") Python抓取網(wǎng)絡(luò)高清美圖
Python抓取網(wǎng)絡(luò)高清美圖
一:前言
嘀嘀嘀,上車請(qǐng)刷卡。昨天看到了不錯(cuò)的圖片分享網(wǎng)——花瓣,里面的圖片質(zhì)量還不錯(cuò),所以利用selenium+xpath我把它的妹子的欄目下爬取了下來(lái),以圖片欄目名稱給文件夾命名分類保存到電腦中。這個(gè)妹子主頁(yè)http://huaban.com/boards/favorite/beauty是動(dòng)態(tài)加載的,如果想獲取更多內(nèi)容可以模擬下拉,這樣就可以更多的圖片資源。這種之前爬蟲中也做過(guò),但是因?yàn)榫W(wǎng)速不夠快所以我就抓了19個(gè)欄目,一共500多張美圖,也已經(jīng)很滿意了。
先看看效果:
Paste_Image.png
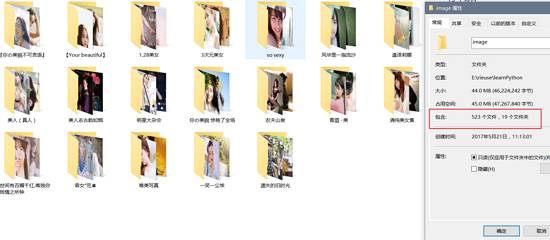
Paste_Image.png
二:運(yùn)行環(huán)境
IDE:Pycharm
Python3.6
lxml 3.7.2
Selenium 3.4.0
requests 2.12.4
三:實(shí)例分析
1.這次爬蟲我開始做的思路是:進(jìn)入這個(gè)網(wǎng)頁(yè)http://huaban.com/boards/favorite/beauty然后來(lái)獲取所有的圖片欄目對(duì)應(yīng)網(wǎng)址,然后進(jìn)入每一個(gè)網(wǎng)頁(yè)中去獲取全部圖片。(如下圖所示)
Paste_Image.png
Paste_Image.png
2.但是爬取獲取的圖片分辨率是236x354,圖片質(zhì)量不夠高,但是那個(gè)時(shí)候已經(jīng)是晚上1點(diǎn)30之后了,所以第二天做了另一個(gè)版本:在這個(gè)基礎(chǔ)上再進(jìn)入每個(gè)縮略圖對(duì)應(yīng)的網(wǎng)頁(yè),再抓取像下面這樣高清的圖片。
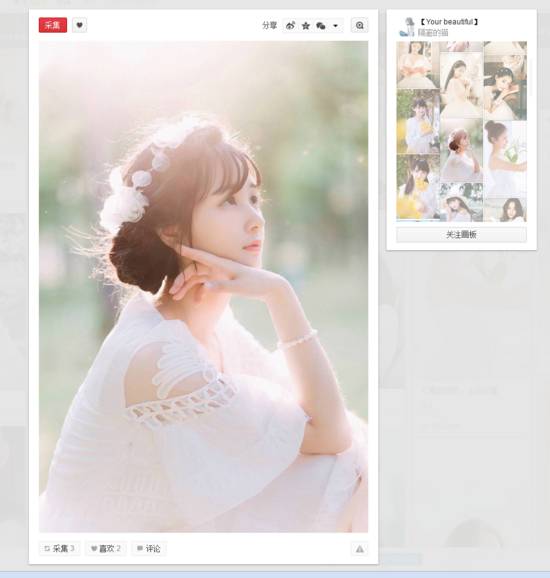
Paste_Image.png
四:實(shí)戰(zhàn)代碼
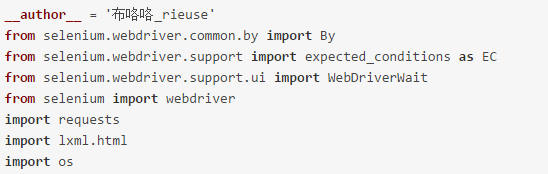
1.第一步導(dǎo)入本次爬蟲需要的模塊
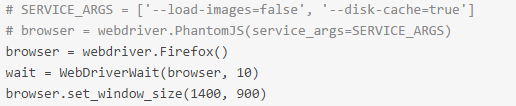
2.下面是設(shè)置webdriver的種類,就是使用什么瀏覽器進(jìn)行模擬,可以使用火狐來(lái)看它模擬的過(guò)程,也可以是無(wú)頭瀏覽器PhantomJS來(lái)快速獲取資源,['--load-images=false', '--disk-cache=true']這個(gè)意思是模擬瀏覽的時(shí)候不加載圖片和緩存,這樣運(yùn)行速度會(huì)加快一些。WebDriverWait標(biāo)明最大等待瀏覽器加載為10秒,set_window_size可以設(shè)置一下模擬瀏覽網(wǎng)頁(yè)的大小。有些網(wǎng)站如果大小不到位,那么一些資源就不加載出來(lái)。
3.parser(url, param)這個(gè)函數(shù)用來(lái)解析網(wǎng)頁(yè),后面有幾次都用用到這些代碼,所以直接寫一個(gè)函數(shù)會(huì)讓代碼看起來(lái)更整潔有序。函數(shù)有兩個(gè)參數(shù):一個(gè)是網(wǎng)址,另一個(gè)是顯性等待代表的部分,這個(gè)可以是網(wǎng)頁(yè)中的某些板塊,按鈕,圖片等等...

