習
強化學習8:深度強化學習中的高級話題
深度學習7:深度學習中的注意力和記憶
強化學習9:深度RL智能體簡史
深度學習8:無監督學習和生成式模型
強化學習10:經典游戲的案例學習
18節課一共24小時,一天看完高級深度強化學習
下面我們介紹第14節“深度強化學習中的高級話題”。講課人是DeepMind研究科學家Hado Van Hasselt。Hado Van Hasselt的研究興趣包括人工智能、機器學習、深度學習,尤其是強化學習。加入DeepMind之前,他在阿爾伯塔大學與Richard Sutton教授合作過。
Hado Van Hasselt是許多前沿論文的共同作者,包括Double Q-learning、DuelingDQN、rainbow DQN、強化學習的Ensemble算法等。
在這一節,Hasselt講了深度強化學習中一些積極的研究主題,這些主題很好地突出了這一領域中正在取得的進展。

前面已經介紹過的強化學習研究主題包括:學習在bandit問題中做決策;序列決策問題;model-free的預測和控制;deep RL中的函數逼近;策略梯度和actor-critic方法;以及從模型中學習。

而高級話題,是這些。
最主要的問題是:如何將未來的獎勵最大化?
這個大問題可以分解成一些子問題:
學習什么?(預測、模型、策略……)
如何學習這些?(TD、規劃……)
如何表示這些學習到的知識?(深度網絡、sample buffers,……)
如何利用這些學習到的知識?
其中一些活躍研究主題包括:
在完全序列,函數逼近設置中的“探索”(Exploration)
利用延遲獎勵的credit assignment
局部規劃或不精確的模型
樣本效率模型
Appropriate generalization
構建有用、通用且信息豐富的agent state

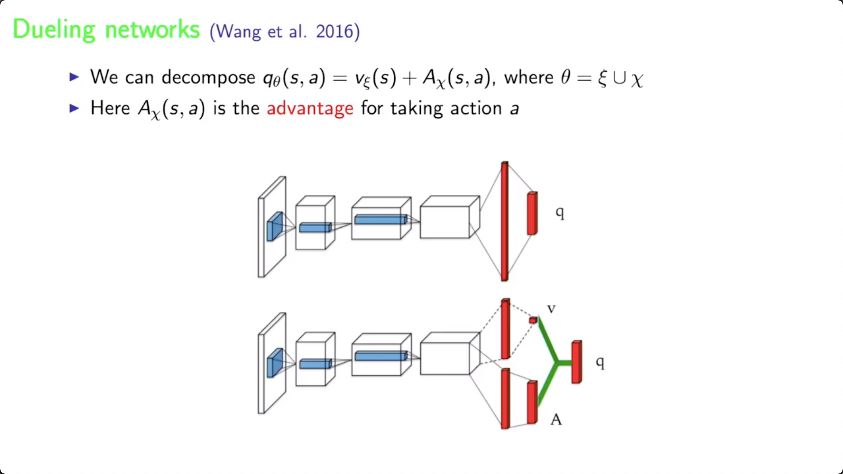
Case study:rainbow DQN(Hasselt et al. 2018)
在這個研究中,Hasselt等人提出rainbow DQN,整合了DQN算法的6種變體,并證明它們很大程度上是互補。DQN的基本想法是利用target networks和experience replay。
這節課接下來的大部分內容圍繞這個case,介紹了最新的技術和思想,請觀看視頻獲得更詳細的解釋。




理解了分布(distribution),或許能對任務有所幫助。這是分布式強化學習的想法。分布式強化學習也意味著representation(例如深度神經網絡)被迫要學習更多。
這可以加快學習:因為學習更多意味著更少的樣本。
以下是分布式強化學習的具體案例。








-
神經網絡
+關注
關注
42文章
4771瀏覽量
100773 -
強化學習
+關注
關注
4文章
266瀏覽量
11256 -
DeepMind
+關注
關注
0文章
130瀏覽量
10865
原文標題:DeepMind高贊課程:24小時看完深度強化學習最新進展(視頻)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
NPU在深度學習中的應用
如何使用 PyTorch 進行強化學習
AI大模型與深度學習的關系
谷歌AlphaChip強化學習工具發布,聯發科天璣芯片率先采用
Python在AI中的應用實例
深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
深度學習模型訓練過程詳解
通過強化學習策略進行特征選擇

深度解析深度學習下的語義SLAM

FPGA在深度學習應用中或將取代GPU
為什么深度學習的效果更好?





 工商網監
工商網監
評論