") Transformer一統(tǒng)江湖:自然語(yǔ)言處理三大特征抽取器比較
Transformer一統(tǒng)江湖:自然語(yǔ)言處理三大特征抽取器比較
自然語(yǔ)言處理中的三大特征處理器:RNN、CNN、Transformer,它們目前誰(shuí)各方面占據(jù)優(yōu)勢(shì)?未來(lái)誰(shuí)又更有前途呢?這篇文章用目前的各種實(shí)驗(yàn)數(shù)據(jù)給出了說(shuō)明,結(jié)論是:放棄幻想,全面擁抱Transformer。
在辭舊迎新的時(shí)刻,大家都在忙著回顧過(guò)去一年的成績(jī)(或者在灶臺(tái)前含淚數(shù)鍋),并對(duì) 2019 做著規(guī)劃,當(dāng)然也有不少朋友執(zhí)行力和工作效率比較高,直接把 2018 年初制定的計(jì)劃拷貝一下,就能在 3 秒鐘內(nèi)完成 2019 年計(jì)劃的制定,在此表示祝賀。2018 年從經(jīng)濟(jì)角度講,對(duì)于所有人可能都是比較難過(guò)的一年,而對(duì)于自然語(yǔ)言處理領(lǐng)域來(lái)說(shuō),2018 年無(wú)疑是個(gè)收獲頗豐的年頭,而諸多技術(shù)進(jìn)展如果只能選擇一項(xiàng)來(lái)講的話,那么當(dāng)之無(wú)愧的應(yīng)該就是Bert 模型了。
在上一篇介紹 Bert 的文章 “從 Word Embedding 到 Bert 模型—自然語(yǔ)言處理中的預(yù)訓(xùn)練技術(shù)發(fā)展史”[1]里,我曾大言不慚地宣稱如下兩個(gè)個(gè)人判斷:一個(gè)是Bert 這種兩階段的模式(預(yù)訓(xùn)練 + Finetuning)必將成為 NLP 領(lǐng)域研究和工業(yè)應(yīng)用的流行方法;第二個(gè)是從 NLP 領(lǐng)域的特征抽取器角度來(lái)說(shuō),Transformer 會(huì)逐步取代 RNN 成為最主流的的特征抽取器。關(guān)于特征抽取器方面的判斷,上面文章限于篇幅,只是給了一個(gè)結(jié)論,并未給出具備誘惑力的說(shuō)明,看過(guò)我文章的人都知道我不是一個(gè)隨便下結(jié)論的人(那位正在補(bǔ)充下一句:“你隨便起來(lái)不是……” 的同學(xué)請(qǐng)住口,請(qǐng)不要泄露國(guó)家機(jī)密,你可以繼續(xù)睡覺(jué),吵到其它同學(xué)也沒(méi)有關(guān)系,哈哈),但是為什么當(dāng)時(shí)我會(huì)下這個(gè)結(jié)論呢?本文可以看做是上文的一個(gè)外傳,會(huì)給出比較詳實(shí)的證據(jù)來(lái)支撐之前給出的結(jié)論。
如果對(duì)目前NLP 里的三大特征抽取器的未來(lái)走向趨勢(shì)做個(gè)宏觀判斷的話,我的判斷是這樣的:
RNN人老珠黃,已經(jīng)基本完成它的歷史使命,將來(lái)會(huì)逐步退出歷史舞臺(tái);
CNN如果改造得當(dāng),將來(lái)還是有希望有自己在 NLP 領(lǐng)域的一席之地,如果改造成功程度超出期望,那么還有一絲可能作為割據(jù)一方的軍閥,繼續(xù)生存壯大,當(dāng)然我認(rèn)為這個(gè)希望不大,可能跟宋小寶打籃球把姚明打哭的概率相當(dāng);
而新歡Transformer明顯會(huì)很快成為 NLP 里擔(dān)當(dāng)大任的最主流的特征抽取器。
至于將來(lái)是否會(huì)出現(xiàn)新的特征抽取器,一槍將 Tranformer 挑落馬下,繼而取而代之成為新的特征抽取山大王?這種擔(dān)憂其實(shí)是挺有必要的,畢竟李商隱在一千年前就告誡過(guò)我們說(shuō):“君恩如水向東流,得寵憂移失寵愁。 莫向樽前奏花落,涼風(fēng)只在殿西頭。” 當(dāng)然這首詩(shī)看樣子目前送給 RNN 是比較貼切的,至于未來(lái) Transformer 是否會(huì)失寵?這個(gè)問(wèn)題的答案基本可以是肯定的,無(wú)非這個(gè)時(shí)刻的來(lái)臨是 3 年之后,還是 1 年之后出現(xiàn)而已。當(dāng)然,我希望如果是在讀這篇文章的你,或者是我,在未來(lái)的某一天,從街頭拉來(lái)一位長(zhǎng)相普通的淑女,送到韓國(guó)整容,一不小心偏離流水線整容工業(yè)的美女模板,整出一位天香國(guó)色的絕色,來(lái)把 Transformer 打入冷宮,那是最好不過(guò)。但是在目前的狀態(tài)下,即使是打著望遠(yuǎn)鏡,貌似還沒(méi)有看到有這種資質(zhì)的候選人出現(xiàn)在我們的視野之內(nèi)。
我知道如果是一位嚴(yán)謹(jǐn)?shù)难邪l(fā)人員,不應(yīng)該在目前局勢(shì)還沒(méi)那么明朗的時(shí)候做出如上看似有些武斷的明確結(jié)論,所以這種說(shuō)法可能會(huì)引起爭(zhēng)議。但是這確實(shí)就是我目前的真實(shí)想法,至于根據(jù)什么得出的上述判斷?這種判斷是否有依據(jù)?依據(jù)是否充分?相信你在看完這篇文章可以有個(gè)屬于自己的結(jié)論。
可能談到這里,有些平常吃虧吃的少所以喜歡挑刺的同學(xué)會(huì)質(zhì)疑說(shuō):你憑什么說(shuō) NLP 的典型特征抽取器就這三種呢?你置其它知名的特征抽取器比如 Recursive NN 于何地? 嗯,是,很多介紹 NLP 重要進(jìn)展的文章里甚至把 Recursive NN 當(dāng)做一項(xiàng) NLP 里的重大進(jìn)展,除了它,還有其它的比如 Memory Network 也享受這種部局級(jí)尊貴待遇。但是我一直都不太看好這兩個(gè)技術(shù),而且不看好很多年了,目前情形更堅(jiān)定了這個(gè)看法。而且我免費(fèi)奉勸你一句,沒(méi)必要在這兩個(gè)技術(shù)上浪費(fèi)時(shí)間,至于為什么,因?yàn)楦疚闹黝}無(wú)關(guān),以后有機(jī)會(huì)再詳細(xì)說(shuō)。
上面是結(jié)論,下面,我們正式進(jìn)入舉證階段。
戰(zhàn)場(chǎng)偵查:NLP 任務(wù)的特點(diǎn)及任務(wù)類型

NLP 任務(wù)的特點(diǎn)和圖像有極大的不同,上圖展示了一個(gè)例子,NLP 的輸入往往是一句話或者一篇文章,所以它有幾個(gè)特點(diǎn):首先,輸入是個(gè)一維線性序列,這個(gè)好理解;其次,輸入是不定長(zhǎng)的,有的長(zhǎng)有的短,而這點(diǎn)其實(shí)對(duì)于模型處理起來(lái)也會(huì)增加一些小麻煩;再次,單詞或者子句的相對(duì)位置關(guān)系很重要,兩個(gè)單詞位置互換可能導(dǎo)致完全不同的意思。如果你聽(tīng)到我對(duì)你說(shuō):“你欠我那一千萬(wàn)不用還了” 和 “我欠你那一千萬(wàn)不用還了”,你聽(tīng)到后分別是什么心情??jī)烧邊^(qū)別了解一下;另外,句子中的長(zhǎng)距離特征對(duì)于理解語(yǔ)義也非常關(guān)鍵,例子參考上圖標(biāo)紅的單詞,特征抽取器能否具備長(zhǎng)距離特征捕獲能力這一點(diǎn)對(duì)于解決 NLP 任務(wù)來(lái)說(shuō)也是很關(guān)鍵的。
上面這幾個(gè)特點(diǎn)請(qǐng)記清,一個(gè)特征抽取器是否適配問(wèn)題領(lǐng)域的特點(diǎn),有時(shí)候決定了它的成敗,而很多模型改進(jìn)的方向,其實(shí)就是改造得使得它更匹配領(lǐng)域問(wèn)題的特性。這也是為何我在介紹 RNN、CNN、Transformer 等特征抽取器之前,先說(shuō)明這些內(nèi)容的原因。
NLP 是個(gè)很寬泛的領(lǐng)域,包含了幾十個(gè)子領(lǐng)域,理論上只要跟語(yǔ)言處理相關(guān),都可以納入這個(gè)范圍。但是如果我們對(duì)大量 NLP 任務(wù)進(jìn)行抽象的話,會(huì)發(fā)現(xiàn)絕大多數(shù) NLP 任務(wù)可以歸結(jié)為幾大類任務(wù)。兩個(gè)看似差異很大的任務(wù),在解決任務(wù)的模型角度,可能完全是一樣的。

通常而言,絕大部分 NLP 問(wèn)題可以歸入上圖所示的四類任務(wù)中:
一類是序列標(biāo)注,這是最典型的 NLP 任務(wù),比如中文分詞,詞性標(biāo)注,命名實(shí)體識(shí)別,語(yǔ)義角色標(biāo)注等都可以歸入這一類問(wèn)題,它的特點(diǎn)是句子中每個(gè)單詞要求模型根據(jù)上下文都要給出一個(gè)分類類別。
第二類是分類任務(wù),比如我們常見(jiàn)的文本分類,情感計(jì)算等都可以歸入這一類。它的特點(diǎn)是不管文章有多長(zhǎng),總體給出一個(gè)分類類別即可。
第三類任務(wù)是句子關(guān)系判斷,比如 Entailment,QA,語(yǔ)義改寫(xiě),自然語(yǔ)言推理等任務(wù)都是這個(gè)模式,它的特點(diǎn)是給定兩個(gè)句子,模型判斷出兩個(gè)句子是否具備某種語(yǔ)義關(guān)系;
第四類是生成式任務(wù),比如機(jī)器翻譯,文本摘要,寫(xiě)詩(shī)造句,看圖說(shuō)話等都屬于這一類。它的特點(diǎn)是輸入文本內(nèi)容后,需要自主生成另外一段文字。
