 AlphaZero如何快速學習每個游戲,如何從隨機對弈開始訓練
AlphaZero如何快速學習每個游戲,如何從隨機對弈開始訓練
不僅會下圍棋,還自學成才橫掃國際象棋和日本將棋的DeepMind AlphaZero,登上了最新一期《科學》雜志封面。
同時,這也是經過完整同行審議的AlphaZero論文,首次公開發表。
論文描述了AlphaZero如何快速學習每個游戲,如何從隨機對弈開始訓練,在沒有先驗知識、只知道基本規則的情況下,成為史上最強大的棋類人工智能。
《科學》雜志評價稱,能夠解決多個復雜問題的單一算法,是創建通用機器學習系統,解決實際問題的重要一步。
DeepMind說,現在AlphaZero已經學會了三種不同的復雜棋類游戲,并且可能學會任何一種完美信息博弈的游戲,這“讓我們對創建通用學習系統的使命充滿信心”。
AlphaZero到底有多厲害?再總結一下。
在國際象棋中,AlphaZero訓練4小時就超越了世界冠軍程序Stockfish;
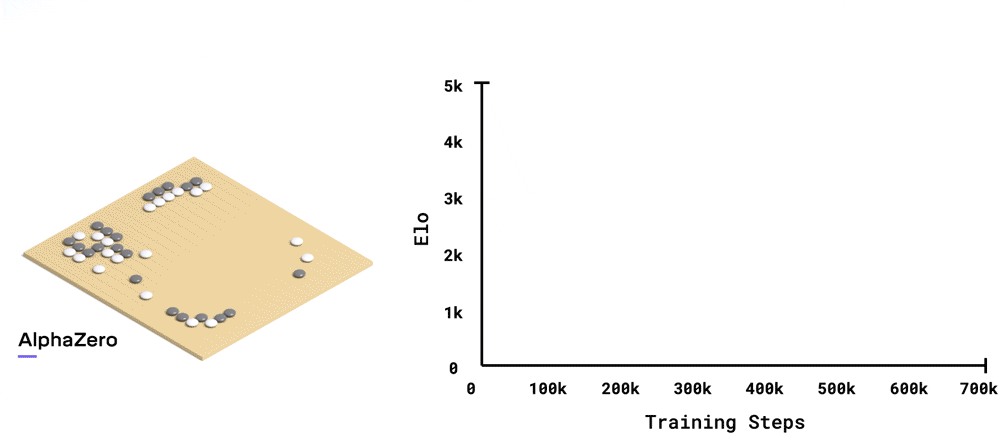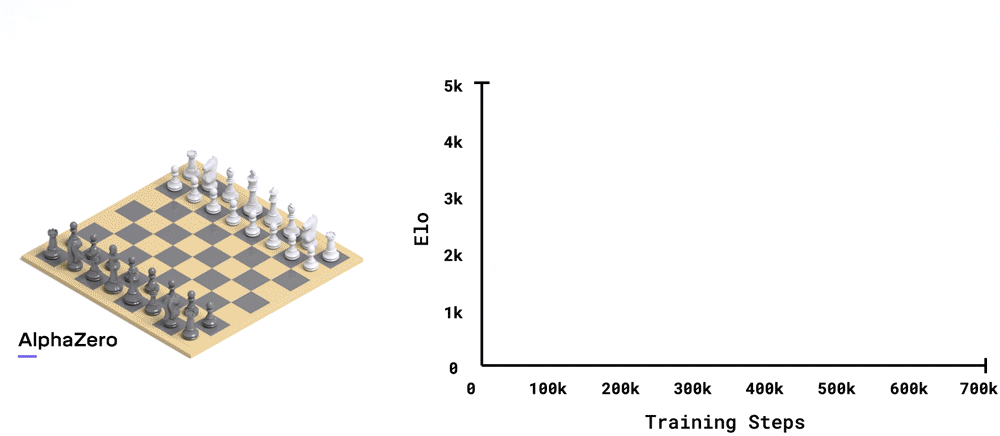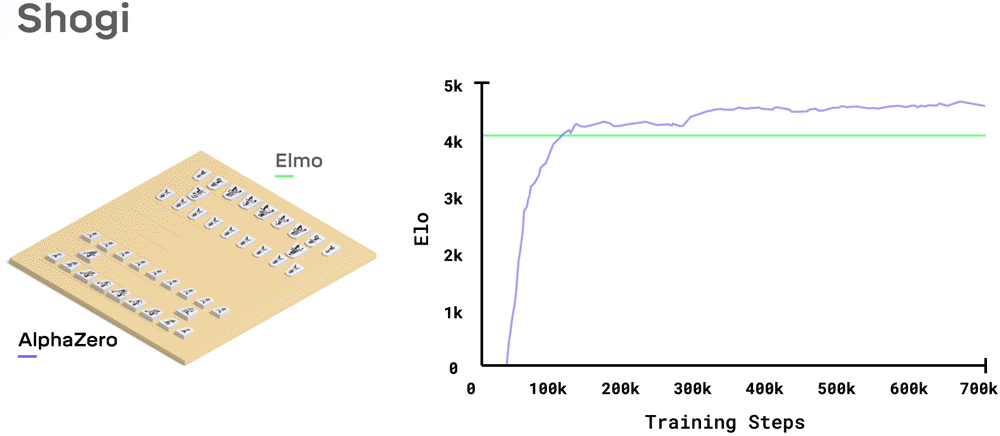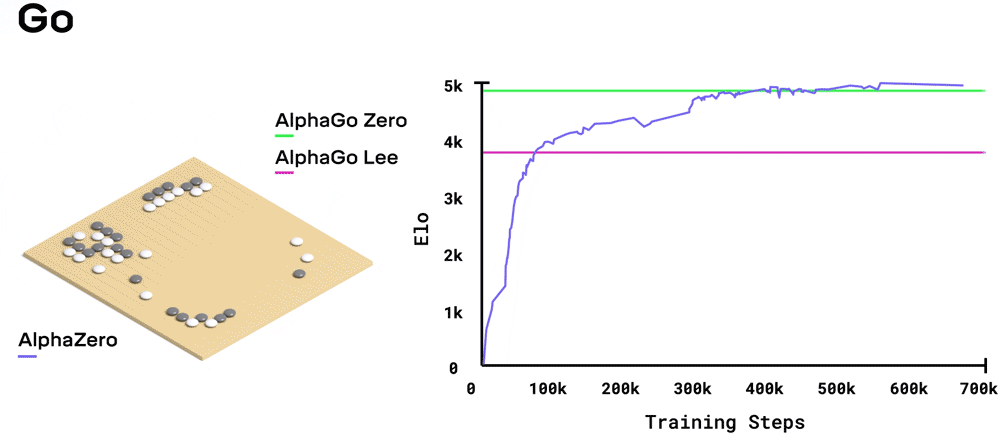
