") 通過FPGA實現(xiàn)深度神經(jīng)網(wǎng)絡(luò)的解決方案
通過FPGA實現(xiàn)深度神經(jīng)網(wǎng)絡(luò)的解決方案
隨著“Alexa”、“Hey Siri”或“Hi Google”等多個產(chǎn)品成功響應(yīng)關(guān)鍵詞,關(guān)鍵字檢測 (KWS) 已成為越來越多嵌入式應(yīng)用的一項重要要求。雖然典型的先進 KWS 解決方案依賴于復(fù)雜的卷積神經(jīng)網(wǎng)絡(luò) (CNN) 和其他深度神經(jīng)網(wǎng)絡(luò) (DNN) 機器學(xué)習(xí)算法,但資源受限型產(chǎn)品的開發(fā)人員可以使用二值神經(jīng)網(wǎng)絡(luò) (BNN) 獲得所需的準(zhǔn)確結(jié)果。
本文介紹了將 KWS 添加到可穿戴設(shè)備和其他低功耗物聯(lián)網(wǎng)設(shè)備的優(yōu)勢,以及所面臨的各項挑戰(zhàn)。在描述 BNN 架構(gòu)及其為何適用于資源受限型 KWS 應(yīng)用之后,本文還介紹了一種通過低功耗 FPGA 實現(xiàn) BNN 的可用解決方案。該解決方案將用于展示如何利用一小部分 CNN 資源要求,為低功耗 KWS 應(yīng)用實現(xiàn) CNN 的高精度。
KWS 的起源和演進
KWS 也被也稱為關(guān)鍵詞檢測,多年來一直應(yīng)用于信息處理應(yīng)用。例如,在文檔處理中,KWS 提供了一種更有效的光學(xué)字符識別替代方法,可為大規(guī)模數(shù)字化文檔編制索引。隨著聲控服務(wù)在智能手機、手表、家用產(chǎn)品等設(shè)備中變得可用,基于語音的 KWS 方法在產(chǎn)品開發(fā)中迅速獲得關(guān)注。在這些產(chǎn)品中,“始終運行”功能允許產(chǎn)品連續(xù)處理音頻輸入,尋找可激活基于語音的用戶界面的關(guān)鍵字。
諸如 XMOS VocalFusion 4-Mic 套件之類板級產(chǎn)品可與 Amazon 語音服務(wù)完全集成,提供了一種即用型解決方案,可在許多應(yīng)用中添加語音助手服務(wù)。但對于功率預(yù)算有限的可穿戴設(shè)備或其他電池供電型產(chǎn)品,開發(fā)人員很大程度上只能去尋找自己的 KWS 解決方案。
過去,實現(xiàn)自定義 KWS 機制要求開發(fā)人員不僅在音頻工程方面具有深厚背景,而且在時間模式識別的統(tǒng)計方法應(yīng)用方面也具有同樣的要求。過去幾十年來,基于隱馬爾可夫模型和相關(guān)算法的統(tǒng)計方法為字識別解決方案提供了基礎(chǔ)。
最近,像卷積神經(jīng)網(wǎng)絡(luò) (CNN) 這樣的 DNN 架構(gòu)已經(jīng)開始用作許多 KWS 應(yīng)用的基礎(chǔ)。
滿足深度神經(jīng)網(wǎng)絡(luò) (DNN) 要求
DNN 架構(gòu)基于多層神經(jīng)元,這些神經(jīng)元經(jīng)過訓(xùn)練,可從輸入數(shù)據(jù)中提取特征,并預(yù)測輸入數(shù)據(jù)對應(yīng)于訓(xùn)練期間所用類之一的概率1。特別是得益于這些算法實現(xiàn)的高識別精度,CNN 架構(gòu)已成為圖像識別的卓越方法。
