") 這款名為Seq2Seq-Vis的工具能將人工智能的翻譯過程進(jìn)行可視化
這款名為Seq2Seq-Vis的工具能將人工智能的翻譯過程進(jìn)行可視化
近年來隨著深度學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)技術(shù)的發(fā)展,機(jī)器翻譯也取得了長足的進(jìn)步。神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)越來越復(fù)雜,但我們始終無法解釋內(nèi)部發(fā)生了什么,“黑箱問題”一直困擾著我們。我們不清楚程序在翻譯過程中如何進(jìn)行決策,所以當(dāng)翻譯出錯(cuò)時(shí)也很難改正。隨著深度學(xué)習(xí)在各行各業(yè)中的廣泛應(yīng)用,深度學(xué)習(xí)的不可解釋性已經(jīng)成為其面臨的嚴(yán)峻挑戰(zhàn)之一。
今年,在德國柏林舉辦的 IEEE VAST 可視化分析大會上,來自 IBM 和哈佛大學(xué)的研究人員展示了為解決翻譯中的 AI 黑盒問題所開發(fā)的調(diào)試工具。這款名為 Seq2Seq-Vis 的工具能將人工智能的翻譯過程進(jìn)行可視化,方便開發(fā)人員對模型進(jìn)行調(diào)試。
Seq2Seq-Vis 主要針對機(jī)器翻譯中最常用的 Seq2Seq模型。這一模型能夠?qū)⑷我忾L度的序列,也就是原文的句子,映射到目標(biāo)語言。除了機(jī)器翻譯任務(wù),在自動問答、文本摘要等任務(wù)中也都主要應(yīng)用 Seq2Seq模型。
簡單來說,Seq2Seq模型在機(jī)器翻譯中的工作原理就是把源語言映射到目標(biāo)語言,得到了目標(biāo)語言的序列(也就是初步翻譯完的句子)后再進(jìn)行優(yōu)化,保證語法和語義上的正確。雖然使用神經(jīng)網(wǎng)路模型后,機(jī)器翻譯的結(jié)果得到了很大的提升,但同時(shí)也非常復(fù)雜。
可視化機(jī)器翻譯的過程
研究人員稱研發(fā) Seq2Seq-Vis 的初衷是想有一個(gè)類似于基于規(guī)則的傳統(tǒng)翻譯軟件中的規(guī)則表,這樣開發(fā)人員可以通過在規(guī)則表中對照得到錯(cuò)誤信息就可以很簡單地修改模型。
Seq2Seq-Vis.io 網(wǎng)站上給出了一個(gè)從德語到英語的演示程序。德語的“die l?ngsten reisen fangen an , wenn es auf den stra?en dunkel wird.”翻譯成英語應(yīng)該是“The longest journeys begin when it gets dark in the streets.”,但被機(jī)器翻譯成了“the longest travel begins when it gets to the streets.”Seq2Seq-Vis 以可視化的方式呈現(xiàn)出了序列到序列模型翻譯的每一步,這樣用戶就能像查找規(guī)則表一樣來找出機(jī)器翻譯翻譯錯(cuò)誤的原因。
