") 阿里巴巴選擇什么作為AI算法研究環(huán)境
阿里巴巴選擇什么作為AI算法研究環(huán)境
我是來自阿里巴巴認知計算實驗室的龍海濤,今天主要跟大家聊一下“《星際爭霸》與人工智能”的話題。首先我會介紹一下為什么我們會選擇《星際爭霸》這個游戲來做人工智能前沿性的研究,然后是我們在這方面初步的嘗試和成果,最后我會跟大家探討一下,未來我們在《星際爭霸》這個游戲里面還可以繼續(xù)去研究的一些課題。
為什么選擇《星際爭霸》作為人工智能算法研究的環(huán)境
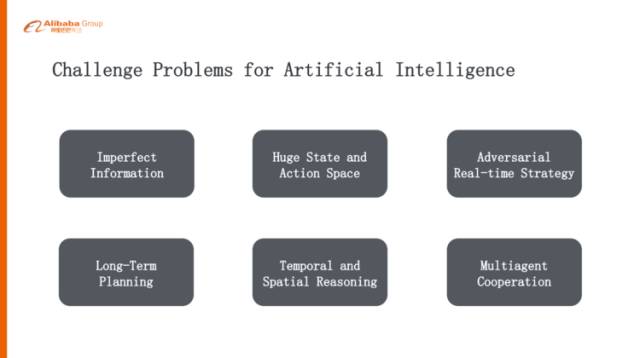
首先可能大家有疑問,為什么選擇《星際爭霸》這個游戲來做我們AI研究的一個平臺。我們這個認知計算實驗室目前是掛靠在搜索事業(yè)部下面,我們團隊的成員基本都是做搜索、廣告、推薦、算法這樣的背景,之前我們主要做的是CTR預估的優(yōu)化,還有CVR轉化率的一些優(yōu)化,從去年“雙11”之后,我們想在認知智能方面做一些前沿性的探索,我們一致認為游戲是一個研究AI算法的絕佳平臺,首先它是非常干凈的平臺,可以源源不斷的去產生數(shù)據(jù),而且迭代非常快,就是說它的智能是可以觀測到的。另外,它離真實的場景和應用是比較近的,并且《星際爭霸》十多年來就是一個非常好的受大家歡迎的游戲,積累了非常非常多的數(shù)據(jù),這樣我們可以從之前的經驗去學習,這也是我們考慮的一個方面。最重要的,它對AI來講存在著非常大的挑戰(zhàn),非常復雜,主要有以下六點:
第一點,它是一個不完全信息下的環(huán)境
比起像圍棋或者象棋這種大家都可能看得見的、完全信息下的博弈,《星際爭霸》是有戰(zhàn)爭迷霧的,所以必須去探路、偵查、了解對手的信息,從而在不確定的情況下去做智能的決策,這個是相對其他游戲來講非常不同或者挑戰(zhàn)更大的一個方面。
第二點,它有非常巨大的搜索空間
圍棋的搜索空間大概在10^170,《星際爭霸》在128×128的地圖上并且人口上限是400個unit的情況下,它的搜索空間大概在10^1685,比圍棋高10個數(shù)量級,這還是在沒有算上其他狀態(tài)(比如說血量等等)的情況下。所以現(xiàn)有的任意一個單一的算法是根本不可能解決《星際爭霸》里面所有的問題的。
第三點,它是一個即時對抗類的游戲
下圍棋可以有一分鐘或者兩分鐘的思考時間,但是在《星際爭霸》里,如果說正常游戲大概是1秒鐘24幀,那么你必須在42毫秒之內做出迅速的反應,而且這個反應不是一個action,而是一系列的action,每個unit都會采取行動,這對我們算法的性能、效率、工程上的考慮都是非常大的挑戰(zhàn)。
第四點,它需要智能體有一個長期的規(guī)劃