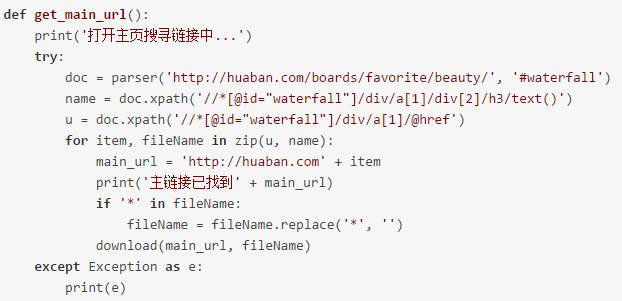
4.下面的代碼就是解析本次主頁(yè)面http://huaban.com/boards/favorite/beauty/然后獲取到每個(gè)欄目的網(wǎng)址和欄目的名稱,使用xpath來(lái)獲取欄目的網(wǎng)頁(yè)時(shí),進(jìn)入網(wǎng)頁(yè)開發(fā)者模式后,如圖所示進(jìn)行操作。之后需要用欄目名稱在電腦中建立文件夾,所以在這個(gè)網(wǎng)頁(yè)中要獲取到欄目的名稱,這里遇到一個(gè)問(wèn)題,一些名稱不符合文件命名規(guī)則要剔除,我這里就是一個(gè) * 影響了。
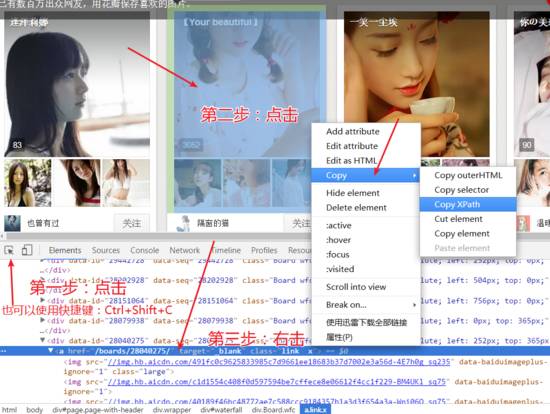
Paste_Image.png
5.前面已經(jīng)獲取到欄目的網(wǎng)頁(yè)和欄目的名稱,這里就需要對(duì)欄目的網(wǎng)頁(yè)分析,進(jìn)入欄目網(wǎng)頁(yè)后,只是一些縮略圖,我們不想要這些低分辨率的圖片,所以要再進(jìn)入每個(gè)縮略圖中,解析網(wǎng)頁(yè)獲取到真正的高清圖片網(wǎng)址。這里也有一個(gè)地方比較坑人,就是一個(gè)欄目中,不同的圖片存放dom格式不一樣,所以我這樣做

這就把兩種dom格式中的圖片地址都獲取了,然后把兩個(gè)地址list合并一下。img_url +=img_url2在本地創(chuàng)建文件夾使用filename = 'image{}'.format(fileName) + str(i) + '.jpg'表示文件保存在與這個(gè)爬蟲代碼同級(jí)目錄image下,然后獲取的圖片保存在image中按照之前獲取的欄目名稱的文件夾中。

五:總結(jié)
這次爬蟲繼續(xù)練習(xí)了Selenium和xpath的使用,在網(wǎng)頁(yè)分析的時(shí)候也遇到很多問(wèn)題,只有不斷練習(xí)才能把自己不會(huì)部分減少,當(dāng)然這次爬取了500多張妹紙還是挺養(yǎng)眼的。
-
python
+關(guān)注
關(guān)注
56文章
4797瀏覽量
84787
原文標(biāo)題:小白請(qǐng)上車 | Python抓取花瓣網(wǎng)高清美圖
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何使用高清網(wǎng)絡(luò)機(jī)頂盒
小米聯(lián)姻美圖 最大的敵人還是蘋果!
python網(wǎng)絡(luò)爬蟲概述
美圖M6s發(fā)布:Angelababy自曝高清自拍 簡(jiǎn)直美炸了
美圖V4高清圖賞
python3.3抓取網(wǎng)頁(yè)數(shù)據(jù)的程序資料免費(fèi)下載






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論