 微控制器的性能分析技術的介紹與了解
微控制器的性能分析技術的介紹與了解
基準測試讓您比較處理器,但仍有很多變化。理解和運行標準基準可以讓設計人員更好地了解和控制他們的應用程序。
比較微處理器從未如此簡單。即使比較通常具有相同基本架構的所有變體的處理器的臺式計算機或膝上型計算機也可能令人沮喪,因為與“更差”的數字相比,具有更快數字的計算機可能運行緩慢。在嵌入式世界中,事情變得更加艱難,其中處理器和配置的數量實際上是無限的。
基準測試是解決這一難題的常用方法。多年來,Dhrystone基準(Whetstone基準測試中的一個游戲,其中包括Dhrystone省略的浮點運算)是城里唯一的游戲。但是,它有許多重大問題。其中最主要的是它不反映任何實際計算,它只是試圖模仿各種操作的統計頻率。此外,編譯器通常可以在編譯時執行大部分計算,這意味著在運行基準測試時不必完成工作。
對基準測試的真正考驗是,在詳細查看結果(特別是那些最初看起來很奇怪的結果)時,您可以合理化為什么結果看起來像他們一樣。理想的基準測試將提供純粹反映處理器性能的分數,與系統的其他部分無關。不幸的是,這是不可能的,因為沒有處理器孤立地運行:所有處理器必須與內存交互 - 高速緩存,數據存儲器和指令存儲器,每個處理器可能會或可能不會以完整的處理器頻率運行。此外,這些處理器必須全部運行由編譯器生成的代碼,并且不同的編譯器生成不同的代碼。
即使是相同的編譯器也會根據編譯代碼時選擇的優化設置生成不同的代碼。這種差異是無法避免的,但要避免的主要是將實際的基準代碼優化掉。
盡管結果可能取決于編譯器和內存,但您應該只能根據處理器本身,編譯器(和設置)以及內存速度來解釋任何此類結果。 Dhrystone基準測試的情況并非如此。然而,嵌入式微處理器基準聯盟(EEMBC)最近的CoreMark基準測試已經克服了這些缺陷,并且被證明更加成功。點擊EEMBC在2009年開發并公開發布了CoreMark基準(現已由超過4,100名用戶下載)。它已經適用于眾多平臺,包括Android。開發人員特別注意避免舊基準測試的陷阱。通過查看CoreMark基準測試的工作原理以及一些示例結果,我們可以看到它不僅可以成為性能的可靠指標,還可以幫助確定微控制器和編譯器性能的改進位置。
CoreMark基準程序
CoreMark基準程序使用三種基本數據結構來表示實際工作。第一個結構是鏈表,它執行指針操作。第二個是矩陣;矩陣運算通常涉及嚴格優化的循環。最后,狀態機需要難以預測的分支,并且其結構比用于矩陣運算的循環要少得多。
為了保持盡可能多的嵌入式系統的可訪問性,無論大小,該程序都有2 kb的代碼占用空間。圖1說明了程序的工作原理。前兩個步驟可能看似微不足道,但它們實際上非常重要 - 它們是確保編譯器無法預先計算任何結果的步驟。直到運行時才知道要使用的輸入數據。
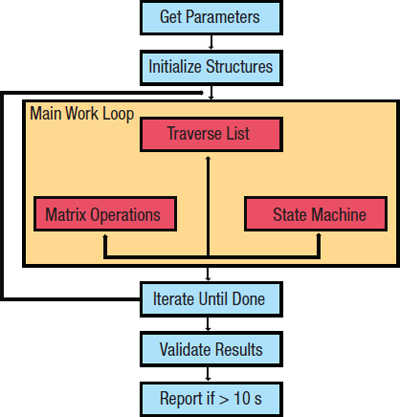
圖1:CoreMark基準測試過程。
大部分基準工作負載發生在主工作循環中。掃描其中一個數據結構,即鏈表。每個條目的值確定是否要執行矩陣操作或狀態機操作。重復該決策操作步驟直到列表用盡。此時,單個迭代完成。重復工作循環直到至少10秒鐘。實施10秒要求以確保足夠的數據以提供有意義的結果。如果運行時間小于此值,那么基準程序將不會報告結果。但是,如果用戶在模擬器上運行基準測試,則可以修改此時間要求。
主要工作完成后,使用公共循環冗余校驗(CRC)功能;它可以作為一種自我檢查,以確保在執行過程中(偶然或其他方面)沒有出錯。假設一切都結束,程序將報告CoreMark結果。此數字表示每秒執行時間的主工作循環的迭代次數。點擊雖然大多數基準用戶都是誠實的,但確保任何基準測試方案都有針對濫用的保護措施始終是非常重要的。有人可以嘗試篡改結果的兩種主要方式:編輯代碼(在移植層內除外),因為代碼必須以源代碼形式提供,并且只是偽造結果。 CRC有助于檢測代碼損壞時可能出現的任何問題,并且EEMBC技術中心的認證是最終仲裁者。沒有人需要對他們的結果進行認證,但認證增加了顯著的可信度,因為它證實了中立的第三方獲得了相同的數字。
