 AI芯片領域好戲才剛開始
AI芯片領域好戲才剛開始
新型架構能夠挖掘深度學習的巨大潛力。然而,到目前為止,只有一款AI芯片是完全符合描述和基準測試的,它就是谷歌的TPU。即便如此,這一領域仍然正在蓬勃發展,相關的技術也開始逐漸明朗,比如模擬計算、新興內存和封裝技術、以及一系列專門用于處理神經網絡的技術等等。
對此,比利時魯汶大學Marian Verhelst教授表示:“這個領域涉及范圍很廣,包括每個層面的研究。”Verhelst教授專門研究探索二元精密格式的芯片。她說,模擬計算很有用,特別是3到8位格式的模擬計算。
NVIDIA首席科學家、資深處理器研究員Bill Dally表示:“NVIDIA有多個和深度學習模擬計算相關的研究項目,但是到目前為止,還沒有一個項目可以轉化為產品。”他補充說,有一些項目是需要數學神經網絡的,生成的結果并不適合用于進行模擬。
“過去那些被否定了的CPU新想法都被重新拿出來進行探索,例如模擬計算、內存處理器、晶圓級集成,”資深計算機研究員David Patterson這樣表示,他現在在谷歌工作。“我迫不及待地想看看這些激進的想法是否奏效。”
“兩三年前,每個優秀的計算機架構師都會說——'我可以做到100倍速’。正因如此,我們看到大量解決方案已經出現,并且提供了各種功能上的改進,不斷逼近當前技術的極限。” Chris Rowen表示,他曾經是MIPS和Tensilica公司的聯合創始人,現在又創建了一家人工智能軟件公司BabbleLabs。
AI基準測試遭遇初創公司冷落
處理器設計的復興給人們帶來的一大挫折就是漫長的等待。
去年5月,百度和谷歌公布了MLPerf基準,以一種公平的方式來衡量“幾十家”初創公司開發的芯片。該項目負責人Patterson表示:“結果有點令人失望,沒有一家初創公司提交第一個迭代的結果。”
“也許他們有戰略方面的考慮。但又不禁讓人懷疑,他們是不是在開發芯片的過程中遇到了問題,還是芯片性能沒有達到他們的預期,又或者是他們的軟件不夠成熟,無法很好地運行這些基準測試?”
這個訓練基準測試采用了ResNet-50,第一個測試結果顯示,谷歌TPUv3在從8個芯片擴展到256個芯片的過程中,性能擴展幾乎可以達到100%,相比之下,NVIDIA Volta在從8個芯片擴展到640個芯片的過程中,性能擴展了大約27%。
Patterson解釋說,TPU之所以占據優勢,是因為它可以作為多處理器在自己的網絡上運行。相比之下,NVIDIA Volta則是運行在x86集群上的。
Patterson希望未來MLPerf之于AI加速器就像Spec之于CPU。第二批訓練結果預計將在今年晚些時候公布。針對數據中心和邊緣推理工作的MLPerf基準測試也將在今年首次亮相。
與此同時,也有研究人員警告稱,AI芯片行業過于關注峰值性能。“我們認為峰值性能沒有什么用,因為峰值性能沒有考慮到效率上的差異,”帝國理工學院Erwei Wang博士這樣表示,最近他和同事共同撰寫了一份關于人工智能加速器的研究報告。他指出,“人們應該公布的是標準數據集和基準測試的持續性能結果,以便更好地對比不同的架構。”下圖為MLPerf在12月發布的初步結果采樣。