不是一個下意識的動作,是需要有記憶,需要考慮這場戰(zhàn)爭應該采取什么樣的策略,中盤應該怎么考慮,發(fā)展到后期又應該采取什么樣的策略,而且這個策略的計劃是根據(jù)偵查到的所有的信息動態(tài)去調整,這對人工智能的挑戰(zhàn)是非常非常大的。
第五點,時間、空間上的推理
在《星際爭霸》里面要玩好的話,必須基于時序上、空間上去做推理,比如說地理位置的優(yōu)勢,坦克如果架在哪里可能會比較好,如果開分機在哪個位置去開會比較有利,甚至于軍營造在什么地方,這些對于AI來說都需要進行一個空間上的推理。
第六點,多個智能體協(xié)作
《星際爭霸》最高有400個unit,所以其實是需要多個智能體協(xié)作的,需要多個兵種去配合,這也是對AI來講一個很大的挑戰(zhàn)。

《星際爭霸》里面AI的研究或者競賽不是最近才出現(xiàn)的,其實在2010年的時候已經有大量的研究人員在研究《星際爭霸》里面的AI,主要是以ALBERTA大學為主的研究力量,包括一些老師和學生,而且有三個固定的競賽和一些循環(huán)賽,大家在上面PK。這一類AI的話是Classic AI,也就是沒有學習能力、沒有模型、也不需要訓練,而是基于預編程的規(guī)則,所以不是非常靈活,這種算法下的AI其實離真正超過人類或者打敗人類目標還是非常非常遠的,它們可以打敗內置的AI,但是還遠遠比不上人類的專業(yè)選手,甚至連普通選手基本上也打不過。
另外一類是Modern AI,也就是以智能體自主學習為主的算法,從去年開始這個領域火起來了,一方面就是,阿里巴巴還有倫敦大學學院,最近我們在合作的基于《星際爭霸1》里面做一些新的AI的嘗試。
另外就是Google Deep Mind,去年11月份他們和暴雪合作,會基于《星際爭霸2》去開放一個API,讓大家基于《星際爭霸2》上開發(fā)自己的AI算法,另外像Facebook他們也有一些團隊做這方面的研究。
深度強化學習
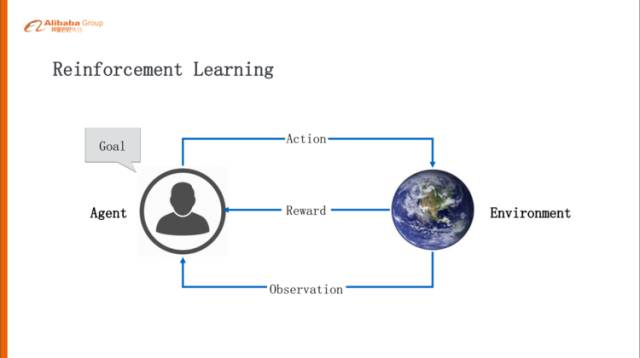
強化學習是非常接近人類學習的一個學習機制,通過這個Agent跟環(huán)境的交互,在交互當中學習。Agent會觀察周圍的環(huán)境,然后環(huán)境會給它一些反饋,Agent根據(jù)狀態(tài)和反饋會做出一些動作,這些動作會或多或少的影響這個環(huán)境,環(huán)境會根據(jù)這個動作反饋一些Reward,Reward可能是獎勵的也可能是懲罰的,Agent根據(jù)這樣的試錯,不斷的去調整。Agent背后有兩個概念非常重要,一個是不停的優(yōu)化策略,什么樣的狀況下采用什么樣的Action是合理的,另外一個是用價值函數(shù)評估當前的狀態(tài)它的價值是怎么樣的。
