 使用Google TPU v3 Pod訓練ResNet-50,在識別率沒有降低的情況下2分鐘搞定ImageNet訓練
使用Google TPU v3 Pod訓練ResNet-50,在識別率沒有降低的情況下2分鐘搞定ImageNet訓練
隨著技術、算力的發展,在 ImageNet 上訓練 ResNet-50 的速度被不斷刷新。2018 年 7 月,騰訊機智機器學習平臺團隊在 ImageNet 數據集上僅用 6.6 分鐘就訓練好 ResNet-50,創造了 AI 訓練世界紀錄;一周前,壕無人性的索尼用 2176 塊 V100 GPU 將這一紀錄縮短到了 224 秒;如今,這一紀錄再次被谷歌刷新……
深度學習非常依賴于硬件條件,它是一個計算密集型的任務。硬件供應商通過在大型計算集群中部署更快的加速器來做出更快的相應。在 petaFLOPS(運算能力單位,每秒千萬億次浮點數運算)規模的設備上訓練深度學習模型需要同時面臨算法和系統軟件兩方面的挑戰。Google 于近日推出了一種大規模計算集群的圖像分類人物訓練解決方案,相關論文發表于 Arxiv:Image Classification at Supercomputer Scale。本文的作者使用 Google TPU v3 Pod 訓練 ResNet-50,在識別率沒有降低的情況下,僅使用了 2.2 分鐘。
背景
深度神經網絡的成功應用與發展離不開瘋狂增長的算力,在許多領域,深度學習的發展可以說是由硬件驅動的。在深度網絡的訓練過程中,最關鍵的部分就是使用隨機梯度下降算法(SGD)優化網絡權重。通常情況下,模型需要使用 SGD 在一個數據集上進行多次的便利才能達到收斂。在整個過程中,浮點數運算能力顯得至關重要。例如,在 ImageNet 數據庫上訓練 ResNet-50 模型,遍歷一次數據庫需要 3.2 萬萬億次浮點數運算。而使模型達到收斂,通常需要遍歷 90 次數據庫。
盡管硬件加速設備(例如 GPU、TPU)已經加快了迭代的次數,使用單個加速設備在大規模數據庫訓練大型的神經網絡仍然需要幾個小時或數天的時間。最常見的加速方法便是通過分布式的 SGD 算法使用多個設備并行訓練,將每個 mini-batch 分布在多個相同的加速設備上。
以往大家都喜歡用異步分布式 SGD 算法在將多個線程聯合起來進行訓練,但是近期的一些工作發現,異步分布式 SGD 算法優化的模型在收斂程度和驗證準確率方面都不如同步分布式 SGD 訓練出的模型。但是,為了保證在提速的同時模型的質量不會有所損失,在使用同步分布式 SGD 算法的過程中,會遇到很多技術和硬件方面的瓶頸,作者總結出以下幾點:
模型的準確率依賴于全局的 batch size 和計算集群中每個節點的 batch size。
在加速設備計算能力足夠高時,CPU 向 GPU 等專用設備的輸入過程成為了訓練過程中的瓶頸。
使用同步分布式 SGD 算法需要大規模的高速并行通信方案,即如何解決一個計算集群內部各個節點之間通信速度的瓶頸。
本文的作者提出了一種同步的分布式 SGD 優化算法,同時還提出了幾個大規模分布式深度學習訓練過程中使用的機器學習方法和優化方法,在加速收斂的過程中保證模型的質量沒有損失。
