 Cornami構建了一個革命性的脈動陣列架構
Cornami構建了一個革命性的脈動陣列架構
科技界出現了許多為人工智能和機器學習開發特殊芯片的初創公司。在加州圣克拉拉由老牌半導體分析公司Linley集團主辦的Linley集團秋季處理器會議上,出現了一些最有趣的產品。
一家總部位于圣克拉拉的創業公司Cornami進行了一場演講。
其聯合創始人和首席技術官Paul Masters描述了一種機器學習的新方式,可以安排芯片的各個元素進行機器學習“訓練”(神經網絡就是在這里發展起來的)和“推理”(神經網絡在不斷的基礎上提供答案)。
Cornami一直在秘密運作,這是Masters首次公開關于該公司芯片運作方式的一些細節。
Cornami的目標是向大眾市場提供芯片,包括“邊緣計算”領域,其中汽車和消費電子產品特別需要具有高響應性能的芯片,并且在運行神經網絡方面具有高能效。
Masters說,該芯片可追溯到20世紀70年代和80年代的技術,稱為脈動陣列。脈動陣列具有很多計算元件,例如乘法—累加器,以執行作為神經網絡的基本計算單元的矩陣乘法。用線將這些元素彼此連接,并連接到網格中的內存。脈動矩陣是根據心臟的收縮功能來命名的:就像血流一樣,數據是通過這些計算元素“泵”出來的。
根據演示,脈動陣列在它們首次出現時并未真正被重視,但它們正在成為構建AI芯片的主要方式。Masters表示:“你已經看到了,它很酷,它來自70年代。”
“谷歌正在使用它們,還有微軟以及數十家初創公司,”他觀察到脈動陣列的普及。
但Masters討論了Cornami如何采用獨特的脈動陣列方法。“脈動陣列的詛咒在于它們是方形的,”Masters說。他指的是乘數累加器的對稱排列。由于這種剛性布局,將數據移入和移出這些計算元素將占用芯片大量的工作,甚至比每個計算元素中的計算本身還要多。
Masters 說“傳統芯片的功耗在哪里?”,這是個大問題。“數據被轉儲到DDR [DRAM內存]中,它必須進入核心進行計算,因此數據從DDR進入三級高速緩存,二級高速緩存和一級高速緩存,然后進入寄存器,之后開始進行計算。如果核心耗盡,就必須反過來,先退出并將所有臨時數據轉儲回寄存器,L1緩存,L2,L3,一遍又一遍。“
Masters解釋說,只要用到L1緩存就需要四倍于實際計算的功耗。如果要用DRAM,幾乎很難做到,而且需要更大的功率來驅動芯片。
Masters說:“傳統機器中能效最低的就是移動數據”。解決方案是擁有數千個核心,通過保持數千個核心繁忙,可以避免返回到內存子系統,而只是簡單地將計算的輸入和輸出從一個元素路由到下一個元素。“如果擁有8,000到32,000個核心,我們可以保持整個神經網絡在一個芯片上”他說。
因此,為了降低進出內存的成本,Cornami芯片重新排列他們的電路,使計算元件可以切換到各種幾何布局,有效地組織芯片上的計算活動,以滿足目前的神經網絡的需求。
“Cornami構建了一個可以根據需要構建任何尺寸,任何形狀的脈動陣列的架構。” 脈動陣列可以被動態地重新排列成非正方形的各種新幾何圖形。這些奇怪的數組形狀使得在計算元素之間移動輸入和輸出變得非常有效。因此,Cornami芯片可以最小化內存和緩存使用,從而“顯著降低功耗和延遲,并提高性能”。
Masters自豪地說,憑借這種靈活性,單個Cornami芯片就可以處理整個神經網絡,并且能夠取代通常用于運行神經網絡的CPU,GPU,FPGA和ASIC的各種組合。他表示,這是一個“芯片上的數據中心”,對于將AI置于汽車等“邊緣計算”中具有重要意義。
Masters展示了一些性能統計數據:運行“SegNet”神經網絡進行圖像識別,與Nvidia“Titan V”GPU相比,Cornami芯片能夠每秒處理877幀,功耗只有30瓦。而Titan GPU功耗250瓦,每秒只能處理8.6幀。
Cornami于2016年9月從Impact Venture Capital獲得了300萬美元的B輪風險投資。隨后,該公司已收到資金,但尚未披露具體數額。
-
人工智能
+關注
關注
1791文章
47279瀏覽量
238513 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646 -
AI芯片
+關注
關注
17文章
1887瀏覽量
35027
原文標題:Cornami AI芯片:革命性的脈動陣列架構
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
東軟醫療光子計數CT獲得革命性突破
安寶特案例 | AR技術在院外心臟驟停急救中的革命性應用

PC示波器:電子測試與測量的革命性工具
使用OPA129構建了一個電荷放大器,6腳輸出經常出現尖峰的原因?
顛覆!硅光“黑馬”打造革命性光學IO技術,可取代芯片內銅線
全新雷達水位流速儀,讓河流管理更智能,革命性水文監測

日本推出革命性的人形機器人
Transformer架構在自然語言處理中的應用
蘋果新專利,Apple Pencil將迎來革命性升級
占位符還是革命性突破?RISC-V處理器架構引領中國芯片產業新機遇!

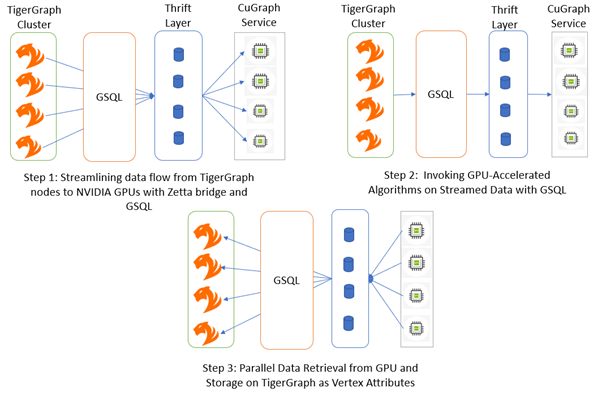
革命性的圖形分析: NVIDIA cuGraph 加速的下一代架構
英倫科技室內裸眼3D廣告機會議一體機正以其革命性的視覺體驗引領著新的趨勢

長電科技推出了一項革命性的高精度熱阻測試與仿真模擬驗證技術
利用太赫茲超構表面開發一款革命性的生物傳感器





 工商網監
工商網監
評論