解決這些不同的任務(wù),從模型角度來(lái)講什么最重要?是特征抽取器的能力。尤其是深度學(xué)習(xí)流行開(kāi)來(lái)后,這一點(diǎn)更凸顯出來(lái)。因?yàn)樯疃葘W(xué)習(xí)最大的優(yōu)點(diǎn)是 “端到端(end to end)”,當(dāng)然這里不是指的從客戶端到云端,意思是以前研發(fā)人員得考慮設(shè)計(jì)抽取哪些特征,而端到端時(shí)代后,這些你完全不用管,把原始輸入扔給好的特征抽取器,它自己會(huì)把有用的特征抽取出來(lái)。
身為資深 Bug 制造者和算法工程師,你現(xiàn)在需要做的事情就是:選擇一個(gè)好的特征抽取器,選擇一個(gè)好的特征抽取器,選擇一個(gè)好的特征抽取器,喂給它大量的訓(xùn)練數(shù)據(jù),設(shè)定好優(yōu)化目標(biāo)(loss function),告訴它你想讓它干嘛…….. 然后你覺(jué)得你啥也不用干等結(jié)果就行了是吧?那你是我見(jiàn)過(guò)的整個(gè)宇宙中最樂(lè)觀的人……. 你大量時(shí)間其實(shí)是用在調(diào)參上…….。從這個(gè)過(guò)程可以看出,如果我們有個(gè)強(qiáng)大的特征抽取器,那么中初級(jí)算法工程師淪為調(diào)參俠也就是個(gè)必然了,在 AutoML(自動(dòng)那啥)流行的年代,也許以后你想當(dāng)調(diào)參俠而不得,李斯說(shuō)的 “吾欲與若復(fù)牽黃犬,俱出上蔡?hào)|門(mén)逐狡兔,豈可得乎!” 請(qǐng)了解一下。所以請(qǐng)珍惜你半夜兩點(diǎn)還在調(diào)整超參的日子吧,因?yàn)閷?duì)于你來(lái)說(shuō)有一個(gè)好消息一個(gè)壞消息,好消息是:對(duì)于你來(lái)說(shuō)可能這樣辛苦的日子不多了!壞消息是:對(duì)于你來(lái)說(shuō)可能這樣辛苦的日子不多了!!!那么怎么才能成為算法高手?你去設(shè)計(jì)一個(gè)更強(qiáng)大的特征抽取器呀。
下面開(kāi)始分?jǐn)⑷筇卣鞒槿∑鳌?/p>
沙場(chǎng)老將 RNN:廉頗老矣,尚能飯否
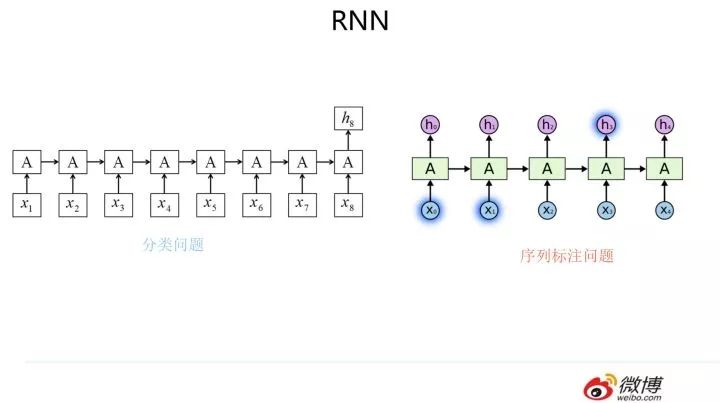
RNN 模型我估計(jì)大家都熟悉,就不詳細(xì)介紹了,模型結(jié)構(gòu)參考上圖,核心是每個(gè)輸入對(duì)應(yīng)隱層節(jié)點(diǎn),而隱層節(jié)點(diǎn)之間形成了線性序列,信息由前向后在隱層之間逐步向后傳遞。我們下面直接進(jìn)入我想講的內(nèi)容。
為何 RNN 能夠成為解決 NLP 問(wèn)題的主流特征抽取器
我們知道,RNN 自從引入 NLP 界后,很快就成為吸引眼球的明星模型,在 NLP 各種任務(wù)中被廣泛使用。但是原始的 RNN 也存在問(wèn)題,它采取線性序列結(jié)構(gòu)不斷從前往后收集輸入信息,但這種線性序列結(jié)構(gòu)在反向傳播的時(shí)候存在優(yōu)化困難問(wèn)題,因?yàn)榉聪騻鞑ヂ窂教L(zhǎng),容易導(dǎo)致嚴(yán)重的梯度消失或梯度爆炸問(wèn)題。為了解決這個(gè)問(wèn)題,后來(lái)引入了 LSTM 和 GRU 模型,通過(guò)增加中間狀態(tài)信息直接向后傳播,以此緩解梯度消失問(wèn)題,獲得了很好的效果,于是很快 LSTM 和 GRU 成為 RNN 的標(biāo)準(zhǔn)模型。其實(shí)圖像領(lǐng)域最早由 HighwayNet/Resnet 等導(dǎo)致模型革命的 skip connection 的原始思路就是從 LSTM 的隱層傳遞機(jī)制借鑒來(lái)的。經(jīng)過(guò)不斷優(yōu)化,后來(lái) NLP 又從圖像領(lǐng)域借鑒并引入了 attention 機(jī)制(從這兩個(gè)過(guò)程可以看到不同領(lǐng)域的相互技術(shù)借鑒與促進(jìn)作用),疊加網(wǎng)絡(luò)把層深作深,以及引入 Encoder-Decoder 框架,這些技術(shù)進(jìn)展極大拓展了 RNN 的能力以及應(yīng)用效果。下圖展示的模型就是非常典型的使用 RNN 來(lái)解決 NLP 任務(wù)的通用框架技術(shù)大禮包,在更新的技術(shù)出現(xiàn)前,你可以在 NLP 各種領(lǐng)域見(jiàn)到這個(gè)技術(shù)大禮包的身影。
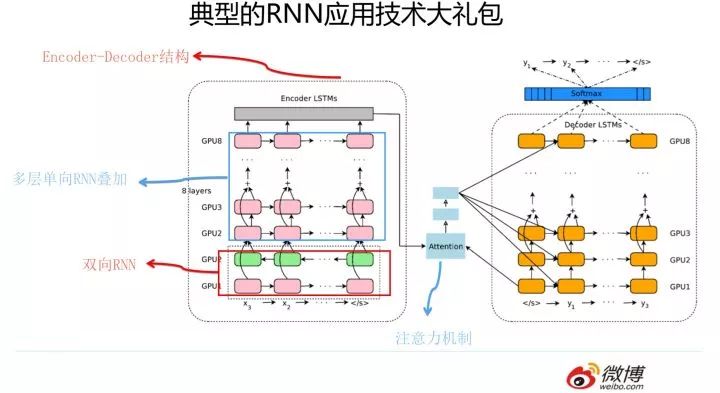
上述內(nèi)容簡(jiǎn)單介紹了 RNN 在 NLP 領(lǐng)域的大致技術(shù)演進(jìn)過(guò)程。那么為什么 RNN 能夠這么快在 NLP 流行并且占據(jù)了主導(dǎo)地位呢?主要原因還是因?yàn)?RNN 的結(jié)構(gòu)天然適配解決 NLP 的問(wèn)題,NLP 的輸入往往是個(gè)不定長(zhǎng)的線性序列句子,而 RNN 本身結(jié)構(gòu)就是個(gè)可以接納不定長(zhǎng)輸入的由前向后進(jìn)行信息線性傳導(dǎo)的網(wǎng)絡(luò)結(jié)構(gòu),而在 LSTM 引入三個(gè)門(mén)后,對(duì)于捕獲長(zhǎng)距離特征也是非常有效的。所以 RNN 特別適合 NLP 這種線形序列應(yīng)用場(chǎng)景,這是 RNN 為何在 NLP 界如此流行的根本原因。
RNN 在新時(shí)代面臨的兩個(gè)嚴(yán)重問(wèn)題
RNN 在 NLP 界一直紅了很多年(2014-2018?),在 2018 年之前,大部分各個(gè)子領(lǐng)域的 State of Art 的結(jié)果都是 RNN 獲得的。但是最近一年來(lái),眼看著 RNN 的領(lǐng)袖群倫的地位正在被動(dòng)搖,所謂各領(lǐng)風(fēng)騷 3-5 年,看來(lái)網(wǎng)紅模型也不例外。
那這又是因?yàn)槭裁茨兀恐饕袃蓚€(gè)原因。
第一個(gè)原因在于一些后起之秀新模型的崛起,比如經(jīng)過(guò)特殊改造的 CNN 模型,以及最近特別流行的 Transformer,這些后起之秀尤其是 Transformer 的應(yīng)用效果相比 RNN 來(lái)說(shuō),目前看具有明顯的優(yōu)勢(shì)。這是個(gè)主要原因,老人如果干不過(guò)新人,又沒(méi)有脫胎換骨自我革命的能力,自然要自覺(jué)或不自愿地退出歷史舞臺(tái),這是自然規(guī)律。至于 RNN 能力偏弱的具體證據(jù),本文后面會(huì)專門(mén)談,這里不展開(kāi)講。當(dāng)然,技術(shù)人員里的 RNN 保皇派們,這個(gè)群體規(guī)模應(yīng)該還是相當(dāng)大的,他們不會(huì)輕易放棄曾經(jīng)這么熱門(mén)過(guò)的流量明星的,所以也想了或者正在想一些改進(jìn)方法,試圖給 RNN 延年益壽。至于這些方法是什么,有沒(méi)有作用,后面也陸續(xù)會(huì)談。
另外一個(gè)嚴(yán)重阻礙 RNN 將來(lái)繼續(xù)走紅的問(wèn)題是:RNN 本身的序列依賴結(jié)構(gòu)對(duì)于大規(guī)模并行計(jì)算來(lái)說(shuō)相當(dāng)之不友好。通俗點(diǎn)說(shuō),就是 RNN 很難具備高效的并行計(jì)算能力,這個(gè)乍一看好像不是太大的問(wèn)題,其實(shí)問(wèn)題很嚴(yán)重。如果你僅僅滿足于通過(guò)改 RNN 發(fā)一篇論文,那么這確實(shí)不是大問(wèn)題,但是如果工業(yè)界進(jìn)行技術(shù)選型的時(shí)候,在有快得多的模型可用的前提下,是不太可能選擇那么慢的模型的。一個(gè)沒(méi)有實(shí)際落地應(yīng)用支撐其存在價(jià)值的模型,其前景如何這個(gè)問(wèn)題,估計(jì)用小腦思考也能得出答案。
那問(wèn)題來(lái)了:為什么 RNN 并行計(jì)算能力比較差?是什么原因造成的?
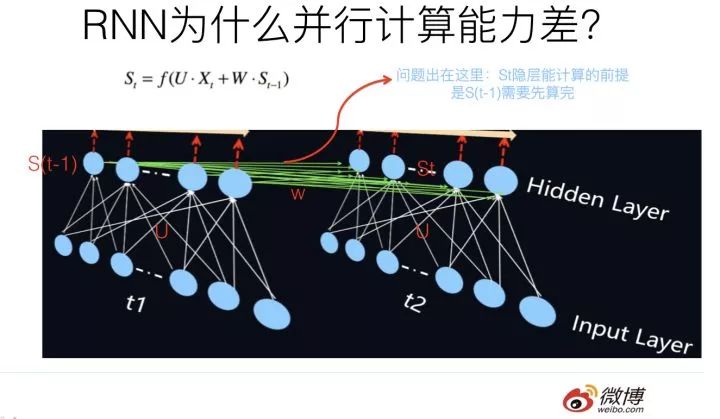
我們知道,RNN 之所以是 RNN,能將其和其它模型區(qū)分開(kāi)的最典型標(biāo)志是:T 時(shí)刻隱層狀態(tài)的計(jì)算,依賴兩個(gè)輸入,一個(gè)是 T 時(shí)刻的句子輸入單詞 Xt,這個(gè)不算特點(diǎn),所有模型都要接收這個(gè)原始輸入;關(guān)鍵的是另外一個(gè)輸入,T 時(shí)刻的隱層狀態(tài) St 還依賴 T-1 時(shí)刻的隱層狀態(tài) S(t-1) 的輸出,這是最能體現(xiàn) RNN 本質(zhì)特征的一點(diǎn),RNN 的歷史信息是通過(guò)這個(gè)信息傳輸渠道往后傳輸?shù)模疽鈪⒖忌蠄D。那么為什么 RNN 的并行計(jì)算能力不行呢?問(wèn)題就出在這里。因?yàn)?T 時(shí)刻的計(jì)算依賴 T-1 時(shí)刻的隱層計(jì)算結(jié)果,而 T-1 時(shí)刻的計(jì)算依賴 T-2 時(shí)刻的隱層計(jì)算結(jié)果…….. 這樣就形成了所謂的序列依賴關(guān)系。就是說(shuō)只能先把第 1 時(shí)間步的算完,才能算第 2 時(shí)間步的結(jié)果,這就造成了 RNN 在這個(gè)角度上是無(wú)法并行計(jì)算的,只能老老實(shí)實(shí)地按著時(shí)間步一個(gè)單詞一個(gè)單詞往后走。
而 CNN 和 Transformer 就不存在這種序列依賴問(wèn)題,所以對(duì)于這兩者來(lái)說(shuō)并行計(jì)算能力就不是問(wèn)題,每個(gè)時(shí)間步的操作可以并行一起計(jì)算。
那么能否針對(duì)性地對(duì) RNN 改造一下,提升它的并行計(jì)算能力呢?如果可以的話,效果如何呢?下面我們討論一下這個(gè)問(wèn)題。
如何改造 RNN 使其具備并行計(jì)算能力?