同樣,不同類型的 CNN 架構(gòu)已經(jīng)在包括 KWS 實現(xiàn)在內(nèi)的語音處理中取得了成功。“傳統(tǒng)”CNN 架構(gòu)的難點在于其尺寸和處理要求。例如,在圖像處理中,CNN 模型已經(jīng)增長到數(shù)百兆字節(jié)的大小。大存儲容量加上廣泛的數(shù)值計算要求,對模型處理平臺提出了很高的要求。
用于實現(xiàn)傳統(tǒng) CNN 架構(gòu)的方法提供的幫助很少。CNN 和其他 DNN 算法通過對網(wǎng)絡(luò)中每層的每個神經(jīng)元執(zhí)行通用矩陣乘法 (GEMM) 運算,實現(xiàn)其精度。在訓(xùn)練期間,當(dāng)模型可能需要處理數(shù)百萬個標(biāo)記的特征向量以獲得預(yù)期結(jié)果時,GEMM 和其他矩陣計算的數(shù)量可以很容易地達到數(shù)十億,從而推動了圖形處理單元 (GPU) 在此模型開發(fā)階段加速處理的需求。當(dāng)部署模型以在應(yīng)用中執(zhí)行推理時,人們希望維持低延時和高精度,這繼續(xù)決定了在要求最為嚴(yán)苛的應(yīng)用中對 GPU 的需求。
在具有較為適中的推理要求的應(yīng)用中,開發(fā)人員可以通過犧牲延時和精度來部署傳統(tǒng) CNN,即使在 Raspberry Pi Foundation Raspberry Pi 3 等通用平臺上,或基于 Arm? Cortex?-M7 的 MCU(例如 Microchip Technology、NXP 或 STMicroelectronics 的 MCU)上亦如此2。
但是,對于對推理準(zhǔn)確性和延時提出嚴(yán)格要求的應(yīng)用,傳統(tǒng) CNN 算法在資源有限的平臺上根本不實用。CNN 提出的存儲器和處理要求遠遠超出了典型線路供電型消費產(chǎn)品內(nèi)置的嵌入式系統(tǒng)的資源范圍,更不用說電池供電型可穿戴設(shè)備或其他預(yù)期提供“始終運行”的KWS 功能的移動設(shè)計。模型壓縮技術(shù)的發(fā)展需要 DNN 算法能夠支持這些平臺。
高效的 DNN 方法
為了解決呈螺旋上升的模型尺寸問題,機器學(xué)習(xí)科學(xué)家已經(jīng)找到了在無顯著精度損失的情況下大幅降低存儲器需求的方法。例如,研究人員修剪了對結(jié)果貢獻很小的內(nèi)部網(wǎng)絡(luò)連接。他們還將內(nèi)部參數(shù)所需的精度降低到 8 位甚至 5 位值。通過應(yīng)用上述方法和其他方法,他們在無明顯精度損失的情況下,將行業(yè)黃金標(biāo)準(zhǔn) CNN 模型的尺寸減小 30 倍至 49 倍,從而減少了存儲器需求3。
除了降低存儲器需求外,模型壓縮技術(shù)還有助于降低處理要求:修剪減少了所需計算次數(shù),而精度降低則加快了計算速度。
但是,即使降低了精度,這些網(wǎng)絡(luò)仍需要大量屬于機器學(xué)習(xí)算法核心的 GEMM 運算。這些運算的范圍不僅推動了對推理平臺高性能硬件的需求,而且還直接影響了這些平臺的功率預(yù)算。饋送這些矩陣運算需要大量訪問存儲器,單是這方面的功耗,就輕易超過電池供電型設(shè)備的功率預(yù)算。
為了解決移動設(shè)備的存儲器、處理和功耗限制,研究人員已將模型壓縮的概念擴展到極致。研究人員將模型參數(shù)量化為 +1 或 -1(或 0)值,以建立稱為二值神經(jīng)網(wǎng)絡(luò) (BNN) 的架構(gòu),而不是簡單地將內(nèi)部參數(shù)的精度降低到 8 位或更低位。
BNN 如何將 KWS 引入資源有限的設(shè)計