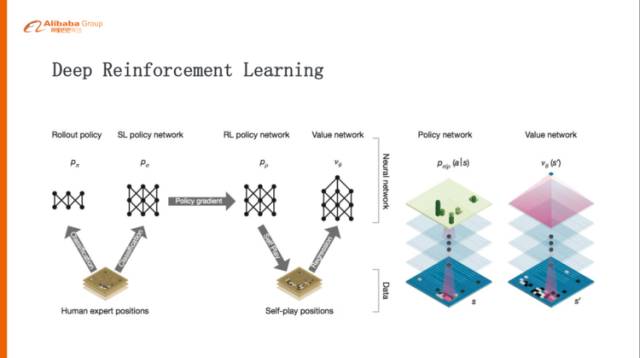
強化學習跟深度學習結合,就叫深度強化學習。因為深度學習或者神經網絡是非常適合去做這種表示學習的,可以表示成一個復雜的函數(shù)。policy或者value用神經網絡去逼近的話,在工程上或者效率上是非常好的提升。以AlphaGo的例子來講,在訓練的時候分成三個階段,第一個階段,從人類的棋譜里面學習人類的先驗的知識,通過監(jiān)督學習學習一個還好的、勝率比較高的policy network,第二個階段,基于監(jiān)督學習學習出來的policy network,然后自我對弈,通過policy gradient再去優(yōu)化policy network,這就比之前學出來的policy network要更好。第三階段,再用學出來的強化學習版的policy network自我對弈,得到一個最佳的。
多智能體協(xié)作

其實目前為止所有的AI的智能體比較成功的一些應用基本都是這種單個的Agent,其實對于人類來講,協(xié)作智能是智能體的一個非常大的方面,我們的祖先智人為什么可以統(tǒng)治地球,其中一個很大的原因就是,他們學會了大規(guī)模的協(xié)作,而且是非常靈活的協(xié)作。可以想象一下,未來全部都是這種AI的智能體,它們能不能自我學習到人類水平協(xié)作的一個智能呢?

我們用了一個詞Artificial Collective Intelligence,這對現(xiàn)實和未來都有非常大的意義。比如手機淘寶,現(xiàn)在絕大部分流量背后都是一個算法推薦出來的,不管廣告還是搜索其背后都是AI的智能體在做,目前這些智能體都是各出各的優(yōu)化,或者推出自己的商品。
其實我們在考慮的是,比如手機淘寶首頁里邊有愛逛街、猜你喜歡這種位置,那么他們能不能夠協(xié)同地去推出一些這樣的商品,從而可以讓用戶的體驗最好,讓平臺的價值最大化。其實以后可能都是算法經濟、AI經濟,都是這種AI的Agent,比如滿大街可能都是自動駕駛的無人車,他們之間是不是也需要一些協(xié)作,讓交通出行效率能夠達到最大化。

最近我們在《星際爭霸》里的微觀戰(zhàn)斗場景下,提出來一個多智能體雙向協(xié)作網絡,關于這個網絡的詳細內容大家感興趣可以下載我們的paper看一下,這個工作是我們跟UCL一起合作完成的,用來探索或者解決多智能體協(xié)作的問題。
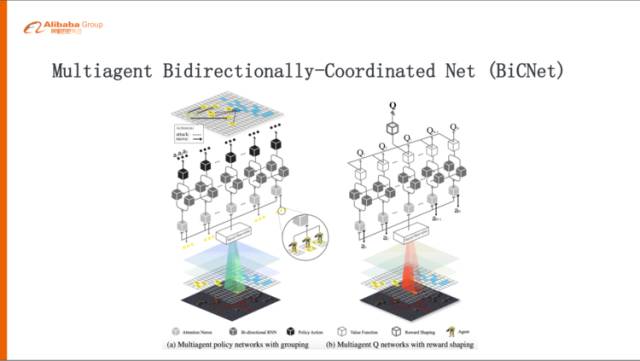