上面說(shuō)過(guò),RNN 不能并行計(jì)算的癥結(jié)所在,在于 T 時(shí)刻對(duì) T-1 時(shí)刻計(jì)算結(jié)果的依賴,而這體現(xiàn)在隱層之間的全連接網(wǎng)絡(luò)上。既然癥結(jié)在這里,那么要想解決問(wèn)題,也得在這個(gè)環(huán)節(jié)下手才行。在這個(gè)環(huán)節(jié)多做點(diǎn)什么事情能夠增加 RNN 的并行計(jì)算能力呢?你可以想一想。
其實(shí)留給你的選項(xiàng)并不多,你可以有兩個(gè)大的思路來(lái)改進(jìn):一種是仍然保留任意連續(xù)時(shí)間步(T-1 到 T 時(shí)刻)之間的隱層連接;而另外一種是部分地打斷連續(xù)時(shí)間步(T-1 到 T 時(shí)刻)之間的隱層連接 。
我們先來(lái)看第一種方法,現(xiàn)在我們的問(wèn)題轉(zhuǎn)化成了:我們?nèi)匀灰A羧我膺B續(xù)時(shí)間步(T-1 到 T 時(shí)刻)之間的隱層連接,但是在這個(gè)前提下,我們還要能夠做到并行計(jì)算,這怎么處理呢?因?yàn)橹灰A暨B續(xù)兩個(gè)時(shí)間步的隱層連接,則意味著要計(jì)算 T 時(shí)刻的隱層結(jié)果,就需要 T-1 時(shí)刻隱層結(jié)果先算完,這不又落入了序列依賴的陷阱里了嗎?嗯,確實(shí)是這樣,但是為什么一定要在不同時(shí)間步的輸入之間并行呢?沒(méi)有人說(shuō) RNN 的并行計(jì)算一定發(fā)生在不同時(shí)間步上啊,你想想,隱層是不是也是包含很多神經(jīng)元?那么在隱層神經(jīng)元之間并行計(jì)算行嗎?如果你要是還沒(méi)理解這是什么意思,那請(qǐng)看下圖。

上面的圖只顯示了各個(gè)時(shí)間步的隱層節(jié)點(diǎn),每個(gè)時(shí)間步的隱層包含 3 個(gè)神經(jīng)元,這是個(gè)俯視圖,是從上往下看 RNN 的隱層節(jié)點(diǎn)的。另外,連續(xù)兩個(gè)時(shí)間步的隱層神經(jīng)元之間仍然有連接,上圖沒(méi)有畫(huà)出來(lái)是為了看著簡(jiǎn)潔一些。這下應(yīng)該明白了吧,假設(shè)隱層神經(jīng)元有 3 個(gè),那么我們可以形成 3 路并行計(jì)算(紅色箭頭分隔開(kāi)成了三路),而每一路因?yàn)槿匀淮嬖谛蛄幸蕾噯?wèn)題,所以每一路內(nèi)仍然是串行的。大思路應(yīng)該明白了是吧?但是了解 RNN 結(jié)構(gòu)的同學(xué)會(huì)發(fā)現(xiàn)這樣還遺留一個(gè)問(wèn)題:隱層神經(jīng)元之間的連接是全連接,就是說(shuō) T 時(shí)刻某個(gè)隱層神經(jīng)元與 T-1 時(shí)刻所有隱層神經(jīng)元都有連接,如果是這樣,是無(wú)法做到在神經(jīng)元之間并行計(jì)算的,你可以想想為什么,這個(gè)簡(jiǎn)單,我假設(shè)你有能力想明白。那么怎么辦呢?很簡(jiǎn)單,T 時(shí)刻和 T-1 時(shí)刻的隱層神經(jīng)元之間的連接關(guān)系需要改造,從之前的全連接,改造成對(duì)應(yīng)位置的神經(jīng)元(就是上圖被紅箭頭分隔到同一行的神經(jīng)元之間)有連接,和其它神經(jīng)元沒(méi)有連接。這樣就可以解決這個(gè)問(wèn)題,在不同路的隱層神經(jīng)元之間可以并行計(jì)算了。
第一種改造 RNN 并行計(jì)算能力的方法思路大致如上所述,這種方法的代表就是論文 “Simple Recurrent Units for Highly Parallelizable Recurrence” 中提出的SRU 方法,它最本質(zhì)的改進(jìn)是把隱層之間的神經(jīng)元依賴由全連接改成了哈達(dá)馬乘積,這樣 T 時(shí)刻隱層單元本來(lái)對(duì) T-1 時(shí)刻所有隱層單元的依賴,改成了只是對(duì) T-1 時(shí)刻對(duì)應(yīng)單元的依賴,于是可以在隱層單元之間進(jìn)行并行計(jì)算,但是收集信息仍然是按照時(shí)間序列來(lái)進(jìn)行的。所以其并行性是在隱層單元之間發(fā)生的,而不是在不同時(shí)間步之間發(fā)生的。
這其實(shí)是比較巧妙的一種方法,但是它的問(wèn)題在于其并行程度上限是有限的,并行程度取決于隱層神經(jīng)元個(gè)數(shù),而一般這個(gè)數(shù)值往往不會(huì)太大,再增加并行性已經(jīng)不太可能。另外每一路并行線路仍然需要序列計(jì)算,這也會(huì)拖慢整體速度。SRU 的測(cè)試速度為:在文本分類上和原始 CNN(Kim 2014)的速度相當(dāng),論文沒(méi)有說(shuō) CNN 是否采取了并行訓(xùn)練方法。 其它在復(fù)雜任務(wù)閱讀理解及 MT 任務(wù)上只做了效果評(píng)估,沒(méi)有和 CNN 進(jìn)行速度比較,我估計(jì)這是有原因的,因?yàn)閺?fù)雜任務(wù)往往需要深層網(wǎng)絡(luò),其它的就不妄作猜測(cè)了。

第二種改進(jìn)典型的思路是:為了能夠在不同時(shí)間步輸入之間進(jìn)行并行計(jì)算,那么只有一種做法,那就是打斷隱層之間的連接,但是又不能全打斷,因?yàn)檫@樣基本就無(wú)法捕獲組合特征了,所以唯一能選的策略就是部分打斷,比如每隔 2 個(gè)時(shí)間步打斷一次,但是距離稍微遠(yuǎn)點(diǎn)的特征如何捕獲呢?只能加深層深,通過(guò)層深來(lái)建立遠(yuǎn)距離特征之間的聯(lián)系。代表性模型比如上圖展示的 Sliced RNN。我當(dāng)初看到這個(gè)模型的時(shí)候,心里忍不住發(fā)出杠鈴般的笑聲,情不自禁地走上前跟他打了個(gè)招呼:你好呀,CNN 模型,想不到你這個(gè)糙漢子有一天也會(huì)穿上粉色裙裝,裝扮成 RNN 的樣子出現(xiàn)在我面前啊,哈哈。了解 CNN 模型的同學(xué)看到我上面這句話估計(jì)會(huì)莞爾會(huì)心一笑:這不就是簡(jiǎn)化版本的 CNN 嗎?不了解 CNN 的同學(xué)建議看完后面 CNN 部分再回頭來(lái)看看是不是這個(gè)意思。
那經(jīng)過(guò)這種改造的 RNN 速度改進(jìn)如何呢?論文給出了速度對(duì)比實(shí)驗(yàn),歸納起來(lái),SRNN 速度比 GRU 模型快 5 到 15 倍,嗯,效果不錯(cuò),但是跟對(duì)比模型 DC-CNN 模型速度比較起來(lái),比 CNN 模型仍然平均慢了大約 3 倍。這很正常但是又有點(diǎn)說(shuō)不太過(guò)去,說(shuō)正常是因?yàn)楸緛?lái)這就是把 RNN 改頭換面成類似 CNN 的結(jié)構(gòu),而片段里仍然采取 RNN 序列模型,所以必然會(huì)拉慢速度,比 CNN 慢再正常不過(guò)了。說(shuō) “說(shuō)不過(guò)去” 是指的是:既然本質(zhì)上是 CNN,速度又比 CNN 慢,那么這么改的意義在哪里?為什么不直接用 CNN 呢?是不是?前面那位因?yàn)槌蕴澇缘纳偎詯?ài)抬杠的同學(xué)又會(huì)說(shuō)了:也許人家效果特別好呢。嗯,從這個(gè)結(jié)構(gòu)的作用機(jī)制上看,可能性不太大。你說(shuō)論文實(shí)驗(yàn)部分證明了這一點(diǎn)呀,我認(rèn)為實(shí)驗(yàn)部分對(duì)比試驗(yàn)做的不充分,需要補(bǔ)充除了 DC-CNN 外的其他 CNN 模型進(jìn)行對(duì)比。當(dāng)然這點(diǎn)純屬個(gè)人意見(jiàn),別當(dāng)真,因?yàn)槲抑v起話來(lái)的時(shí)候經(jīng)常搖頭晃腦,此時(shí)一般會(huì)有人驚奇地跟我反饋說(shuō):為什么你一講話我就聽(tīng)到了水聲?
上面列舉了兩種大的改進(jìn) RNN 并行計(jì)算能力的思路,我個(gè)人對(duì)于 RNN 的并行計(jì)算能力持悲觀態(tài)度,主要因?yàn)?RNN 本質(zhì)特性決定了我們能做的選擇太少。無(wú)非就是選擇打斷還是不打斷隱層連接的問(wèn)題。如果選擇打斷,就會(huì)面臨上面的問(wèn)題,你會(huì)發(fā)現(xiàn)它可能已經(jīng)不是 RNN 模型了,為了讓它看上去還像是 RNN,所以在打斷片段里仍然采取 RNN 結(jié)構(gòu),這樣無(wú)疑會(huì)拉慢速度,所以這是個(gè)兩難的選擇,與其這樣不如直接換成其它模型;如果我們選擇不打斷,貌似只能在隱層神經(jīng)元之間進(jìn)行并行,而這樣做的缺點(diǎn)是:一方面并行能力上限很低;另外一方面里面依然存在的序列依賴估計(jì)仍然是個(gè)問(wèn)題。這是為何悲觀的原因,主要是看不到大的希望。
偏師之將 CNN:刺激戰(zhàn)場(chǎng)絕地求生
在一年多前,CNN 是自然語(yǔ)言處理中除了 RNN 外最常見(jiàn)的深度學(xué)習(xí)模型,這里介紹下 CNN 特征抽取器,會(huì)比 RNN 說(shuō)得詳細(xì)些,主要考慮到大家對(duì)它的熟悉程度可能沒(méi)有 RNN 那么高。
NLP 中早期的懷舊版 CNN 模型
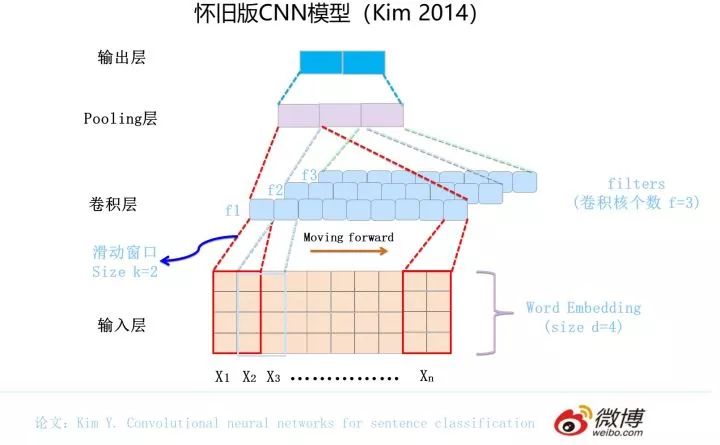
最早將 CNN 引入 NLP 的是 Kim 在 2014 年做的工作,論文和網(wǎng)絡(luò)結(jié)構(gòu)參考上圖。一般而言,輸入的字或者詞用Word Embedding的方式表達(dá),這樣本來(lái)一維的文本信息輸入就轉(zhuǎn)換成了二維的輸入結(jié)構(gòu),假設(shè)輸入 X 包含 n 個(gè)字符,而每個(gè)字符的 Word Embedding 的長(zhǎng)度為 d,那么輸入就是 d*n 的二維向量。
卷積層本質(zhì)上是個(gè)特征抽取層,可以設(shè)定超參數(shù) F 來(lái)指定卷積層包含多少個(gè)卷積核(Filter)。對(duì)于某個(gè) Filter 來(lái)說(shuō),可以想象有一個(gè) d*k 大小的移動(dòng)窗口從輸入矩陣的第一個(gè)字開(kāi)始不斷往后移動(dòng),其中 k 是 Filter 指定的窗口大小,d 是 Word Embedding 長(zhǎng)度。對(duì)于某個(gè)時(shí)刻的窗口,通過(guò)神經(jīng)網(wǎng)絡(luò)的非線性變換,將這個(gè)窗口內(nèi)的輸入值轉(zhuǎn)換為某個(gè)特征值,隨著窗口不斷往后移動(dòng),這個(gè) Filter 對(duì)應(yīng)的特征值不斷產(chǎn)生,形成這個(gè) Filter 的特征向量。這就是卷積核抽取特征的過(guò)程。卷積層內(nèi)每個(gè) Filter 都如此操作,就形成了不同的特征序列。Pooling 層則對(duì) Filter 的特征進(jìn)行降維操作,形成最終的特征。一般在 Pooling 層之后連接全聯(lián)接層神經(jīng)網(wǎng)絡(luò),形成最后的分類過(guò)程。
這就是最早應(yīng)用在 NLP 領(lǐng)域 CNN 模型的工作機(jī)制,用來(lái)解決 NLP 中的句子分類任務(wù),看起來(lái)還是很簡(jiǎn)潔的,之后陸續(xù)出現(xiàn)了在此基礎(chǔ)上的改進(jìn)模型。這些懷舊版 CNN 模型在一些任務(wù)上也能和當(dāng)時(shí)懷舊版本的 RNN 模型效果相當(dāng),所以在 NLP 若干領(lǐng)域也能野蠻生長(zhǎng),但是在更多的 NLP 領(lǐng)域,還是處于被 RNN 模型壓制到抑郁癥早期的尷尬局面。那為什么在圖像領(lǐng)域打遍天下無(wú)敵手的 CNN,一旦跑到 NLP 的地盤(pán),就被 RNN 這個(gè)地頭蛇壓制得無(wú)顏見(jiàn)圖像領(lǐng)域江東父老呢?這說(shuō)明這個(gè)版本的 CNN 還是有很多問(wèn)題的,其實(shí)最根本的癥結(jié)所在還是老革命遇到了新問(wèn)題,主要是到了新環(huán)境沒(méi)有針對(duì)新環(huán)境的特性做出針對(duì)性的改變,所以面臨水土不服的問(wèn)題。
CNN 能在 RNN 縱橫的各種 NLP 任務(wù)環(huán)境下生存下來(lái)嗎?謎底即將揭曉。
CNN 的進(jìn)化:物競(jìng)天擇的模型斗獸場(chǎng)
下面我們先看看懷舊版 CNN 存在哪些問(wèn)題,然后看看我們的 NLP 專家們是如何改造 CNN,一直改到目前看上去還算效果不錯(cuò)的現(xiàn)代版本 CNN 的。
