 如何在Raspberry Pi 3上構建機器學習應用程序
如何在Raspberry Pi 3上構建機器學習應用程序
希望評估機器學習方法的開發人員發現了越來越多的專業硬件和開發平臺,這些平臺通常針對特定類別的機器學習架構和應用程序進行調整。雖然這些專業平臺對于許多機器學習應用程序至關重要,但很少有新的機器學習人員可以做出有關選擇理想平臺的明智決策。
開發人員需要一個更易于訪問的平臺來獲得機器開發經驗學習應用程序并更深入地了解資源需求和最終的功能。
如Digi-Key文章“使用隨時可用的硬件和軟件開始機器學習”中所述,開發任何用于監督機器學習的模型包括三個關鍵步驟:
準備培訓模型的數據
模型實施
模型培訓
數據準備將熟悉的數據采集方法與標記特定數據實例所需的額外步驟相結合,以便在培訓過程中使用。對于最后兩個步驟,機器學習模型專家直到最近才需要使用相對較低級別的數學庫來實現模型算法中涉及的詳細計算。機器學習框架的可用性大大降低了模型實施和培訓的復雜性。
今天,任何熟悉Python或其他支持語言的開發人員都可以使用這些框架快速開發能夠運行的機器學習模型。各種各樣的平臺。本文將介紹如何在Raspberry Pi 3上開發機器學習應用程序之前的機器學習堆棧和培訓過程。
機器學習堆棧
為了支持模型開發,機器學習框架提供了一整套資源(圖1)。在典型堆棧的頂部,培訓和推理庫提供定義,培訓和運行模型的服務。這些模型反過來建立在內核函數的優化實現上,例如卷積和激活函數,如ReLU,以及矩陣乘法等。這些優化的數學函數適用于較低級別的驅動程序,這些驅動程序提供抽象層以與通用CPU連接,或者在可用時充分利用專用硬件(如圖形處理單元(GPU))。
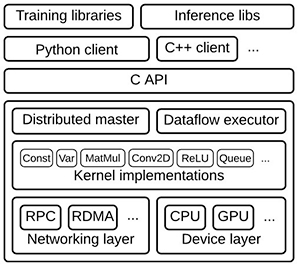
圖1:在典型的機器學習堆棧中,更高級別的庫提供了實現神經網絡和其他機器學習算法的功能,借鑒了專業的數學庫實現針對底層硬件層中的CPU和GPU優化的內核函數。 (圖片來源:Google)
隨著提供這些堆棧的TensorFlow等機器學習框架的可用性,無論硬件目標如何,在應用程序中實現機器學習的開發過程大致相同。在不同硬件平臺上利用TensorFlow的能力允許開發人員開始在相對適度的硬件平臺上探索模型開發,然后利用這些經驗在更強大的硬件上開發機器學習應用程序。
預計專業的高性能人工智能(AI)芯片最終將為開發人員提供實現復雜機器學習算法的能力。在此之前,開發人員可以開始評估機器學習并使用通用平臺創建真正的機器學習應用程序,包括Raspberry Pi Foundation的Raspberry Pi 3,或任何基于通用處理器(如Arm ?)的現成開發板。 Cortex ? -A系列MCU或Arm Cortex-M系列MCU。
Raspberry Pi 3作為機器學習應用程序的開發平臺提供了一些直接的優勢。其Arm Cortex-A53四核處理器提供了顯著的性能,而核心的NEON單指令,多數據(SIMD)擴展能夠執行一定程度的多媒體和機器學習類型處理。但是,開發人員可以使用任意數量的兼容硬件附件輕松擴展基礎Raspberry Pi 3硬件平臺。
例如,要創建下面描述的機器學習圖像識別系統,開發人員可以添加相機,如800萬像素Raspberry Pi相機模塊v2或其低光Pi NoIR相機(圖2)。
圖2:低 - 諸如Raspberry Pi 3之類的成本板為機器學習開發提供了一個有用的平臺,支持諸如用于開發圖像分類應用程序的相機模塊之類的附加組件。 (圖片來源:Raspberry Pi Foundation)
在軟件方面,Raspberry Pi社區創建了一個同樣豐富的生態系統,開發人員可以在其中找到包含完整的預編譯二進制輪文件的分發版,以便在Raspberry上安裝TensorFlow皮。 TensorFlow在Raspberry Pi車輪存儲庫piwheels.org上為Python 3.4和3.5提供了這些車輪文件。或者,由于Docker現在正式支持Arm架構,開發人員可以使用dockerhub.com中的合適容器。
實現機器學習模型