在基本拓撲方面,BNN 與 CNN 大致相同,并且所含層類型相同(包括卷積層、歸一化層、激活層和池化層)。這些層內(nèi)使用 1 位參數(shù)(權(quán)重與偏置值),在運算上差異巨大。
BNN 不是執(zhí)行傳統(tǒng) CNN 中所需的 32 位浮點 GEMM 運算,而是可以使用更簡單的按位 XNOR 運算。雖然這種方法可能導(dǎo)致訓(xùn)練時間延長,但研究人員發(fā)現(xiàn),BNN 模型的準(zhǔn)確率幾乎與使用 32 位浮點值的模型相當(dāng)4。二進制化參數(shù)的使用不僅減少了 BNN 的存儲器占用空間,而且還減少了其存儲器訪問要求,因為可以在單字訪問周期中獲取多個 1 位參數(shù),并且饋送 XNOR 運算所需的參數(shù)更少。
BNN 的計算簡化后,處理要求也隨之顯著降低。因此,BNN 可以在不顯著影響精度的情況下,實現(xiàn)比先前方法更高的推理率。在一項研究中,研究人員比較了在 Xilinx XC7Z020 FPGA 片上系統(tǒng) (SoC) 上實現(xiàn) CNN 和 BNN 的性能,其中該片上系統(tǒng)在基于 XC7Z020 的開發(fā)平臺(如 Digilent 的 ZedBoard)上運行。使用 XC7Z020 FPGA 后,兩個 DNN 均實現(xiàn)了高效性能,但 CNN 實現(xiàn)了每瓦特 7.27 每秒十億次運算 (GOPS),而 BNN 在相同零件上的數(shù)據(jù)為 44.2 GOPS/瓦5。
由于其可編程性和高能效,F(xiàn)PGA 已成為使用 CNN 的應(yīng)用(如嵌入式視覺)的熱門推理平臺6。先進的 FPGA 組合了嵌入式存儲器和多個并行處理數(shù)字信號處理 (DSP) 單元,可加快 GEMM 和其他矩陣計算。雖然 BNN 需要的 DSP 資源僅是 CNN 所需的一小部分,但 FPGA 仍然非常適合這些架構(gòu)。例如,開發(fā)人員可利用能夠加速此架構(gòu)中二進制卷積或其他按位運算的專用邏輯,來增強其基于 FPGA 的 BNN。
但是,對于專注于大型應(yīng)用的典型開發(fā)人員而言,即使縮短項目日程以適應(yīng)快速發(fā)展的應(yīng)用領(lǐng)域(如可穿戴設(shè)備和其他聲控連接產(chǎn)品),只要對基于 FPGA 的 DNN 進行優(yōu)化設(shè)計,不論類型如何,都會造成拖延。Lattice Semiconductor 的 SensAI? 技術(shù)堆棧通過專門的 DNN IP、參考設(shè)計、設(shè)計服務(wù)以及用于實現(xiàn)推理模型的簡單 FPGA 開發(fā)工作流程消除了這一障礙。
基于 FPGA 的 BNN 解決方案
SensAI 將 DNN IP 與神經(jīng)網(wǎng)絡(luò)編譯器結(jié)合在一個工作流程中,旨在加快實現(xiàn)通過行業(yè)標(biāo)準(zhǔn)機器學(xué)習(xí)框架(包括 Caffe 和 TensorFlow)創(chuàng)建的神經(jīng)網(wǎng)絡(luò)模型(圖 1)。
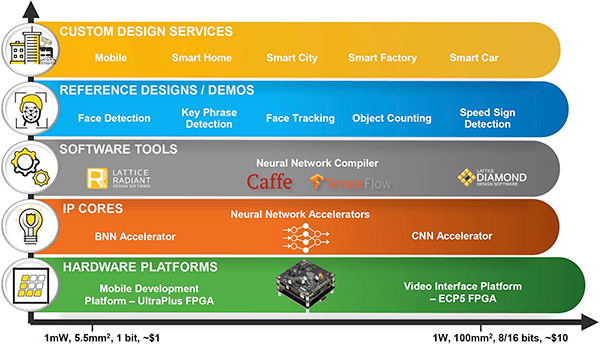
圖 1:Lattice SensAI 技術(shù)堆棧可幫助開發(fā)人員使用通過標(biāo)準(zhǔn)機器學(xué)習(xí)框架創(chuàng)建的 CNN 和 BNN 模型,在 Lattice iCE40 UltraPlus 和 ECP5 FPGA 上實現(xiàn)低功耗推理引擎。(圖片來源:Lattice Semiconductor)