首先,我們先要明確一點(diǎn):CNN 捕獲到的是什么特征呢?從上述懷舊版本 CNN 卷積層的運(yùn)作機(jī)制你大概看出來(lái)了,關(guān)鍵在于卷積核覆蓋的那個(gè)滑動(dòng)窗口,CNN 能捕獲到的特征基本都體現(xiàn)在這個(gè)滑動(dòng)窗口里了。大小為 k 的滑動(dòng)窗口輕輕的穿過(guò)句子的一個(gè)個(gè)單詞,蕩起陣陣漣漪,那么它捕獲了什么? 其實(shí)它捕獲到的是單詞的 k-gram 片段信息,這些 k-gram 片段就是 CNN 捕獲到的特征,k 的大小決定了能捕獲多遠(yuǎn)距離的特征。

說(shuō)完這個(gè),我們來(lái)看 Kim 版 CNN 的第一個(gè)問(wèn)題:它只有一個(gè)卷積層。表面看上去好像是深度不夠的問(wèn)題是吧?我會(huì)反問(wèn)你說(shuō):為什么要把 CNN 作深呢?其實(shí)把深度做起來(lái)是手段,不是目的。只有一個(gè)卷積層帶來(lái)的問(wèn)題是:對(duì)于遠(yuǎn)距離特征,單層 CNN 是無(wú)法捕獲到的,如果滑動(dòng)窗口 k 最大為 2,而如果有個(gè)遠(yuǎn)距離特征距離是 5,那么無(wú)論上多少個(gè)卷積核,都無(wú)法覆蓋到長(zhǎng)度為 5 的距離的輸入,所以它是無(wú)法捕獲長(zhǎng)距離特征的。
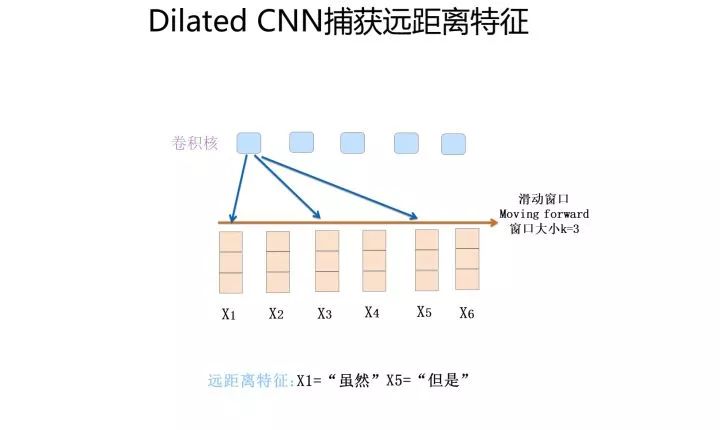
那么怎樣才能捕獲到長(zhǎng)距離的特征呢?有兩種典型的改進(jìn)方法:一種是假設(shè)我們?nèi)匀挥脝蝹€(gè)卷積層,滑動(dòng)窗口大小 k 假設(shè)為 3,就是只接收三個(gè)輸入單詞,但是我們想捕獲距離為 5 的特征,怎么做才行?顯然,如果卷積核窗口仍然覆蓋連續(xù)區(qū)域,這肯定是完不成任務(wù)的。提示一下:你玩過(guò)跳一跳是吧?能采取類似策略嗎?對(duì),你可以跳著覆蓋呀,是吧?這就是Dilated 卷積的基本思想,確實(shí)也是一種解決方法。
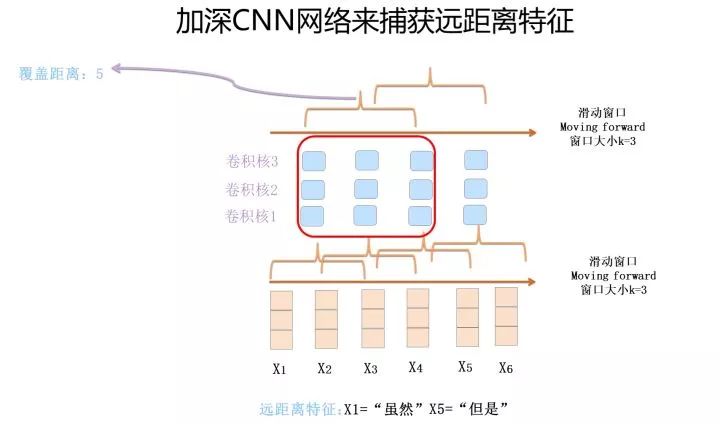
第二種方法是把深度做起來(lái)。第一層卷積層,假設(shè)滑動(dòng)窗口大小 k 是 3,如果再往上疊一層卷積層,假設(shè)滑動(dòng)窗口大小也是 3,但是第二層窗口覆蓋的是第一層窗口的輸出特征,所以它其實(shí)能覆蓋輸入的距離達(dá)到了 5。如果繼續(xù)往上疊加卷積層,可以繼續(xù)增大卷積核覆蓋輸入的長(zhǎng)度。
上面是兩種典型的解決 CNN 遠(yuǎn)距離特征捕獲能力的方案,Dilated CNN 偏技巧一些,而且疊加卷積層時(shí)超參如何設(shè)置有些學(xué)問(wèn),因?yàn)檫B續(xù)跳接可能會(huì)錯(cuò)過(guò)一些特征組合,所以需要精心調(diào)節(jié)參數(shù)搭配,保證所有可能組合都被覆蓋到。相對(duì)而言,把 CNN 作深是主流發(fā)展方向。上面這個(gè)道理好理解,其實(shí)自從 CNN 一出現(xiàn),人們就想各種辦法試圖把 CNN 的深度做起來(lái),但是現(xiàn)實(shí)往往是無(wú)情的,發(fā)現(xiàn)怎么折騰,CNN 做 NLP 問(wèn)題就是做不深,做到 2 到 3 層卷積層就做不上去了,網(wǎng)絡(luò)更深對(duì)任務(wù)效果沒(méi)什么幫助(請(qǐng)不要拿 CharCNN 來(lái)做反例,后來(lái)研究表明使用單詞的 2 層 CNN 效果超過(guò) CharCNN)。目前看來(lái),還是深層網(wǎng)絡(luò)參數(shù)優(yōu)化手段不足導(dǎo)致的這個(gè)問(wèn)題,而不是層深沒(méi)有用。后來(lái) Resnet 等圖像領(lǐng)域的新技術(shù)出現(xiàn)后,很自然地,人們會(huì)考慮把 Skip Connection 及各種 Norm 等參數(shù)優(yōu)化技術(shù)引入,這才能慢慢把 CNN 的網(wǎng)絡(luò)深度做起來(lái)。
上面說(shuō)的是 Kim 版本 CNN 的第一個(gè)問(wèn)題,無(wú)法捕獲遠(yuǎn)距離特征的問(wèn)題,以及后面科研人員提出的主要解決方案。回頭看 Kim 版本 CNN 還有一個(gè)問(wèn)題,就是那個(gè) Max Pooling 層,這塊其實(shí)與 CNN 能否保持輸入句子中單詞的位置信息有關(guān)系。首先我想問(wèn)個(gè)問(wèn)題:RNN 因?yàn)槭蔷€性序列結(jié)構(gòu),所以很自然它天然就會(huì)把位置信息編碼進(jìn)去;那么,CNN 是否能夠保留原始輸入的相對(duì)位置信息呢?我們前面說(shuō)過(guò)對(duì)于 NLP 問(wèn)題來(lái)說(shuō),位置信息是很有用的。其實(shí) CNN 的卷積核是能保留特征之間的相對(duì)位置的,道理很簡(jiǎn)單,滑動(dòng)窗口從左到右滑動(dòng),捕獲到的特征也是如此順序排列,所以它在結(jié)構(gòu)上已經(jīng)記錄了相對(duì)位置信息了。但是如果卷積層后面立即接上 Pooling 層的話,Max Pooling 的操作邏輯是:從一個(gè)卷積核獲得的特征向量里只選中并保留最強(qiáng)的那一個(gè)特征,所以到了 Pooling 層,位置信息就被扔掉了,這在 NLP 里其實(shí)是有信息損失的。所以在 NLP 領(lǐng)域里,目前 CNN 的一個(gè)發(fā)展趨勢(shì)是拋棄 Pooling 層,靠全卷積層來(lái)疊加網(wǎng)絡(luò)深度,這背后是有原因的(當(dāng)然圖像領(lǐng)域也是這個(gè)趨勢(shì))。
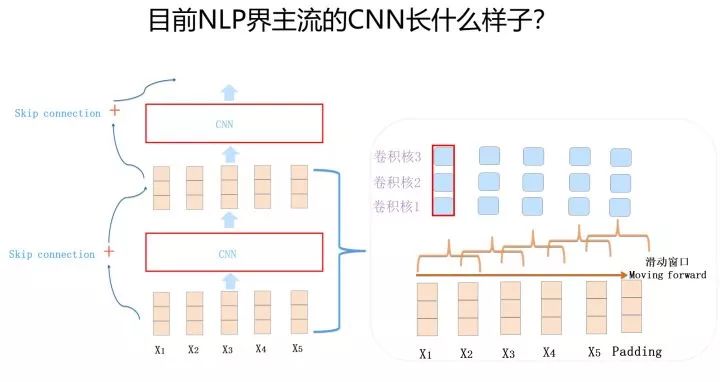
上圖展示了在 NLP 領(lǐng)域能夠施展身手的摩登 CNN 的主體結(jié)構(gòu),通常由 1-D 卷積層來(lái)疊加深度,使用 Skip Connection 來(lái)輔助優(yōu)化,也可以引入 Dilated CNN 等手段。比如 ConvS2S 主體就是上圖所示結(jié)構(gòu),Encoder 包含 15 個(gè)卷積層,卷積核 kernel size=3,覆蓋輸入長(zhǎng)度為 25。當(dāng)然對(duì)于 ConvS2S 來(lái)說(shuō),卷積核里引入 GLU 門(mén)控非線性函數(shù)也有重要幫助,限于篇幅,這里不展開(kāi)說(shuō)了,GLU 貌似是 NLP 里 CNN 模型必備的構(gòu)件,值得掌握。再比如 TCN(論文:An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling),集成了幾項(xiàng)技術(shù):利用 Dilated CNN 拓展單層卷積層的輸入覆蓋長(zhǎng)度,利用全卷積層堆疊層深,使用 Skip Connection 輔助優(yōu)化,引入 Casual CNN 讓網(wǎng)絡(luò)結(jié)構(gòu)看不到 T 時(shí)間步后的數(shù)據(jù)。不過(guò) TCN 的實(shí)驗(yàn)做得有兩個(gè)明顯問(wèn)題:一個(gè)問(wèn)題是任務(wù)除了語(yǔ)言模型外都不是典型的 NLP 任務(wù),而是合成數(shù)據(jù)任務(wù),所以論文結(jié)論很難直接說(shuō)就適合 NLP 領(lǐng)域;另外一點(diǎn),它用來(lái)進(jìn)行效果比較的對(duì)比方法,沒(méi)有用當(dāng)時(shí)效果很好的模型來(lái)對(duì)比,比較基準(zhǔn)低。所以 TCN 的模型效果說(shuō)服力不太夠。其實(shí)它該引入的元素也基本引入了,實(shí)驗(yàn)說(shuō)服力不夠,我覺(jué)得可能是它命中缺 GLU 吧。
除此外,簡(jiǎn)單談一下 CNN 的位置編碼問(wèn)題和并行計(jì)算能力問(wèn)題。上面說(shuō)了,CNN 的卷積層其實(shí)是保留了相對(duì)位置信息的,只要你在設(shè)計(jì)模型的時(shí)候別手賤,中間層不要隨手瞎插入 Pooling 層,問(wèn)題就不大,不專門(mén)在輸入部分對(duì) position 進(jìn)行編碼也行。但是也可以類似 ConvS2S 那樣,專門(mén)在輸入部分給每個(gè)單詞增加一個(gè) position embedding,將單詞的 position embedding 和詞向量 embedding 疊加起來(lái)形成單詞輸入,這樣也可以,也是常規(guī)做法。
至于 CNN 的并行計(jì)算能力,那是非常強(qiáng)的,這其實(shí)很好理解。我們考慮單層卷積層,首先對(duì)于某個(gè)卷積核來(lái)說(shuō),每個(gè)滑動(dòng)窗口位置之間沒(méi)有依賴關(guān)系,所以完全可以并行計(jì)算;另外,不同的卷積核之間也沒(méi)什么相互影響,所以也可以并行計(jì)算。CNN 的并行度是非常自由也非常高的,這是 CNN 的一個(gè)非常好的優(yōu)點(diǎn)。
以上內(nèi)容介紹了懷舊版 CNN 是如何在 NLP 修羅場(chǎng)一步步通過(guò)自我進(jìn)化生存到今天的。CNN 的進(jìn)化方向,如果千言萬(wàn)語(yǔ)一句話歸納的話,那就是:想方設(shè)法把 CNN 的深度做起來(lái),隨著深度的增加,很多看似無(wú)關(guān)的問(wèn)題就隨之解決了。就跟我們國(guó)家最近 40 年的主旋律是發(fā)展經(jīng)濟(jì)一樣,經(jīng)濟(jì)發(fā)展好了,很多問(wèn)題就不是問(wèn)題了。最近幾年之所以大家感到各方面很困難,癥結(jié)就在于經(jīng)濟(jì)不行了,所以很多問(wèn)題無(wú)法通過(guò)經(jīng)濟(jì)帶動(dòng)來(lái)解決,于是看似各種花樣的困難就冒出來(lái),這是一個(gè)道理。
那么介紹了這么多,摩登版 CNN 效果如何呢?與 RNN 及 Transforme 比起來(lái)怎樣?別著急,后面會(huì)專門(mén)談這個(gè)問(wèn)題。
白衣騎士 Transformer:蓋世英雄站上舞臺(tái)
Transformer 是谷歌在 17 年做機(jī)器翻譯任務(wù)的 “Attention is all you need” 的論文中提出的,引起了相當(dāng)大的反響。 每一位從事 NLP 研發(fā)的同仁都應(yīng)該透徹搞明白 Transformer,它的重要性毫無(wú)疑問(wèn),尤其是你在看完我這篇文章之后,我相信你的緊迫感會(huì)更迫切,我就是這么一位善于制造焦慮的能手。不過(guò)這里沒(méi)打算重點(diǎn)介紹它,想要入門(mén) Transformer 的可以參考以下三篇文章:一個(gè)是 Jay Alammar 可視化地介紹 Transformer 的博客文章The Illustrated Transformer,非常容易理解整個(gè)機(jī)制,建議先從這篇看起,這是中文翻譯版本;第二篇是 Calvo 的博客:Dissecting BERT Part 1: The Encoder,盡管說(shuō)是解析 Bert,但是因?yàn)?Bert 的 Encoder 就是 Transformer,所以其實(shí)它是在解析 Transformer,里面舉的例子很好;再然后可以進(jìn)階一下,參考哈佛大學(xué) NLP 研究組寫(xiě)的 “The Annotated Transformer.”,代碼原理雙管齊下,講得也很清楚。
下面只說(shuō)跟本文主題有關(guān)的內(nèi)容。
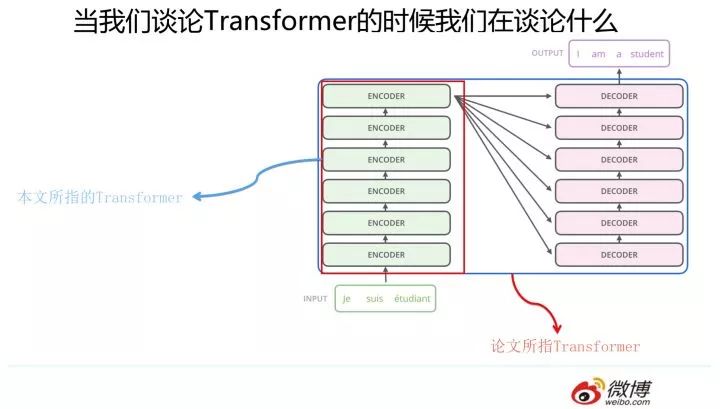
這里要澄清一下,本文所說(shuō)的 Transformer 特征抽取器并非原始論文所指。我們知道,“Attention is all you need” 論文中說(shuō)的的 Transformer 指的是完整的 Encoder-Decoder 框架,而我這里是從特征提取器角度來(lái)說(shuō)的,你可以簡(jiǎn)單理解為論文中的 Encoder 部分。因?yàn)?Encoder 部分目的比較單純,就是從原始句子中提取特征,而 Decoder 部分則功能相對(duì)比較多,除了特征提取功能外,還包含語(yǔ)言模型功能,以及用 attention 機(jī)制表達(dá)的翻譯模型功能。所以這里請(qǐng)注意,避免后續(xù)理解概念產(chǎn)生混淆。
Transformer 的 Encoder 部分(不是上圖一個(gè)一個(gè)的標(biāo)為 encoder 的模塊,而是紅框內(nèi)的整體,上圖來(lái)自 The Illustrated Transformer,Jay Alammar 把每個(gè) Block 稱為 Encoder 不太符合常規(guī)叫法)是由若干個(gè)相同的 Transformer Block 堆疊成的。 這個(gè) Transformer Block 其實(shí)才是 Transformer 最關(guān)鍵的地方,核心配方就在這里。那么它長(zhǎng)什么樣子呢?

