 內存內計算的原理以及其市場前景分析
內存內計算的原理以及其市場前景分析
最近,內存內計算成了熱門關鍵詞。今年早些時候,IBM發布了基于相變內存(PCM)的內存內計算,在此之后基于Flash內存內計算的初創公司Mythic獲得了來自軟銀領投的高達4000萬美元的B輪融資,而在中國,初創公司知存科技也在做內存內計算的嘗試。本文將對內存內計算的原理以及其市場前景做一些分析。
馮諾伊曼架構之痛
馮諾伊曼架構是計算機的經典架構,同時也是目前計算機以及處理器芯片的主流架構。在馮諾伊曼架構中,計算/處理單元與內存是兩個完全分離的單元:計算/處理單元根據指令從內存中讀取數據,在計算/處理單元中完成計算/處理,并存回內存。
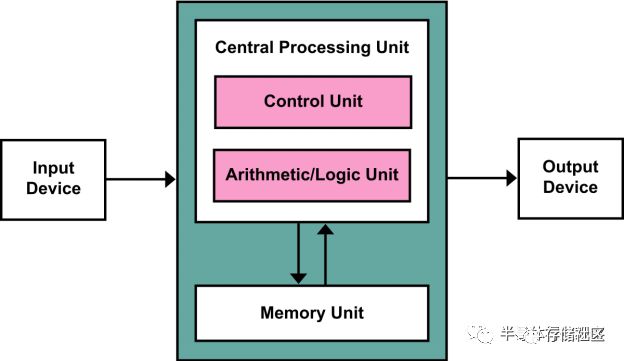
馮諾伊曼架構是經典的計算機體系架構,也構成了過去近一個世紀的計算機科學的基礎。然而,馮諾伊曼架構在構建之初只是一個理論模型,在建立該模型時做了一個合理的假設就是處理器和內存的速度很接近。當然,馮諾伊曼在當時沒有辦法預測到未來集成電路發展對于計算機造成的深遠變化。計算機處理器的性能隨著摩爾定律高速發展,其性能隨著晶體管特征尺寸的縮小而直接提升,因此在過去數十年中其性能提升可謂是天翻地覆,現在一顆手機中處理器的性能已經比30年前超級計算機中的處理器還要強。
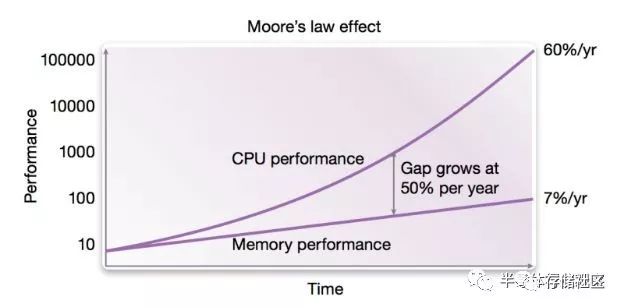
另一方面,計算機的主要內存使用的是DRAM方案,DRAM是基于電容充放電實現的高密度存儲方案,其性能(速度)取決于兩方面,即內存中電容充放電的讀取/寫入速度以及DRAM與處理器之間的接口帶寬。DRAM電容充放電的讀取/寫入速度隨著摩爾定律有一定提升,但是速度并不如處理器這么快,另一方面DRAM與處理器之間的接口屬于混合信號電路,其帶寬提升速度主要是受到PCB板上走線的信號完整性所限制,因此從摩爾定律晶體管尺寸縮小所獲得的益處并不大。這也造成了DRAM的性能提升速度遠遠慢于處理器速度,目前DRAM的性能已經成為了整體計算機性能的一個重要瓶頸,即所謂阻礙性能提升的“內存墻”。
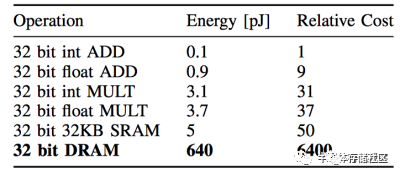
除了性能之外,內存對于能效比的限制也成了傳統馮諾伊曼體系計算機的一個瓶頸。這個瓶頸在人工智能應用快速普及的今天尤其顯著。這一代人工智能基于的是神經網絡模型,而神經網絡模型的一個重要特點就是計算量大,而且計算過程中涉及到的數據量也很大,使用傳統馮諾伊曼架構會需要頻繁讀寫內存。目前的DRAM一次讀寫32bit數據消耗的能量比起32bit數據計算消耗的能量要大兩到三個數量級,因此成為了總體計算設備中的能效比瓶頸。如果想讓人工智能應用也走入對于能效比有嚴格要求的移動端和嵌入式設備以實現“人工智能無處不在”,那么內存訪問瓶頸就是一個不得不解決的問題。
內存內計算的原理
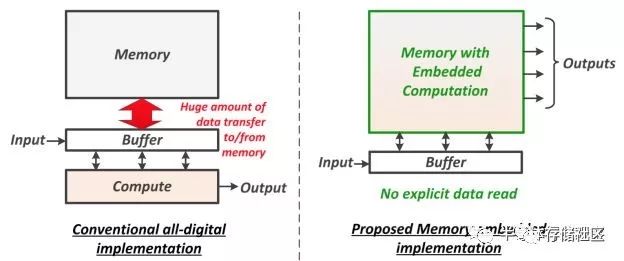
