") 一文解讀語音識別的運行原理
一文解讀語音識別的運行原理
今天的文章將向您展示如何構建可以識別 10 個不同字詞的基本語音識別網(wǎng)絡。需要注意的是,真正的語音和音頻識別系統(tǒng)要復雜得多,但就像用于識別圖像的 MNIST,這個基本語音識別網(wǎng)絡能夠幫助您基本了解所涉及的技術。學完本教程后,您將獲得一個模型,該模型會嘗試將時長為 1 秒的音頻片段歸類為無聲、未知字詞、“yes”、“no”、“up”、“down”、“l(fā)eft”、“right”、“on”、“off”、“stop” 或 “go”。您還可以在 Android 應用中運行該模型。
準備
您應確保安裝了 TensorFlow;此外,由于腳本會下載超過 1GB 的訓練數(shù)據(jù),因此您需要確保計算機擁有穩(wěn)定的互聯(lián)網(wǎng)連接和足夠的可用空間。訓練過程可能需要幾個小時,因此請確保您的計算機可以完成這么長時間的訓練操作。
訓練
要開始訓練過程,請轉(zhuǎn)到 TensorFlow 源代碼樹,然后運行以下腳本:
python tensorflow/examples/speech_commands/train.py
該腳本會先下載語音指令數(shù)據(jù)集,其中包含超過 105000 個 WAVE 音頻文件,音頻內(nèi)容是有人說出 30 個不同的字詞。這些數(shù)據(jù)由 Google 收集,并依據(jù) CC BY 許可發(fā)布,您可以提交 5 分鐘自己的錄音來幫助改進該數(shù)據(jù)。歸檔數(shù)據(jù)超過 2GB,因此這部分過程可能需要一段時間,但您應該可以看到進度日志;下載完成后,您無需再次執(zhí)行此步驟。如需詳細了解該數(shù)據(jù)集,請參閱https://arxiv.org/abs/1804.03209
下載完成后,您將看到如下日志信息:
I0730 16:53:44.766740 55030 train.py:176] Training from step: 1I0730 16:53:47.289078 55030 train.py:217] Step #1: rate 0.001000, accuracy 7.0%, cross entropy 2.611571
這表明初始化過程已經(jīng)完成,訓練循環(huán)已經(jīng)開始。您將看到該日志輸出每個訓練步的信息。下面詳細說明了該日志信息的含義:
Step #1表明正在進行訓練循環(huán)的第一步。在此示例中總共有 18000 個訓練步,您可以查看步編號來了解還有多少步即可完成。
rate 0.001000是控制網(wǎng)絡權重更新速度的學習速率。在訓練的早期階段,它是一個相對較大的數(shù)字 (0.001),但在訓練周期的后期會減少到原來的十分之一,即 0.0001。
accuracy 7.0%表示模型在本訓練步中預測正確的類別數(shù)量。該值通常會有較大的波動,但應該會隨著訓練的進行總體有所提高。該模型會輸出一個數(shù)字數(shù)組,每個標簽對應一個數(shù)字,每個數(shù)字都表示輸入可能歸入該類別的預測概率。可通過選擇得分最高的條目來挑選預測標簽。得分始終介于 0 到 1 之間,值越高表示結果的置信度越高。
cross entropy 2.611571是用于指導訓練過程的損失函數(shù)的結果。它是一個得分,通過將當前訓練運行的得分向量與正確標簽進行比較計算而出,該得分應在訓練期間呈下滑趨勢。
經(jīng)過 100 步之后,您應看到如下所示的行:
I0730 16:54:41.813438 55030 train.py:252] Saving to "/tmp/speech_commands_train/conv.ckpt-100"