它的照片見(jiàn)上圖,看上去是不是很可愛(ài),有點(diǎn)像安卓機(jī)器人是吧?這里需要強(qiáng)調(diào)一下,盡管 Transformer 原始論文一直重點(diǎn)在說(shuō) Self Attention,但是目前來(lái)看,能讓 Transformer 效果好的,不僅僅是 Self attention,這個(gè) Block 里所有元素,包括 Multi-head self attention,Skip connection,LayerNorm,F(xiàn)F 一起在發(fā)揮作用。為什么這么說(shuō)?你看到后面會(huì)體會(huì)到這一點(diǎn)。
我們針對(duì) NLP 任務(wù)的特點(diǎn)來(lái)說(shuō)下 Transformer 的對(duì)應(yīng)解決方案。首先,自然語(yǔ)言一般是個(gè)不定長(zhǎng)的句子,那么這個(gè)不定長(zhǎng)問(wèn)題怎么解決呢?Transformer 做法跟 CNN 是類似的,一般設(shè)定輸入的最大長(zhǎng)度,如果句子沒(méi)那么長(zhǎng),則用 Padding 填充,這樣整個(gè)模型輸入起碼看起來(lái)是定長(zhǎng)的了。另外,NLP 句子中單詞之間的相對(duì)位置是包含很多信息的,上面提過(guò),RNN 因?yàn)榻Y(jié)構(gòu)就是線性序列的,所以天然會(huì)將位置信息編碼進(jìn)模型;而 CNN 的卷積層其實(shí)也是保留了位置相對(duì)信息的,所以什么也不做問(wèn)題也不大。但是對(duì)于 Transformer 來(lái)說(shuō),為了能夠保留輸入句子單詞之間的相對(duì)位置信息,必須要做點(diǎn)什么。為啥它必須要做點(diǎn)什么呢?因?yàn)檩斎氲牡谝粚泳W(wǎng)絡(luò)是 Muli-head self attention 層,我們知道,Self attention 會(huì)讓當(dāng)前輸入單詞和句子中任意單詞發(fā)生關(guān)系,然后集成到一個(gè) embedding 向量里,但是當(dāng)所有信息到了 embedding 后,位置信息并沒(méi)有被編碼進(jìn)去。所以,Transformer 不像 RNN 或 CNN,必須明確的在輸入端將 Positon 信息編碼,Transformer 是用位置函數(shù)來(lái)進(jìn)行位置編碼的,而 Bert 等模型則給每個(gè)單詞一個(gè) Position embedding,將單詞 embedding 和單詞對(duì)應(yīng)的 position embedding 加起來(lái)形成單詞的輸入 embedding,類似上文講的 ConvS2S 的做法。而關(guān)于 NLP 句子中長(zhǎng)距離依賴特征的問(wèn)題,Self attention 天然就能解決這個(gè)問(wèn)題,因?yàn)樵诩尚畔⒌臅r(shí)候,當(dāng)前單詞和句子中任意單詞都發(fā)生了聯(lián)系,所以一步到位就把這個(gè)事情做掉了。不像 RNN 需要通過(guò)隱層節(jié)點(diǎn)序列往后傳,也不像 CNN 需要通過(guò)增加網(wǎng)絡(luò)深度來(lái)捕獲遠(yuǎn)距離特征,Transformer 在這點(diǎn)上明顯方案是相對(duì)簡(jiǎn)單直觀的。說(shuō)這些是為了單獨(dú)介紹下 Transformer 是怎樣解決 NLP 任務(wù)幾個(gè)關(guān)鍵點(diǎn)的。
Transformer 有兩個(gè)版本:Transformer base和Transformer Big。兩者結(jié)構(gòu)其實(shí)是一樣的,主要區(qū)別是包含的 Transformer Block 數(shù)量不同,Transformer base 包含 12 個(gè) Block 疊加,而 Transformer Big 則擴(kuò)張一倍,包含 24 個(gè) Block。無(wú)疑 Transformer Big 在網(wǎng)絡(luò)深度,參數(shù)量以及計(jì)算量相對(duì) Transformer base 翻倍,所以是相對(duì)重的一個(gè)模型,但是效果也最好。
華山論劍:三大特征抽取器比較
結(jié)合 NLP 領(lǐng)域自身的特點(diǎn),上面幾個(gè)部分分別介紹了 RNN/CNN/Transformer 各自的特性。從上面的介紹,看上去好像三大特征抽取器在 NLP 領(lǐng)域里各有所長(zhǎng),推想起來(lái)要是把它們拉到 NLP 任務(wù)競(jìng)技場(chǎng)角斗,一定是互有勝負(fù),各擅勝場(chǎng)吧?
事實(shí)究竟如何呢?是三個(gè)特征抽取器三花齊放還是某一個(gè)一枝獨(dú)秀呢?我們通過(guò)一些實(shí)驗(yàn)來(lái)說(shuō)明這個(gè)問(wèn)題。
為了更細(xì)致和公平地做對(duì)三者進(jìn)行比較,我準(zhǔn)備從幾個(gè)不同的角度來(lái)分別進(jìn)行對(duì)比,我原先打算從以下幾個(gè)維度來(lái)進(jìn)行分析判斷:句法特征提取能力;語(yǔ)義特征提取能力;長(zhǎng)距離特征捕獲能力;任務(wù)綜合特征抽取能力。上面四個(gè)角度是從 NLP 的特征抽取器能力強(qiáng)弱角度來(lái)評(píng)判的,另外再加入并行計(jì)算能力及運(yùn)行效率,這是從是否方便大規(guī)模實(shí)用化的角度來(lái)看的。
因?yàn)槟壳瓣P(guān)于特征抽取器句法特征抽取能力方面進(jìn)行比較的文獻(xiàn)很少,好像只看到一篇文章,結(jié)論是 CNN 在句法特征提取能力要強(qiáng)于 RNN,但是因?yàn)槭潜容^早的文章,而且沒(méi)有對(duì)比 transformer 在句法特征抽取方面的能力,所以這塊很難單獨(dú)比較,于是我就簡(jiǎn)化為對(duì)以下幾項(xiàng)能力的對(duì)比:
語(yǔ)義特征提取能力;
長(zhǎng)距離特征捕獲能力;
任務(wù)綜合特征抽取能力;
并行計(jì)算能力及運(yùn)行效率
三者在這些維度各自表現(xiàn)如何呢?下面我們分頭進(jìn)行說(shuō)明。
語(yǔ)義特征提取能力
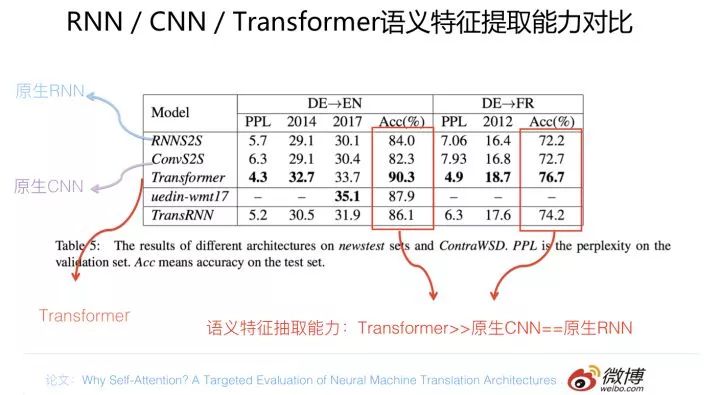
從語(yǔ)義特征提取能力來(lái)說(shuō),目前實(shí)驗(yàn)支持如下結(jié)論:Transformer 在這方面的能力非常顯著地超過(guò) RNN 和 CNN(在考察語(yǔ)義類能力的任務(wù) WSD 中,Transformer 超過(guò) RNN 和 CNN 大約 4-8 個(gè)絕對(duì)百分點(diǎn)),RNN 和 CNN 兩者能力差不太多。
長(zhǎng)距離特征捕獲能力

在長(zhǎng)距離特征捕獲能力方面,目前在特定的長(zhǎng)距離特征捕獲能力測(cè)試任務(wù)中(主語(yǔ) - 謂語(yǔ)一致性檢測(cè),比如 we……..are…),實(shí)驗(yàn)支持如下結(jié)論:原生 CNN 特征抽取器在這方面極為顯著地弱于 RNN 和 Transformer,Transformer 微弱優(yōu)于 RNN 模型 (尤其在主語(yǔ)謂語(yǔ)距離小于 13 時(shí)),能力由強(qiáng)到弱排序?yàn)?Transformer>RNN>>CNN; 但在比較遠(yuǎn)的距離上(主語(yǔ)謂語(yǔ)距離大于 13),RNN 微弱優(yōu)于 Transformer,所以綜合看,可以認(rèn)為T(mén)ransformer 和 RNN 在這方面能力差不太多,而 CNN 則顯著弱于前兩者。
那么為什么 CNN 在捕獲長(zhǎng)距離特征方面這么弱呢?這個(gè)我們?cè)谇拔闹v述 CNN 的時(shí)候就說(shuō)過(guò),CNN 解決這個(gè)問(wèn)題是靠堆積深度來(lái)獲得覆蓋更長(zhǎng)的輸入長(zhǎng)度的,所以 CNN 在這方面的表現(xiàn)與卷積核能夠覆蓋的輸入距離最大長(zhǎng)度有關(guān)系。如果通過(guò)增大卷積核的 kernel size,同時(shí)加深網(wǎng)絡(luò)深度,以此來(lái)增加輸入的長(zhǎng)度覆蓋。實(shí)驗(yàn)證明這能夠明顯提升 CNN 的 long-range 特征捕獲能力。但是盡管如此,CNN 在這方面仍然顯著弱于 RNN 和 Transformer。這個(gè)問(wèn)題背后的原因是什么呢(因?yàn)樯鲜鲋髡Z(yǔ) - 謂語(yǔ)一致性任務(wù)中,CNN 的深度肯定可以覆蓋 13-25 這個(gè)長(zhǎng)度了,但是表現(xiàn)還是很弱)?其實(shí)這是一個(gè)很好的值得探索的點(diǎn)。
對(duì)于 Transformer 來(lái)說(shuō),Multi-head attention 的 head 數(shù)量嚴(yán)重影響 NLP 任務(wù)中 Long-range 特征捕獲能力:結(jié)論是 head 越多越有利于捕獲 long-range 特征。在上頁(yè) PPT 里寫(xiě)明的論文出來(lái)之前,有個(gè)工作(論文:Tran. The Importance of Being Recurrent for Modeling Hierarchical Structure)的結(jié)論和上述結(jié)論不一致:它的結(jié)論是在” 主語(yǔ) - 謂語(yǔ)一致性” 任務(wù)上,Transformer 表現(xiàn)是弱于 LSTM 的。如果綜合這兩篇論文,我們看似得到了相互矛盾的結(jié)論,那么到底誰(shuí)是正確的呢?Why Self-attention 的論文對(duì)此進(jìn)行了探索,它的結(jié)論是:這個(gè)差異是由于兩個(gè)論文中的實(shí)驗(yàn)中 Transformer 的超參設(shè)置不同導(dǎo)致的,其中尤其是 multi-head 的數(shù)量,對(duì)結(jié)果影響嚴(yán)重,而如果正確設(shè)置一些超參,那么之前 Trans 的論文結(jié)論是不成立的。也就是說(shuō),我們目前仍然可以維持下面結(jié)論:在遠(yuǎn)距離特征捕獲能力方面,Transformer 和 RNN 能力相近,而 CNN 在這方面則顯著弱于前兩者。
任務(wù)綜合特征抽取能力
上面兩項(xiàng)對(duì)比是從特征抽取的兩個(gè)比較重要的單項(xiàng)能力角度來(lái)評(píng)估的,其實(shí)更重要的是在具體任務(wù)中引入不同特征抽取器,然后比較效果差異,以此來(lái)綜合評(píng)定三者的綜合能力。那么這樣就引出一個(gè)問(wèn)題:NLP 中的任務(wù)很多,哪些任務(wù)是最具有代表性的呢?答案是機(jī)器翻譯。你會(huì)看到很多 NLP 的重要的創(chuàng)新模型都是在機(jī)器翻譯任務(wù)上提出來(lái)的,這背后是有道理的,因?yàn)闄C(jī)器翻譯基本上是對(duì) NLP 各項(xiàng)處理能力綜合要求最高的任務(wù)之一,要想獲得高質(zhì)量的翻譯結(jié)果,對(duì)于兩種語(yǔ)言的詞法,句法,語(yǔ)義,上下文處理能力,長(zhǎng)距離特征捕獲等等更方面都需要考慮進(jìn)來(lái)才行。這是為何看到很多比較工作是在機(jī)器翻譯上作出的,這里給個(gè)背后原因的解釋,以避免被質(zhì)疑任務(wù)單一,沒(méi)有說(shuō)服力的問(wèn)題。當(dāng)然,我預(yù)料到那位 “因?yàn)槌蕴澤佟? 愛(ài)挑刺” 的同學(xué)會(huì)這么質(zhì)問(wèn)我,沒(méi)關(guān)系,即使你對(duì)此提出質(zhì)疑,我依然能夠拿出證據(jù),為什么這么講,請(qǐng)往后看。
那么在以機(jī)器翻譯為代表的綜合特征抽取能力方面,三個(gè)特征抽取器哪個(gè)更好些呢?