在日本將棋中,AlphaZero訓練2小時就超越了世界冠軍程序Elmo。
在圍棋中,AlphaZero訓練30小時就超越了與李世石對戰的AlphaGo。
AlphaZero有什么不同
國際象棋有什么難的?
實際上,國際象棋是計算機科學家很早就開始研究的領域。1997年,深藍擊敗了人類國際象棋冠軍卡斯帕羅夫,這是一個人工智能的里程碑。此后20年,國際象棋的算法在超越人類后,一直還在不斷地進步。
這些算法都是由強大的人類棋手和程序員構建,基于手工制作的功能和精心調整的權重來評估位置,并且結合了高性能的alpha-beta搜索。
而提到游戲樹的復雜性,日本將棋比國際象棋還難。日本將棋程序,使用了類似國際象棋的算法,例如高度優化的alpha-beta搜索,以及許多有針對性的設置。
AlphaZero則完全不同,它依靠的是深度神經網絡、通用強化學習算法和通用樹搜索算法。除了基本規則之外,它對這些棋類游戲一無所知。
其中,深度神經網絡取代了手工寫就的評估函數和下法排序啟發算法,蒙特卡洛樹搜索(MCTS)算法取代了alpha-beta搜索。
AlphaZero深度神經網絡的參數,通過自我博弈的強化學習來訓練,從隨機初始化的參數開始。
隨著時間推移,系統漸漸從輸、贏以及平局里面,學會調整參數,讓自己更懂得選擇那些有利于贏下比賽的走法。
那么,圍棋和國際象棋、將棋有什么不同?