此行會將當前的訓練權重保存到檢查點文件中。如果訓練腳本中斷了,您可以查找上次保存的檢查點,然后將--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-100用作命令行參數(shù)重啟該腳本,以便從該點開始。
混淆矩陣
經(jīng)過 400 步之后,您會看到以下日志信息:
I0730 16:57:38.073667 55030 train.py:243] Confusion Matrix:[[258 0 0 0 0 0 0 0 0 0 0 0][ 7 6 26 94 7 49 1 15 40 2 0 11][ 10 1 107 80 13 22 0 13 10 1 0 4][ 1 3 16 163 6 48 0 5 10 1 0 17][ 15 1 17 114 55 13 0 9 22 5 0 9][ 1 1 6 97 3 87 1 12 46 0 0 10][ 8 6 86 84 13 24 1 9 9 1 0 6][ 9 3 32 112 9 26 1 36 19 0 0 9][ 8 2 12 94 9 52 0 6 72 0 0 2][ 16 1 39 74 29 42 0 6 37 9 0 3][ 15 6 17 71 50 37 0 6 32 2 1 9][ 11 1 6 151 5 42 0 8 16 0 0 20]]
第一部分是混淆矩陣。要理解它的具體含義,您首先需要了解所用的標簽。在本示例中,所用的標簽是 “silence”、“unknown”、“yes”、“no”、“up”、“down”、“l(fā)eft”、“right”、“on”、“off”、“stop” 和 “go”。每列代表一組被模型預測為每個標簽的樣本,因此第一列代表預測為無聲的所有音頻片段,第二列代表預測為未知字詞的所有音頻片段,第三列代表預測為 “yes” 的所有音頻片段,依此類推。
每行表示音頻片段實際歸入的標簽。第一行是歸入無聲的所有音頻片段,第二行是歸入未知字詞的所有音頻片段,第三行是歸入 “yes” 的所有音頻片段,依此類推。
此矩陣比單個準確率得分更加有用,因為它可以很好地總結網(wǎng)絡出現(xiàn)的錯誤。在此示例中,您可以發(fā)現(xiàn),除了第一個數(shù)值以外,第一行中的所有條目均為 0。因為第一行表示所有實際無聲的音頻片段,這意味著所有音頻片段都未被錯誤地標記為字詞,因此我們未得出任何有關無聲的假負例。這表示網(wǎng)絡已經(jīng)可以很好地區(qū)分無聲和字詞。
如果我們往下看,就會發(fā)現(xiàn)第一列有大量非零值。該列表示預測為無聲的所有音頻片段,因此第一個單元格外的正數(shù)是錯誤的預測。這表示一些實際是語音字詞的音頻片段被預測為無聲,因此我們得出了很多假正例。
完美的模型會生成混淆矩陣,除了穿過中心的對角線上的條目以外,所有其他條目都為 0。發(fā)現(xiàn)偏離這個模式的地方有助于您了解模型最容易在哪些方面混淆;確定問題所在后,您就可以通過添加更多數(shù)據(jù)或清理類別來解決這些問題。
驗證
在混淆矩陣之后,您應看到如下所示的行:
I0730 16:57:38.073777 55030 train.py:245] Step 400: Validation accuracy = 26.3% (N=3093)
最好將數(shù)據(jù)集分成三個類別。最大的子集(本示例中為約 80% 的數(shù)據(jù))用于訓練網(wǎng)絡,較小的子集(本示例中為約 10% 的數(shù)據(jù),稱為 “驗證” 集)預留下來以評估訓練期間的準確率,另一個子集(剩下的 10%,稱為 “測試” 集)用來評估訓練完成后的準確率。
之所以采用這種拆分方法,是因為始終存在這樣一種風險:網(wǎng)絡在訓練期間開始記憶輸入。通過將驗證集分離開來,可以確保模型能夠處理它之前從未見過的數(shù)據(jù)。測試集是一種額外的保護措施,可以確保您不僅以適合訓練集和驗證集的方式調(diào)整模型,而且使模型能夠泛化到范圍更廣的輸入。