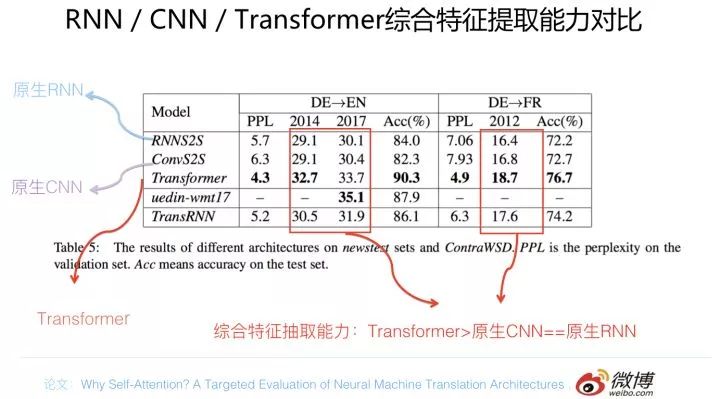
先給出一個(gè)機(jī)器翻譯任務(wù)方面的證據(jù),仍然是 why Self attention 論文的結(jié)論,對(duì)比實(shí)驗(yàn)結(jié)果數(shù)據(jù)參考上圖。在兩個(gè)機(jī)器翻譯任務(wù)中,可以看到,翻譯質(zhì)量指標(biāo) BLEU 證明了如下結(jié)論:Transformer 綜合能力要明顯強(qiáng)于 RNN 和 CNN(你要知道,技術(shù)發(fā)展到現(xiàn)在階段,BLEU 絕對(duì)值提升 1 個(gè)點(diǎn)是很難的事情),而 RNN 和 CNN 看上去表現(xiàn)基本相當(dāng),貌似 CNN 表現(xiàn)略好一些。
你可能覺(jué)得一個(gè)論文的結(jié)論不太能說(shuō)明問(wèn)題,那么我再給出一個(gè)證據(jù),不過(guò)這個(gè)證據(jù)只對(duì)比了 Transformer 和 RNN,沒(méi)帶 CNN 玩,不過(guò)關(guān)于說(shuō)服力我相信你不會(huì)質(zhì)疑,實(shí)驗(yàn)對(duì)比數(shù)據(jù)如下:

上面是 GPT 論文的實(shí)驗(yàn)結(jié)論,在 8 個(gè)不同的 NLP 任務(wù)上,在其它條件相同的情況下,只是把特征抽取器從 Transformer 換成 LSTM,平均下來(lái) 8 個(gè)任務(wù)得分掉了 5 個(gè)點(diǎn)以上。這具備足夠說(shuō)服力嗎?
其實(shí)還有其它機(jī)器翻譯方面的實(shí)驗(yàn)數(shù)據(jù),篇幅原因,不一一列舉了。如果你是個(gè)較真的人,實(shí)在還想看,那請(qǐng)看下一節(jié),里面有另外一個(gè)例子的數(shù)據(jù)讓來(lái)你服氣。如果歸納一下的話,現(xiàn)在能得出的結(jié)論是這樣的:從綜合特征抽取能力角度衡量,Transformer 顯著強(qiáng)于 RNN 和 CNN,而 RNN 和 CNN 的表現(xiàn)差不太多,如果一定要在這兩者之間比較的話,通常 CNN 的表現(xiàn)要稍微好于 RNN 的效果。
當(dāng)然,需要強(qiáng)調(diào)一點(diǎn),本部分所說(shuō)的 RNN 和 CNN 指的是原生的 RNN 和 CNN 模型,就是說(shuō)你可以在經(jīng)典的結(jié)構(gòu)上增加 attention,堆疊層次等各種改進(jìn),但是不包含對(duì)本身結(jié)構(gòu)特別大的變動(dòng),就是說(shuō)支持整容,但是不支持變性。這里說(shuō)的原生版本指的是整容版本,我知道你肯定很關(guān)心有沒(méi)有變性版本的 RNN 和 CNN,我負(fù)責(zé)任地跟你說(shuō),有。你想知道它變性之后是啥樣子?等會(huì)你就看到了,有它們的照片給你。
并行計(jì)算能力及運(yùn)算效率
關(guān)于三個(gè)特征抽取器的并行計(jì)算能力,其實(shí)我們?cè)谇拔姆质鋈齻€(gè)模型的時(shí)候都大致提過(guò),在此僅做個(gè)歸納,結(jié)論如下:
RNN 在并行計(jì)算方面有嚴(yán)重缺陷,這是它本身的序列依賴特性導(dǎo)致的,所謂成也蕭何敗也蕭何,它的這個(gè)線形序列依賴性非常符合解決 NLP 任務(wù),這也是為何 RNN 一引入到 NLP 就很快流行起來(lái)的原因,但是也正是這個(gè)線形序列依賴特性,導(dǎo)致它在并行計(jì)算方面要想獲得質(zhì)的飛躍,看起來(lái)困難重重,近乎是不太可能完成的任務(wù)。
而對(duì)于 CNN 和 Transformer 來(lái)說(shuō),因?yàn)樗鼈儾淮嬖诰W(wǎng)絡(luò)中間狀態(tài)不同時(shí)間步輸入的依賴關(guān)系,所以可以非常方便及自由地做并行計(jì)算改造,這個(gè)也好理解。
所以歸納一下的話,可以認(rèn)為并行計(jì)算能力由高到低排序如下:Transformer 和 CNN 差不多,都遠(yuǎn)遠(yuǎn)遠(yuǎn)遠(yuǎn)強(qiáng)于 RNN。
我們從另外一個(gè)角度來(lái)看,先拋開(kāi)并行計(jì)算能力的問(wèn)題,單純地比較一下三個(gè)模型的計(jì)算效率。可能大家的直觀印象是 Transformer 比較重,比較復(fù)雜,計(jì)算效率比較低,事實(shí)是這樣的嗎?

上圖列出了單層的 Self attention/RNN/CNN 的計(jì)算效率,首先要注意:上面列的是 Self attention, 不是 Transformer 的 Block,因?yàn)?Transformer Block 里其實(shí)包含了好幾層,而不是單層。我們先說(shuō) self attention,等會(huì)說(shuō) Transformer Block 的計(jì)算量。
從上圖可以看出,如果是 self attention/CNN/RNN 單層比較計(jì)算量的話,三者都包含一個(gè)平方項(xiàng),區(qū)別主要是:self attention 的平方項(xiàng)是句子長(zhǎng)度,因?yàn)槊恳粋€(gè)單詞都需要和任意一個(gè)單詞發(fā)生關(guān)系來(lái)計(jì)算 attention,所以包含一個(gè) n 的平方項(xiàng)。而 RNN 和 CNN 的平方項(xiàng)則是 embedding size。那么既然都包含平方項(xiàng),怎么比較三個(gè)模型單層的計(jì)算量呢?首先容易看出 CNN 計(jì)算量是大于 RNN 的,那么 self attention 如何與其它兩者比較呢。可以這么考慮:如果句子平均長(zhǎng)度 n 大于 embedding size,那么意味著 Self attention 的計(jì)算量要大于 RNN 和 CNN;而如果反過(guò)來(lái),就是說(shuō)如果 embedding size 大于句子平均長(zhǎng)度,那么明顯 RNN 和 CNN 的計(jì)算量要大于 self attention 操作。而事實(shí)上是怎樣?我們可以想一想,一般正常的句子長(zhǎng)度,平均起來(lái)也就幾十個(gè)單詞吧。而當(dāng)前常用的 embedding size 從 128 到 512 都常見(jiàn),所以在大多數(shù)任務(wù)里面其實(shí) self attention 計(jì)算效率是要高于 RNN 和 CNN 的。
但是,那位因?yàn)槌蕴澇缘纳偎韵矚g挑刺的同學(xué)會(huì)繼續(xù)質(zhì)問(wèn)我:“哥,我想知道的是 Transformer 和 RNN 及 CNN 的計(jì)算效率對(duì)比,不是 self attention。另外,你能降低你腦袋里發(fā)出的水聲音量嗎?”。嗯,這個(gè)質(zhì)問(wèn)很合理,我來(lái)粗略估算一下,因?yàn)?Transformer 包含多層,其中的 skip connection 后的 Add 操作及 LayerNorm 操作不太耗費(fèi)計(jì)算量,我先把它忽略掉,后面的 FFN 操作相對(duì)比較耗時(shí),它的時(shí)間復(fù)雜度應(yīng)該是 n 乘以 d 的平方。所以如果把 Transformer Block 多層當(dāng)作一個(gè)整體和 RNN 及 CNN 單層對(duì)比的話,Transformer Block 計(jì)算量肯定是要多于 RNN 和 CNN 的,因?yàn)樗旧硪舶粋€(gè) n 乘以 d 的平方,上面列出的 self attention 的時(shí)間復(fù)雜度就是多出來(lái)的計(jì)算量。這么說(shuō)起來(lái),單個(gè) Transformer Block 計(jì)算量大于單層 RNN 和 CNN,沒(méi)毛病。
上面考慮的是三者單層的計(jì)算量,可以看出結(jié)論是:Transformer Block >CNN >RNN。如果是考慮不同的具體模型,會(huì)與模型的網(wǎng)絡(luò)層深有很大關(guān)系,另外還有常見(jiàn)的 attention 操作,所以問(wèn)題會(huì)比較復(fù)雜,這里不具體討論了。
說(shuō)完非并行情況的三者單層計(jì)算量,再說(shuō)回并行計(jì)算的問(wèn)題。很明顯,對(duì)于 Transformer 和 CNN 來(lái)說(shuō),那個(gè)句子長(zhǎng)度 n 是可以通過(guò)并行計(jì)算消掉的,而 RNN 因?yàn)樾蛄幸蕾嚨膯?wèn)題,那個(gè) n 就消不掉,所以很明顯,把并行計(jì)算能力考慮進(jìn)來(lái),RNN 消不掉的那個(gè) n 就很要命。這只是理論分析,實(shí)際中三者計(jì)算效率到底如何呢?我們給出一些三者計(jì)算效率對(duì)比的實(shí)驗(yàn)結(jié)論。
論文 “Convolutional Sequence to Sequence Learning” 比較了 ConvS2S 與 RNN 的計(jì)算效率, 證明了跟 RNN 相比,CNN 明顯速度具有優(yōu)勢(shì),在訓(xùn)練和在線推理方面,CNN 比 RNN 快 9.3 倍到 21 倍。論文 “Dissecting Contextual Word Embeddings: Architecture and Representation” 提到了 Transformer 和 CNN 訓(xùn)練速度比雙向 LSTM 快 3 到 5 倍。論文 “The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation” 給出了 RNN/CNN/Transformer 速度對(duì)比實(shí)驗(yàn),結(jié)論是:Transformer Base 速度最快;CNN 速度次之,但是比 Transformer Base 比慢了將近一倍;Transformer Big 速度再次,主要因?yàn)樗膮?shù)量最大,而吊在車尾最慢的是 RNN 結(jié)構(gòu)。
總而言之,關(guān)于三者速度對(duì)比方面,目前的主流經(jīng)驗(yàn)結(jié)論基本如上所述:Transformer Base 最快,CNN 次之,再次 Transformer Big,最慢的是 RNN。RNN 比前兩者慢了 3 倍到幾十倍之間。
綜合排名情況
以上介紹內(nèi)容是從幾個(gè)不同角度來(lái)對(duì) RNN/CNN/Transformer 進(jìn)行對(duì)比,綜合這幾個(gè)方面的實(shí)驗(yàn)數(shù)據(jù),我自己得出的結(jié)論是這樣的:?jiǎn)螐娜蝿?wù)綜合效果方面來(lái)說(shuō),Transformer 明顯優(yōu)于 CNN,CNN 略微優(yōu)于 RNN。速度方面 Transformer 和 CNN 明顯占優(yōu),RNN 在這方面劣勢(shì)非常明顯。這兩者再綜合起來(lái),如果我給的排序結(jié)果是Transformer>CNN>RNN,估計(jì)沒(méi)有什么問(wèn)題吧?那位吃虧….. 愛(ài)挑刺的同學(xué),你說(shuō)呢?