使用這種軟件,Raspberry Pi 3和相機模塊的組合,開發人員可以使用Arm的示例代碼構建一個簡單的機器學習手勢識別應用程序。此應用程序僅用于檢測用戶何時做出特定手勢:在這種情況下,以一種慶祝手勢向空中舉手。
首先,使用Python腳本(記錄。 py)記錄幾次執行相同手勢的人的短視頻片段。由于此應用程序應盡可能簡單,因此下一步將使用TensorFlow中嵌入的Keras機器學習應用程序編程接口(API)開始培訓。在此示例中,訓練過程在另一個Python腳本(train.py)中定義,該腳本包括Keras模型定義和訓練序列(清單1)。
復制 def main():. 。 。 model_file = argv [1] recording_files = argv [2:] feature_extractor = PiNet()。 。 。 for i,filename in enumerate(recording_files):stdout.write('%s'%filename)stdout.flush()with open(filename,'rb')as f:x = load(f)features = [feature_extractor.features (f)對于f in x] label = np.zeros((len(recording_files),))label [i] = 1.#在該列的文件欄中創建一個帶有1的標簽xs + = features#添加從此文件加載的幀的功能ys + = [label] * len(x)#為文件中的每個幀添加標簽class_count [i] = len(x)print(“創建網絡以對%s進行分類“%','。join(recording_files))classifier = make_classifier(xs [0] .shape,len(recording_files))print(”訓練網絡將高級功能映射到%d類別“%len(recording_files)) classifier.fit([np.array(xs)],[np.array(ys)],epochs = 20,shuffle = True)print(“現在我們保存這個模型,以便我們可以隨時部署它”)分類器。 save(model_file)def make_classifier(input_shape,num_classes):“”“制作一個非常簡單的分類器圖層:GaussianNoise:添加隨機噪聲到pre發泄我們的分類器記住具體的例子。展平:輸入可能來自具有形狀(x,y,深度)的層;將其壓平至1D。密集:每個類提供一個輸出,按比例縮放為1(softmax)“”##定義一個簡單的神經網絡net_input = keras.layers.Input(input_shape)noise = keras.layers.GaussianNoise(0.3)(net_input)flat = keras .layers.Flatten()(noise)net_output = keras.layers.Dense(num_classes,activation ='softmax')(flat)net = keras.models.Model([net_input],[net_output])#在使用前編譯模型損失應該與輸出激活函數匹配,例如#binary_crossentropy用于sigmoid,categorical_crossentropy用于softmax,mse用于線性。#Adam是一個可靠的默認優化器,我們可以將學習速率保留為默認值.net.compile(optimizer = keras。 optimizers.Adam(),loss ='categorical_crossentropy',metrics = ['accuracy'])return net
清單1:在Arm示例應用程序庫的這個片段中,培訓過程結合了一個預先訓練好的模型,該應用程序需要簡單的分類器。(代碼來源:Arm)
盡管這個模型很簡單,它實際上非常復雜,使用了一種稱為轉移學習的技術。轉移學習使用經過驗證的模型,該模型使用一個數據集作為培訓針對不同但相關問題集的模型的起點。在這種情況下,該應用程序使用來自Google的MobileNet模型集的優化卷積神經網絡(CNN)模型。