圍棋的對弈結局只有輸贏兩種,而國際象棋和日本將棋都有平局。其中,國際象棋的最優結果被認為是平局。
此外,圍棋的落子規則相對簡單、平移不變,而國際象棋和日本將棋的規則是不對稱的,不同的棋子有不同的下法,例如士兵通常只能向前移動一步,而皇后可以四面八方無限制的移動。而且這些棋子的移動規則,還跟位置密切相關。
盡管存在這些差異,但AlphaZero與下圍棋的AlphaGo Zero使用了相同架構的卷積網絡。
AlphaGo Zero的超參數通過貝葉斯優化進行調整。而在AlphaZero中,這些超參數、算法設置和網絡架構都得到了繼承。
除了探索噪聲和學習率之外,AlphaZero沒有為不同的游戲做特別的調整。
5000個TPU練出最強全能棋手
系統需要多長時間去訓練,取決于每個游戲有多難:國際象棋大約9小時,將棋大約12小時,圍棋大約13天。
只是這個訓練速度很難復現,DeepMind在這個環節,投入了5000個一代TPU來生成自我對弈游戲,16個二代TPU來訓練神經網絡。
訓練好的神經網絡,用來指引一個搜索算法,就是蒙特卡洛樹搜索 (MCTS) ,為每一步棋選出最有利的落子位置。
每下一步之前,AlphaZero不是搜索所有可能的排布,只是搜索其中一小部分。
比如,在國際象棋里,它每秒搜索6萬種排布。對比一下,Stockfish每秒要搜索6千萬種排布,千倍之差。
△每下一步,需要做多少搜索?
AlphaZero下棋時搜索的位置更少,靠的是讓神經網絡的選擇更集中在最有希望的選擇上。DeepMind在論文中舉了個例子來展示。
上圖展示的是在AlphaZero執白、Stockfish執黑的一局國際象棋里,經過100次、1000次……直到100萬次模擬之后,AlphaZero蒙特卡洛樹的內部狀態。每個樹狀圖解都展示了10個最常訪問的狀態。
經過全面訓練的系統,就和各個領域里的最強AI比一比:國際象棋的Stockfish,將棋的Elmo,以及圍棋的前輩AlphaGo Zero。
每位參賽選手都是用它最初設計中針對的硬件來跑的:
Stockfish和Elmo都是用44個CPU核;AlphaZero和AlphaGo Zero用的都是一臺搭載4枚初代TPU和44個CPU核的機器。
(一枚初代TPU的推理速度,大約相當于一個英偉達Titan V GPU。)
另外,每場比賽的時長控制在3小時以內,每一步棋不得超過15秒。
比賽結果是,無論國際象棋、將棋還是圍棋,AlphaGo都擊敗了對手:
國際象棋,大比分擊敗2016 TCEC冠軍Stockfish,千場只輸155場。
將棋,大比分擊敗2017 CSA世界冠軍Elmo,勝率91.2%。
圍棋,擊敗自學成才的前輩AlphaGo Zero,勝率61%。
不按套路落子
因為AlphaZero自己學習了每種棋類,于是,它并不受人類現有套路的影響,產生了獨特的、非傳統的、但具有創造力和動態的棋路。
在國際象棋里,它還發展出自己的直覺和策略,增加了一系列令人興奮的新想法,改變了幾個世紀以來對國際象棋戰略的思考。
國際象棋世界冠軍卡斯帕羅夫也在《科學》上撰文表示,AlphaZero具備動態、開放的風格,“就像我一樣”。他指出通常國際象棋程序會追求平局,但AlphaZero看起來更喜歡風險、更具侵略性。卡斯帕羅夫表示,AlphaZero的棋風可能更接近本源。
卡斯帕羅夫說,AlphaZero以一種深刻而有用的方式超越了人類。
國際象棋大師馬修·薩德勒(Matthew Sadler)和女性國際大師娜塔莎·里根(Natasha Regan)即將于2019年1月出版新書《棋類變革者(Game Changer)》,在這本書中,他們分析了數以千計的AlphaZero棋譜,認為AlphaZero的棋路不像任何傳統的國際象棋引擎,馬修·薩德勒評價它為“就像以前翻看一些厲害棋手的秘密筆記本。”
棋手們覺得,AlphaZero玩這些游戲的風格最迷人。
國際象棋特級大師馬修·薩德勒說:“它的棋子帶著目的和控制力包圍對手的王的方式”,最大限度地提高了自身棋子的活動性和移動性,同時最大限度地減少了對手棋子的活動和移動性。
與直覺相反,AlphaZero似乎對“材料”的重視程度較低,這一想法是現代游戲的基礎,每一個棋子都具有價值,如果玩家在棋盤上的某個棋子價值高于另一個,那么它就具有物質優勢。AlphaZero愿意在游戲早期犧牲棋子,以獲得長期收益。
“令人印象深刻的是,它設法將自己的風格強加于各種各樣的位置和空缺,”馬修說他也觀察到,AlphaZero以非常刻意的方式發揮作用,一開始就以“非常人性化的堅定目標”開始。