這是我們提出來的BiCNet(Multiagent Bidirectionally-Coordinated Net)的網絡結構,它其實也是比較經典的結構,分成兩部分,左邊這部分是一個policy的網絡,就是說從下往上會把《星際爭霸》的環(huán)境進行一些抽象,包括地圖的信息、敵方單位的血量、攻擊力,還有我方unit的信息,抽象出來形成一個共享的State,經過一個雙向的RNN這樣的網絡,進行充分的雙向的溝通,再往上每個Agent去得出自己的Action,比如我到某一個地方去攻擊誰。左邊這個policy network就是對于當前的狀態(tài)應該采取什么行動,右邊就是一個value的network,根據(jù)前面policy得出來的Action,還有抽象出來的State進行評估,Q值大概是多少,做出一個預判。當采取這些行動以后,這個環(huán)境就會給出相應的反饋,一些Reward來說明這步打的好還是不好,然后會通過一個Reword從右邊這個網絡下來,去反向傳播更新里面的參數(shù)。
這個網絡有幾點比較好的設計:
第一,它的scalability比較好,《星際爭霸》里面打仗的時候隨時可能會有傷亡,這個Agent死掉以后這個網絡不是還可以正常的工作,包括源源不斷涌現(xiàn)的新的Agent進來,是不是也是可以工作。我們看到雙向網絡參數(shù)是共享的,所以是不會有影響的。
第二,我們在中間用了這樣一個雙向網絡以后,其實是在一個效率和性能之間做了比較好的平衡,如果用全連接網絡的話,計算量會過大。但是我們用一個雙向網絡,前面告訴你大概要做什么樣的Action,回來再告訴前面的人他們采取了什么樣的Action,一結合,最后算出來應該追加的策略是什么樣子,從實際來看效果也是非常好的。
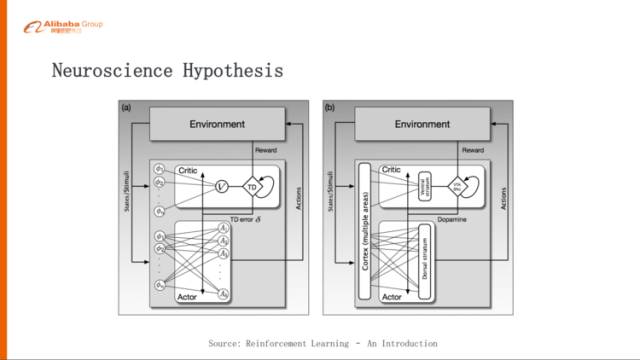
其實我們認知計算實驗室在設計一些算法或者模型的時候會參考神經科學里邊目前的一些研究成果,我們認為研究認知心理學、大腦、類腦的研究或者神經科學,對于做人工智能應該有兩個好處。
第一個好處就是,神經科學具有啟發(fā)性,就是當你在一些具體的問題或者場景里面去思考的時候,會遇到一些問題,這些問題可能是從來沒有人解過的,如果神經科學、交叉科學里有類似的這種結構或者算法,這些可能會很好的解決你的問題,帶來算法上的一些啟發(fā)。
反過來另外一點,神經科學也可以幫你做驗證,你設計一個算法以后,如果神經科學里面有類似的結構,那么很大概率這個算法是可以工作的。
其實我們的Actor-Critic網絡在人腦里面也是有相應的對應,左邊就是Actor-Critic這個網絡,右邊是我們的大腦,大腦里邊紋狀體就是負責Actor、Critic兩部分,這個紋狀體腹部是負責Critic這部分,背部是負責Actor這部分,Reward下來以后我們大腦會計算,這與預期的Reward有什么差距,這個差距就會以多巴胺的形式影響到Actor,下一次你就要按照這個去調節(jié),讓下一次Action做的更好一點。
