 Intel用3D堆疊技術為摩爾定律續命
Intel用3D堆疊技術為摩爾定律續命
過去的一年,我們在處理器市場看到了AMD的崛起和Intel的頹勢。Intel的7nm工藝遲遲沒有進展,而AMD卻搶先發布了第一款基于7nm的處理器。當然,Intel也不會坐以待斃,最近發布了基于3D堆疊芯片的新架構Foveros,在采訪中更是坦言摩爾定律還有很多空間值得挖掘。本文將分析3D堆疊架構對于Intel以及未來處理器市場的重要影響。
More Moore與More than Moore
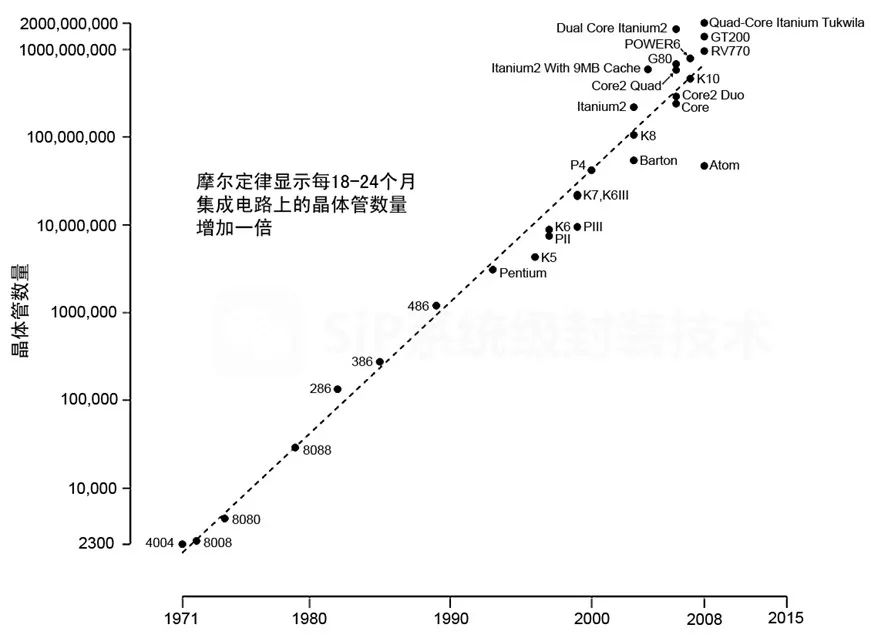
隨著摩爾定律經過數十載的發展,目前片上晶體管的尺寸已經離技術極限不遠。這意味著按照摩爾定律進一步縮減晶體管特征尺寸的難度越來越大。于是,半導體工藝下一步發展走到了十字路口。
在過去摩爾定律的黃金時期,其背后的邏輯是:半導體行業需要以一個合適的速度增長以實現利潤的最大化。隨著制程的進化,同樣的芯片的制造成本會更低,因為單位面積晶體管數量提升導致相同的芯片所需要的面積縮小。所以制程發展速度如果過慢,則意味著芯片制作成本居高不下,導致利潤無法擴大。因此,摩爾定律背后的終極推動力其實是經濟因素。同時,隨著半導體特征尺寸下降,芯片的性能也會上升,因此縮小晶體管的特征尺寸可謂是一舉兩得。
然而,隨著半導體工藝接近極限,進一步做小特征尺寸越來越貴,在16nm節點時半導體廠商紛紛引入了FinFET和multi-pattern技術,在減小特征尺寸的同時卻也大大增加了半導體工藝的成本;到了7nm又要開始引入EUV,甚至到了5nm以下的節點FinFET也不夠用了有可能需要使用更新一代的Gate-all-around器件,這又回進一步提升成本。因此,現在的新半導體工藝僅僅是在出貨量足夠大的時候才能賺回高昂的成本,這也是現在只有少部分公司有能力和決心使用最新半導體工藝的原因。換句話說,特征尺寸繼續縮小的經濟推動力在目前7nm的節點已經較小。
另一方面,甚至性能上的推動力也不如以往。之前晶體管特征尺寸每縮小一次,性能都會有接近50%的提升,而現在特征尺寸在7nm附近每次縮小帶來的性能提升已經所剩無幾,其主要改善主要來自于能效比的提升(每次晶體管特征尺寸縮小仍然能帶來40%左右的顯著能效比提升)。
在這樣的情況下,是否要進一步通過縮小晶體管特征尺寸來繼續半導體行業的發展成為了一個問題。一個方向當然是延續摩爾定律的路子繼續縮小特征尺寸(即More Moore),引入新的光刻技術,引入新的器件等等,例如三星就發布了用于3nm的Gate All-Around FET路線圖,然而隨著性能和經濟學推動力變弱,這樣的路徑還能走多遠不好說。另一個方向就是用其他的路徑來代替摩爾定律通過縮小晶體管特征尺寸實現的經濟學和性能推動力,來延續半導體行業的發展。這樣的路線就是More than Moore路線。
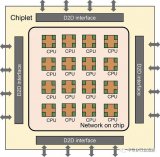
More than Moore目前的一種主流模式是通過高級封裝技術來實現。首先改變之前SoC單芯片越做越大越做越復雜的傳統思維,在More than Moore中把芯片劃分成多個不同的模塊,每個模塊分別用合適的半導體工藝實現(成為芯片粒chiplet),最后不同的chiplet再用高級封裝技術集成在同一個封裝內。Marvell提出的Mochi架構就是典型的More than Moore思路,使用不同半導體工藝的芯片粒分別實現CPU、GPU、Modem、WiFi等不同模組,不同芯片粒之間使用標準的高速接口進行通信,并封裝在同一封裝內。