從速度和效果折衷的角度看,對(duì)于工業(yè)界實(shí)用化應(yīng)用,我的感覺(jué)在特征抽取器選擇方面配置 Transformer base 是個(gè)較好的選擇。
三者的合流:向 Transformer 靠攏
上文提到了,Transformer 的效果相對(duì)原生 RNN 和 CNN 來(lái)說(shuō)有比較明顯的優(yōu)勢(shì),那么是否意味著我們可以放棄 RNN 和 CNN 了呢?事實(shí)倒也并未如此。我們聰明的科研人員想到了一個(gè)巧妙的改造方法,我把它叫做 “寄居蟹” 策略(就是上文說(shuō)的 “變性” 的一種帶有海洋文明氣息的文雅說(shuō)法)。什么意思呢?我們知道 Transformer Block 其實(shí)不是只有一個(gè)構(gòu)件,而是由 multi-head attention/skip connection/Layer Norm/Feed forward network 等幾個(gè)構(gòu)件組成的一個(gè)小系統(tǒng),如果我們把 RNN 或者 CNN 塞到 Transformer Block 里會(huì)發(fā)生什么事情呢?這就是寄居蟹策略的基本思路。
那么怎么把 RNN 和 CNN 塞到 Transformer Block 的肚子里,讓它們背上重重的殼,從而能夠?qū)崿F(xiàn)寄居策略呢?
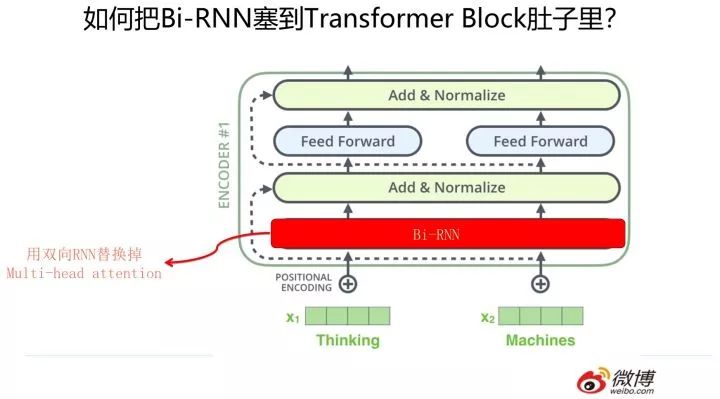
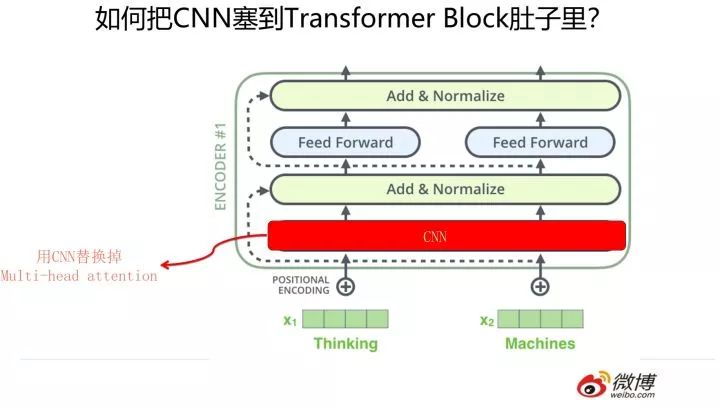
其實(shí)很簡(jiǎn)單,參考上面兩張 PPT,簡(jiǎn)而言之,大的方向就是把 self attention 模塊用雙向 RNN 或者 CNN 替換掉,Transformer Block 的其它構(gòu)件依然健在。當(dāng)然這只是說(shuō)明一個(gè)大方向,具體的策略可能有些差異,但是基本思想八九不離十。
那么如果 RNN 和 CNN 采取這種寄居策略,效果如何呢?他們還爬的動(dòng)嗎?其實(shí)這種改造方法有奇效,能夠極大提升 RNN 和 CNN 的效果。而且目前來(lái)看,RNN 或者 CNN 想要趕上 Transformer 的效果,可能還真只有這個(gè)辦法了。

我們看看 RNN 寄居到 Transformer 后,效果是如何的。上圖展示了對(duì)原生 RNN 不斷進(jìn)行整容手術(shù),逐步加入 Transformer 的各個(gè)構(gòu)件后的效果。我們從上面的逐步變身過(guò)程可以看到,原生 RNN 的效果在不斷穩(wěn)定提升。但是與土生土長(zhǎng)的 Transformer 相比,性能仍然有差距。
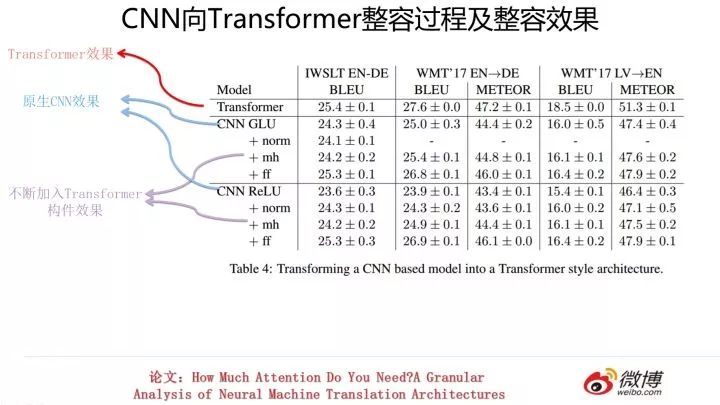
類似的,上圖展示了對(duì) CNN 進(jìn)行不斷改造的過(guò)程以及其對(duì)應(yīng)效果。同樣的,性能也有不同幅度的提升。但是也與土家 Transformer 性能存在一些差距。
這說(shuō)明什么?我個(gè)人意見(jiàn)是:這說(shuō)明 Transformer 之所以能夠效果這么好,不僅僅 multi-head attention 在發(fā)生作用,而是幾乎所有構(gòu)件都在共同發(fā)揮作用,是一個(gè)小小的系統(tǒng)工程。
但是從上面結(jié)果看,變性版本 CNN 好像距離 Transformer 真身性能還是比不上,有些數(shù)據(jù)集合差距甚至還很大,那么是否意味著這條路也未必走的通呢?Lightweight convolution 和 Dynamic convolutions 給人們帶來(lái)一絲曙光,在論文 “Pay Less Attention With LightweightI and Dynamic Convolutions” 里提出了上面兩種方法,效果方面基本能夠和 Transformer 真身相當(dāng)。那它做了什么能夠達(dá)成這一點(diǎn)呢?也是寄居策略。就是用 Lightweight convolution 和 Dynamic convolutions 替換掉 Transformer 中的 Multi-head attention 模塊,其它構(gòu)件復(fù)用了 Transformer 的東西。和原生 CNN 的最主要區(qū)別是采用了 Depth-wise separable CNN 以及 softmax-normalization 等優(yōu)化的 CNN 模型。
而這又說(shuō)明了什么呢?我覺(jué)得這說(shuō)明了一點(diǎn):RNN 和 CNN 的大的出路在于寄生到 Transformer Block 里,這個(gè)原則沒(méi)問(wèn)題,看起來(lái)也是他倆的唯一出路。但是,要想效果足夠好,在塞進(jìn)去的 RNN 和 CNN 上值得花些功夫,需要一些新型的 RNN 和 CNN 模型,以此來(lái)配合 Transformer 的其它構(gòu)件,共同發(fā)揮作用。如果走這條路,那么 RNN 和 CNN 翻身的一天也許還會(huì)到來(lái)。
盡管如此,我覺(jué)得 RNN 這條路仍然不好走,為什么呢,你要記得 RNN 并行計(jì)算能力差這個(gè)天生缺陷,即使把它塞到 Transformer Block 里,別說(shuō)現(xiàn)在效果還不行,就算哪天真改出了一個(gè)效果好的,但是因?yàn)樗牟⑿心芰Γ瑫?huì)整體拖慢 Transformer 的運(yùn)行效率。所以我綜合判斷 RNN 這條路將來(lái)也走不太通。
2019 來(lái)自未來(lái)的消息:總結(jié)
很多年前的小學(xué)語(yǔ)文課本上有句話,是這么說(shuō)的:“張華考上了北京大學(xué);李萍進(jìn)了中等技術(shù)學(xué)校;我在百貨公司當(dāng)售貨員:我們都有光明的前途”。我們小的時(shí)候看到這句話,對(duì)此深信不疑,但是走到 2019 的今天,估計(jì)已經(jīng)沒(méi)有父母愿意跟他們的孩子說(shuō)這句話了,畢竟欺騙孩子是個(gè)挺不好的事情。如果套用這句話來(lái)說(shuō)明 NLP 的三大特征抽取器的前途的話,應(yīng)該是這樣的:“Transformer 考上了北京大學(xué);CNN 進(jìn)了中等技術(shù)學(xué)校,希望有一天能夠考研考進(jìn)北京大學(xué);RNN 在百貨公司當(dāng)售貨員:我們都有看似光明的前途。”
我們把上文的所有證據(jù)都收集起來(lái)進(jìn)行邏輯推理,可以模仿曹雪芹老師,分別給三位 NLP 界佳麗未來(lái)命運(yùn)寫(xiě)一句判詞。當(dāng)然,再次聲明,這是我個(gè)人判斷。
進(jìn)退維谷的 RNN
為什么說(shuō) RNN 進(jìn)退維谷呢?有幾個(gè)原因。
首先,如果靠原生的 RNN(包括 LSTM,GRU 以及引入 Attention 以及堆疊層次等各種你能想到的改進(jìn)方法,可以一起上),目前很多實(shí)驗(yàn)已經(jīng)證明效果比起 Transformer 有較大差距,現(xiàn)在看基本沒(méi)有迎頭趕上的可能,所以原生的 RNN 從效果來(lái)講是處于明顯劣勢(shì)的。
其次,原生的 RNN 還有一個(gè)致命的問(wèn)題:并行計(jì)算能力受限制太嚴(yán)重。想要大規(guī)模實(shí)用化應(yīng)用?目前看希望渺茫。我們前面說(shuō)過(guò),決定了 RNN 本身的根本特質(zhì)是:T 時(shí)刻隱層節(jié)點(diǎn)對(duì)前向輸入及中間計(jì)算結(jié)果的序列依賴,因?yàn)樗€形序列收集前面的信息,這是 RNN 之所以是 RNN 的最主要特點(diǎn)。正是它的這個(gè)根本特質(zhì),使得 RNN 的并行計(jì)算能力想要獲得根本解決基本陷入了一個(gè)兩難的境地:要么仍然保持 RNN 序列依賴的根本特性,這樣不論怎么改造,因?yàn)檫@個(gè)根本還在,所以 RNN 依舊是 RNN,所謂 “我就是我,是不一樣的煙火”,但是如果這樣,那么其并行能力基本無(wú)法有力發(fā)揮,天花板很低;當(dāng)然除此外,還有另外一條路可走,就是把這種序列依賴關(guān)系打掉,如果這樣,那么這種打掉序列依賴關(guān)系的模型雖然看上去仍然保留了部分 RNN 整形前的樣貌,其實(shí)它骨子里已經(jīng)是另外一個(gè)人了,這已經(jīng)不是你記憶中的 RNN 了。就是說(shuō),對(duì) RNN 來(lái)說(shuō),要么就認(rèn)命接受慢的事實(shí),躲進(jìn)小樓成一統(tǒng),管他春夏與秋冬,僅僅是學(xué)術(shù)界用來(lái)發(fā)表論文的一種載體,不考慮大規(guī)模實(shí)用化的問(wèn)題。要么就徹底改頭換面變成另外一個(gè)人,如果真走到這一步,我想問(wèn)的是:你被別人稱為高效版本的 RNN,你自己好意思答應(yīng)嗎?這就是 RNN 面臨的兩難境地。
再次,假設(shè)我們?cè)贅?lè)觀一點(diǎn),把對(duì) RNN 的改造方向定位為將 RNN 改造成類似 Transformer 的結(jié)構(gòu)這種思路算進(jìn)來(lái):無(wú)非就是在 Transformer 的 Block 里,把某些部件,當(dāng)然最可行的是把 Multi-head self attention 部件換成 RNN。我們就算退一步講,且將這種大幅結(jié)構(gòu)改造的模型也算做是 RNN 模型吧。即使這樣,已經(jīng)把自己整形成長(zhǎng)得很像 Transformer 了,RNN 依然面臨上述原生 RNN 所面臨的同樣兩個(gè)困境:一方面即使這種連變性削骨都上的大幅度整容版本的 RNN,效果雖然有明顯提升,但是仍然比不過(guò) Transformer;另外,一旦引入 RNN 構(gòu)件,同樣會(huì)觸發(fā) Transformer 結(jié)構(gòu)的并行計(jì)算能力問(wèn)題。所以,目前 Transformer 發(fā)動(dòng)機(jī)看上去有點(diǎn)帶不動(dòng) RNN 這個(gè)隊(duì)友。
綜合以上幾個(gè)因素,我們可以看出,RNN 目前處于進(jìn)退兩難的地步,我覺(jué)得它被其它模型替換掉只是時(shí)間問(wèn)題,而且好像留給它的時(shí)間不多了。當(dāng)然,這是我個(gè)人意見(jiàn)。我說(shuō)這番話的時(shí)候,你是不是又聽(tīng)到了水聲?
