 北大語言計算與機器學習研究組推出一套全新中文分詞工具包pkuseg
北大語言計算與機器學習研究組推出一套全新中文分詞工具包pkuseg
日前,北京大學語言計算與機器學習研究組研制推出一套全新中文分詞工具包 pkuseg,這一工具包有如下三個特點:
高分詞準確率。相比于其他的分詞工具包,當使用相同的訓練數據和測試數據,pkuseg 可以取得更高的分詞準確率。
多領域分詞。不同于以往的通用中文分詞工具,此工具包同時致力于為不同領域的數據提供個性化的預訓練模型。根據待分詞文本的領域特點,用戶可以自由地選擇不同的模型。而其他現有分詞工具包,一般僅提供通用領域模型。
支持用戶自訓練模型。支持用戶使用全新的標注數據進行訓練。
各項性能對比如下:
與 jieba、THULAC 等國內代表分詞工具包進行性能比較:
考慮到 jieba 分詞和 THULAC 工具包等并沒有提供細領域的預訓練模型,為了便于比較,開發團隊重新使用它們提供的訓練接口在細領域的數據集上進行訓練,用訓練得到的模型進行中文分詞。他們選擇 Linux 作為測試環境,在新聞數據(MSRA)、混合型文本(CTB8)、網絡文本(WEIBO)數據上對不同工具包進行了準確率測試。在此過程中,他們使用第二屆國際漢語分詞評測比賽提供的分詞評價腳本,其中 MSRA 與 WEIBO 使用標準訓練集測試集劃分,CTB8 采用隨機劃分。對于不同的分詞工具包,訓練測試數據的劃分都是一致的;即所有的分詞工具包都在相同的訓練集上訓練,在相同的測試集上測試。
以下是在不同數據集上的對比結果:
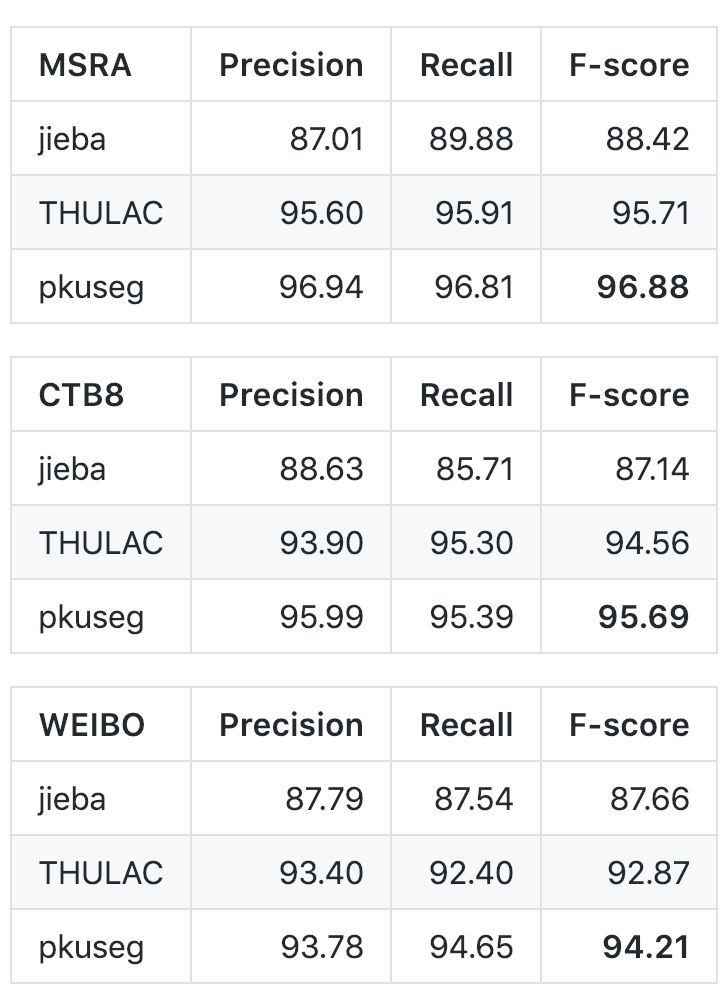
同時,為了比較細領域分詞的優勢,開發團隊比較了他們的方法和通用分詞模型的效果對比。其中 jieba 和 THULAC 均使用了軟件包提供的、默認的分詞模型:
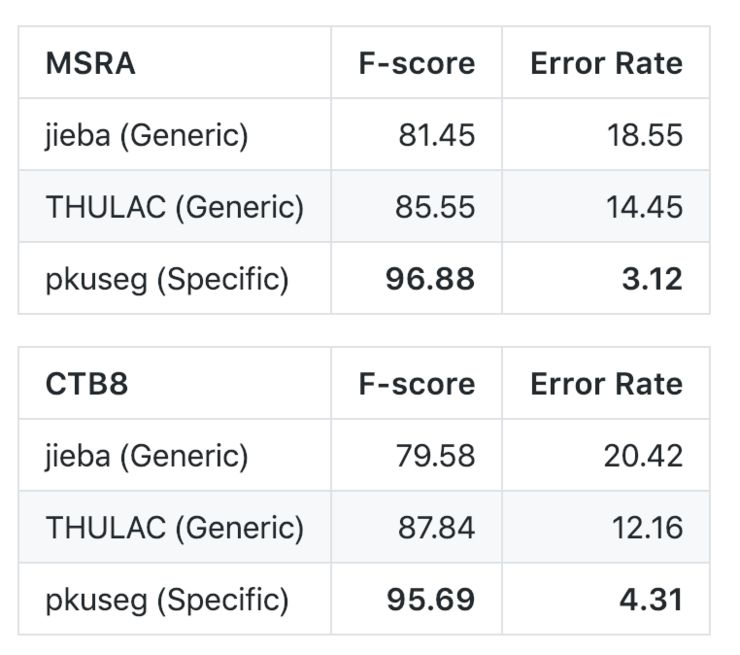
從結果上來看,當用戶了解待分詞文本的領域時,細領域分詞可以取得更好的效果。然而 jieba 和 THULAC 等分詞工具包僅提供了通用領域模型。
目前,該工具包已經在 GitHub 開源,編譯、安裝和使用說明如下。
編譯和安裝
pip install pkuseg之后通過 import pkuseg 來引用
2. 從 github 下載(需要下載模型文件,見預訓練模型)
將 pkuseg 文件放到目錄下,通過 import pkuseg 使用模型需要下載或自己訓練。
使用方式
1. 代碼示例
代碼示例1 使用默認模型及默認詞典分詞import pkusegseg = pkuseg.pkuseg() #以默認配置加載模型text = seg.cut('我愛北京***') #進行分詞print(text)
代碼示例2 設置用戶自定義詞典import pkuseglexicon = ['北京大學', '北京***'] #希望分詞時用戶詞典中的詞固定不分開seg = pkuseg.pkuseg(user_dict=lexicon) #加載模型,給定用戶詞典text = seg.cut('我愛北京***') #進行分詞print(text)
代碼示例3import pkusegseg = pkuseg.pkuseg(model_name='./ctb8') #假設用戶已經下載好了ctb8的模型并放在了'./ctb8'目錄下,通過設置model_name加載該模型text = seg.cut('我愛北京***') #進行分詞print(text)
代碼示例4import pkusegpkuseg.test('input.txt', 'output.txt', nthread=20) #對input.txt的文件分詞輸出到output.txt中,使用默認模型和詞典,開20個進程
代碼示例5import pkusegpkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20) #訓練文件為'msr_training.utf8',測試文件為'msr_test_gold.utf8',模型存到'./models'目錄下,開20個進程訓練模型