在More than Moore中,經濟學的推動要素來自于使用最適合的工藝來實現不同的模塊。例如,使用成熟的28nm甚至65nm來實現模擬電路,而使用最新的7nm來實現高性能數字邏輯,其成本比起全部使用最新半導體工藝來實現所有模塊要便宜得多。而在性能方面,More than Moore的推動力則來自于新的體系架構,例如在高級封裝中可以為處理器和存儲器之間提供遠高于傳統方案的內存帶寬(HBM和HBM2),內存帶寬的提升一方面改善了系統性能,另一方面也為新的計算機體系架構設計打開了大門。總而言之,在More Moore方向中,晶體管縮小同時是成本降低和性能提高的驅動力;在More than Moore方案中,成本降低來自于芯片中不同模塊各自使用最合適的工藝,而性能提升則來自于新的電路設計。
More than Moore的高級封裝技術傳統方案主要有2.5D和3D兩種。2.5D技術是指將多塊芯片粒在硅載片(silicon interposer)上使用互聯線連接在一起,由于硅載片上的互聯線密度可以遠高于傳統PCB上的互聯線密度,因此可以實現高性能互聯。其典型的技術即TSMC推出的CoWoS,InFO以及Intel的EMIB等技術。而傳統的3DIC技術則是將多塊芯片堆疊在一起,并使用TSV技術將不同的芯片做互聯。目前,3DIC主要用在內存芯片之間的堆疊架構和傳感器的堆疊,而2.5D技術則已經廣泛應用在多款高端芯片組中。另外3D和2.5D之間也不是完全對立,例如在HBM內存中,多塊內存之間使用3DIC集成,而內存與主芯片之間則使用2.5D技術集成在一起。
Intel的3D堆疊技術:
More than Moore的新發展
Intel在高級封裝領域一直處于領先地位,之前的EMIB技術就有其獨到的優勢,而這次Intel發布的Foveros架構則是3DIC方面一個長足的進步。
Foveros架構中,芯片3D堆疊在硅載片上,并通過硅載片做互聯。Foveros進步在于其硅載片從原來的無源硅載片變成了有源硅載片。在之前的典型2.5D封裝中,硅載片上只是做互聯線供芯片之間做互聯,因此是無源硅載片。而在Foveros架構中,硅載片是有源的,即硅載片上除了互聯線(無源)之外,還包含了有源電路 。如果說傳統的2.5D封裝中的硅載片只是一種載片,那么載Foveros中的有源硅載片實際上就是一塊真正的芯片了,而這次的計算和存儲芯片是堆疊在一塊真正的芯片上,因此可以說是名副其實的3DIC。相比2.5D封裝,使用Foveros的3D封裝大大提升了集成密度,同時芯片與有源硅載片之間的IO帶寬也有潛力能做更大,從而獲得更大的性能提升。
在2019年即將發布的Foveros芯片組中,Intel計劃將一塊使用10nm工藝的高性能計算芯片粒(P1274)堆疊在一塊使用22nm工藝的有源硅載片SoC(P1222)上。22nm的硅載片上具體擁有哪些模塊還不清楚,但是預計主要的IO接口(如DDR)電路將會在這塊有源硅載片上實現,因為IO電路并不需要10nm這樣的尖端工藝,使用22nm無論是對于成本、良率還是混合電路設計難度來說都是最適合的。事實上,這也符合了More than Moore的精神,即使用最合適的半導體工藝去實現相應的模塊,從而實現成本的降低,成為半導體行業繼續演化的經濟學動力。Intel在發布會上暗示,未來可能會把混合信號電路和存儲器做在這塊有源硅載片上,這也為3DIC有源硅載片技術帶來了很大的想象空間。