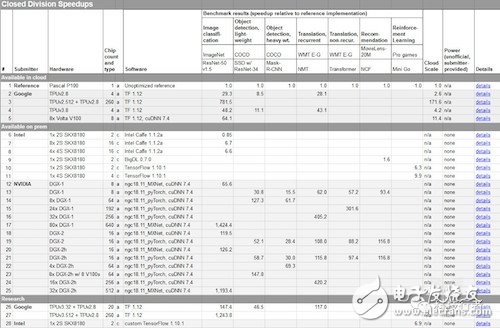
分析師:格局尚不明朗
有分析師抱怨說,包括Graphcore和Wave Computing等在內的知名初創公司到目前為止都沒能提供性能數據。唯一的例外是Habana Labs。
The Linley Group分析師Linley Gwennap表示,該初創公司“似乎有一些真實的數據,在白皮書中詳細說明其性能是NVIDIAGPU的3到5倍......但他們最初關注的是推理任務,而非訓練。”
對此,Moor Insights&Strategy分析師Karl Freund也指出,目前來自初創公司的性能數據確實“少得可憐”。
其中,Habana只是在采樣階段,Wave宣稱已有客戶采用,Graphcore表示會在4月之前出貨芯片產品,Groq可能會在4月北京舉行的一個活動上第一次亮相,其他初創公司則可能會于9月在舊金山舉行的一次活動上發布產品。
有幾家中國初創公司——例如Cambricon和Horizon Robotics,讓我們看到了一些希望,這些公司先于美國的同類企業進入市場,專注于人工智能推理領域。
Freund表示:“由于目前在推理領域還沒有巨頭出現,所以會掀起一股淘金熱,但我不知道是否有初創公司能夠在訓練領域向NVIDIA GPU發起挑戰,因為只是在一個產品周期內你無法扭轉競爭形勢,企業需要可持續的領先地位。”
他說:“唯一一個真正在訓練領域站穩腳跟的是英特爾,英特爾已經推出了Nervana芯片,他們正在等待合適的時機,因為如果只是有一堆MAC和降低了的精度,立刻會被NVIDIA秒殺。他們需要解決內存帶寬和擴展問題。”
在這場競賽中,英特爾可以說是多管齊下。英特爾的一位AI軟件經理表示,與他工作關系最緊密的,就是至強處理器和前蘋果及AMD GPU大師Raja Koduri設計的新GPU。
英特爾最新的Cascade Lake至強處理器中增添了很多新功能,用以加速人工智能。我們預計,英特爾將不再需要GPU或加速器,但也不會放棄與GPU和加速器在性能或效率方面的競爭。
而對于NVIDIA來說,他們正在將最新的12納米處理器封裝到各種工作站、服務器和機架系統中。有人說,NVIDIA在AI訓練方面遙遙領先,甚至可以把7納米產品保留到2020年之后再推出。
除了,NVIDIA之外,許多大廠商也都在基于專有的互連技術、封裝技術、編程工具和其他技術構建競爭生態系統。其中,英特爾涉及的技術領域最廣泛,包括專有的處理器互連、針對Optane DIMM的內存協議、網絡框架、以及新興的EMIB和Foveros芯片封裝。
AMD、Arm、IBM和Xilinx則圍繞CCIX(用于極速器的一種緩存一致性互連技術)和GenZ(一種內存鏈接技術)進行聯手。最近,英特爾還發布了一種針對加速器和內存的更開放的處理器互連技術——CXL,但到目前為止,CXL仍然缺少對CCIX和GenZ的第三方支持。下圖為AI芯片初創公司列表。

