 編譯器原理到底是怎樣的帶你簡單的了解編譯器原理
編譯器原理到底是怎樣的帶你簡單的了解編譯器原理
編程語言是怎樣工作的
理解編譯器內部原理,可以讓你更高效利用它。按照編譯的工作順序,逐步深入編程語言和編譯器是怎樣工作的。本文有大量的鏈接、樣例代碼和圖表幫助你理解編譯器。
作者注:
這是我在 Medium 上的第二篇文章的再版,上一版有超過 21000 的閱讀量。很高興我能夠幫助到各位的學習,因此我根據上一版的評論,完完全全重寫了。
我選擇 Rust 作為這篇文章的主要語言。它是一種詳盡的、高效的、現代的而且看起來特意使得設計編譯器變得簡單。我很喜歡使用它。
寫這篇文章的目的主要是吸引讀者的注意力,而不是提供 20 多頁的令人頭皮發麻的閱讀材料。對于那些你感興趣的更深層次的話題,文章中有許多鏈接會引導你找到相關的資料。大多數鏈接到維基百科 。
感謝你的關注,我希望你能夠喜歡這些我花費了超過 20 個小時的寫出的文章。歡迎在文章底部評論處留下任何問題或者建議。
簡單介紹
編譯器是什么?
你口中所說的編程語言本質上只是一個軟件,這個軟件叫做編譯器,編譯器讀入一個文本文件,經過大量的處理,最終產生一個二進制文件。編譯器的語言部分就是它處理的文本樣式。因為電腦只能讀取 1 和 0 ,而人們編寫 Rust 程序要比直接編寫二進制程序簡單地多,因此編譯器就被用來把人類可讀的文本轉換成計算機可識別的機器碼。
編譯器可以是任何可以把文本文件轉換成其他文件的程序。例如,下面有一個用 Rust 語言寫的編譯器把 0 轉換成 1,把 1 轉換成 0 :
// An example compiler that turns 0s into 1s, and 1s into 0s.
fn main(){
let input = "1 0 1 A 1 0 1 3";
// iterate over every character `c` in input
let output: String = input.chars().map(|c|
ifc == '1'{'0'}
elseifc == '0'{'1'}
else{c}// if not 0 or 1, leave it alone
).collect();
println!("{}",output);// 0 1 0 A 0 1 0 3
}
編譯器是做什么的?
簡言之,編譯器獲取源代碼,產生一個二進制文件。因為從復雜的、人類可讀的代碼直接轉化成0/1二進制會很復雜,所以編譯器在產生可運行程序之前有多個步驟:
從你給定的源代碼中讀取單個詞。
把這些詞按照單詞、數字、符號、運算符進行分類。
通過模式匹配從分好類的單詞中找出運算符,明確這些運算符想進行的運算,然后產生一個運算符的樹(表達式樹)。
最后一步遍歷表達式樹中的所有運算符,產生相應的二進制數據。
盡管我說編譯器直接從表達式樹轉換到二進制,但實際上它會產生匯編代碼,之后匯編代碼會被匯編/編譯到二進制數據。匯編程序就好比是一種高級的、人類可讀的二進制。
解釋器是什么?