訓練腳本會自動將數(shù)據(jù)集分為這三個類別,上面的日志行會顯示在驗證集上運行時模型的準確率。理想情況下,該準確率應該相當接近訓練準確率。如果訓練準確率有所提高但驗證準確率沒有,則表明存在過擬合,模型只學習了有關訓練音頻片段的信息,而沒有學習能泛化的更廣泛模式。
Tensorboard
使用 Tensorboard 可以很好地觀察訓練進度。默認情況下,腳本會將事件保存到 /tmp/retrain_logs,您可以通過運行以下命令加載這些事件:
tensorboard --logdir /tmp/retrain_logs
然后,在瀏覽器中轉(zhuǎn)到http://localhost:6006,您將看到顯示模型進度的圖表。
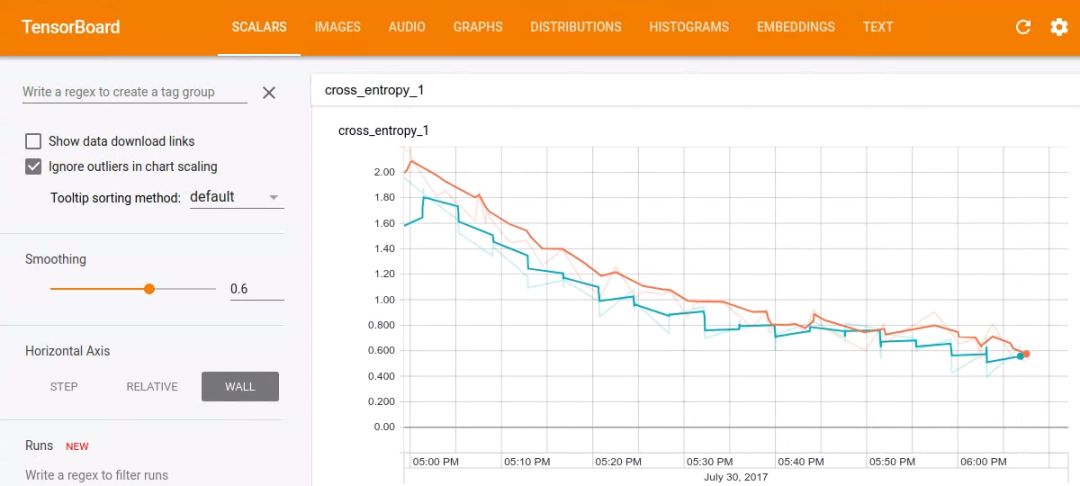
訓練完成
經(jīng)過幾個小時(具體取決于計算機的速度)的訓練后,腳本應該已經(jīng)完成了全部 18000 個訓練步。它會輸出在測試集上運行時的最終混淆矩陣以及準確率得分。使用默認設置時,您應該會看到準確率介于 85% 到 90% 之間。
由于音頻識別在移動設備上特別有用,因此接下來我們會將其導出為易于在這些平臺上使用的緊湊格式。為此,請運行以下命令行:
python tensorflow/examples/speech_commands/freeze.py --start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000 --output_file=/tmp/my_frozen_graph.pb
創(chuàng)建凍結模型后,您可以使用label_wav.py腳本對其進行測試,如下所示:
python tensorflow/examples/speech_commands/label_wav.py --graph=/tmp/my_frozen_graph.pb --labels=/tmp/speech_commands_train/conv_labels.txt --wav=/tmp/speech_dataset/left/a5d485dc_nohash_0.wav
上述命令應該會輸出 3 個標簽:
left (score = 0.81477)right (score = 0.14139)_unknown_ (score = 0.03808)
希望 “l(fā)eft” 的得分最高,因為它是正確的標簽,但由于訓練是隨機的,因此嘗試的第一個文件可能并非如此。嘗試一下同一文件夾中的其他一些 .wav 文件,看看效果如何。
得分介于 0 到 1 之間,值越高表示模型對其預測越有信心。
在 Android 應用中運行模型
要查看該模型在實際應用中的工作原理,最簡單的方法是下載預構建的 Android 演示應用,并將其安裝在手機上。您會在應用列表中看到 “TF Speech”,打開它就會看到我們剛剛訓練模型時使用的動詞列表(以 “Yes” 和 “No” 開始)。授權該應用使用麥克風以后,您應該可以試著說出這些字詞,在該模型識別出其中一個字詞時,您會在界面中看到相應字詞突出顯示出來。
您還可以自行構建該應用,因為它是開源的,可在 GitHub 上的 TensorFlow 代碼庫中找到。默認情況下,它會從 tensorflow.org 下載預訓練的模型,但您可以輕松地將其替換為自己訓練的模型。如果這樣做,您需要確保主要 SpeechActivity Java 源文件中的常量(例如SAMPLE_RATE和SAMPLE_DURATION)與您在訓練期間對默認設置所做的任何更改相匹配。您還會看到一個Java 版本的 RecognizeCommands 模塊,它與本教程中的 C++ 版本非常相似。如果您已經(jīng)調(diào)整了參數(shù),也可以在 SpeechActivity 中進行更新,以獲得與服務器測試中的結果相同的結果。
