") 2018年,機器學習和人工智能領域最重要的突破是什么?
2018年,機器學習和人工智能領域最重要的突破是什么?
2018年,人工智能發(fā)展到什么階段了?Quora鼎鼎有名的大V認為,AI炒作和AI威脅論在今年都降溫,并且不會有AI寒冬,升溫的是各種開源框架,2019年的AI,你認為會是怎樣?
2018年,機器學習和人工智能領域最重要的突破是什么?
(這里給你留出充分思考的時間。)
看看其他的觀點。
之前,KDnuggets邀請了11位來自工業(yè)、學術和技術一線人員,回顧2018年AI的進展。其中,呼吁阻止AI學術頂會向商業(yè)化淪陷的CMU助理教授Zachary C. Lipton認為,2018年 (深度學習) 最大的進展就是沒有進展。
最近,Forbes則采訪了120位AI行業(yè)的創(chuàng)始人和高管,在2018年AI技術和產業(yè)現狀的基礎上,對2019年進行展望,提出了120個預測。(里面有讓你覺得英雄所見略同的看法嗎?)
與往年一樣,Quora鼎鼎有名的大V、機器學習研究者、前Quora工程負責人Xavier Amatriain,也寫下了他認為2018年機器學習和人工智能領域最大的進展:
AI炒作和AI威脅論都有所降溫;
越來越多的人開始關注公平性、可解釋性或因果關系等問題;
深度學習不會再遇到寒冬,并且在圖像分類以外(尤其是自然語言處理)領域投入實用并產生效益;
AI框架方面的競爭正在升溫,要是你想做出點事情,最好發(fā)表幾個你自己的框架。
一起來看看。
深度學習寒冬不會到來,2018對AI的期望和恐懼都下降了
正如Xavier Amatriain說的那樣,深度學習的寒冬不會到來——這項技術已經用到產業(yè)里并帶來了收益,現實讓人們收起了一部分對AI的期望和恐懼,業(yè)界開始思考數據的公平性、模型的可解釋性等更本質的問題。
如果說2017年是人工智能炒作和威脅論的風口浪尖,那么2018似乎是我們開始冷靜下來的一年。
雖然馬斯克等人確實還在繼續(xù)強調他們對人工智能的恐懼,但他們可能忙于處理其他事務而無暇顧及這個議題。
與此同時,媒體和公眾看來也都意識到,雖然自動駕駛汽車和類似的技術在推進,但不會很快到來。不過,仍然有聲音支持對AI本身進行管制,Xavier Amatriain認為這種觀點是錯誤的,真正該管制的是AI所造成的結果。
深度學習:可解釋性得到更多關注,NLP迎來ImageNet時刻
關于AI炒作和AI威脅論的降溫實際上前面已經說過了,Xavier Amatriain表示他很高興看到今年的重點似乎已經轉移到去解決更具體的問題上面。
例如,業(yè)內圍繞公平性 (fairness)展開了大量的討論,不僅舉辦了多個相關主題的會議 (比如FATML、ACM FAT),甚至還出現了一些在線課程。
ACM FAT會議,2019年1月底在美國召開
關于可解釋性 (interpretability)、對算法或模型的理解 (explanation)和因果關系 (causality)。后者重新成為人們關注的焦點,主要是因為Judea Pearl出版了“The Book of Why”這本書。關于推薦系統的ACM Recsys會議,最佳論文獎也頒給了一篇討論如何在嵌入中包含因果關系的論文 (Causal Embeddings for Recommendations)。