解釋器非常像編譯器,它也是讀入編程語言的代碼,然后處理這些代碼。盡管如此,解釋器會跳過了代碼生成,然后即時編譯并執行 AST。解釋器最大的優點就在于在你 debug 期間運行程序所消耗的時間。編譯器編譯一個程序可能在一秒到幾分鐘不等,然而解釋器可以立即開始執行程序,而不必編譯。解釋器最大的缺點在于它必須安裝在用戶電腦上,程序才可以執行。
雖然這篇文章主要是關于編譯器的,但是對于編譯器和解釋器之間的區別和編譯器相關的內容一定要弄清楚。
1. 詞法分析
第一步是把輸入一個詞一個詞的拆分開。這一步被叫做詞法分析,或者說是分詞。這一步的關鍵就在于我們把字符組合成我們需要的單詞、標識符、符號等等。詞法分析大多都不需要處理邏輯運算像是算出2+2– 其實這個表達式只有三種標記:一個數字:2,一個加號,另外一個數字:2。
讓我們假設你正在解析一個像是12+3這樣的字符串:它會讀入字符1,2,+,和3。我們已經把這些字符拆分開了,但是現在我們必須把他們組合起來;這是分詞器的主要任務之一。舉個例子,我們得到了兩個單獨的字符1和2,但是我們需要把它們放到一起,然后把它們解析成為一個整數。至于+也需要被識別為加號,而不是它的字符值 – 字符值是43 。
如果你可以閱讀過上面的代碼,并且弄懂了這樣做的含義,接下來的 Rust 分詞器會組合數字為32位整數,加號就最后了標記值 Plus(加).
https://play.rust-lang.org/?gist=070c3b6b985098a306c62881d7f2f82c&version=stable&mode=debug&edition=2015
你可以點擊 Rust playgroud 左上角的 “Run” 按鈕來編譯和執行你瀏覽器中的代碼。
在一種編程語言的編譯器中,詞法解析器可能需要許多不同類型的標記。例如:符號,數字,標識符,字符串,操作符等。想知道要從源文件中提取怎樣的標記完全取決于編程語言本身。
intmain(){
inta;
intb;
a = b = 4;
returna - b;
}
Scanner production:
[Keyword(Int),Id("main"),Symbol(LParen),Symbol(RParen),Symbol(LBrace),Keyword(Int),Id("a"),Symbol(Semicolon),Keyword(Int),Id("b"),Symbol(Semicolon),Id("a"),Operator(Assignment),Id("b"),
Operator(Assignment),Integer(4),Symbol(Semicolon),Keyword(Return),Id("a"),Operator(Minus),Id("b"),Symbol(Semicolon),Symbol(RBrace)]
C 語言的樣例代碼已經進行過詞法分析,并且輸出了它的標記。
2. 解析
解析器確實是語法解析的核心。解析器提取由詞法分析器產生的標記,并嘗試判斷它們是否符合特定的模式,然后把這些模式與函數調用,變量調用,數學運算之類的表達式關聯起來。 解析器逐詞地定義編程語言的語法。
int a = 3 和 a: int = 3 的區別在于解析器的處理上面。解析器決定了語法的外在形式是怎樣的。它確保括號和花括號的左右括號是數量平衡的,每個語句結尾都有一個分號,每個函數都有一個名稱。當標記不符合預期的模式時,解析器就會知道標記的順序不正確。