2. 參數說明
pkuseg.pkuseg(model_name='ctb8', user_dict=[])model_name 模型路徑。默認是'ctb8'表示我們預訓練好的模型(僅對pip下載的用戶)。用戶可以填自己下載或訓練的模型所在的路徑如model_name='./models'。user_dict 設置用戶詞典。默認不使用詞典。填'safe_lexicon'表示我們提供的一個中文詞典(僅pip)。用戶可以傳入一個包含若干自定義單詞的迭代器。
pkuseg.test(readFile, outputFile, model_name='ctb8', user_dict=[], nthread=10)readFile 輸入文件路徑outputFile 輸出文件路徑model_name 同pkuseg.pkuseguser_dict 同pkuseg.pkusegnthread 測試時開的進程數
pkuseg.train(trainFile, testFile, savedir, nthread=10)trainFile 訓練文件路徑testFile 測試文件路徑savedir 訓練模型的保存路徑nthread 訓練時開的進程數
預訓練模型
分詞模式下,用戶需要加載預訓練好的模型。開發團隊提供了三種在不同類型數據上訓練得到的模型,根據具體需要,用戶可以選擇不同的預訓練模型。以下是對預訓練模型的說明:
MSRA: 在MSRA(新聞語料)上訓練的模型。新版本代碼采用的是此模型。
下載地址:https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA
CTB8: 在CTB8(新聞文本及網絡文本的混合型語料)上訓練的模型。
下載地址:https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA
WEIBO: 在微博(網絡文本語料)上訓練的模型。
下載地址:https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ
開發團隊預訓練好其它分詞軟件的模型可以在如下地址下載:
jieba: 待更新
THULAC: 在 MSRA、CTB8、WEIBO、PKU 語料上的預訓練模型,下載地址:https://pan.baidu.com/s/11L95ZZtRJdpMYEHNUtPWXA,提取碼:iv82
其中 jieba 的默認模型為統計模型,主要基于訓練數據上的詞頻信息,開發團隊在不同訓練集上重新統計了詞頻信息。對于 THULAC,他們使用其提供的接口進行訓練(C++版本),得到了在不同領域的預訓練模型。
-
機器學習
+關注
關注
66文章
8428瀏覽量
132834 -
數據集
+關注
關注
4文章
1208瀏覽量
24748
原文標題:學界 | 北大開源中文分詞工具包 pkuseg
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
恩智浦車規級深度學習工具包使新一代汽車應用性能提高30倍
Facebook推出ReAgent AI強化學習工具包
Python人工智能學習工具包+入門與實踐資料集錦
中文分詞研究難點-詞語切分和語言規范
愛特梅爾推出全新的汽車應用開發工具包ATAPMxx
Google Kubernetes機器學習工具包Kubeflow發布0.1版
Python網頁爬蟲,文本處理,科學計算,機器學習和數據挖掘工具集
北大開源了一個中文分詞工具包,名為——PKUSeg
ToolKit是一套應用于嵌入式系統的通用工具包
搭建一套優秀的嵌入式軟件框架必備的通用工具包
Microchip 推出 MPLAB? 機器學習開發工具包,助力開發人員輕松將機器學習集成到 MCU 和 MPU中
Microchip(微芯)推出MPLAB機器學習開發工具包






 工商網監
工商網監
評論