Seq2Seq-Vis 另一個(gè)很有用的功能是它能找出與某個(gè)字詞相關(guān)的訓(xùn)練集,這也是解決 AI 黑盒問題的一大難點(diǎn)。其實(shí)一個(gè)機(jī)器學(xué)習(xí)模型除了訓(xùn)練集一無所知,所以要解決機(jī)器翻譯中的錯(cuò)誤最終都要回到訓(xùn)練集中去。
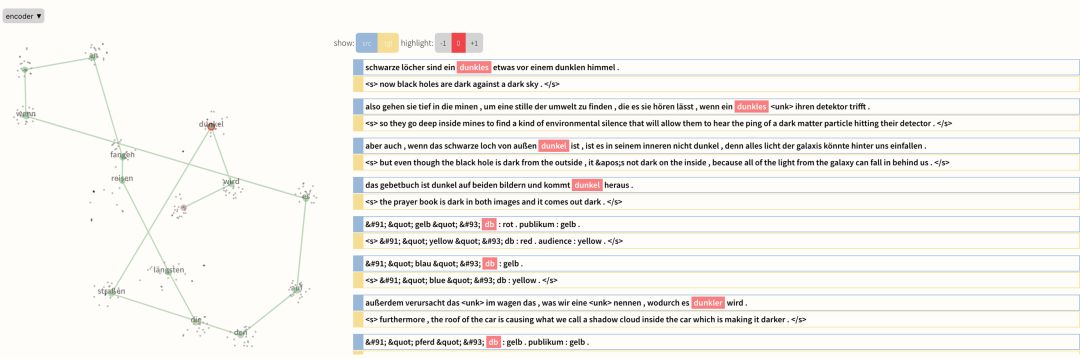
將機(jī)器翻譯過程可視化,用戶就能確定翻譯出錯(cuò)到底是編碼器解碼器使用的訓(xùn)練樣本出了錯(cuò)還是注意力模型的設(shè)置或者其他環(huán)節(jié)出錯(cuò)了。
更正序列到序列模型
Seq2Seq-Vis 并不是第一個(gè)試圖解決 AI 黑盒問題的工具,之前有很多大公司和研究機(jī)構(gòu)都有進(jìn)行嘗試,甚至 IBM 自己也在這上面下過功夫。事實(shí)上,很多類似的工具需要的信息比 Seq2Seq-Vis 更少,比如有的工具只需要神經(jīng)網(wǎng)絡(luò)的輸出就可以,而 Seq2Seq-Vis 還需要訓(xùn)練集,整個(gè)模型的架構(gòu)和設(shè)置。但 Seq2Seq-Vis 卻是第一個(gè)既能可視化模型的決策過程也能讓開發(fā)人員直接修改模型的工具。開發(fā)人員可以通過可視化的方式對模型的決策過程進(jìn)行修改并觀察反饋來實(shí)現(xiàn)探索式的調(diào)試,比如修改輸出序列的單詞或者對注意力模型的配置進(jìn)行修改。
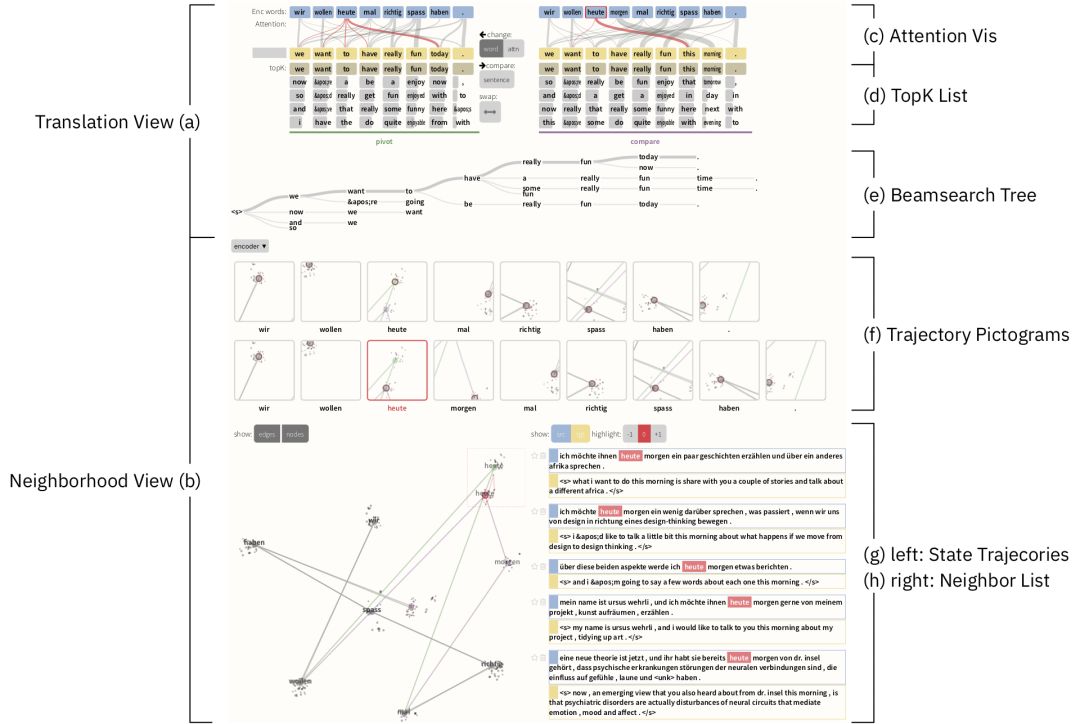
聽起來是不是很酷,不過Seq2Seq-Vis 的目標(biāo)群體是模型架構(gòu)師或工程師而非機(jī)器翻譯的終端用戶。因?yàn)橐屵@一工具真正發(fā)揮作用需要用戶對“序列到序列”模型有較為深入的了解。雖然目標(biāo)這一工具還只是應(yīng)用在IBM的內(nèi)部項(xiàng)目中,但它是開源的,所以大家都可以來試試。
-
人工智能
+關(guān)注
關(guān)注
1793文章
47532瀏覽量
239293 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8429瀏覽量
132852 -
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14919
原文標(biāo)題:開源 | IBM、哈佛共同研發(fā):Seq2Seq模型可視化工具
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
光學(xué)系統(tǒng)的3D可視化
焊接過程可視化的應(yīng)用前景有哪些

《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第4章-AI與生命科學(xué)讀后感
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新
FPGA在人工智能中的應(yīng)用有哪些?
大屏數(shù)據(jù)可視化 開源





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論