演示應用會根據(jù)您復制到資源(位于凍結圖旁邊)中的標簽文本文件自動更新其結果界面列表,這意味著您可以輕松嘗試不同的模型,而無需更改任何代碼。如果更改路徑,則需要更新LABEL_FILENAME和MODEL_FILENAME以指向所添加的文件。
此模型的工作原理
本教程中使用的架構基于小型關鍵字檢測卷積神經(jīng)網(wǎng)絡這篇論文中介紹的一些架構。之所以選擇它,是因為它雖然不是最先進的架構,但是相對簡單、可快速訓練,并且易于理解。可以通過多種方法構建用于處理音頻的神經(jīng)網(wǎng)絡模型,其中包括遞歸網(wǎng)絡或擴張(帶洞)卷積。對于本教程所基于的卷積網(wǎng)絡類型,接觸過圖像識別的人可能都很熟悉。不過,初次接觸時也可能會覺得不可思議,因為音頻本身是一段時間內(nèi)的一維連續(xù)信號,而不是二維空間問題。
為了解決這一問題,我們會定義一個我們認為我們的語音字詞應該符合的時間范圍,并將這段時間內(nèi)的音頻信號轉(zhuǎn)換成圖像。為此,可以將傳入的音頻樣本分成小段(時長僅為幾毫秒)并計算一組頻段內(nèi)頻率的強度。一段音頻內(nèi)的每組頻率強度被視為數(shù)字向量,這些向量按時間順序排列,形成一個二維數(shù)組。然后,該值數(shù)組可被視為單通道圖像,稱為聲譜圖。如果要查看音頻樣本生成的圖像類型,可以運行 wav_to_spectrogram 工具:
bazel run tensorflow/examples/wav_to_spectrogram:wav_to_spectrogram -- --input_wav=/tmp/speech_dataset/happy/ab00c4b2_nohash_0.wav --output_image=/tmp/spectrogram.png
如果您打開/tmp/spectrogram.png,應該會看到如下內(nèi)容:
由于 TensorFlow 的內(nèi)存排序原因,該圖像中的時間從上往下逐漸增加,而頻率從左到右排列,這與時間從左到右排列的聲譜圖慣例不同。您應該能夠看到幾個不同的部分,第一個音節(jié) “Ha” 與 “ppy” 不同。
由于人耳對某些頻率更加敏感,因此語音識別領域傳統(tǒng)的做法是進一步處理該表示法,將其轉(zhuǎn)換成一組梅爾倒頻譜系數(shù)(簡稱 MFCC)。MFCC 也是一種二維單通道表示法,因此也可將其視為圖像。如果您的目標是一般聲音而不是語音,您可以跳過此步驟并直接在聲譜圖上進行操作。
然后,這些處理步驟生成的圖像會饋送到多層卷積神經(jīng)網(wǎng)絡中,最后是全連接層,后跟 softmax。您可以在以下位置了解該部分的定義:tensorflow/examples/speech_commands/models.py。
流式處理準確率
大部分音頻識別應用需要在連續(xù)的音頻流上運行,而不是在單個音頻片段上運行。在此環(huán)境中使用模型的典型方法是在不同的時間偏移量處重復應用該模型,并計算一小段時間內(nèi)結果的平均值,以生成平滑預測。如果您將輸入視為圖像,則它將沿時間軸持續(xù)滾動。我們想要識別的字詞可能在任意時間點出現(xiàn),因此,我們需要拍攝一系列快照,以便有機會生成一種對齊方式,用于捕獲在我們饋送到模型的時間段內(nèi)出現(xiàn)的大部分語音內(nèi)容。如果我們以足夠快的速度采樣,那么我們就很有可能在多個時間段內(nèi)捕獲相關字詞,因此計算結果的平均值可以提高預測的整體置信度。
有關如何對流式數(shù)據(jù)使用模型的示例,請查看test_streaming_accuracy.cc(https://www.tensorflowers.cn/t/7512)。該示例使用RecognizeCommands(https://www.tensorflowers.cn/t/7514)類處理一個較長的輸入音頻、嘗試檢測字詞,并將這些預測結果與標簽和時間的真實列表進行對比。該示例可清楚說明如何將模型應用于一段時間內(nèi)的音頻信號流。