為了解決“內存墻”問題,一個最近得到越來越多關注的思路就是做內存內計算。2018年的國際固態半導體會議(ISSCC,全球最頂尖的芯片設計會議,發表最領先的芯片設計成果,稱為“芯片界的奧林匹克”)有專門一個議程,其中的論文全部討論內存內計算;到了2019年,根據最新發布的ISSCC 2019預覽,也有5篇關于內存內計算的論文,不過分散在不同的議程中。內存計算的主要改進就是把計算嵌入到內存里面去,這樣內存就不僅僅是一個存儲器,還是一個計算器。這樣一來,在存儲/讀取數據的時候就同時完成了運算,因此大大減少了計算過程中的數據存取的耗費。
內存內計算現在還處于探索階段,有很多種具體實現方式。舉一個ISSCC 2018年論文中的例子。這個內存內計算的電路由MIT的研究組提出,主要用途是加速卷積計算。我們知道,卷積計算可以展開成帶權重的累加計算,從另一個角度來看其實就是多個數的加權平均。因此,該電路實現的就是電荷域的加權平均,其中權重(1-bit)儲存在SRAM中,輸入數據(7-bit數字信號)經過DAC成為模擬信號,而根據SRAM中的對應權重,DAC的輸出在模擬域被乘以1或者-1,然后在模擬域做平均,最后由ADC讀出成為數字信號。具體來說,由于乘法的權重是1-bit(1或-1),因此可以簡單地用一個開關加差分線來控制,如果是權重是1就讓差分線一邊的電容充電到DAC輸出值,反之則讓差分線另一邊充到這個值。平均也很簡單,幾條差分線簡單地連到一起就是在電荷域做了平均了。
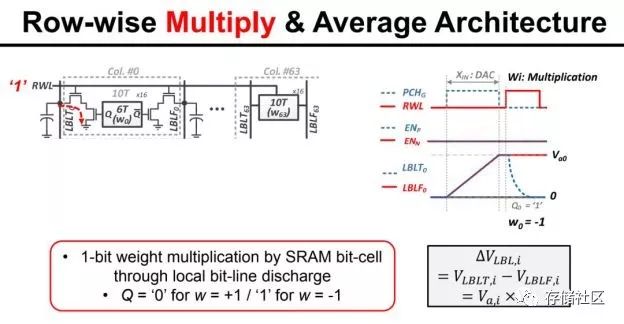
當然,內存內計算的電路并不止于一種,其計算的精度也并不限于1-bit計算。但是,從以上的例子我們可以看出內存內計算的核心思想,一般是把計算都轉化為帶權重加和計算,把權重存在內存單元中,然后在內存的核心電路(如讀出電路)上做修改,從而讓讀出的過程就是輸入數據和權重在模擬域做點乘的過程,相當于實現了輸入的帶權重累加,即卷積。因為卷積是人工智能以及其他計算的核心組成部分,因此內存內計算可以被廣泛使用在這類應用中。內存內計算會使用模擬電路做計算,這也是它和傳統使用數字邏輯做計算的不同之處。
內存內計算的兩大推動力以及市場前景
人們十幾年之前就認識到了“內存墻”的問題,但是為什么內存內計算在這兩年才火起來呢?我們認為,最近內存內計算興起的背后有兩大動力。
第一個動力是基于神經網絡的人工智能的興起,尤其是人工智能希望能普及到移動端和嵌入式設備中,這樣能效比很高的內存內計算就獲得了關注。另外,神經網絡的一個特點是對于計算精度的誤差擁有較高的容忍度,因此內存內計算的模擬計算中引入的誤差往往可以被神經網絡所接受,也可以說內存內計算和人工智能(尤其是嵌入式人工智能)可謂是天作之合。
第二個動力是新的存儲器。對于內存內計算來說,存儲器的特性往往決定了內存內計算的效率,因此當帶有新特性的存儲器出現時,往往會帶動內存內計算的發展。舉例來說,最近很火的ReRAM使用電阻調制來實現數據存儲,因此每一位的讀出使用的是電流信號而非傳統的電荷信號。這樣一來,由于電流做累加運算是非常自然而然的操作(把幾路電流直接組合在一起就實現了電流的加和,甚至無需額外電路),因此ReRAM非常適合內存內計算,也確實有不少研究組已經在做相關的研究并發表了論文。從存儲器推廣的角度,新的存儲器也愿意搭上人工智能的風潮,因此新存儲器廠商也樂于看到有人做基于自家存儲器的內存內計算加速人工智能,也會幫助一起推廣內存內計算。