“傳統引擎非常強大,幾乎不會出現明顯錯誤,但在面對沒有具體和可計算解決方案的位置時,會發生偏差,”他說。 “正是在這樣的位置,AlphaZero才能體現出‘感覺’,‘洞察’或‘直覺’。”
這種獨特的能力,在其他傳統的國際象棋程序中看不到,并且已經給最近舉辦的世界國際象棋錦標賽提供了新的見解和評論。
“看看AlphaZero的分析與頂級國際象棋引擎甚至頂級大師級棋手的分析有何不同,這真是令人著迷,”女棋手娜塔莎·里根說。 “AlphaZero可以成為整個國際象棋圈強大的教學工具。”
AlphaZero的教育意義,早在2016年AlphaGo對戰李世石時就已經看到。
在比賽期間,AlphaGo發揮出了許多極具創造性的勝利步法,包括在第二場比賽中的37步,這推翻了之前數百年的思考。這種下法以及其他許多下法,已經被包括李世石本人在內的所有級別的棋手研究過。
他對第37步這樣評價:“我曾認為AlphaGo是基于概率計算的,它只是一臺機器。但當我看到這一舉動時,我改變了想法。當然AlphaGo是有創造性的。“
不僅僅是棋手
DeepMind在博客中說AlphaZero不僅僅是國際象棋、將棋或圍棋。它是為了創建能夠解決各種現實問題的智能系統,它需要靈活適應新的狀況。
這正是AI研究中的一項重大挑戰:系統能夠以非常高的標準掌握特定技能,但在略微修改任務后往往會失敗。
AlphaZero現在能夠掌握三種不同的復雜游戲,并可能掌握任何完美信息游戲,解決了以上問題中重要的一步。
他們認為,AlphaZero的創造性見解,加上DeepMind在AlphaFold等其他項目中看到的令人鼓舞的結果,帶來了創建通用學習系統的信心,有助于找到一些新的解決方案,去解決最重要和最復雜的科學問題。
DeepMind的Alpha家族從最初的圍棋算法AlphaGo,幾經進化,形成了一個家族。
剛提到的AlphaFold,最近可以說關注度爆表。
它能根據基因序列來預測蛋白質的3D結構,還在有“蛋白質結構預測奧運會”之稱的CASP比賽中奪冠,力壓其他97個參賽者。這是“證明人工智能研究驅動、加速科學進展重要里程碑”,DeepMInd CEO哈薩比斯形容為“燈塔”。
從2016年AlphaGo論文發表在《自然》上,到今天AlphaZero登上《科學》,Alpha家族除了最新出爐的AlphaFold之外,AlphaGo、AlphaGo Zero和AlphaZero已經全部在頂級期刊Nature和Science上亮相。
期待轟動科研界的AlphaFold論文早日露面。
AlphaZero論文
這篇刊載在《科學》上的論文,題為:
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
作者包括:David Silver、Thomas Hubert、Julian Schrittwieser、Ioannis Antonoglou、Matthew Lai、Arthur Guez、Marc Lanctot、Laurent Sifre、Dharshan Kumaran、Thore Graepel、Timothy Lillicrap、Karen Simonyan、Demis Hassabis。
《科學》刊載的論文在此:http://science.sciencemag.org/content/362/6419/1140
棋局可以在此下載:https://deepmind.com/research/alphago/alphazero-resources/
DeepMind還特別寫了一個博客,傳送門:https://deepmind.com/blog/alphazero-shedding-new-light-grand-games-chess-shogi-and-go/
-
神經網絡
+關注
關注
42文章
4774瀏覽量
100909 -
人工智能
+關注
關注
1792文章
47442瀏覽量
239013 -
機器學習
+關注
關注
66文章
8425瀏覽量
132775
原文標題:AlphaZero登上《科學》封面:一個算法“通殺”三大棋,完整論文首次發布
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何才能高效地進行深度學習模型訓練?
AlphaGo為何精通圍棋?圍棋論文曝光【中文翻譯】-原來它是這樣深度學習和思考的,難怪老贏!
如何在基于Arm的設備上運行游戲AI呢
谷歌發布新版AlphaGo,對弈自我學習,已擊敗柯潔系統
隨機塊模型學習算法
史上最強棋類AI降臨!也是迄今最強的棋類AI——AlphaZero
Python隨機數模塊的隨機函數使用

基于預訓練模型和長短期記憶網絡的深度學習模型






 工商網監
工商網監
評論