Lattice 的 CNN IP 旨在與 Lattice ECP5 FPGA 配合使用,支持在 Lattice 基于 ECP5 的嵌入式視覺開發(fā)套件上運行 1 W 或更低功耗的高性能圖像識別功能。但是,對于資源受限的設(shè)計,Lattice 的 BNN IP 使開發(fā)人員能夠充分利用這種高效架構(gòu),在低功耗 Lattice ICE40 UltraPlus FPGA 上實現(xiàn)推理引擎。
使用 Lattice BNN IP 后,這些基于 ICE40 UltraPlus 的推理引擎可以在顯著降低運行功耗、使用更少存儲器和處理資源的情況下實現(xiàn)高精度。Lattice 通過 KWS 推理模型的完整 ICE40 UltraPlus FPGA 實現(xiàn),展示了此 BNN IP 的效率,其中推理模型實現(xiàn)在 Lattice 移動開發(fā)平臺 (MDP) 上的運行功耗約為 1 mW。
Lattice SensAI BNN IP 包括實現(xiàn) BNN 推理解決方案所需的全套模塊(圖 2)。
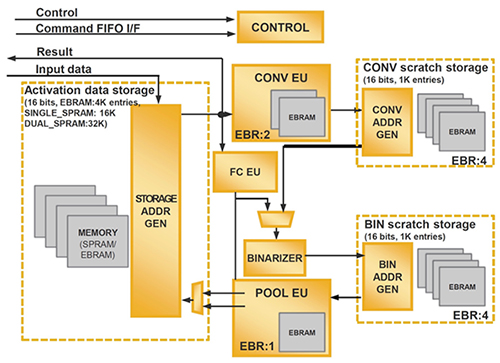
圖 2:Lattice SensAI IP 提供了在 Lattice iCE40 UltraPlus FPGA 上實現(xiàn) BNN 解決方案所需的全套模型層、存儲器子系統(tǒng)、控制邏輯和系統(tǒng)接口。(圖片來源:Lattice Semiconductor)
除了支持卷積、池化和其他 DNN 層功能外,該 IP 還有多個存儲器子系統(tǒng),包括用于訓(xùn)練期間所開發(fā)模型的固定參數(shù)和推理期間所執(zhí)行計算的中間結(jié)果的子系統(tǒng)。除了輸入、輸出和控制線的接口邏輯外,該 IP 還提供了一個控制子系統(tǒng),用于處理實現(xiàn)模型操作的命令序列。
對于新項目,開發(fā)人員使用 Lattice Radiant 軟件包中的一些簡單菜單為其特定設(shè)計生成基本 IP 內(nèi)核。這里,開發(fā)人員只需使用 Radiant IP 配置向?qū)е刑峁┑牟藛芜x項,為所需存儲器(8、16 或 64 KB)和二進制類型(+ 1/-1 或 +1/0)配置 BNN IP 塊。開發(fā)人員通過使用另一個 Radiant 菜單來完成此簡單設(shè)置過程,生成 RTL 和其他支持文件,Radiant FPGA 程序員使用這些文件,根據(jù)其所選 BNN 配置對設(shè)備進行編程。
雖然此 FPGA 編程工作流程為 BNN 模型提供了底層執(zhí)行平臺,但模型本身的編程遵循 SensAI 環(huán)境中的單獨路徑。
在 SensAI 工作流程的模型開發(fā)部分,開發(fā)人員使用 Lattice 神經(jīng)網(wǎng)絡(luò)編譯器將 Caffe 或 TensorFlow 模型轉(zhuǎn)換成相應(yīng)文件,這些文件包含在所配置 BNN 核心上實現(xiàn)這些模型所需的模型參數(shù)和命令序列。在最后一步中,開發(fā)人員使用 Radiant 將模型文件和 FPGA 比特流文件加載到 FPGA 平臺中。
KWS 實現(xiàn)
Lattice 利用了一個旨在運行于 Lattice MDP 之上的基于 BNN 的完整 KWS 模型演示此 BNN 開發(fā)過程。MDP 本身就是一個出色的平臺,結(jié)合了 iCE40 UltraPlus FPGA 和一系列可能在典型低功耗移動應(yīng)用中遇到的外設(shè)。