事實上,Intel在12月發布的Foveros多少也是對AMD于11月發布的Rome架構處理器的回應。11月,AMD發布的Rome架構處理器也是基于高級封裝,由多塊7nm Zen2處理器芯片粒和一塊14nm 互聯和IO芯片使用2.5D技術封裝而成,其中每塊7nm Zen2芯片粒都含有8個核,而多塊芯片粒經過組合最多可以實現64核,芯片粒之間則通過14nm互聯芯片進行芯片間通信。AMD Rome和Intel Foveros使用芯片粒加高級封裝的基本思路如出一轍,但是Intel Foveros使用了3D封裝而AMD Rome使用的是2.5D,因此在封裝技術上Intel更勝一步,至于Intel 3D封裝帶來的性能提升是否能抵消AMD使用7nm領先半導體工藝的優勢,我們不妨拭目以待。從另一個角度來看,事實上使用More than Moore高級封裝技術已經成為了半導體行業旗艦公司的共識,未來可望從高端處理器芯片慢慢普及到更多芯片品類。
More than Moore能走多遠
Intel的Foveros是More than Moore高級封裝技術的最新發展,其使用的3D堆疊技術相較于之前的2.5D技術可謂是一大進步。然而,在把2.5D變為3D之后,More than Moore接下來的路又該怎么走?在之前的摩爾定律時代,只要縮小特征尺寸即可;而在More than Moore時代,又該如何繼續挖掘潛力以延續摩爾定律的輝煌呢?
我們認為, 現在半導體行業采用More than Moore的主要目的首先是為了提升性能,而非提高集成度以降低成本。芯片行業經過了數十年的發展,已經早已成為了大量新技術的基石:移動通信、多媒體、人工智能、區塊鏈等等對于社會擁有強大驅動力的技術無一不以高性能芯片為基礎。這些新技術應用對于芯片性能提升的需求遠遠大于芯片成本降低的需求。這也是為什么去年AMD搶先使用7nm對Intel造成巨大影響的原因,因為7nm新工藝意味著更強大的性能(而非更低的成本)。事實上,這次Intel推出的Foveros的部分原因也是希望其高性能10nm處理器能盡快量產,而僅僅把核心邏輯電路部分用10nm工藝實現而其他部分用成熟的22nm工藝做顯然能改善整體芯片組的良率,從而讓高性能芯片組早日進入商用。總之,將來半導體先進工藝的進化動力將主要來自于性能提升而非成本降低。
那么,More than Moore對于性能的提升主要來自于哪里呢?除了之前說的可以降低使用最先進半導體工藝芯片粒的面積以提升良率,從而加快新工藝芯片上市速度間接提升性能之外,更主要的性能提升空間來自于封裝技術本身的性能提升以及芯片新架構帶來的性能提升。
從高級封裝技術本身來說,其主要的性能提升主要是指更高密度、支持更高頻率信號的互聯線,以及更復雜的堆疊模式。互聯線方面的提升帶來的最直觀性能改善來自于更高芯片之間(包括處理器與內存)的通信帶寬。在高級封裝出現之前,芯片間通信的帶寬往往取決于PCB板上走線的密度以及其走線支持的信號頻率,而PCB板這里是摩爾定律管不到的地方。2000年第一代DDR推出時的接口頻率是100MHz,而到2015年未使用高級封裝的DDR4 的接口頻率是1200MHz,內存帶寬在15年間僅上升12倍,這遠遠小于處理器的性能提升速度,因此內存帶寬事實上成為了系統性能的瓶頸,即所謂的“內存墻”。而當基于高級封裝的HBM出現時,一下將內存帶寬由DDR4時代的19.2GB/s提升到了128GB/s,HBM2更是提升到了256GB/s,可謂是質的提升。HBM帶來的性能提升主要來自于高級封裝優質的互聯線,一方面走線密度大大提升,之前DDR系列的借口寬度為64,而HBM則提升到了1024;
另一方面由于高級封裝走線對于高頻信號的支持遠好于傳統PCB,因此未來有更大的潛力能繼續提升芯片間的通信速度,從而讓“內存墻”問題不復存在。在堆疊模式方面,我們看到了Foveros從2.5D進化到了3D,未來可望還能實現更多層次的堆疊等。然而,新的堆疊工藝開發難度遠高于高級封裝內走線密度的提升,因此我們在未來幾年內更有希望看到的是使用高級封裝技術帶來的更方便靈活同時也速度更高的芯片間通信。