話雖如此,許多其他作者認為,因果關系在某種程度上是對深度學習理論的干擾,我們應該再次關注更具體的問題,比如 interpretability 或 explanation。說到 Explanation,這個領域的亮點之一可能是華盛頓大學 Marco Tulio Ribeiro等人發(fā)表的 Anchor論文和代碼,這他們對自己提出的著名模型LIME的改進。
雖然關于深度學習是最通用的AI范例這一點,仍然存在許多疑問(提問者算我一個);雖然Yann LeCun和Gary Marcus兩人已經是第n次爭論這個問題,但很明顯,深度學習不僅僅停留于此。
在這一年里,深度學習方法在視覺以外的領域,包括語言、醫(yī)療、教育等領域取得了前所未有的成功。尤其是教育方面,國內國外的自適應學習(Adaptive Learning) 都愈發(fā)火熱,以中國的松鼠AI (乂學教育) 為代表的個性化自適應教學平臺,甚至請到了“機器學習教父”Tom Mitchell出任首席科學家。
事實上,在NLP領域,我們看到了今年最引人注目的進展。如果讓我必須選擇今年最令人印象深刻的AI應用程序,那么我的選擇都來自NLP領域(而且都來自谷歌)。第一個是谷歌的超級有用的Smart Compose智能撰寫郵件工具,第二個是Duplex對話系統。
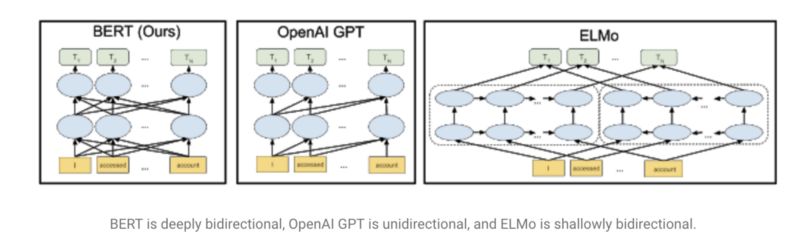
使用語言模型的想法加速了NLP的進步,這個想法在今年由Fast.ai的UMLFit推廣起來。接著,我們看到了其他(改進的)方法,如艾倫研究所的ELMO,Open AI的transformers,以及最近谷歌發(fā)布的BERT,它在許多任務上擊敗了此前的SOTA結果。這些模型被描述為“NLP的ImageNet時刻”,因為它們提供了隨時可用的預訓練通用模型,也可以對特定任務進行微調。
除了語言模型之外,還有許多其他有趣的改進,比如facebook的多語言嵌入。值得注意的是,我們還看到這些方法和其他方法是如何迅速地集成到更一般的NLP框架中,比如AllenNLP或Zalando的FLAIR。
生態(tài):AI框架戰(zhàn)升溫,要出成績你最好發(fā)表幾個自己的框架
說到框架,今年的“AI框架戰(zhàn)爭”可謂愈演愈烈。令人驚訝的是,隨著Pytorch 1.0的發(fā)布,Pytorch似乎正在趕上TensorFlow。
雖然在生產中使用Pytorch的情況仍然不夠理想,但是Pytorch在這方面的進展似乎比TensorFlow在可用性、文檔和教育方面的進展要快。有趣的是,選擇Pytorch作為實現Fast.ai library的框架很可能起了重要作用。
話雖如此,谷歌已經意識到了這一切,并正在朝著正確的方向推進,例如將Keras納入框架。最后,我們都能從所有這些偉大的資源中獲益,所以請繼續(xù)迎接它們的到來吧!