調整基準測試運行
當程序查找用于初始化數據的用戶參數時,您不會顯式提供原始數據。這將是太多的工作,它還將通過仔細選擇初始化數據開辟操縱的可能性。相反,程序會查找必須由用戶設置的三粒種值。
這些數字以對用戶不透明的方式指導數據結構中值的初始化。雖然它們充當“種子”,但沒有隨機因素。結構是完全確定的,并且具有相同種子的基準的多次運行將導致相同的執行和結果。
您可能還需要調整基準來考慮系統分配內存的方式。具有充足資源的系統可以簡單地使用heap和malloc()調用。這允許在需要時進行每次內存分配,并確保所需的內存量。然而,這種靈活性需要付出代價,更好的系統需要更快的方式來使用內存。
最快的方法是完全預分配內存,但使用不可行的鏈表操作。中間方法是創建許多預定義的內存塊(內存池),可以根據需要進行分配。權衡是你不能選擇每個塊中有多少內存 - 你得到一個固定大小的塊。移植層允許您使基準測試適應被評估系統上使用的內存分配方案的類型。并行性是您可以利用的另一個特性,如果您的系統支持它。您可以為并行操作構建CoreMark基準,指定在執行期間生成的上下文(線程或進程)的數量。但是,您應該避免使用CoreMark來表示處理器的多核性能,因為由于其小尺寸,該基準測試肯定會線性擴展99.9%。
了解結果
當然,這是您對基準測試結果所做的事情,可能導致混淆(有意或無意)。出于這個原因,EEMBC強加了嚴格的報告要求。 CoreMark網站http://www.coremark.org提供了報告結果的位置,您不能只輸入一個CoreMark分數。還有一些其他關鍵變量可能會影響您的結果。
最大的是使用的編譯器和編譯基準時設置的選項。您必須在提交結果時報告該信息。
第二個主要影響因素是分配內存的方式 - 如果它不是堆(malloc),您必須報告所采用的方法。
第三個因素,在相關時,是并行化。您必須報告創建的上下文的數量。
還有另一種方法可以報告結果。您可以將時鐘頻率標準化,而不是指定原始CoreMark值,以便專注于架構效率。這是一個CoreMark/MHz值,用于衡量每百萬個時鐘周期的迭代次數。如果報告此編號,則還必須報告相對于處理器時鐘速度的內存速度。如果可以相對于處理器頻率配置高速緩存頻率,則還必須報告該配置。
查看某些特定結果可以幫助顯示各種所需報告元素如何與不同的基準分數相關聯,以及在報告結果時識別這些元素的重要性。隨后的所有數字均來自CoreMark網站上公開的結果列表。
編譯器版本的簡單影響可以在表1的結果中看到。使用較新的編譯器版本,ADI公司的處理器顯示速度提高了10%,可能表明新編譯器的工作做得更好。 Microchip示例顯示了兩個更遠的GNU C編譯器(gcc)版本之間的差異。對于兩個恩智浦處理器,所有編譯器都是同一版本的微妙變體,從而最大限度地減少了差異。
ProcessorCompilerCoreMark/MHz模擬器件BF536gcc 4.1.21.01gcc 4.3.31.12Microchip PIC32MX36F512Lgcc 3.4.4 MPLAB C32 v1.00-200710241.90gcc 4.3.2(Sourcery G ++ Lite 4.3-81)2.30NXP LPC1114Keil ARMcc v4.0.0.5241.06gcc 4.3 .3(紅色代碼)0.98NXP LPC1768ARM CC 4.01.75Keil ARMCC v4.0.0.5241.76表1:不同編譯器對CoreMark結果的影響。即使使用相同的編譯器,不同的設置當然會產生不同的結果因為編譯器試圖以不同方式優化程序。表2顯示了一些示例結果。
ProcessorCompilerSettingsCoreMark/MHzMicrochip