此開發(fā)板集成了四個 iCE40 UltraPlus 器件,在演示該板內(nèi)置的 1.54 英寸顯示屏、640 x 480 圖像傳感器和 RGB LED 的應(yīng)用中,每個器件都有展示。該板還包含一整套傳感器,包括壓力傳感器、羅盤傳感器、3 軸線性加速計、3D 加速計和 3D 陀螺儀。針對像關(guān)鍵字檢測這樣的音頻應(yīng)用,該電路板還包括兩個 I2S 麥克風(fēng)和兩個 PDM 麥克風(fēng)。對于要求更高的應(yīng)用,開發(fā)人員可以將 Lattice 的 8 麥克風(fēng) LF-81AGG-EVN 子板插入 MDP,以支持音頻波束形成,從而在聲控應(yīng)用中增強方向響應(yīng)(圖 3)。
圖 3:Lattice 移動開發(fā)平臺 (MDP) 集成了一套廣泛的支持功能和外設(shè),同時為 8 麥克風(fēng)陣列(圖中顯示為與 MDP 相連)等擴展組件提供連接器。(圖片來源:Lattice Semiconductor)
該開發(fā)板的內(nèi)置電源管理電路允許開發(fā)人員采用內(nèi)部鋰離子電池實現(xiàn)獨立操作,或采用外部電源為該板供電。在開發(fā)過程中,可通過主機開發(fā)平臺 USB 連接為該板供電。此主機可運行 Lattice iCEcube2,用于創(chuàng)建自定義設(shè)計,或運行 Lattice Radiant 編程器,以使用像 Lattice 關(guān)鍵詞檢測演示這樣預(yù)先建立的設(shè)計對板載 iCE40 FPGA 進行編程。
Lattice DNN 演示(包括用于關(guān)鍵字詞檢測的演示)提供了一整套常規(guī)情況下通過 SensAI 工作流生成的文件。因此,開發(fā)人員使用 Radiant 編程器即可加載這些文件,以評估模型的性能,例如關(guān)鍵字詞檢測演示中的 BNN 推理模型。
對于希望檢查實現(xiàn)細節(jié)的開發(fā)人員,演示項目還提供模型文件,包括 TensorFlow .pb 文件以及 Caffe .proto 和 .caffeemodel 文件。開發(fā)人員可以檢查這些模型以評估所提供的網(wǎng)絡(luò)設(shè)計。對于具有更多特殊要求的應(yīng)用,這些模型可用作開發(fā)人員自有模型的起點。通常,設(shè)計人員會發(fā)現(xiàn)基于典型 CNN 類型設(shè)計的拓撲。
在 Lattice 關(guān)鍵詞檢測演示項目中,所提供的 BNN 網(wǎng)絡(luò)設(shè)計使用熟悉的拓撲結(jié)構(gòu),重復(fù)多個階段,每個階段包括卷積層、批量歸一化層、縮放層、ReLu 激活層和池化層(圖 4)。盡管與傳統(tǒng)的 CNN 設(shè)計在很大程度上無甚區(qū)別,但 Lattice BNN 實現(xiàn)采用內(nèi)部二值參數(shù)和相關(guān)機制,這是此高效架構(gòu)的核心。

圖 4:BNN 包含在 Lattice 演示項目中,使用一個由三個相似卷積模塊組成的流水線執(zhí)行關(guān)鍵詞檢測,每個卷積模塊包括卷積層、批量歸一化層、縮放層、ReLu 激活層和池化層。(圖片來源:Lattice/Ethereon)
Lattice 演示使用用于管理從外部閃存加載的音頻流和命令序列的模塊,將此 BNN 推理模型實現(xiàn)為嵌入 FPGA 中的 BNN 加速器引擎實現(xiàn)(圖 5)。
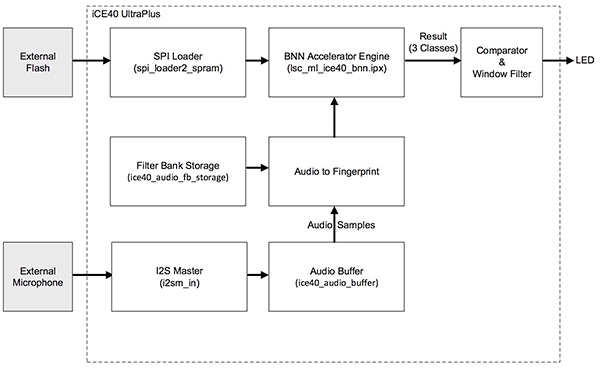