圖:左圖為 4-chip 的云 TPU v2 設備,峰值計算能力為 180 teraFLOPS(每秒萬億次浮點運算),使用 64GB 的 HBM(高帶寬內存);右圖為使用水冷的 4-chip 云 TPU v3 設備,峰值計算能力為 420 teraFLOPS,使用 128GBHBM。TPU v2 設備可組成最高 256-chip 的計算集群,稱為 TPU Pod,可提供高達 11.5petaFLOPS 的混合精度吞吐量。TPU v3 Pod 的規模可達 1024-chip,是 TPU v2 Pod 的四倍,理論上可提供 107.5 petaFLOPS 的混合精度吞吐量
方法
本文的作者受之前大規模訓練方法的啟發,在實驗過程中使用了以下一些技術:
混合精度:在實驗過程中,卷積操作使用了 bfloat16 數據,這是一種 TPU 上的半精度 16 位浮點數。此外,卷積層之間的激活函數也使用了 bfloat16 的格式。為了保證計算精度與 32 位浮點數網絡不相上下的精度,對于所有的非卷積的操作(例如,批歸一化、損失函數計算、梯度求和)都使用了 32 位浮點數。由于網絡訓練過程中的主要計算和內存消耗都是在卷積操作上,因此使用 bfloat16 可以獲得更高的訓練吞吐量。
學習率配置: 先前的一些研究表明,學習率應當與 batch size 成比例。在實驗過程中,作者使用了線性變化的學習率策略進行配置(例如,batch size 設成兩倍,則學習率也設為兩倍)。同時作者也使用了平緩的學習率預熱(warm-up)方法和學習率衰減。
分層自適應速率縮放(LARS): 盡管使用動量(momentum)的隨機梯度下降算法已經可以將 batch 最高設為 8192,但使用 LARS 優化器可以達到 32786 的 batch size 并且對于模型質量沒有影響。更大的 batch size 也增加了模型在 TPU 集群上執行時的吞吐量。
分布式批歸一化
批歸一化在圖像分類任務中有著不可或缺的作用,它通過對一個 mini-batch 內的數據進行歸一化,使得經過 batch-norm 層的數據服從相同均值與方差的分布,使得下層神經元可以更好的對數據分布情況進行學習。
在分布式訓練過程中,通常讓每個計算節點獨立的進行 batch norm, 這樣的好處是可以大大縮短訓練時間,因為每個計算節點之間無需額外的通信過程。在實驗過程中,作者發現 BN 的批大小(例如計算節點的批大小)對模型的驗證準確率有重要影響。已經有研究證明在計算節點的批大小小于 32 時,ResNet-50 的最終訓練結果在驗證數據上的準確率并不能收斂。
當使用數據并行的方法在大規模計算機集群上進行部署時,需要同時對全局的 batch size 大小進行擴大,同時對每個節點的局部 batch size 進行縮小。考慮到 BN 層的影響,作者主要針對每個節點上的 batch size 較小的情況進行研究。
作者通過對幾個計算節點組成的子節點做分布式的批歸一化來實現對 BN 這一過程的增強。具體算法如圖所示:

圖:分布式批歸一化算法示意圖,圖中集群包含兩個計算節點
首先各個節點計算獨立的局部均值與方差
計算一個子集群(圖中子集群包含兩個計算節點的)中的分布式均值和方差。
使用分布式均值和方差對子集群中的所有節點進行歸一化
輸入管道優化