由Google開發的MobileNet模型是CNN在標記的事實標準ImageNet數據集的子集上進行訓練圖片。 MobileNet模型的顯著特點是它們被配置為支持移動設備或通用板(如Raspberry Pi)所需的減少的資源需求。這種資源減少的成本降低了準確性。雖然這些模型提供的精確度遠遠低于關鍵任務應用程序的要求,但MobileNet模型可以證明對于更寬松的要求和轉移學習中的基本模型非常有用。
對于此應用程序,train.py腳本使用MobileNet模型創建一個特征提取器,其中最終分類層已被刪除:
feature_extractor = PiNet()
PiNet函數只讀取代碼庫中包含的修改后的MobileNet模型。
然后,應用程序使用該修改后的模型為此訓練數據集創建要素集(要素):
features = [feature_extractor.features(f)for f in x]
其中x是一個數組,包含在初始數據收集步驟中由record.py生成的幀。
最后,train.py腳本使用Keras fit方法訓練模型和save方法以保存最終模型以供推理使用:
classifier.fit ([np.array(xs)],[np.array(ys)],epochs = 20,shuffle = True)
classifier.save(model_file)
要使用生成的模型文件進行推理,請調用另一個腳本run.py.此腳本中的關鍵設計模式是無限循環,它采用每個幀,計算要素(extractor.features),使用相同的分類器進行推理(classifier.predict),并生成標簽的預測(np.argmax)。預測只是目標手勢是否已經發生(清單2)。
復制 而True:raw_frame = camera.next_frame()#使用MobileNet獲取此幀的功能z = extractor.features(raw_frame)#使用這些功能,我們可以預測a 'normal'/'yeah'class(0或1)#Keras期望一組輸入并產生一個輸出數組classes = classifier.predict(np.array([z]))[0]#smooth the outputs - this添加延遲但減少中斷平滑=平滑* SMOOTH_FACTOR +類*(1.0 - SMOOTH_FACTOR)選擇= np.argmax(平滑)#所選類是概率最高的類#顯示類概率和選定的類摘要='類%d [%s]'%(已選中,''。join('%02.0f %%'%(99 * p)為平滑的p))stderr.write(' r'+ summary)
清單2:Arm示例run.py腳本中的這個片段演示了推理的基本設計模式,使用相同的預訓練模型提取特征和相同的分類器來執行推理。 (代碼源:Arm)
多分類模型
開發一個應用程序來檢測一類輸入,例如單個手勢,這在機器學習開發中是值得的,但機器學習應用程序通常用于多類分類。另一個Arm示例應用程序演示了執行此操作所需的步驟,并提供了完成多分類模型開發通常所需步驟的更完整示例。例如,除了捕獲期望的手勢之外,單個手勢應用程序不需要重要的數據準備。相比之下,多分類應用程序涉及大量數據捕獲和相關的開發步驟,以使用Arm提供的Python腳本使用目標類(手勢)標記捕獲的視頻。在這種情況下,開發者捕獲不同動作的短視頻剪輯,例如進入或離開房間,指向燈(打開或關閉),以及制作不同的手勢以開始或停止音樂播放。使用classify.py腳本,查看圖像并輸入相應的標簽(與每個操作對應的整數)。標記完成后,保留約10%的標記數據,用于測試模型,如下所述。
使用訓練數據和保留的測試集,下一步是創建模型本身。與在單個手勢應用程序中大量使用預訓練模型不同,此應用程序構建完整的CNN模型。在這種情況下,使用一系列Keras語句,使用構建2D卷積層(Conv2D)的Keras函數逐層構建模型,添加激活層(激活),池化層(MaxPooling2D)等(列表) 3)。