數據中心試水DIY芯片
當初創公司爭相在服務器系統中為自己的芯片占據一席之地的時候,一些企業卻在部署他們自己研發的加速器。
比如:谷歌已經在使用第三代TPU,該版本采用了液體冷卻技術,運行平穩;百度去年也宣布推出了自己的首款芯片;亞馬遜表示將在今年晚些時候推出首款芯片;Facebook正在組建一支半導體團隊;阿里巴巴則在去年收購了一家處理器專業公司。
大多數廠商對其芯片的架構和性能都非常苛刻。百度表示,將發布針對訓練和推理任務的不同版本14納米“昆侖”芯片,可以提供260 TOPS性能,功耗為100 W,其中封裝了數千個核心,總內存帶寬為512 GB/s。亞馬遜方面表示,Inferentia將實現數百TOPS的推理吞吐量,多個芯片聚合在一起可以實現數千TOPS性能。
“很多初創公司都是以面向超大規模數據中心售賣芯片為目標開展業務的,而現在,這可能行不通了,”二級公有云服務商Packet公司首席執行官Zac Smith這樣表示。
我們可能永遠也看不到云計算巨頭設計芯片的拆解細節,但是有一些公開信息描述了很多嵌入塊的情況。Linley Group分析師Mike Demler表示,這些嵌入塊展現了從改進后的DSP和GPU模塊,到使用乘法累加數組,再到數據流體系結構的演變,這種架構將生成的信息從神經網絡的一個層面傳遞到另一個層面。
和三星最新公布的Samsung Exynos中的AI模塊一樣,很多芯片都轉向重度使用網絡修剪和量化技術,運行8位和16位操作以優化效率和網絡稀疏性。
對網絡進行修剪將變得越來越重要。卷積神經網絡(CNN)之父Yann LeCun表示,神經網絡模型只會越變越大,這就要求性能越來越高。不過他指出,神經網絡模型可以被極大程度上進行修剪,特別是考慮到人類大腦最大限度上只被激活了2%。
他在最近一篇針對芯片設計人員的論文中,呼吁開發能夠處理極其稀疏網絡的芯片。“在大多數情況下,芯片單元都是處于關閉狀態的,事件驅動型的硬件具有一定的優勢,如此一來,只有激活的單元才會消耗資源。”他這樣寫道。
“遞歸神經網絡是最稀疏的,因此,使用細粒度修剪也是最有效的。有50%-90%的修剪都是針對CNN的,但是芯片設計人員要面對支持細粒度修剪不規則性和靈活性方面的挑戰。”帝國理工學院研究員Erwei Wang這樣表示。
減少權重數量和降低精度有助于減少內存需求。Wang說,英特爾的至強芯片和其他很多芯片已經在使用8位整數數據執行推理任務,而FPGA和嵌入式芯片正在向4位甚至二進制精度發展。
這么做是為了讓處理操作盡可能靠近內存所在位置,避免片外訪問。理想情況下,這意味著能夠在寄存器內部或者至少是在緩存內部進行計算。
LeCun甚至在他的論文中設想了一種將內存和處理單元結合起來的可編程寄存器。
“為了讓深度學習系統具備推理能力,深度學習系統需要一種短期內存作為情景內存......這樣的內存會變得非常普及,而且非常龐大,亟需硬件方面的支持。”他這樣寫道。下圖為根據研究員Erwei Wang及其同事最近對可編程架構的研究調查現實,性能差異是很大的。
MAC單元之外所需的靈活性
如果必須遠離芯片,那就把大量請求批量處理成幾個較大的請求,這已經是一種很流行的技術。Patterson注意到谷歌最近發表了一篇論文,對于批量操作最理想大小的討論帶來了一些啟發。
Patterson表示:“如果你小心操作的話,會在某個區域內得到最理想的加速,然后當你增加批量處理規模的時候,就會發現收益出現遞減,然后在很多模型中都表現平平。”
LeCun在論文中警告說:“我們需要新的硬件架構,這些架構在批量處理大小為1的時候可以高效運行。這意味著我們完全不需要依賴于矩陣產品作為最低層級的操作工具。”這一理論無疑是對目前芯片核心的多架構單元的某種終結。
鑒于現在還是深度學習的早期發展階段,最重要的指導方針是保持靈活性,以及在可編程性和性能之間尋求平衡。
“我們吸取到的教訓是,神經網絡是持續演化的,你無法對神經網絡的維度做出假設,但又希望在各個方面都能保持高效。”負責開發Eyeriss芯片的Vivienne Sze這樣表示。
Wang說,在深度學習發展演化的過程中,FPGA將發揮重要的作用,這就要求硬件具備靈活性。他看好Xilinx的Versal ACAP,這是一種FPGA與硬件的混合體。
Wang提出的LUTNet研究探索了如何在無需維護索引的前提下定制查找表,以作為處理細粒度修剪的推理核心。他表示,這將讓推理任務所需的芯片減少一半。
這可以說是一個新穎的想法,很多企業已經在這方面進行實踐。例如,東芝最近推出了一種ADAS加速器,其94.5平方毫米的芯片中封裝了4個Cortex-A53核心,2個Cortex-R4、4個DSP、8個專用加速器模塊。
總的來說,對于AI芯片領域,我們還有非常大的想象空間,可以說,好戲才剛剛開始。
-
cpu
+關注
關注
68文章
10868瀏覽量
211844 -
神經網絡
+關注
關注
42文章
4772瀏覽量
100792 -
AI
+關注
關注
87文章
30919瀏覽量
269171
發布評論請先 登錄
相關推薦
RISC-V在AI領域的發展前景怎么樣?
如今火熱的AI芯片到底是什么

SK集團與亞馬遜等討論加強AI芯片領域合作
后摩智能引領AI芯片革命,推出邊端大模型AI芯片M30

smartconfig按照例程,每次剛開始掃描就結束了,為什么?

risc-v多核芯片在AI方面的應用



英偉達中國特供AI芯片開始預訂
新火種AI|AI行業規模將達2250億美元,國產芯片如何獲益?





 工商網監
工商網監
評論