訓練模型過程中,輸入管道包括了數據讀取、數據分析、預處理、旋轉和批量化等操作。如果輸入管道的吞吐量不能和 TPU 等模型管道(前向或反向傳播過程)的吞吐量相匹配,整個過程將會由于輸入管道的問題產生吞吐量上的瓶頸。導致輸入管道與模型管道吞吐量差異的主要原因是專用硬件加速設備與 CPU 之間的性能差異,因為模型管道是完全在專用硬件加速設備上執行的。
在本文中, 作者使用了很多關鍵的優化方法來解決輸入管道導致的瓶頸。此前,還未有工作對這些技術進行整合。具體方法如下:
數據共享與緩存: 理想情況下,所有的數據會一次性讀取并緩存在內存中以備直接使用,但是對于真實情況中的大規模數據集這種做法往往是不可行的。由于計算集群之間是可以共享內存與數據的,因此在大規模計算集群中,作者使用這種數據集共享與緩存的方法來提高輸入管道的吞吐量。
預提取并計算: 在計算當前批的數據同時對下一批的數據進行提取和處理,當前批計算完時便可直接提取數據使用。
混合 JPEG 解碼與裁剪: 使用原始的編碼數據進行數據增強等操作然后只對有效的部分進行解碼
并行數據分析: 對于輸入管道來說,數據分析與處理是非常消耗算力的,多核 CPU 可以使用多線程進行加速。
二維梯度求和
本文的作者提出了一種二維梯度求和方法,用于多個計算節點之間的梯度的計算和傳播。在傳統的一維方法中,梯度求和這一步的時間復雜度是 O(n^2),使用二維求和后,時間復雜度可以降到 O(n)。具體計算方法如下圖所示。
圖:二維環形梯度傳播,第一階段,藍色張量在 Y 軸方向進行求和,紅色張量在 X 軸方向進行求和。第二階段,維度進行轉換再次求和。
實驗與分析
作者進行了多個實驗,對文中提到的幾個技術細節進行論證。
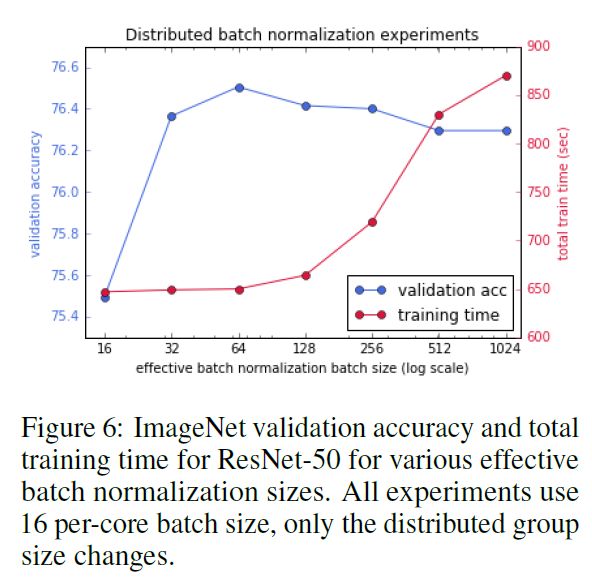
分布式批歸一化
分布式歸一化的結果如下圖所示,實驗使用了 TPU v2 Pod 進行訓練,并且沒有使用 LARS 優化。
輸入管道優化
左圖是逐漸增加每種優化方法的實驗結果,中間的圖是組合優化的結果與逐漸減少其他優化方法的結果對比,右圖是并行化數量對實驗結果的影響。所有的實驗結果都以數據吞吐量為指標。

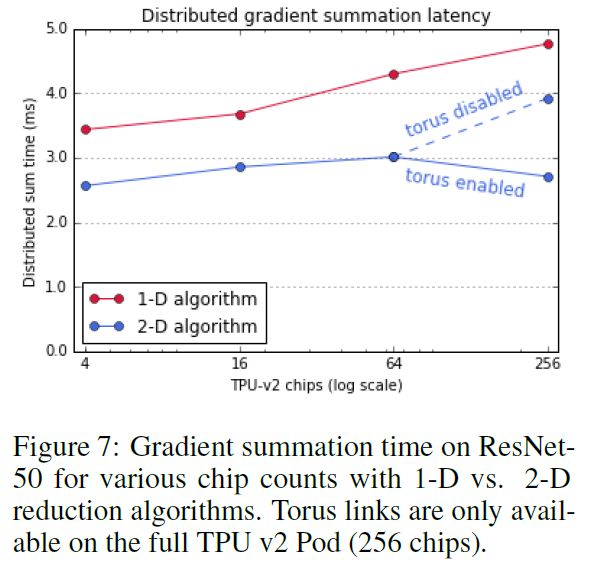
二維梯度求和
下圖是二維梯度求和算法與一維梯度求和算法的比較,可見使用二維梯度求和在各個配置的情況下都可以有效的減少分布式求和的時間。
與已有最好方法的對比
最后,作者與目前最好的分布式計算方法進行了比較,在準確率相同的情況下,本文提出的方法相比之前的方法大大減少了時間消耗。

目前谷歌云已經上線 Cloud TPU v3 測試版,單臺設備價格每小時 2.4 美元到 8 美元,也不是很貴,你也可以動手試試看哦~
-
谷歌
+關注
關注
27文章
6176瀏覽量
105677 -
數據分析
+關注
關注
2文章
1455瀏覽量
34090 -
深度學習
+關注
關注
73文章
5510瀏覽量
121337
原文標題:谷歌刷新世界紀錄!2分鐘搞定 ImageNet 訓練
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大模型訓練框架(五)之Accelerate
采用FP8混合精度,DeepSeek V3訓練成本僅557.6萬美元!
在VDD1沒有供電的情況下,VDD2正常供電的情況下,AMC1200的輸出應該是什么狀態?
基于改進ResNet50網絡的自動駕駛場景天氣識別算法






 工商網監
工商網監
評論