要測試模型,您需要使用一個時長較長的音頻文件,以及標注每個語音字詞出現(xiàn)位置的標簽文件。如果您不想自己錄制音頻,可以使用generate_streaming_test_wav實用程序生成一些合成測試數(shù)據(jù)。默認情況下,該實用程序會生成一個時長為 10 分鐘的 .wav 文件(其中大約每隔 3 秒出現(xiàn)一個語音字詞),以及一個包含字詞語音實際出現(xiàn)時間的文本文件。這些字詞來自當前數(shù)據(jù)集的測試部分,與背景噪聲混在一起。要運行該文件,請使用:
bazel run tensorflow/examples/speech_commands:generate_streaming_test_wav
該命令會將 .wav 文件保存到/tmp/speech_commands_train/streaming_test.wav,并將列出標簽的文本文件保存到/tmp/speech_commands_train/streaming_test_labels.txt。然后,您可以通過以下命令運行準確率測試:
bazel run tensorflow/examples/speech_commands:test_streaming_accuracy -- --graph=/tmp/my_frozen_graph.pb --labels=/tmp/speech_commands_train/conv_labels.txt --wav=/tmp/speech_commands_train/streaming_test.wav --ground_truth=/tmp/speech_commands_train/streaming_test_labels.txt --verbose
該命令會輸出以下信息:字詞與標簽匹配正確的字詞數(shù)量、預測為錯誤標簽的字詞數(shù)量,以及沒有實際語音內(nèi)容時觸發(fā)模型的次數(shù)。有多種參數(shù)可以控制平均信號操作的行為,其中包括--average_window_ms(設置計算結果平均值的時長)、--clip_stride_ms(表示應用模型的間隔時間)、--suppression_ms(在發(fā)現(xiàn)第一個字詞后的一段時間內(nèi)阻止觸發(fā)后續(xù)字詞檢測),以及--detection_threshold(控制平均得分必須達到多少才可被視為穩(wěn)定結果)。
您將看到流式準確率輸出 3 個數(shù)字,而不僅僅是訓練中使用的一個指標。這是因為不同的應用具有不同的要求,其中一些應用可以容忍頻繁的錯誤結果,只要找到了實際字詞(較高的召回率)就行;還有一些應用非常注重確保預測出的標簽很有可能正確,即便未檢測到一些字詞(較高的精確率)。您可以根據(jù)該工具提供的數(shù)字了解模型在應用中的效果,還可以嘗試調(diào)整信號平均參數(shù)來調(diào)整模型,以獲得所需的效果。要了解適用于您應用的參數(shù),您可以查看生成的ROC 曲線來權衡利弊。
RecognizeCommands
流式準確率工具使用一個簡單的解碼器,該解碼器包含在名為RecognizeCommands的小型 C++ 類中。該類會獲得在一段時間內(nèi)運行 TensorFlow 模型的輸出,然后計算信號的平均值,并在有充分證據(jù)表明已發(fā)現(xiàn)可識別的字詞時返回有關標簽的信息。這個實現(xiàn)的規(guī)模很小,只需跟蹤最后幾條預測并計算平均值即可,因此可根據(jù)需要輕松移植到其他平臺和語言。例如,在 Android 上可以通過 Java 很方便地執(zhí)行相似的操作,或者在樹莓派上使用 Python 執(zhí)行相似的操作。只要這些實現(xiàn)采用相同的邏輯,您就可以使用流式測試工具調(diào)整控制計算平均值的參數(shù),然后將這些參數(shù)轉(zhuǎn)到應用中以獲取類似的結果。