其實多巴胺體現(xiàn)在我們的算法里面就是TD error,也就是我們算的Reward的誤差,這其實是一個很好的對應。
實驗平臺和實際效果
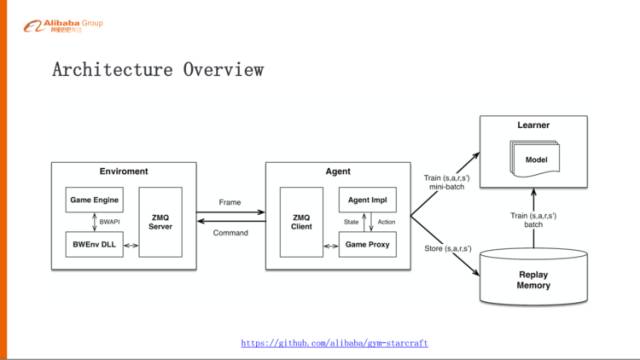
前面是網絡架構的設計,為了實現(xiàn)這樣一個算法模型,我們搭了一個實驗平臺,這個實驗平臺就是基于Facebook的TorchCraft,它是把《星際爭霸1》和Torch封裝在一起,但是我們比較習慣于TensorFlow和Python,所以在上面做了一個封裝,再把這套架構放在這個OpenAI標準接口里邊,大家有興趣可以試一下。
這個架構主要分成兩部分,對應剛才說的強化學習:
左邊是Environment,其實就是《星際爭霸》這個游戲,包括引擎,還有里面的DLL,DLL基于BWEnv,這是一個官方認可的DLL。基于這個BWEnv DLL把內部的狀態(tài)、指令封裝起來,其實這就是一個Server;
右邊就是Agent,是一個Client,這樣你可以連上很多的Agent玩這個游戲。中間是傳遞的信息,Environment會把它每一幀的數(shù)據(jù)吐給Agent,Agent會把每一幀的數(shù)據(jù)抽象成狀態(tài),然后再把這個State送到model里面去學習或者做預測,反過來會預測出來一些Action,這些Action會封裝成指令,再發(fā)回給《星際爭霸》的Environment,比如說開槍或者逃跑,這個是我們搭的這樣一個《星際爭霸》的實驗平臺。
下面是我們這個實驗平臺做到的一些效果,總結起來有五種可觀測的智能。
第一種,可以配合走位。

這個例子就是三個槍兵打一個Super的小狗,這個小狗是我們編輯過的,血量非常大,一下子打不死。三個槍兵打一個小狗,a/b這兩個圖,在訓練的早期其實是沒有學會太多的配合意識,所以他們走位的時候經常會發(fā)生碰撞,經過可能幾萬輪的訓練以后,他們慢慢學會了配合隊友的走位,這樣大家撞不到一起。
第二個場景,邊打邊撤

這個配合就是邊打邊撤,Hit and Run這樣的技能,這個例子就是三個槍兵打一個狂徒,利用遠程攻擊的優(yōu)勢來消滅敵人。
第三種,掩護攻擊

剛才三個槍兵打一個狂徒的時候是同時撤退,但是在這個場景下有些槍兵可能會去吸引這個小狗或者去阻擋一下,讓另外兩個槍兵抓住這個時間空隙來消滅這個小狗。非常有意思的一點就是,這種協(xié)作不是在任何情況下都會出現(xiàn)的,如果你的環(huán)境不是那么的有挑戰(zhàn)性,可能它就是簡單的Hit and Run就足夠了,如果我們的環(huán)境更嚴苛一點,比如這個小狗血量調高,攻擊力從3調到4,或者血量從210調到270,發(fā)現(xiàn)它又學會了另一種更高級的掩護攻擊的協(xié)作,這就非常有意思了。