圖 5:Lattice 關(guān)鍵詞檢測演示在單個低功耗 Lattice iCE40 UltraPlus FPGA 上實現(xiàn)了一個完整的 KWS 系統(tǒng)。(圖片來源:Lattice Semiconductor)
這里,I2S 主模塊接受來自外部麥克風(fēng)的音頻數(shù)據(jù),并將數(shù)據(jù)傳遞到音頻緩沖器。音頻到指紋塊進而從緩沖器中讀取音頻樣本,并使用從濾波器組存儲區(qū)讀取的濾波器生成基本音頻頻譜圖。此操作可提供合適的結(jié)果,且沒有傳統(tǒng) FFT 頻譜圖的計算復(fù)雜性。
最后,BNN 加速器引擎使用此經(jīng)處理的音頻流進行推理,產(chǎn)生三種可能的輸出:靜默、關(guān)鍵詞、無關(guān)鍵詞。
在配置好開發(fā)板并加載演示文件后,開發(fā)人員只需通過為 MDP 板供電并說出關(guān)鍵詞(在本例中為“seven”一詞)即可運行演示。當(dāng)推理引擎檢測到關(guān)鍵詞時,F(xiàn)PGA 將打開 MDP 中的內(nèi)置 RGB LED。
總結(jié)
機器學(xué)習(xí)功能強大,可為增強可穿戴設(shè)備和其他移動應(yīng)用提供強大的解決方案,例如與聲控用戶界面配合使用的關(guān)鍵字檢測。雖然像 CNN 這樣的機器學(xué)習(xí)模型架構(gòu)可以提供高度準(zhǔn)確的結(jié)果,但是它們對存儲器、處理和功率的要求通常超出電池供電型設(shè)備的資源能力。
如本文所述,BNN 架構(gòu)解決了這些問題。使用 Lattice Semiconductor 的先進機器學(xué)習(xí)解決方案,開發(fā)人員可以借助這一功耗僅約 1 mW 的 KWS 模型快速增強其設(shè)計。
-
FPGA
+關(guān)注
關(guān)注
1629文章
21744瀏覽量
603660 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100807 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8420瀏覽量
132685
發(fā)布評論請先 登錄
相關(guān)推薦
FPGA在深度神經(jīng)網(wǎng)絡(luò)中的應(yīng)用
分享幾個用FPGA實現(xiàn)的小型神經(jīng)網(wǎng)絡(luò)

殘差網(wǎng)絡(luò)是深度神經(jīng)網(wǎng)絡(luò)嗎
簡單認識深度神經(jīng)網(wǎng)絡(luò)
如何在FPGA上實現(xiàn)神經(jīng)網(wǎng)絡(luò)
深度神經(jīng)網(wǎng)絡(luò)概述及其應(yīng)用
深度神經(jīng)網(wǎng)絡(luò)與基本神經(jīng)網(wǎng)絡(luò)的區(qū)別
深度神經(jīng)網(wǎng)絡(luò)的設(shè)計方法
bp神經(jīng)網(wǎng)絡(luò)是深度神經(jīng)網(wǎng)絡(luò)嗎
卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的是什么
卷積神經(jīng)網(wǎng)絡(luò)的原理與實現(xiàn)
卷積神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)及其功能
深度神經(jīng)網(wǎng)絡(luò)模型有哪些
神經(jīng)網(wǎng)絡(luò)架構(gòu)有哪些
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論