高級訓練
訓練腳本的默認設置旨在在一個相對較小的文件中生成良好的端到端結果,但您可以根據(jù)自己的要求更改多個選項以自定義結果。
自定義訓練數(shù)據(jù)
默認情況下,腳本將下載Speech Commands 數(shù)據(jù)集,但您也可提供自己的訓練數(shù)據(jù)。要使用您自己的數(shù)據(jù)進行訓練,您應確保您要識別的每個聲音至少有幾百條錄音,并按照類別將它們整理到文件夾中。例如,如果您嘗試讓模型區(qū)分狗吠聲和貓叫聲,則需要創(chuàng)建一個名為animal_sounds的根文件夾,然后在該文件夾下創(chuàng)建兩個分別名為bark和miaow的子文件夾。然后,將音頻文件整理到相應文件夾中。
要將腳本指向新的音頻文件,您需要設置--data_url=以阻止 Speech Commands 數(shù)據(jù)集的下載,并設置--data_dir=/your/data/folder/以查找您剛剛創(chuàng)建的文件。
這些文件本身應是 16 位有小端字節(jié)序且采用 PCM 編碼的 WAVE 格式。采樣率默認為 16000,但是可以使用--sample_rate參數(shù)更改采樣率,只要所有音頻始終保持相同的采用率(腳本不支持重新采樣)即可。音頻片段也應保持大致相同的時長。默認預期時長為 1 秒,但您可以使用--clip_duration_ms標記設置時長。如果音頻片段在開頭的無聲時長不同,則可以考慮使用字詞對齊工具標準化這些音頻片段。
需要注意一個問題,數(shù)據(jù)集中可能存在相同聲音的非常類似的重復,如果這些重復分布在訓練集、驗證集和測試集中,可能會產(chǎn)生誤導性指標。例如,Speech Commands 集合讓人們多次重復相同的字詞。這些重復的語音之間可能會非常相似,如果訓練出現(xiàn)過擬合并記住其中一個,則模型在測試集中發(fā)現(xiàn)非常類似的副本時會給出過好的預測。為了避免這種風險,Speech Commands 努力確保將同一人發(fā)出的相同字詞的多個音頻片段放入同一數(shù)據(jù)集中。音頻片段根據(jù)其文件名的哈希值分配到訓練集、測試集或驗證集中,這樣一來,即使添加新的音頻片段,也能確保分配是穩(wěn)定的,并避免訓練樣本轉(zhuǎn)移到其他集合。為了確保同一位指定發(fā)聲人的所有字詞語音都位于同一數(shù)據(jù)集中,哈希函數(shù)在計算分配時會忽略文件名中 “nohash” 之后的所有內(nèi)容。這意味著如果您有pete_nohash_0.wav和pete_nohash_1.wav這樣的文件名,則它們肯定位于同一集合中。
未知類別
應用可能會聽到訓練集之外的聲音,并且您希望模型表明它無法識別這些情況下的噪聲。為了幫助網(wǎng)絡學習要忽略哪些聲音,您需要提供一些不屬于任何類別的音頻片段。為此,您需要創(chuàng)建quack、oink和moo子文件夾,并使用用戶可能會聽到的其他動物的噪聲填充這些子文件夾。在訓練期間,腳本的--wanted_words參數(shù)定義您關注的類別,子文件夾名稱中提到的所有其他類別用于填充_unknown_類別。Speech Commands 數(shù)據(jù)集中的未知類別下有 20 個字詞,包括 0 到 9 之間的數(shù)字和隨機姓名(如 “Sheila”)。
默認情況下,從未知類別中挑選 10% 的訓練樣本,但您可以使用--unknown_percentage標記控制該比例。如果提高該比例,模型將未知字詞誤識別為所需字詞的可能性就會降低,但如果該比例過高,則可能會適得其反,因為模型可能認為將所有字詞都歸類為未知字詞是最安全的做法!
