") 基于代理方式的有MySQL Proxy和Amoeba
基于代理方式的有MySQL Proxy和Amoeba
Sharding的基本思想就要把一個數(shù)據(jù)庫切分成多個部分放到不同的數(shù)據(jù)庫(server)上,從而緩解單一數(shù)據(jù)庫的性能問題。不太嚴(yán)格的講,對于海量數(shù)據(jù)的數(shù)據(jù)庫,如果是因為表多而數(shù)據(jù)多,這時候適合使用垂直切分,即把關(guān)系緊密(比如同一模塊)的表切分出來放在一個server上。如果表并不多,但每張表的數(shù)據(jù)非常多,這時候適合水平切分,即把表的數(shù)據(jù)按某種規(guī)則(比如按ID散列)切分到多個數(shù)據(jù)庫(server)上。當(dāng)然,現(xiàn)實中更多是這兩種情況混雜在一起,這時候需要根據(jù)實際情況做出選擇,也可能會綜合使用垂直與水平切分,從而將原有數(shù)據(jù)庫切分成類似矩陣一樣可以無限擴(kuò)充的數(shù)據(jù)庫(server)陣列。
需要特別說明的是:當(dāng)同時進(jìn)行垂直和水平切分時,切分策略會發(fā)生一些微妙的變化。比如:在只考慮垂直切分的時候,被劃分到一起的表之間可以保持任意的關(guān)聯(lián)關(guān)系,因此你可以按“功能模塊”劃分表格,但是一旦引入水平切分之后,表間關(guān)聯(lián)關(guān)系就會受到很大的制約,通常只能允許一個主表(以該表ID進(jìn)行散列的表)和其多個次表之間保留關(guān)聯(lián)關(guān)系,也就是說:當(dāng)同時進(jìn)行垂直和水平切分時,在垂直方向上的切分將不再以“功能模塊”進(jìn)行劃分,而是需要更加細(xì)粒度的垂直切分,而這個粒度與領(lǐng)域驅(qū)動設(shè)計中的“聚合”概念不謀而合,甚至可以說是完全一致,每個shard的主表正是一個聚合中的聚合根!這樣切分下來你會發(fā)現(xiàn)數(shù)據(jù)庫分被切分地過于分散了(shard的數(shù)量會比較多,但是shard里的表卻不多),為了避免管理過多的數(shù)據(jù)源,充分利用每一個數(shù)據(jù)庫服務(wù)器的資源,可以考慮將業(yè)務(wù)上相近,并且具有相近數(shù)據(jù)增長速率(主表數(shù)據(jù)量在同一數(shù)量級上)的兩個或多個shard放到同一個數(shù)據(jù)源里,每個shard依然是獨立的,它們有各自的主表,并使用各自主表ID進(jìn)行散列,不同的只是它們的散列取模(即節(jié)點數(shù)量)必需是一致的.
1、常用的分庫分表中間件
1.1 簡單易用的組件:
-
當(dāng)當(dāng)sharding-jdbc
-
蘑菇街TSharding
1.2 強(qiáng)悍重量級的中間件:
-
sharding
-
TDDL Smart Client的方式(淘寶)
-
Atlas(Qihoo 360)
-
alibaba.cobar(是阿里巴巴(B2B)部門開發(fā))
-
MyCAT(基于阿里開源的Cobar產(chǎn)品而研發(fā))
-
Oceanus(58同城數(shù)據(jù)庫中間件)
-
OneProxy(支付寶首席架構(gòu)師樓方鑫開發(fā))
-
vitess(谷歌開發(fā)的數(shù)據(jù)庫中間件)
2、分庫分表需要解決的問題
1、事務(wù)問題
解決事務(wù)問題目前有兩種可行的方案:分布式事務(wù)和通過應(yīng)用程序與數(shù)據(jù)庫共同控制實現(xiàn)事務(wù)下面對兩套方案進(jìn)行一個簡單的對比。
方案一:使用分布式事務(wù)
-
優(yōu)點: 交由數(shù)據(jù)庫管理,簡單有效
-
缺點:性能代價高,特別是shard越來越多時
方案二:由應(yīng)用程序和數(shù)據(jù)庫共同控制
-
原理:將一個跨多個數(shù)據(jù)庫的分布式事務(wù)分拆成多個僅處 于單個數(shù)據(jù)庫上面的小事務(wù),并通過應(yīng)用程序來總控 各個小事務(wù)。
-
優(yōu)點:性能上有優(yōu)勢
-
缺點:需要應(yīng)用程序在事務(wù)控制上做靈活設(shè)計。如果使用 了spring的事務(wù)管理,改動起來會面臨一定的困難。
2、跨節(jié)點Join的問題