你可以寫好幾種不同類型的解析器。最常見的解析器之一是從上到下的,遞歸降解的解析器。遞歸降解的解析器是用起來最簡單也是最容易理解的解析器。我寫的所有解析器樣例都是基于遞歸降解的。
解析器解析的語法可以使用一種 語法 表示出來。像 EBNF 這樣的語法就可以描述一個解析器用于解析簡單的數學運算,像是這樣 12+3 :
expr = additive_expr;
additive_expr = term,('+' | '-'),term;
term = number;
簡單加法和減法表達式的 EBNF 語法。
請記住語法文件并不是解析器,但是它確實是解析器的一種表達形式。你可以圍繞上面的語法創建一個解析器。語法文件可以被人使用并且比起直接閱讀和理解解析器的代碼要簡單許多。
那種語法的解析器應該是expr解析器,因為它直接與所有內容都相關的頂層。唯一有效的輸入必須是任意數字,加號或減號,任意數字。expr需要一個additive_expr,這主要出現在加法和減法表達式中。additive_expr首先需要一個term(一個數字),然后是加號或者減號,最后是另一個term。
解析 12+3 產生的樣例 AST
解析器在解析時產生的樹狀結構被稱為抽象的語法樹,或者稱之為 AST。ast 中包含了所有要進行操作。解析器不會計算這些操作,它只是以正確的順序來收集其中的標記。
我之前補充了我們的詞法分析器代碼,以便它與我們的語法想匹配,并且可以產生像圖表一樣的 AST。我用// BEGIN PARSER //和// END PARSER //的注釋標記出了新的解析器代碼的開頭和結尾。
https://play.rust-lang.org/?gist=205deadb23dbc814912185cec8148fcf&version=stable&mode=debug&edition=2015
我們可以再深入一點。假設我們想要支持只有數字沒有運算符的輸入,或者添加除法和乘法,甚至添加優先級。只要簡單地修改一下語法文件,這些都是完全有可能的,任何調整都會直接反映在我們的解析器代碼中。
expr = additive_expr;
additive_expr = multiplicative_expr,{('+' | '-'),multiplicative_expr};
multiplicative_expr = term,{("*" | "/"),term};
term = number;
新的語法。
https://play.rust-lang.org/?gist=1587a5dd6109f70cafe68818a8c1a883&version=nightly&mode=debug&edition=2018
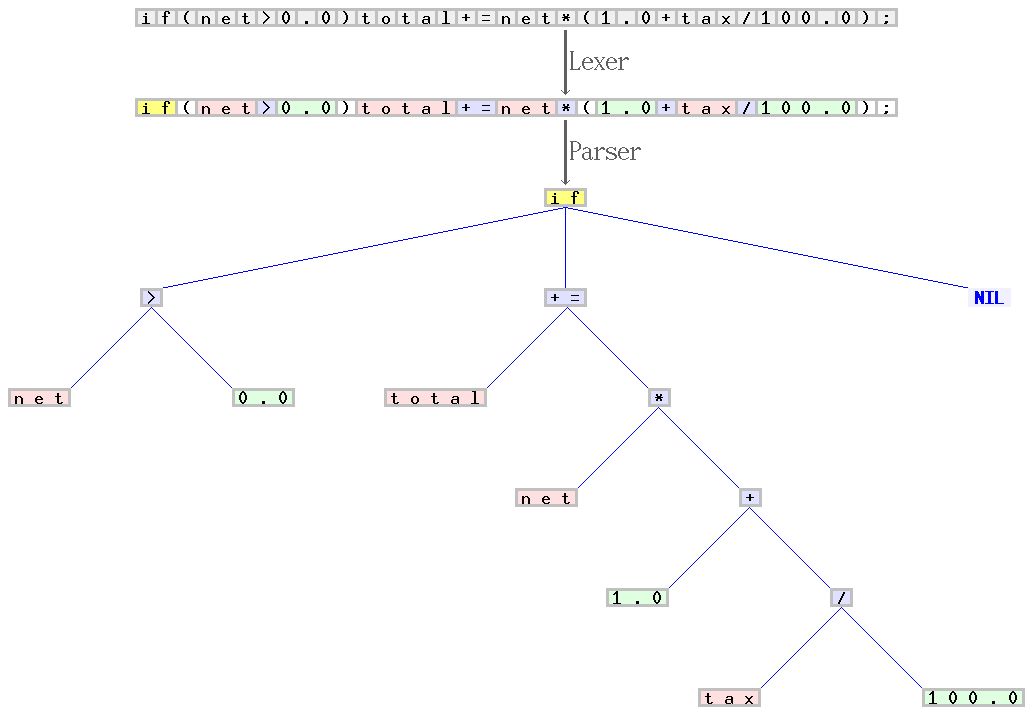
針對 C 語言語法編寫的解析器(又叫做詞法分析器)和解析器樣例。從字符序列的開始 “if(net>0.0)total+=net(1.0+tax/100.0);”,掃描器組成了一系列標記,并且對它們進行分類,例如,標識符,保留字,數字,或者運算符。后者的序列由解析器轉換成語法樹,然后由其他的編譯器分階段進行處理。掃描器和解析器分別處理 C 語法中的規則和與上下文無關的部分。引自:Jochen Burghardt.來源.