背景噪聲
即使環(huán)境中出現(xiàn)其他不相關的聲音,實際應用也必須識別音頻。為了構建一個可以穩(wěn)健應對此類干擾的模型,我們需要使用具有類似特性的已錄制音頻進行訓練。Speech Commands 數(shù)據(jù)集中的文件是由用戶使用各種設備在多種不同的環(huán)境(而不是在錄音室)中錄制的,因此有助于提高訓練的真實性。為了更加真實,您可以將環(huán)境音頻的隨機片段混合到訓練輸入中。Speech Commands 集合中有一個名為_background_noise_的特殊文件夾,其中包含時長 1 分鐘的 WAVE 文件,內(nèi)容為白噪音以及機械和日常家庭活動的錄音。
這些文件的小片段是隨機選擇的,并在訓練期間以較低的音量混合到音頻片段中。音量也是隨機選擇的,并由--background_volume參數(shù)按比例進行控制,其中 0 表示無聲,1 表示最大音量。并非所有音頻片段中都加入背景噪聲,因此--background_frequency標記控制混入噪聲的比例。
您自己的應用在其自身環(huán)境中運行所用的背景噪聲模式可能與默認模式不同,因此您可以在_background_noise_文件夾中提供自己的音頻片段。這些音頻片段的采樣率應與主數(shù)據(jù)集相同,但時長應該長很多,以便可以從中選擇一組效果良好的隨機片段。
無聲
在大多數(shù)情況下,您關注的聲音都是斷斷續(xù)續(xù)的,因此務必要清楚何時沒有匹配的音頻。為此,可以使用一個特殊的_silence_標簽,表明模型何時未檢測到任何值得關注的內(nèi)容。由于真實環(huán)境中并不存在絕對的無聲情況,因此我們實際上必須提供安靜且不相關的音頻樣本。為此,我們重復使用也混入到實際音頻片段中的_background_noise_文件夾,提取音頻數(shù)據(jù)的簡短片段,并饋送這些片段(包含實際類別標簽_silence_)。默認情況下,10% 的訓練數(shù)據(jù)是按照這種方法提供的,但可以使用--silence_percentage控制該比例。與未知字詞一樣,如果提高該比例,則模型給出的結果可能傾向于無聲的真正例,代價是字詞出現(xiàn)假負例;但如果該比例過高,則可能導致模型陷入始終猜測無聲的陷阱。
時移
為了符合實際地扭曲訓練數(shù)據(jù)以有效增加數(shù)據(jù)集的大小,進而提高整體準確率,一種方式是添加背景噪聲,而另一種方式是時移。這涉及到訓練樣本數(shù)據(jù)在時間方面的隨機偏移,以便截去開頭或結尾的一小部分,而另一部分則用零填充。這模擬了訓練數(shù)據(jù)開始時間的自然變化,并由--time_shift_ms標記控制,默認為 100 毫秒。提高該值將提供更多變化,但可能會截去音頻的重要部分。一種通過真實扭曲來增強數(shù)據(jù)的相關方法是使用時間伸縮和音調(diào)縮放,但這不在本教程的討論范圍之內(nèi)。
自定義模型
用于該腳本的默認模型非常大,每次推理需要使用超過 8 億 FLOP,并需要使用 940000 個權重參數(shù)。該模型在臺式機或新型手機上可以快速運行,但要在資源更有限的設備上快速運行,則涉及到太多計算。為了支持這些用例,可以采用幾個替代方法:
low_latency_conv基于Neural Networks for Small-footprint Keyword Spotting(小型關鍵字檢測卷積神經(jīng)網(wǎng)絡)這篇論文中介紹的 “cnn-one-fstride4” 拓撲。準確率略低于卷積神經(jīng)網(wǎng)絡,但權重參數(shù)的數(shù)量大致相同,但運行一次預測只需要 1100 萬 FLOP,提高了模型的運行速度。
要使用該模型,請在命令行上指定--model_architecture=low_latency_conv。您還需要更新訓練速率和訓練步數(shù),因此完整命令如下所示:
python tensorflow/examples/speech_commands/train --model_architecture=low_latency_conv --how_many_training_steps=20000,6000 --learning_rate=0.01,0.001
該命令要求腳本以 0.01 的學習速率訓練 20000 個訓練步,然后進行微調(diào),以原來速率的十分之一完成 6000 個訓練步。
low_latency_svdf基于Compressing Deep Neural Networks using a Rank-Constrained Topology paper(利用秩受限的拓撲壓縮深度神經(jīng)網(wǎng)絡)這篇論文中介紹的拓撲。準確率也低于卷積神經(jīng)網(wǎng)絡,但只使用大約 750000 個參數(shù),最重要的是,它允許在測試時(即您在應用中實際用到時)優(yōu)化執(zhí)行,并且需要 750000 個 FLOP。