只要是進(jìn)行切分,跨節(jié)點Join的問題是不可避免的。但是良好的設(shè)計和切分卻可以減少此類情況的發(fā)生。解決這一問題的普遍做法是分兩次查詢實現(xiàn)。在第一次查詢的結(jié)果集中找出關(guān)聯(lián)數(shù)據(jù)的id,根據(jù)這些id發(fā)起第二次請求得到關(guān)聯(lián)數(shù)據(jù)。
3、跨節(jié)點的count,order by,group by以及聚合函數(shù)問題
這些是一類問題,因為它們都需要基于全部數(shù)據(jù)集合進(jìn)行計算。多數(shù)的代理都不會自動處理合并工作。解決方案:與解決跨節(jié)點join問題的類似,分別在各個節(jié)點上得到結(jié)果后在應(yīng)用程序端進(jìn)行合并。和join不同的是每個結(jié)點的查詢可以并行執(zhí)行,因此很多時候它的速度要比單一大表快很多。但如果結(jié)果集很大,對應(yīng)用程序內(nèi)存的消耗是一個問題。
4、數(shù)據(jù)遷移,容量規(guī)劃,擴(kuò)容等問題
來自淘寶綜合業(yè)務(wù)平臺團(tuán)隊,它利用對2的倍數(shù)取余具有向前兼容的特性(如對4取余得1的數(shù)對2取余也是1)來分配數(shù)據(jù),避免了行級別的數(shù)據(jù)遷移,但是依然需要進(jìn)行表級別的遷移,同時對擴(kuò)容規(guī)模和分表數(shù)量都有限制。總得來說,這些方案都不是十分的理想,多多少少都存在一些缺點,這也從一個側(cè)面反映出了Sharding擴(kuò)容的難度。
5、事務(wù)
5.1 分布式事務(wù)
-
參考:關(guān)于分布式事務(wù)、兩階段提交、一階段提交、Best Efforts 1PC模式和事務(wù)補(bǔ)償機(jī)制的研究
-
優(yōu)點基于兩階段提交,最大限度地保證了跨數(shù)據(jù)庫操作的“原子性”,是分布式系統(tǒng)下最嚴(yán)格的事務(wù)實現(xiàn)方式。實現(xiàn)簡單,工作量小。由于多數(shù)應(yīng)用服務(wù)器以及一些獨立的分布式事務(wù)協(xié)調(diào)器做了大量的封裝工作,使得項目中引入分布式事務(wù)的難度和工作量基本上可以忽略不計。
-
缺點系統(tǒng)“水平”伸縮的死敵。基于兩階段提交的分布式事務(wù)在提交事務(wù)時需要在多個節(jié)點之間進(jìn)行協(xié)調(diào),最大限度地推后了提交事務(wù)的時間點,客觀上延長了事務(wù)的執(zhí)行時間,這會導(dǎo)致事務(wù)在訪問共享資源時發(fā)生沖突和死鎖的概率增高,隨著數(shù)據(jù)庫節(jié)點的增多,這種趨勢會越來越嚴(yán)重,從而成為系統(tǒng)在數(shù)據(jù)庫層面上水平伸縮的"枷鎖", 這是很多Sharding系統(tǒng)不采用分布式事務(wù)的主要原因。
基于Best Efforts 1PC模式的事務(wù)
參考spring-data-neo4j的實現(xiàn)。鑒于Best Efforts 1PC模式的性能優(yōu)勢,以及相對簡單的實現(xiàn)方式,它被大多數(shù)的sharding框架和項目采用
5.2 事務(wù)補(bǔ)償(冪等值)
對于那些對性能要求很高,但對一致性要求并不高的系統(tǒng),往往并不苛求系統(tǒng)的實時一致性,只要在一個允許的時間周期內(nèi)達(dá)到最終一致性即可,這使得事務(wù)補(bǔ)償機(jī)制成為一種可行的方案。事務(wù)補(bǔ)償機(jī)制最初被提出是在“長事務(wù)”的處理中,但是對于分布式系統(tǒng)確保一致性也有很好的參考意義。籠統(tǒng)地講,與事務(wù)在執(zhí)行中發(fā)生錯誤后立即回滾的方式不同,事務(wù)補(bǔ)償是一種事后檢查并補(bǔ)救的措施,它只期望在一個容許時間周期內(nèi)得到最終一致的結(jié)果就可以了。事務(wù)補(bǔ)償?shù)膶崿F(xiàn)與系統(tǒng)業(yè)務(wù)緊密相關(guān),并沒有一種標(biāo)準(zhǔn)的處理方式。一些常見的實現(xiàn)方式有:對數(shù)據(jù)進(jìn)行對帳檢查;基于日志進(jìn)行比對;定期同標(biāo)準(zhǔn)數(shù)據(jù)來源進(jìn)行同步,等等。
6、ID問題
一旦數(shù)據(jù)庫被切分到多個物理結(jié)點上,我們將不能再依賴數(shù)據(jù)庫自身的主鍵生成機(jī)制。一方面,某個分區(qū)數(shù)據(jù)庫自生成的ID無法保證在全局上是唯一的;另一方面,應(yīng)用程序在插入數(shù)據(jù)之前需要先獲得ID,以便進(jìn)行SQL路由.