第四種,分組的集火攻擊

這個例子是15個槍兵打16個槍兵,大家想想應該怎么取勝?策略可能3個槍兵或者4個槍兵自動組成一組,這3個槍兵先干掉一個、再干掉一個,就是把火力集中,但又不是15個槍兵打1個,而把火力分散一點,最后可能我們這方還剩6個槍兵,對方可能全部消滅掉了,這個都是通過很多輪次的學習之后他們自動去學到的這樣一個配合。
第五種,不光是槍兵之間學會配合,還可以多兵種配合,異構的Agent的配合。

這個例子就是,兩個運輸機,每個運輸機帶一個坦克去打一頭大象,正常來講,兩個坦克打一個大象肯定是打不過的,加上運輸機的配合以后,大象攻擊某一個坦克的時候,運輸機會及時的把這個坦克收起來,讓大象撲空,同時另外一個運輸機趕緊把它的坦克放下去,去攻擊大象,這樣一來一回可能大象一點便宜占不到就被消滅了,這個是基于我們之前的做出BiCNet一個協(xié)作的展現(xiàn)。
關于未來的一些思考
但是《星際爭霸》里其實不光是微觀戰(zhàn)斗,其實更難的是宏觀的策略方面,怎么樣“宏觀+微觀”打一整個游戲,這樣其實我們也有一些思考,可能不是特別成熟,但是我們可以一起探討一下。
每一個層級設定一個Goal
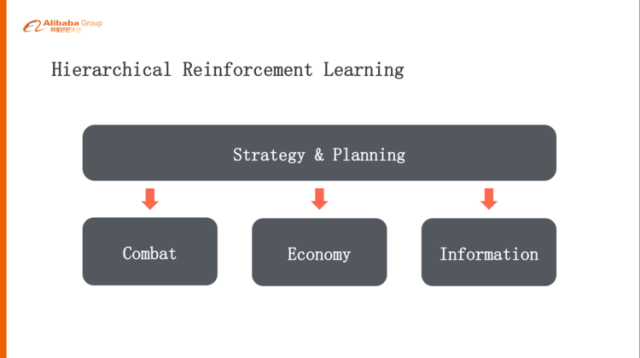
要玩一個full-game,如果是簡單的單層次的強化學習,可能解決不了問題,因為action space實在太大了,一個比較自然的做法就是做層級式的方式,可能上層是策略規(guī)劃,下面一層就是它的戰(zhàn)斗、經濟發(fā)展、探路、地圖的分析等等,這樣的話一層一層的,就是高層給下層設置一個goal,下層再給下面一層設計一個goal,其實這跟人的問題分解是比較類似的。
模仿學習(Imitation Learning)
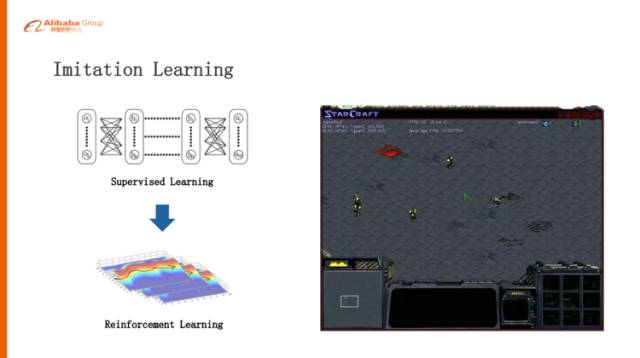
我們覺得值得去研究和探討的是模仿學習,Imitation Learning,剛剛講的AlphaGo的例子也是Imitation Learning,第一步通過監(jiān)督學習學習比較好的策略,再把監(jiān)督學習學好的策略通過自我的對弈去提升,在《星際爭霸》里面更需要這種模仿學習,比如說我們兩個槍兵打一個小狗的時候,我們認為一個好的策略是一個槍兵吸引小狗在那兒繞圈,然后另外一個槍兵就站在中心附近開槍,把這個小狗消滅,兩個槍兵一滴血可以不死。但是這種策略是比較難學習的,所以我們先給它人為的讓這個槍兵在里面畫圈,畫上幾步之后槍兵自己學會畫圈了,帶著小狗,然后另外一個槍兵在后面追著屁股打,這種探索就非常的有效。
持續(xù)學習(Continual Learning)