復制 def main():如果len(argv)!= 3或argv [1] ==' - help':print(“ “”用法:train.py TRAIN_DIR VAL_DIR ...訓練一個轉換網后保存TRAIN_DIR/model.h5以區分其子目錄中的圖像。“”“)exit(1)train_data_dir = argv [1] val_data_dir = argv [2 ] nb_train_samples = len(glob('%s/*/* .png'%train_data_dir))nb_classes = len(glob('%s/*/'%train_data_dir))batch_size = 100 model = Sequential()model.add( Conv2D(32,(3,3),input_shape =(128,128,3)))model.add(Activation('elu'))model.add(MaxPooling2D(pool_size =(2,2)))model.add (Conv2D(32,(3,3)))model.add(Activation('elu'))model.add(MaxPooling2D(pool_size =(2,2)))model.add(Conv2D(64,(3,3) )))model.add(Activation('elu'))model.add(MaxPooling2D(pool_size =(2,2))) model.add(Flatten())model.add(Dense(64))model.add(Activation('elu'))model.add(Dropout(0.5))model.add(Dense(nb_classes))model.add(激活('softmax'))model.compile(loss ='categorical_crossentropy',optimizer ='adam',metrics = ['accuracy'])
清單3:Arm多分類示例應用程序說明了使用Keras函數逐層構建卷積神經網絡。 (代碼源:Arm)
該模型還引入了dropout層的概念(清單3中的Dropout),它提供了一種稱為正則化的模型優化形式。在模型訓練算法中,正則化因子降低了模型追逐每個特征的趨勢,這可能導致模型中的過度擬合。 Dropout通過將一組隨機神經元從處理鏈中刪除而執行同樣的功能(圖3)。
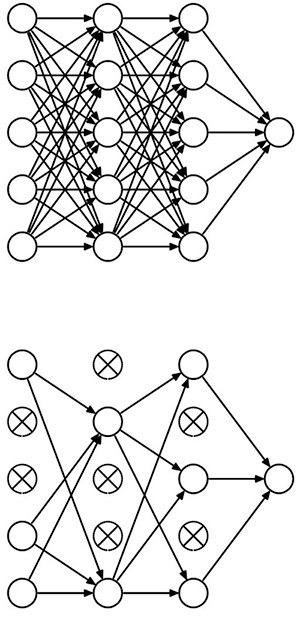
圖3:Dropout通過隨機禁用神經元在深層神經網絡中提供正則化,有效地將完全連接的神經網絡(頂部)轉換為密度較低的版本(底部) 。 (圖片來源:多倫多大學)
掌握完成的模型后,使用TensorFlow和其他框架內置的傳統培訓方法。對于非常復雜的模型,實際的培訓過程可能需要數小時,數天甚至數周。雖然開發人員通常使用GPU來加速培訓,但是像之前的應用程序一樣,使用傳輸學習可以幫助減少培訓時間。但是,在此多分類應用程序中使用完整模型會轉化為更長的訓練時間。 Arm指出,這個應用程序的培訓時間在Raspberry Pi上可能很重要。相反,Arm建議開發人員在自己的工作站上安裝TensorFlow,在工作站上進行培訓,然后將訓練好的模型復制回Raspberry Pi。
使用模型時,推理過程大部分遵循相同的系列先前為單個手勢應用程序顯示的調用。當然,對于這個應用程序,推理過程使用清單3中描述的自定義模型,而不是清單1中描述的單個手勢預訓練模型和淺層分類器。除了這個明顯的差異之外,多分類模型開發還增加了一個額外的步驟用于在生產使用之前測試模型。
在此測試階段,運行模型就像生產推理一樣,但不使用一些新的輸入數據,而是使用培訓中保留的10%標記數據。由于已經知道每個測試圖像推斷的正確答案,因此測試腳本可以記錄實際的準確度結果,以便與完成培訓時獲得的準確度結果進行比較。
除了作為硬度量標準的基本優勢之外,測試階段和模型響應測試數據的方式可以提供關于可能需要采取哪些步驟來改進模型的提示。因為該測試數據包括在訓練中使用的相同類型的數據,所以訓練的模型應該產生具有在訓練期間實現的相同精度水平的預測。對于過度擬合的模型,減少輸入特征的數量并應用更強大的正則化方法。對于有欠配合的模型,請做相反的事情;添加更多功能并減少正規化量。