一些常見的主鍵生成策略
6.1 UUID
使用UUID作主鍵是最簡單的方案,但是缺點也是非常明顯的。由于UUID非常的長,除占用大量存儲空間外,最主要的問題是在索引上,在建立索引和基于索引進(jìn)行查詢時都存在性能問題。
結(jié)合數(shù)據(jù)庫維護(hù)一個Sequence表
此方案的思路也很簡單,在數(shù)據(jù)庫中建立一個Sequence表,表的結(jié)構(gòu)類似于:
1CREATETABLE`SEQUENCE`(2`table_name`varchar(18)NOTNULL,3`nextid`bigint(20)NOTNULL,4PRIMARYKEY(`table_name`)5)ENGINE=InnoDB
每當(dāng)需要為某個表的新紀(jì)錄生成ID時就從Sequence表中取出對應(yīng)表的nextid,并將nextid的值加1后更新到數(shù)據(jù)庫中以備下次使用。此方案也較簡單,但缺點同樣明顯:由于所有插入任何都需要訪問該表,該表很容易成為系統(tǒng)性能瓶頸,同時它也存在單點問題,一旦該表數(shù)據(jù)庫失效,整個應(yīng)用程序?qū)o法工作。有人提出使用Master-Slave進(jìn)行主從同步,但這也只能解決單點問題,并不能解決讀寫比為1:1的訪問壓力問題。
6.2 Twitter的分布式自增ID算法Snowflake
在分布式系統(tǒng)中,需要生成全局UID的場合還是比較多的,twitter的snowflake解決了這種需求,實現(xiàn)也還是很簡單的,除去配置信息,核心代碼就是毫秒級時間41位 機(jī)器ID 10位 毫秒內(nèi)序列12位。
-
10---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---000000000000在上面的字符串中,第一位為未使用(實際上也可作為long的符號位),接下來的41位為毫秒級時間,然后5位datacenter標(biāo)識位,5位機(jī)器ID(并不算標(biāo)識符,實際是為線程標(biāo)識),然后12位該毫秒內(nèi)的當(dāng)前毫秒內(nèi)的計數(shù),加起來剛好64位,為一個Long型。
這樣的好處是:整體上按照時間自增排序,并且整個分布式系統(tǒng)內(nèi)不會產(chǎn)生ID碰撞(由datacenter和機(jī)器ID作區(qū)分),并且效率較高,經(jīng)測試,snowflake每秒能夠產(chǎn)生26萬ID左右,完全滿足需要。
7、跨分片的排序分頁
一般來講,分頁時需要按照指定字段進(jìn)行排序。當(dāng)排序字段就是分片字段的時候,我們通過分片規(guī)則可以比較容易定位到指定的分片,而當(dāng)排序字段非分片字段的時候,情況就會變得比較復(fù)雜了。為了最終結(jié)果的準(zhǔn)確性,我們需要在不同的分片節(jié)點中將數(shù)據(jù)進(jìn)行排序并返回,并將不同分片返回的結(jié)果集進(jìn)行匯總和再次排序,最后再返回給用戶。如下圖所示:
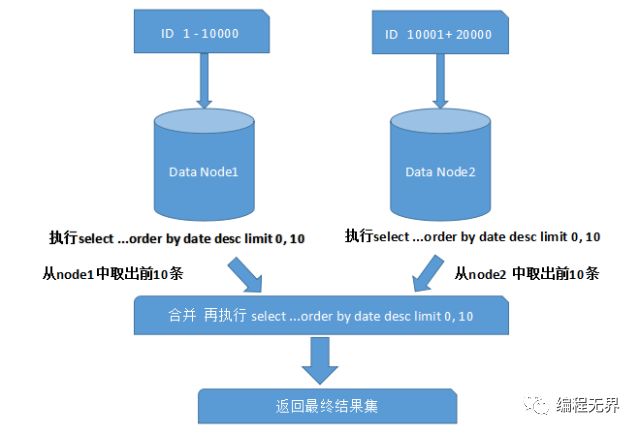
上面圖中所描述的只是最簡單的一種情況(取第一頁數(shù)據(jù)),看起來對性能的影響并不大。但是,如果想取出第10頁數(shù)據(jù),情況又將變得復(fù)雜很多,如下圖所示:
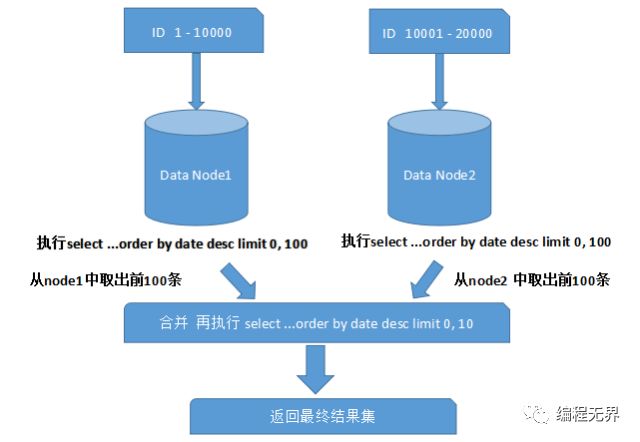