要使用該模型,請在命令行上指定--model_architecture=low_latency_svdf,并更新訓練速率和訓練步數(shù),因此完整命令如下所示:
python tensorflow/examples/speech_commands/train --model_architecture=low_latency_svdf --how_many_training_steps=100000,35000 --learning_rate=0.01,0.005
請注意,盡管所需的訓練步數(shù)多于前兩個拓撲,但計算數(shù)量減少意味著訓練花費的時間應大致相同,并且最終得出的準確率大約為 85%。此外,您還可以通過在 SVDF 層中更改以下參數(shù)輕松地進一步調(diào)整拓撲,以便實現(xiàn)所需的計算量和準確率。
rank - 近似秩(通常越高越好,但會導致更多計算)。
num_units - 類似于其他層類型,指定層中的節(jié)點數(shù)(節(jié)點越多,效果越好,計算量也會更多)。
對于運行時,由于層允許通過緩存某些內(nèi)部神經(jīng)網(wǎng)絡激活進行優(yōu)化,因此您需要確保在凍結圖和在流式模式(例如 test_streaming_accuracy.cc)下執(zhí)行模型時使用一致的步長(例如 clip_stride_ms 標記)。
自定義其他參數(shù)
如果您想嘗試自定義模型,最好先從調(diào)整聲譜圖創(chuàng)建參數(shù)開始。這可能會更改模型的輸入圖像的大小,并且models.py中的創(chuàng)建代碼會自動調(diào)整計算和權重的數(shù)量(https://www.tensorflowers.cn/t/7516),以適應不同維度。如果您縮小輸入圖像的大小,則模型將需要更少的計算來處理輸入,這樣做可以很好地改善延遲情況,但會降低準確率。--window_stride_ms控制每個頻率分析樣本與前一個之間相隔的時間。如果增加該值,則指定時長內(nèi)的樣本就會變少,輸入的時間軸也會變短。--dct_coefficient_count標記控制用于頻率計算的分桶數(shù)量,因此降低該值會減少其他維度中的輸入。--window_size_ms參數(shù)不會影響大小,但會控制每個樣本用于計算頻率的區(qū)域?qū)挾取H绻獙ふ业穆曇魰r長很短,則縮短訓練樣本的時長(由--clip_duration_ms控制)也會有所幫助,因為這樣也會縮短輸入的時間維度。不過,您需要確保所有訓練數(shù)據(jù)都在音頻片段的初始部分包含正確的音頻。
如果您想到了一個可以解決問題的完全不同模型,您可以將其插入models.py中,并讓腳本的剩余部分處理所有預處理和訓練工作。您可以向create_model添加一個新子句,查找該模型架構的名稱,然后調(diào)用模型創(chuàng)建函數(shù)。該函數(shù)獲得聲譜圖輸入的大小以及其他模型信息,并且會創(chuàng)建 TensorFlow 操作來讀取這些信息,同時生成輸出預測向量和控制丟棄率的占位符。腳本的剩余部分負責將該模型集成到更大的圖中,該圖會執(zhí)行輸入計算,并應用 softmax 和損失函數(shù)來訓練模型。
在調(diào)整模型和訓練超參數(shù)時會遇到的一個常見問題是,可能會引入非數(shù)字值,這是由數(shù)值精確問題所致。通常,解決此問題的方式是減小學習速率等數(shù)值的大小并減少權重初始化函數(shù),但如果問題仍然存在,則可以啟用--check_nans標記來跟蹤錯誤的來源。啟用該標記后,系統(tǒng)會在 TensorFlow 中的大部分常規(guī)操作之間插入檢查操作,而且會在遇到這些錯誤時中止訓練過程并顯示實用的錯誤消息。
-
語音識別
+關注
關注
38文章
1742瀏覽量
112747
原文標題:簡單的音頻識別
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
設計一個語音識別的模塊
基于語音識別做一款能識別語音的App
一個基于語音識別的盲人上網(wǎng)輔助系統(tǒng)的設計
語音識別的應用場景
語音識別的技術歷程
情感語音識別的前世今生
情感語音識別的應用與挑戰(zhàn)
情感語音識別的挑戰(zhàn)與未來趨勢
語音識別的技術歷程及工作原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論