PIC24JF64GA004gcc 4.0.3 dsPIC030,Microchip v3_20-Os -mpa1.01-031.12Microchip
PIC24HJ128GP202gcc 4.0.3 dsPIC030,Microchip v3.12-031.86-mpa1.29Microchip
PIC32MX36F512Lgcc 4.4.4 MPLAB C32 v1.00-20071024-021.71-031.90表2:更改編譯器設置會產生不同的CoreMark結果。
第一個例子(PIC24JF64GA004),針對較小的代碼尺寸進行優化需要降低約10%的基準性能。在第二種情況下,差異更為顯著,在設置過程抽象優化標志(-mpa)時運行速度降低30%。最后一個處理器上的編譯器設置之間的差異也反映了優化量的差異,從-O3設置提供的更高速度優化中獲益大約10%。
內存的影響可以在表3中看到。在第一種情況下,當時鐘頻率超過閃存可以處理的頻率時,會引入等待狀態,從而降低CoreMark/MHz數量。類似地,在第二種情況下,DRAM無法跟上50 MHz以上的處理器,因此存儲器和處理器之間的時鐘頻率比降至1:2,從而降低了CoreMark/MHz數量。
ProcessorClock
SpeedMemory NotesCoreMark/MHzCoreMarkTI OMAP 3530500Code in FLASH2.4212106002.191314TI Stellaris LM3S9B96 Cortex M3501:1內存/CPU時鐘不可能超過50 Mhz1.9296801.60128表4:更改緩存大小對CoreMark結果的影響。 》然而,在這兩種情況下,時鐘頻率的增加都大于運行效率的降低,因此原始CoreMark數量仍然隨著時鐘頻率的增加而增加;它只是沒有像頻率那樣增加。點擊最后,緩存大小的影響可以在表4中看到。這里,代碼適合第一個配置的2 kb緩存,但它完全填充緩存。堆棧上的所有函數參數都不適合,因此會有一些緩存未命中。在第二種情況下,緩存具有兩倍的容量,這意味著它不會遇到與第一個示例中相同的緩存未命中,從而為其提供更好的分數。
ProcessorCompilerCoreMark/MHzAnalog器件BF536gcc 4.1.21.01表3:內存設置對CoreMark結果的影響。
請注意,與第一種情況的三級流水線相比,第二種情況有五級流水線。由于狀態機示例的廣泛分支,較長的管道應該導致性能下降。當分支被錯誤預測時,較長的管道需要更長的時間來重新填充。因此,較高的CoreMark分數表明較大的緩存超過了這種降級。
所有這些例子中的得分都證明了兩個事實。首先,單個數字(在本例中為CoreMark/MHz)可以準確地表示底層微控制器架構的性能;后面的例子清楚地表明了這一點。其次,背景是重要的。編譯器可以影響它生成的代碼執行的程度。這幾乎應該是顯而易見的 - 人們花費大量時間來開發和改進編譯器以改進他們創建的結果,但“好”結果取決于您的目標是快速代碼還是小代碼。更快的代碼將運行得更快,更小的代碼將不會運行(除非它實際上有助于優化內存或緩存利用率)。但是,這些例子顯示的最重要的事情是結果之間的差異有合理的解釋。它們不是由一些實際的基準測試代碼引起的,這些代碼可能有利于一個微控制器架構而不是另一個,或者是編譯器直接丟棄代碼。從這個意義上講,CoreMark基準測試是公平和平衡的,可以真實地反映編譯器和體系結構,而且只能反映編譯器和體系結構。
-
微控制器
+關注
關注
48文章
7576瀏覽量
151727 -
處理器
+關注
關注
68文章
19382瀏覽量
230484 -
編譯器
+關注
關注
1文章
1638瀏覽量
49197
發布評論請先 登錄
相關推薦
LPC微控制器產品族譜
AT32微控制器硬件設計指南及抗EMC設計要點
如何讓微控制器性能發揮極限



基于MAXQ3120微控制器的性能特點與應用分析






 工商網監
工商網監
評論