除了高級封裝本身帶來的直接性能提升,More than Moore在未來對于芯片的性能提升潛力來自于新的處理器架構設計。事實上,學術界和業界在新的處理器架構上的研究已經有非常多的積累,但是由于標準CMOS工藝的各種考量一直沒有商業化,而隨著More than Moore高級封裝技術的到來,這些研究都可望能實用化,從而成為半導體行業的重要驅動力。例如,眾核架構之前已經研究了很久,但是以往的技術在實施眾核架構時會遇到各種實際的問題。如果把眾核集成在一塊芯片上,則芯片面積可能過大而導致良率問題;如果把眾核封裝成不同的芯片,則芯片間通信的開銷會過大。現在隨著高級封裝技術的來臨,可以把眾核做成多個芯片粒,并用硅載片上的高速總線進行芯片間通信,從而充分發揮眾核架構的設計優勢。
事實上,我們看到AMD Rome使用多個芯片粒組合成64核處理器正是一個印證。除了眾核芯片之外,各種新存儲器也將從More than Moore路線中獲益。新存儲器,如MRAM,ReRAM等,能提供很高的存儲密度和很低的訪問延遲,但是因為需要特殊工藝因此很難直接集成到使用最新半導體工藝的SoC上,這也是之前新存儲器商用化較慢的一個原因。現在有了高級封裝則無需再擔心工藝的兼容性問題,而是完全可以把SoC和存儲器做成不同的芯片粒,然后用硅載片連接到一起。這樣同一封裝內的新存儲器可以作為新的大容量緩存單元,從而提升處理器的性能。最后,More than Moore和目前流行的異構計算相結合也能獲得良好的效果:異構計算主張把不同的計算使用專用化的計算處理單元來完成以實現高性能高效率計算,而More than Moore路線則可以把異構計算中使用到的專用計算處理單元用合適工藝的芯片粒實現,然后用高級封裝技術實現互聯和封裝。這樣通過類似樂高積木一樣組合不同的專用化處理模組芯片粒,就可以快速而高效地設計出高性能專用芯片模組。
綜上,結合高級封裝技術本身的技術提升,More than Moore路線開啟的新架構設計以及異構計算的新設計理念和設計生態,我們預計在未來處理器至少還能實現10倍以上性能提升。而且,在More than Moore時代,芯片性能提升中,設計師的重要性大大提升,因此未來將是芯片設計的好時代。
-
摩爾定律
+關注
關注
4文章
634瀏覽量
79060 -
intel
+關注
關注
19文章
3482瀏覽量
186051
原文標題:Intel的3D堆疊能否為摩爾定律續命?
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
擊碎摩爾定律!英偉達和AMD將一年一款新品,均提及HBM和先進封裝

3D打印技術,推動手板打樣從概念到成品的高效轉化


高算力AI芯片主張“超越摩爾”,Chiplet與先進封裝技術迎百家爭鳴時代

裸眼3D筆記本電腦——先進的光場裸眼3D技術
“自我實現的預言”摩爾定律,如何繼續引領創新
SK海力士5層堆疊3D DRAM制造良率已達56.1%
VIVERSE 推行實時3D渲染: 探索Polygon Streaming技術力量與應用
封裝技術會成為摩爾定律的未來嗎?

功能密度定律是否能替代摩爾定律?摩爾定律和功能密度定律比較
三星將推出GDDR7產品及280層堆疊的3D QLC NAND技術
摩爾定律的終結:芯片產業的下一個勝者法則是什么?

Chiplet技術對英特爾和臺積電有哪些影響呢?

中國團隊公開“Big Chip”架構能終結摩爾定律?





 工商網監
工商網監
評論