因為內存內計算的兩大推力是人工智能和新存儲器,因此我們看到的新存儲器產品在人工智能和新存儲器這兩個關鍵詞上至少會有一個,也有不少內存內計算項目會同時橫跨兩個關鍵詞。
內存內計算的芯片產品預計會有兩種形式。第一種形式是作為一種帶有計算功能的存儲器IP出售。這樣的帶內存內計算功能的存儲器IP可能是傳統的SRAM,也可能是eFlash,ReRAM,MRAM,PCM這樣的新存儲器。這樣的存儲器IP往往是一家做內存內計算的公司和一家做存儲器的公司(如TSMC或SMIC)聯合做推廣。
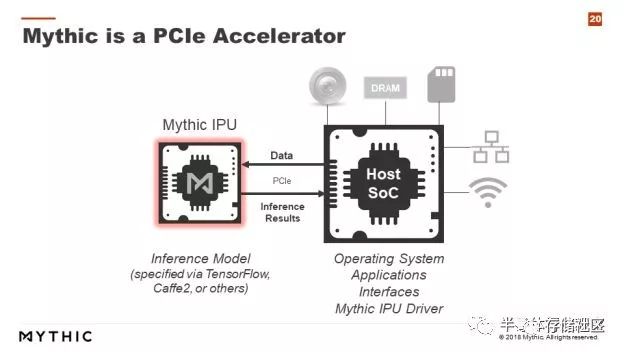
第二種形式是直接做基于內存內計算的人工智能加速芯片。例如Mythic就計劃流片做基于Flash存儲器的PCIe加速卡,通過PCIe接口和主CPU做通信,Mythic的內存芯片上存儲了權重數據,這樣當數據送到Mythic的IPU上后就可以直接讀出計算結果。這樣一來就省去了權重數據的讀取開銷。
那么內存內計算對于人工智能芯片市場會有什么影響呢?首先,我們看到內存內計算本質上會使用模擬計算,因此其計算精度會受到模擬計算低信噪比的影響,通常精度上限在8bit左右,而且只能做定點數計算,難以做浮點數計算。所以,需要高計算精度的人工智能訓練市場并不適合內存內計算,換句話說內存內計算的主戰場是在人工智能推理市場。即使在人工智能推理市場,由于精度的限制,內存內計算對于精度要求較高的邊緣服務器計算等市場也并不適合,而更適合嵌入式人工智能等對于能效比有高要求而對于精確度有一定容忍的市場。此外,內存內計算其實最適合本來就需要大存儲器的場合。舉例來說,Flash在IoT等場景中本來就一定需要,那么如果能讓這塊Flash加上內存內計算的特性就相當合適,而在那些本來存儲器并不是非常重要的場合,為了引入內存內計算而加上一塊大內存就未必合適。基于這樣的分析,我們認為內存內計算有望成為未來嵌入式人工智能(如智能IoT)的重要組成部分。
結語
隨著人工智能和新存儲器的興起,內存內計算也成為了新的熱點。內存內計算利用存儲器的獨特特性,結合模擬計算直接在存儲器中完成計算,從而大大減少人工智能計算中的內存讀寫操作。由于內存內計算的精度受到模擬計算的限制,因此它最適合追求能效比且能接受一定精確度損失的嵌入式人工智能應用。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
內存
+關注
關注
8文章
3025瀏覽量
74056 -
人工智能
+關注
關注
1791文章
47279瀏覽量
238511
原文標題:內存內計算,下一代計算的新范式?
文章出處:【微信號:TopStorage,微信公眾號:存儲加速器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論