pytorch 與 tensorflow 的搜索趨勢
在框架空間中,另一個進展很快的是強化學習。
雖然我認為RL的研究進展并不像前幾年那樣令人印象深刻 (浮現在我腦海中的只有DeepMind最近的Impala工作),但令人驚訝的是,在一年時間里,我們看到所有主要AI玩家都發(fā)布了RL框架。
谷歌發(fā)布了用于研究的Dopamine框架,Deepmind發(fā)布了某種程度上與Dopamine競爭的TRFL框架。Facebook不甘落后,發(fā)布了Horizon,而微軟發(fā)布了TextWorld,后者更專門用于訓練基于文本的智能體。希望2019年所有這些開源的優(yōu)勢能夠幫助RL領域取得更多進步。
最后,我很高興看到谷歌最近在TensorFlow之上發(fā)布了TFRank。 Ranking是一個非常重要的ML應用。
數據:用合成數據訓練DL模型
深度學習似乎最終消除了對數據的智能需求,但事實遠非如此。
圍繞著改進數據的想法,該領域仍有一些非常有趣的進展。例如,雖然數據增強已經存在了一段時間,并且對于許多DL應用程序來說是關鍵,但谷歌今年發(fā)布了AutoAugment,這是一種深度強化學習方法,可以自動增強訓練數據。
一個更極端的想法是用合成數據訓練DL模型。這已經在實踐中嘗試了一段時間,被許多人視為AI未來的關鍵。NVidia在Training Deep Networks with Synthetic Data這篇論文中提出了有趣的新穎想法。在“Learning from the experts”這篇論文中,我們還展示了如何使用專家系統來生成合成數據,然后將合成數據與實際數據相結合,使用這些數據來訓練DL系統。
最后,還有一個有趣的想法,即使用“弱監(jiān)督”來減少對大量手工標記數據的需求。Snorkel是一個非常有趣的項目,旨在通過提供一個通用框架來促進這種方法。
基礎理論:AI沒有太多基礎性突破?
我并沒有看到太多AI更基礎性的突破。我并不完全同意Hinton的觀點,他說這種創(chuàng)新的缺乏是由于該領域“資深人士太少,年輕人太多”,盡管在科學上確實存在這樣的趨勢,即突破性研究經常是在更老的年紀完成的。
在我看來,目前缺乏突破的主要原因是,現有方法和變體仍然有許多有效的實際應用,所以很難冒險采用那些可能不太實際的方法。當該領域的大部分研究由大公司贊助時,這一點就更加重要了。
這方面,今年有一篇有趣的論文挑戰(zhàn)了某些假設,題為“對用于序列建模的一般卷積和遞歸網絡的經驗評估”(An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling)。在高度經驗主義和使用已知方法的同時,這篇論文打開了發(fā)現新方法的大門,因為它證明了通常被認為是最優(yōu)的方法實際上并不是最優(yōu)。
需要明確的是,我不同意Bored Yann LeCun的觀點,他認為卷積網絡是最終的“終極算法”(master algorithm),而且我認為RNN也不是。
即使是序列建模,也有很大的研究空間!另一篇具有高度探索性的論文是最近的NeurIPS最佳論文“Neural Ordinary Differential Equations”,它挑戰(zhàn)了DL中的一些基本內容,包括layers本身的概念。
2018年,機器學習和人工智能的發(fā)展卡在了數據集上面
在 Xavier Amatriain 的觀點之后,新智元也補充一點:
2018年,機器學習和人工智能的進展卡在了數據集上面。
為什么這么說?
昨天,創(chuàng)業(yè)公司Graphext在Reddit上發(fā)帖,公布了他們對2018年Reddit網站Machine Learning內容分類里2509條帖子聚類分析的結果 (點擊“閱讀原文”查看大圖):
(Reddit上) 人們最關心的話題 (占比20%) 是數據集,包括訓練數據,大規(guī)模數據集,開源,新的數據、模型、樣本等等;其次是研究論文 (占比18%),包括復現結果、Kaggle競賽和谷歌、FB的工作;再次是訓練 (占比16%)。
Graphext對2018年Reddit機器學習帖子聚類結果:最受關注的是數據
雖是一家之言,但這個聚類結果也在一定程度上反映了當前機器學習和人工智能從業(yè)者的關注點——數據!大數據!開源大數據!
也難怪作為學者的Zachary Lipton要說,2018年深度學習最大的進展就是沒有進展——我們仍舊在依靠大數據,手握大數據和大算力的谷歌、FB等巨頭最容易出成果,而迫切復現其算法和模型的其他機器學習工程師則關注訓練的問題。
-
人工智能
+關注
關注
1791文章
47294瀏覽量
238578 -
機器學習
+關注
關注
66文章
8419瀏覽量
132675 -
深度學習
+關注
關注
73文章
5503瀏覽量
121182
原文標題:2018機器學習和AI最大突破沒找到,但我發(fā)現了最大障礙!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論