我看到網(wǎng)上很多人還在推 RNN 說(shuō):其實(shí)還是 RNN 好用。我覺(jué)得這其實(shí)是一種錯(cuò)覺(jué)。之所以會(huì)產(chǎn)生這個(gè)錯(cuò)覺(jué),原因來(lái)自兩個(gè)方面:一方面是因?yàn)?RNN 發(fā)展歷史長(zhǎng),所以有大量經(jīng)過(guò)優(yōu)化的 RNN 框架可用,這對(duì)技術(shù)選型選擇困難癥患者來(lái)說(shuō)是個(gè)福音,因?yàn)槟汶S手選一個(gè)知名度還可以的估計(jì)效果就不錯(cuò),包括對(duì)一些數(shù)據(jù)集的前人摸索出的超參數(shù)或者調(diào)參經(jīng)驗(yàn);而 Transformer 因?yàn)闅v史太短,所以各種高效的語(yǔ)言版本的優(yōu)秀框架還少,選擇不多。另外,其實(shí)我們對(duì) Transformer 為何有效目前還不是特別清楚,包括相關(guān)的各種數(shù)據(jù)集合上的調(diào)參經(jīng)驗(yàn)公開(kāi)的也少,所以會(huì)覺(jué)得調(diào)起來(lái)比較費(fèi)勁。隨著框架越來(lái)越多,以及經(jīng)驗(yàn)分享越來(lái)越充分,這個(gè)不再會(huì)是問(wèn)題。這是一方面。另外一方面,很多人反饋對(duì)于小數(shù)據(jù)集 RNN 更好用,這固然跟 Transformer 的參數(shù)量比較多有關(guān)系,但是也不是沒(méi)有解決辦法,一種方式是把 Block 數(shù)目降低,減少參數(shù)量;第二種辦法是引入 Bert 兩階段訓(xùn)練模型,那么對(duì)于小數(shù)據(jù)集合來(lái)說(shuō)會(huì)極大緩解效果問(wèn)題。所以綜合這兩方面看,RNN 貌似在某些場(chǎng)合還有優(yōu)勢(shì),但是這些所謂的優(yōu)勢(shì)是很脆弱的,這其實(shí)反映的是我們對(duì) Transformer 整體經(jīng)驗(yàn)不足的事實(shí),隨著經(jīng)驗(yàn)越來(lái)越豐富,RNN 被 Transformer 取代基本不會(huì)有什么疑問(wèn)。
一息尚存的 CNN
CNN 在 14 年左右在 NLP 界剛出道的時(shí)候,貌似跟 RNN 比起來(lái)表現(xiàn)并不算太好,算是落后生,但是用發(fā)展的眼光看,未來(lái)的處境反而看上去比 RNN 的狀態(tài)還要占優(yōu)一些。之所以造成這個(gè)奇怪現(xiàn)象,最主要的原因有兩個(gè):一個(gè)是因?yàn)?CNN 的天生自帶的高并行計(jì)算能力,這對(duì)于延長(zhǎng)它的生命力發(fā)揮了很大作用。這就決定了與 Transformer 比起來(lái),它并不存在無(wú)法克服的困難,所以仍然有希望;第二,早期的 CNN 做不好 NLP 的一個(gè)很大原因是網(wǎng)絡(luò)深度做不起來(lái),隨著不斷借鑒圖像處理的新型 CNN 模型的構(gòu)造經(jīng)驗(yàn),以及一些深度網(wǎng)絡(luò)的優(yōu)化 trick,CNN 在 NLP 領(lǐng)域里的深度逐步能做起來(lái)了。而既然深度能做起來(lái),那么本來(lái) CNN 做 NLP 天然的一個(gè)缺陷:無(wú)法有效捕獲長(zhǎng)距離特征的問(wèn)題,就得到了極大緩解。目前看可以靠堆深度或者結(jié)合 dilated CNN 來(lái)一定程度上解決這個(gè)問(wèn)題,雖然還不夠好,但是仍然是那句話,希望還在。
但是,上面所說(shuō)只是從道理分析角度來(lái)講 CNN 的希望所在,話分兩頭,我們說(shuō)回來(lái),目前也有很多實(shí)驗(yàn)證明了原生的 CNN 在很多方面仍然是比不過(guò) Transformer 的,典型的還是長(zhǎng)距離特征捕獲能力方面,原生的 CNN 版本模型仍然極為顯著地弱于 RNN 和 Transformer,而這點(diǎn)在 NLP 界算是比較嚴(yán)重的缺陷。好,你可以說(shuō):那我們把 CNN 引到 Transformer 結(jié)構(gòu)里,比如代替掉 Self attention,這樣和 Transformer 還有一戰(zhàn)吧?嗯,是的,目前看貌似只有這條路是能走的通的,引入 depth separate CNN 可以達(dá)到和 Transformer 接近的效果。但是,我想問(wèn)的是:你確認(rèn)長(zhǎng)成這樣的 CNN,就是把 CNN 塞到 Transformer Block 的肚子里,你確認(rèn)它的親朋好友還能認(rèn)出它嗎?
當(dāng)然,我之所以寫(xiě) CNN 一息尚存,是因?yàn)槲矣X(jué)得把 CNN 塞到 Transformer 肚子里這種方案,對(duì)于篇章級(jí)別的 NLP 任務(wù)來(lái)說(shuō),跟采取 self attention 作為發(fā)動(dòng)機(jī)的 Transformer 方案對(duì)比起來(lái),是具有極大優(yōu)勢(shì)的領(lǐng)域,也是適合它的戰(zhàn)場(chǎng),后面我估計(jì)會(huì)出現(xiàn)一些這方面的論文。為什么這么講?原因下面會(huì)說(shuō)。
穩(wěn)操勝券的 transformer
我們?cè)诜治鑫磥?lái) NLP 的三大特征抽取器哪個(gè)會(huì)勝出,我認(rèn)為,起碼根據(jù)目前的信息來(lái)看,其實(shí) Transformer 在很多戰(zhàn)場(chǎng)已經(jīng)贏了,在這些場(chǎng)地,它未來(lái)還會(huì)繼續(xù)贏。為什么呢?上面不是說(shuō)了嗎,原生的 RNN 和 CNN,總有一些方面顯著弱于 Transformer(并行計(jì)算能力或者效果,或者兩者同時(shí)都比 Transformer 弱)。那么他們未來(lái)的希望,目前大家都寄托在把 RNN 和 CNN 寄生在 Transformer Block 里。RNN 不用說(shuō)了,上面說(shuō)過(guò)它的進(jìn)退維艱的現(xiàn)狀。單說(shuō) CNN 吧,還是上一部分的那句話,我想問(wèn)的是:你確認(rèn)長(zhǎng)成這樣的 CNN,就是把 CNN 塞到 Transformer Block 的肚子里,你確認(rèn)它的親朋還能認(rèn)出它嗎?
目前能夠和 Transformer 一戰(zhàn)的 CNN 模型,基本都已經(jīng)長(zhǎng)成 Transformer 的模樣了。而這又說(shuō)明了什么呢?難道這是 CNN 要能戰(zhàn)勝 Transformer 的跡象嗎?這是一道留給您的思考題和辯論題。當(dāng)然,我不參加辯論。
Transformer 作為一個(gè)新模型,并不是完美無(wú)缺的。它也有明顯的缺點(diǎn):首先,對(duì)于長(zhǎng)輸入的任務(wù),典型的比如篇章級(jí)別的任務(wù)(例如文本摘要),因?yàn)槿蝿?wù)的輸入太長(zhǎng),Transformer 會(huì)有巨大的計(jì)算復(fù)雜度,導(dǎo)致速度會(huì)急劇變慢。所以估計(jì)短期內(nèi)這些領(lǐng)地還能是 RNN 或者長(zhǎng)成 Transformer 模樣的 CNN 的天下(其實(shí)目前他倆這塊做得也不好),也是目前看兩者的希望所在,尤其是 CNN 模型,希望更大一些。但是是否 Transformer 針對(duì)長(zhǎng)輸入就束手無(wú)策,沒(méi)有解決辦法呢?我覺(jué)得其實(shí)并不是,比如拍腦袋一想,就能想到一些方法,雖然看上去有點(diǎn)丑陋。比如可以把長(zhǎng)輸入切斷分成 K 份,強(qiáng)制把長(zhǎng)輸入切短,再套上 Transformer 作為特征抽取器,高層可以用 RNN 或者另外一層 Transformer 來(lái)接力,形成 Transformer 的層級(jí)結(jié)構(gòu),這樣可以把 n 平方的計(jì)算量極大減少。當(dāng)然,這個(gè)方案不優(yōu)雅,這個(gè)我承認(rèn)。但是我提示你一下:這個(gè)方向是個(gè)值得投入精力的好方向,你留意一下我這句話,也許有意想不到的收獲。(注:上面這段話是我之前早已寫(xiě)好的,結(jié)果今天(1 月 12 日)看見(jiàn)媒體號(hào)在炒作:“Transforme-XL,速度提升 1800 倍”云云。看了新聞,我找來(lái) Transformer-XL 論文看了一下,發(fā)現(xiàn)它解決的就是輸入特別長(zhǎng)的問(wèn)題,方法呢其實(shí)大思路和上面說(shuō)的內(nèi)容差不太多。說(shuō)這么多的意思是:我并不想刪除上面內(nèi)容,為避免發(fā)出來(lái)后,那位 “愛(ài)挑刺” 同學(xué)說(shuō)我拷貝別人思路沒(méi)引用。我決定還是不改上面的說(shuō)法,因?yàn)檫@個(gè)點(diǎn)子實(shí)在是太容易想到的點(diǎn)子,我相信你也能想到。)除了這個(gè)缺點(diǎn),Transformer 整體結(jié)構(gòu)確實(shí)顯得復(fù)雜了一些,如何更深刻認(rèn)識(shí)它的作用機(jī)理,然后進(jìn)一步簡(jiǎn)化它,這也是一個(gè)好的探索方向,這句話也請(qǐng)留意。還有,上面在做語(yǔ)義特征抽取能力比較時(shí),結(jié)論是對(duì)于距離遠(yuǎn)于 13 的長(zhǎng)距離特征,Transformer 性能弱于 RNN,說(shuō)實(shí)話,這點(diǎn)是比較出乎我意料的,因?yàn)?Transformer 通過(guò) Self attention 使得遠(yuǎn)距離特征直接發(fā)生關(guān)系,按理說(shuō)距離不應(yīng)該成為它的問(wèn)題,但是效果竟然不如 RNN,這背后的原因是什么呢?這也是很有價(jià)值的一個(gè)探索點(diǎn)。
我預(yù)感到我可能又講多了,能看到最后不容易,上面幾段話算是送給有耐心的同學(xué)的禮物,其它不多講了,就此別過(guò),請(qǐng)忽略你聽(tīng)到的嘩嘩的水聲。
-
Transformer
+關(guān)注
關(guān)注
0文章
143瀏覽量
6007 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13350 -
nlp
+關(guān)注
關(guān)注
1文章
488瀏覽量
22038
原文標(biāo)題:Transformer一統(tǒng)江湖:自然語(yǔ)言處理三大特征抽取器比較
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Zigbee是否真的窮途末路?NB-IoT是否能一統(tǒng)江湖?
NLPIR語(yǔ)義分析是對(duì)自然語(yǔ)言處理的完美理解
自然語(yǔ)言處理怎么最快入門(mén)?
【推薦體驗(yàn)】騰訊云自然語(yǔ)言處理
Python自然語(yǔ)言處理學(xué)習(xí)筆記:建立基于特征的文法
全面擁抱Transformer:NLP三大特征抽取器(CNNRNNTF)比較
什么是自然語(yǔ)言處理_自然語(yǔ)言處理常用方法舉例說(shuō)明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論