有些讀者可能并不太理解,為什么不能像獲取第一頁數(shù)據(jù)那樣簡單處理(排序取出前10條再合并、排序)。其實并不難理解,因為各分片節(jié)點中的數(shù)據(jù)可能是隨機(jī)的,為了排序的準(zhǔn)確性,必須把所有分片節(jié)點的前N頁數(shù)據(jù)都排序好后做合并,最后再進(jìn)行整體的排序。很顯然,這樣的操作是比較消耗資源的,用戶越往后翻頁,系統(tǒng)性能將會越差。
那如何解決分庫情況下的分頁問題呢?有以下幾種辦法:
如果是在前臺應(yīng)用提供分頁,則限定用戶只能看前面n頁,這個限制在業(yè)務(wù)上也是合理的,一般看后面的分頁意義不大(如果一定要看,可以要求用戶縮小范圍重新查詢)。
如果是后臺批處理任務(wù)要求分批獲取數(shù)據(jù),則可以加大page size,比如每次獲取5000條記錄,有效減少分頁數(shù)(當(dāng)然離線訪問一般走備庫,避免沖擊主庫)。
分庫設(shè)計時,一般還有配套大數(shù)據(jù)平臺匯總所有分庫的記錄,有些分頁查詢可以考慮走大數(shù)據(jù)平臺。
8、分庫策略
分庫維度確定后,如何把記錄分到各個庫里呢?
8.1 兩種方式:
-
根據(jù)數(shù)值范圍,比如用戶Id為1-9999的記錄分到第一個庫,10000-20000的分到第二個庫,以此類推。
-
根據(jù)數(shù)值取模,比如用戶Id mod n,余數(shù)為0的記錄放到第一個庫,余數(shù)為1的放到第二個庫,以此類推。
優(yōu)劣比較:
評價指標(biāo)按照范圍分庫按照Mod分庫
庫數(shù)量前期數(shù)目比較小,可以隨用戶/業(yè)務(wù)按需增長前期即根據(jù)mode因子確定庫數(shù)量,數(shù)目一般比較大
訪問性能前期庫數(shù)量小,全庫查詢消耗資源少,單庫查詢性能略差前期庫數(shù)量大,全庫查詢消耗資源多,單庫查詢性能略好
調(diào)整庫數(shù)量比較容易,一般只需為新用戶增加庫,老庫拆分也只影響單個庫困難,改變mod因子導(dǎo)致數(shù)據(jù)在所有庫之間遷移
數(shù)據(jù)熱點新舊用戶購物頻率有差異,有數(shù)據(jù)熱點問題新舊用戶均勻到分布到各個庫,無熱點
實踐中,為了處理簡單,選擇mod分庫的比較多。同時二次分庫時,為了數(shù)據(jù)遷移方便,一般是按倍數(shù)增加,比如初始4個庫,二次分裂為8個,再16個。這樣對于某個庫的數(shù)據(jù),一半數(shù)據(jù)移到新庫,剩余不動,對比每次只增加一個庫,所有數(shù)據(jù)都要大規(guī)模變動。
補(bǔ)充下,mod分庫一般每個庫記錄數(shù)比較均勻,但也有些數(shù)據(jù)庫,存在超級Id,這些Id的記錄遠(yuǎn)遠(yuǎn)超過其他Id,比如在廣告場景下,某個大廣告主的廣告數(shù)可能占總體很大比例。如果按照廣告主Id取模分庫,某些庫的記錄數(shù)會特別多,對于這些超級Id,需要提供單獨庫來存儲記錄。
9、分庫數(shù)量
分庫數(shù)量首先和單庫能處理的記錄數(shù)有關(guān),一般來說,Mysql 單庫超過5000萬條記錄,Oracle單庫超過1億條記錄,DB壓力就很大(當(dāng)然處理能力和字段數(shù)量/訪問模式/記錄長度有進(jìn)一步關(guān)系)。
在滿足上述前提下,如果分庫數(shù)量少,達(dá)不到分散存儲和減輕DB性能壓力的目的;如果分庫的數(shù)量多,好處是每個庫記錄少,單庫訪問性能好,但對于跨多個庫的訪問,應(yīng)用程序需要訪問多個庫,如果是并發(fā)模式,要消耗寶貴的線程資源;如果是串行模式,執(zhí)行時間會急劇增加。