基于MCU的應用程序
TensorFlow和其他框架均提供一致的模型開發方法,可應用于各種目標硬件平臺。然而,它們絕不是唯一的方法。在基于Arm的平臺上開發機器學習應用程序時,開發人員可以轉向公司自己的庫。
Arm Compute Library開發用于支持Arm Cortex-A系列MCU,提供了一整套實現CNN的功能。和其他機器學習算法。對于Arm Cortex-M系列MCU,Arm Cortex微控制器軟件接口標準(CMSIS)包括神經網絡(NN)庫。正如CMSIS-DSP擴展用于DSP應用的CMSIS一樣,CMSIS-NN提供機器學習功能,用于在基于Arm Cortex-M的平臺上實現流行的NN架構。例如,使用CMSIS-NN庫在STMicroelectronics NUCLEO-F746ZG開發板上實現CNN,該開發板是基于STMicroelectronics Arm Cortex-M7的STM32F746ZG MCU構建的。
用CMSIS實現神經網絡-NN,開發人員可以從TensorFlow或其他框架導入現有模型。或者,他們可以通過一系列CMSIS-NN函數調用本地實現CNN。例如,為了實現能夠處理行業標準CIFAR-10標記圖像數據集的CNN,開發人員將逐層構建模型,類似于之前針對Keras所示的方法。在這種情況下,CNN層實現為一系列CMSIS-NN函數調用。最終的softmax層產生CIFAR-10所需的10個輸出神經元(清單4)。
復制 int main(){。 。 。//conv1 img_buffer2 - > img_buffer1 arm_convolve_HWC_q7_RGB(img_buffer2,CONV1_IM_DIM,CONV1_IM_CH,conv1_wt,CONV1_OUT_CH,CONV1_KER_DIM,CONV1_PADDING,CONV1_STRIDE,conv1_bias,CONV1_BIAS_LSHIFT,CONV1_OUT_RSHIFT,img_buffer1,CONV1_OUT_DIM,(q15_t *)col_buffer,NULL); arm_relu_q7(img_buffer1,CONV1_OUT_DIM * CONV1_OUT_DIM * CONV1_OUT_CH);//pool1 img_buffer1 - > img_buffer2 arm_maxpool_q7_HWC(img_buffer1,CONV1_OUT_DIM,CONV1_OUT_CH,POOL1_KER_DIM,POOL1_PADDING,POOL1_STRIDE,POOL1_OUT_DIM,NULL,img_buffer2);//CONV2 img_buffer2 - > img_buffer1 arm_convolve_HWC_q7_fast(img_buffer2,CONV2_IM_DIM,CONV2_IM_CH,conv2_wt,CONV2_OUT_CH,CONV2_KER_DIM,CONV2_PADDING,CONV2_STRIDE,conv2_bias,CONV2_BIAS_LSHIFT,CONV2_OUT_RSHIFT,img_buffer1,CONV2_OUT_DIM,(q15_t *)col_buffer,NULL); arm_relu_q7(img_buffer1,CONV2_OUT_DIM * CONV2_OUT_DIM * CONV2_OUT_CH);//POOL2 img_buffer1 - > img_buffer2 arm_maxpool_q7_HWC(img_buffer1,CONV2_OUT_DIM,CONV2_OUT_CH,POOL2_KER_DIM,POOL2_PADDING,POOL2_STRIDE,POOL2_OUT_DIM,col_buffer,img_buffer2);//conv3 img_buffer2 - > img_buffer1 arm_convolve_HWC_q7_fast(img_buffer2,CONV3_IM_DIM,CONV3_IM_CH,conv3_wt,CONV3_OUT_CH,CONV3_KER_DIM,CONV3_PADDING ,CONV3_STRIDE,conv3_bias,CONV3_BIAS_LSHIFT,CONV3_OUT_RSHIFT,img_buffer1,CONV3_OUT_DIM,(q15_t *)col_buffer,NULL); arm_relu_q7(img_buffer1,CONV3_OUT_DIM * CONV3_OUT_DIM * CONV3_OUT_CH);//pool3 img_buffer-> img_buffer2 arm_maxpool_q7_HWC(img_buffer1,CONV3_OUT_DIM,CONV3_OUT_CH,POOL3_KER_DIM,POOL3_PADDING,POOL3_STRIDE,POOL3_OUT_DIM,col_buffer,img_buffer2); arm_fully_connected_q7_opt(img_buffer2,ip1_wt,IP1_DIM,IP1_OUT,IP1_BIAS_LSHIFT,IP1_OUT_RSHIFT,ip1_bias,output_data,(q15_t *)img_buffer1); arm_softmax_q7(output_data,10,output_data); for(int i = 0; i <10; i ++){printf(“%d:%d n”,i,output_data [i]); } return 0;}
清單4:在Arm示例CIFAR-10應用程序的這個片段中,主例程說明了用于構建CIFAR10目標卷積神經網絡的一系列調用。 Arm Cortex微控制器軟件接口標準(CMSIS)神經網絡(NN)庫。 (代碼來源:Arm)
通用平臺缺乏資源來提供基于GPU的系統可能的推理性能。結果,這些平臺通常不能可靠地支持以維持無閃爍外觀所需的通常幀速率操作的任何類型的“實時”視頻推斷。即便如此,上述CMSIS-NN CIFAR-10模型可以實現大約每秒10的推理速度,這可能足夠快以支持需要有限更新速率的相對簡單的應用程序。
持續發展簡化的模型,如MobileNet和TensorFlow Lite和Facebook的Caffe2Go等框架,為物聯網和其他連接應用的資源受限設備實現機器學習提供了更多選擇。
結論
機器學習應用程序遵循典型的數據準備和培訓開發模式,在不同的目標平臺上保持概念上的一致性。因此,開發人員可以使用低成本開發板快速獲得實現機器學習算法的經驗。
隨著機器學習庫和針對這些板優化的框架的可用性,開發人員可以使用諸如Raspberry之類的板Pi 3或STMicroelectronics NUCLEO-F746ZG實現了有效的機器學習推理引擎,能夠為具有適度要求的應用提供有用的結果。
-
cpu
+關注
關注
68文章
10882瀏覽量
212220 -
gpu
+關注
關注
28文章
4754瀏覽量
129069 -
應用程序
+關注
關注
37文章
3283瀏覽量
57756 -
機器學習
+關注
關注
66文章
8425瀏覽量
132773
發布評論請先 登錄
相關推薦
如何在Raspberry Pi上安裝TensorFlow
如何在Raspbian上設置沒有顯示器和鍵盤的Raspberry Pi
如何使用Raspberry Pi3和藍牙構建遙控汽車
Raspberry Pi 3和3 b +上的Android Pie 9.0
使用計算庫在Raspberry PI和HiKey 960上分析AlexNet
raspberry pi官網
Eyer1951正在使用帶有節拍檢測應用程序的Raspberry Pi 3 B +
在Raspberry Pi上安裝Android的方法
使用Raspberry Pi上的OpenCV庫構建人臉識別系統
如何在Raspberry Pi 3上安裝OpenCV4庫
基于Raspberry PI的應用程序的典型場景家庭自動化

如何在Raspberry Pi零2W上阻止帶有Pi孔的廣告
使用Raspberry Pi來托管服務應用程序以及運行客戶端程序





 工商網監
工商網監
評論