3. 生成代碼
代碼生成器接收一個 AST ,然后生成相應的代碼或者匯編代碼。代碼生成器必須以遞歸下降的順序遍歷AST中的所有內容-就像是解析器的工作方式一樣-之后生成相應的內容,只不過這里生成的不再是語法樹,而是代碼了。
https://godbolt.org/z/K8416_
如果打開上面的鏈接,你就可以看到左側樣例代碼產生的匯編代碼。匯編代碼的第三行和第四行展示了編譯器在AST中遇到常量的時候是怎樣為這些常量生成相應的代碼的。
Godbolt Compiler Explorer 是一個很棒的工具,允許你用高級語言編寫代碼,并查看它產生的匯編代碼。你可以有點暈頭轉向了,想知道產生的是哪種代碼,但不要忘記給你的編程語言編譯器添加優化選項來看看它到底有多智能。(對于 Rust 是-O)
如果你對于編譯器是在匯編語言中怎樣把一個本地變量保存到內存中感興趣的話,這篇文章(“代碼生成”部分)非常詳細地解釋了堆棧的相關知識。大多數情況下,當變量不是本地變量的時候,高級編譯器會在堆區為變量分配空間,并把它們保存到堆區,而不是棧區。你可以從這個 StackOverflow 的回答上閱讀更多關于變量存儲的內容。
因為匯編是一個完全不同的,而且復雜的主題,因此這里我不會過多地討論它。我只是想強調代碼生成器的重要性和它的作用。此外,代碼生成器不僅可以產生匯編代碼。Haxe編譯器有一個可以產生 6 種以上不同的編程語言的后端:包括 C++,Java,和 Python。
后端指的是編譯器的代碼生成器或者表達式解析器;因此前端是詞法分析器和解析器。同樣也有一個中間端,它通常與優化和 IR 有關,這部分會在稍后解釋。后端通常與前端無關,后端只關心它接收到的 AST。這意味著可以為幾種不同的前端或者語言重用相同的后端。大名鼎鼎的GNU Compiler Collection就屬于這種情況。
我找不到比我的 C 編譯器后端更好的代碼生成器示例了。
在生成匯編代碼之后,這些匯編代碼會被寫入到一個新的匯編文件中 (.s或.asm)。然后該文件會被傳遞給匯編器,匯編器是匯編語言的編譯器,它會生成相應的二進制代碼。之后這些二進制代碼會被寫入到一個新的目標文件中 (.o) 。
目標文件是機器碼,但是它們并不可以被執行。為了讓它們變成可執行文件,目標文件需要被鏈接到一起。鏈接器讀取通用的機器碼,然后使它變為一個可執行文件、共享庫或是靜態庫。
鏈接器是因操作系統而不同的應用程序。隨便一個第三方的鏈接器都應該可以編譯你后端產生的目標代碼。因此在寫編譯器的時候不需要創建你自己的鏈接器。
編譯器可能有中間表示,或者簡稱 IR 。IR 主要是為了在優化或者翻譯成另一門語言的時候,無損地表示原來的指令。IR 不再是原來的代碼;IR 是為了尋找代碼中潛在的優化而進行的無損簡化。循環展開和向量化都是利用 IR 完成的。
總結
當你理解了編譯器的時候,你就可以更有效地使用你的編程語言。或許有一天你會對創建你自己的編程語言感興趣?我希望這能夠幫到你。
-
二進制
+關注
關注
2文章
795瀏覽量
41697 -
C語言
+關注
關注
180文章
7610瀏覽量
137221 -
編譯器
+關注
關注
1文章
1637瀏覽量
49191
原文標題:人人都能讀懂的編譯器原理
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
編譯器是如何工作的_編譯器的工作過程詳解
深入編程語言和編譯器是怎樣工作的
編譯器對芯片行業到底有什么意義
Verilog HDL 編譯器指令說明

交叉編譯器安裝教程
編譯器的優化選項





 工商網監
工商網監
評論