最后分庫數(shù)量還直接影響硬件的投入,一般每個分庫跑在單獨物理機(jī)上,多一個庫意味多一臺設(shè)備。所以具體分多少個庫,要綜合評估,一般初次分庫建議分4-8個庫。
10、路由透明
分庫從某種意義上來說,意味著DB schema改變了,必然影響應(yīng)用,但這種改變和業(yè)務(wù)無關(guān),所以要盡量保證分庫對應(yīng)用代碼透明,分庫邏輯盡量在數(shù)據(jù)訪問層處理。當(dāng)然完全做到這一點很困難,具體哪些應(yīng)該由DAL負(fù)責(zé),哪些由應(yīng)用負(fù)責(zé),這里有一些建議:
對于單庫訪問,比如查詢條件指定用戶Id,則該SQL只需訪問特定庫。此時應(yīng)該由DAL層自動路由到特定庫,當(dāng)庫二次分裂時,也只要修改mod 因子,應(yīng)用代碼不受影響。
對于簡單的多庫查詢,DAL負(fù)責(zé)匯總各個數(shù)據(jù)庫返回的記錄,此時仍對上層應(yīng)用透明。
11、使用框架還是自主研發(fā)
目前市面上的分庫分表中間件相對較多,其中基于代理方式的有MySQL Proxy和Amoeba,基于Hibernate框架的是Hibernate Shards,基于jdbc的有當(dāng)當(dāng)sharding-jdbc,基于mybatis的類似maven插件式的有蘑菇街的蘑菇街TSharding,通過重寫spring的ibatis template類是Cobar Client,這些框架各有各的優(yōu)勢與短板,架構(gòu)師可以在深入調(diào)研之后結(jié)合項目的實際情況進(jìn)行選擇,但是總的來說,我個人對于框架的選擇是持謹(jǐn)慎態(tài)度的。一方面多數(shù)框架缺乏成功案例的驗證,其成熟性與穩(wěn)定性值得懷疑。另一方面,一些從成功商業(yè)產(chǎn)品開源出框架(如阿里和淘寶的一些開源項目)是否適合你的項目是需要架構(gòu)師深入調(diào)研分析的。當(dāng)然,最終的選擇一定是基于項目特點、團(tuán)隊狀況、技術(shù)門檻和學(xué)習(xí)成本等綜合因素考量確定的。
-
Server
+關(guān)注
關(guān)注
0文章
91瀏覽量
24053 -
TDD
+關(guān)注
關(guān)注
1文章
122瀏覽量
38209 -
MySQL
+關(guān)注
關(guān)注
1文章
817瀏覽量
26626 -
sharding
+關(guān)注
關(guān)注
0文章
5瀏覽量
7925
原文標(biāo)題:分庫分表需要考慮的問題及方案
文章出處:【微信號:DBDevs,微信公眾號:數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
手把手教你入門MySQL零基礎(chǔ)入門教程!
MySQL零基礎(chǔ)入門教程!
0基礎(chǔ)學(xué)Mysql:mysql入門視頻教程!
mysql零基礎(chǔ)入門視頻教程免費分享!
手把手教你入門MySQL零基礎(chǔ)入門教程!
免費分享: MySQL零基礎(chǔ)入門教程!
linux配置mysql的兩種方式
防火墻術(shù)語-Proxy
java動態(tài)代理分析

IP數(shù)據(jù)云 識別和分析tor、proxy等各類型代理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論