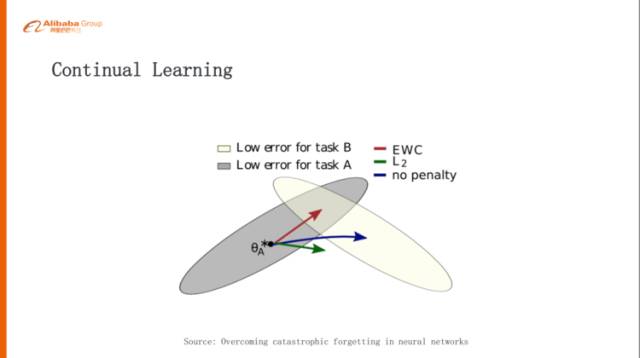
Continual Learning,如果要邁向通用智能,這是繞不過去的課題。
Continual Learning像人一樣,我們學會了走路,下一次我們學會了說話,我們在學說話的時候可能就不會把走路這件事情這個本領忘掉,但是在《星際爭霸》一些場景的時候,神經網絡學到A的時候再去學B,這個時候可能會把A的事情忘掉。
舉個例子,一開始我們訓練一個槍兵打一個小狗,這個小狗是電腦里邊自帶的AI,比較弱,這個槍兵學會了邊打邊撤,肯定能把小狗打死。我們再反過來訓練一個小狗,這個小狗去打電腦槍兵,這個小狗學會最佳策略就是說一直追著咬,永遠不要猶豫,猶豫就會被消滅掉,所以它是一條惡狗,一直追著槍兵咬。然后我們把這槍兵和小狗同時訓練,讓他們同時對弈,這樣發(fā)現(xiàn)一個平衡態(tài),就是槍兵一直逃,狗一直追,《星際爭霸》設計比較好的就是非常平衡。然后這個槍兵就學會了一直跑,我們再把這個槍兵放回到原來的環(huán)境,就是再打一個電腦帶的小狗,發(fā)現(xiàn)它也會一直跑,它不會邊打邊撤。
你發(fā)現(xiàn)它學習的時候,學會了A再學會B,A忘了,這個其實是對通用人工智能是非常大的挑戰(zhàn),最近DeepMind也發(fā)了一個相關工作的paper,這也是一個promising的方向,大家有興趣可以去看一下,他們的算法叫EWC。
引入Memory機制
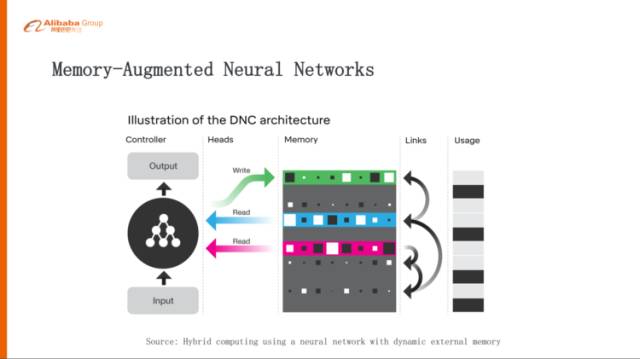
最后一點,前面有說到幾大挑戰(zhàn),其中有一大挑戰(zhàn)就是長期的規(guī)劃,長期規(guī)劃里邊我們認為一個比較好的做法就是,給這種強化學習里面去引入Memory的機制,這也是目前的一個比較火的方向,像Memory Networks、DNC,要解決的問題就是,我們在學習的過程當中應該記住什么東西,從而使得我們可以達到一個很好的最大的Reward。
所以今天跟大家交流的主要就是說,其實在《星際爭霸》里面是蘊含了非常非常豐富的研究通用人工智能或者研究認知智能的場景,這個里面可以有很多非常有意思的課題。我只是列舉了四個方向,其實還有很多很多方向可以去研究。
-
人工智能
+關注
關注
1792文章
47483瀏覽量
239162 -
阿里巴巴
+關注
關注
7文章
1617瀏覽量
47338 -
AI算法
+關注
關注
0文章
252瀏覽量
12296
原文標題:阿里巴巴為什么選擇星際爭霸作為AI算法研究環(huán)境?
文章出處:【微信號:WUKOOAI,微信公眾號:悟空智能科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網監(jiān)
工商網監(jiān)
評論