 目標檢測在算力限制場景下的特點
目標檢測在算力限制場景下的特點
今天的分享是面向極市開發者們,分享中會相對偏向于實戰,更像是一個如何調參的經驗方法論方面的分享。需要強調的是,因為不少內容缺少系統的數學和理論基礎,所以必須稱之為淺談,比如邊際效用遞減曲線、特征空間復雜程度等自提概念都還需要進一步提煉和完善,也希望能借此機會可以和大家展開深入討論。
算力限制場景主要是指在嵌入式設備,也就是算力相對比較弱的芯片上面做實時或者準實時的目標檢測。這個問題在學術和工業界一直都是備受關注,并且在深度學習越來越強調落地的大背景下,這個問題也正變得越來越突出。
問題
分享之前,先提出幾個問題,我們帶著這幾個問題來貫穿整個分享。第一組問題,在實踐中,當我們遇到一個具體的任務的時候,比如熱門的車輛檢測問題,它屬于剛體檢測(被檢測物體內部不會有形變的情況)。那么,一般需要多大的神經網絡計算量,可以滿足一般場景下檢出絕大多數目標,同時保證出現盡量少的誤報?當我們需要在嵌入式的低計算能力的硬件平臺上完成這個任務的時候,我們應該怎么去完成這個任務?第二組問題,如果現在我們面臨的新任務是手勢檢測,也就是柔體檢測(被檢測物體內部會發生形變的情況),剛體檢測任務中面臨的問題顯然是同樣存在的。那么,因為我們做過了剛體檢測問題,經驗直接借鑒過來,適用嗎?第三組觸及靈魂的問題來了,既然剛體柔體都搞過一遍了,那么能不能再隨便來一個新的任務,都可以套用一套相同的方法來完成?也就是大家最關心的放之四海而皆準的標準“煉丹”方法。更進一步,學術上非常熱門的AutoML 與網絡結構搜索Network Architecture Search,與這個所謂的同一套方法又有什么關系呢?
目標檢測在算力限制場景下的特點
我們先看一下目標檢測這個方法在算力限制場景下的基本特點。谷歌在2016年11月Speed/accuracy trade-offs for modern convolutional object detectors 論文中,有這樣一張coco 檢測問題時所能達到的mAP結果圖。圖上有當時最熱門的神經網絡骨干網和檢測方法,他們在不同的網絡大小下,有的方法能力強,有的方法耗時短。可以發現,所有方法都沒有超出作者在圖上沿左下右上的一條凸起的虛線,也就是說,在這里速度和精度是“魚和熊掌不可兼得”的。同樣,在谷歌2018年7月發表的MNasNet 論文中,對于MNasNet 和MobileNet-V2的對比,同樣也展示出來神似的一條曲線,不同的是橫軸從GPU時間換成了手機上的預測時間。
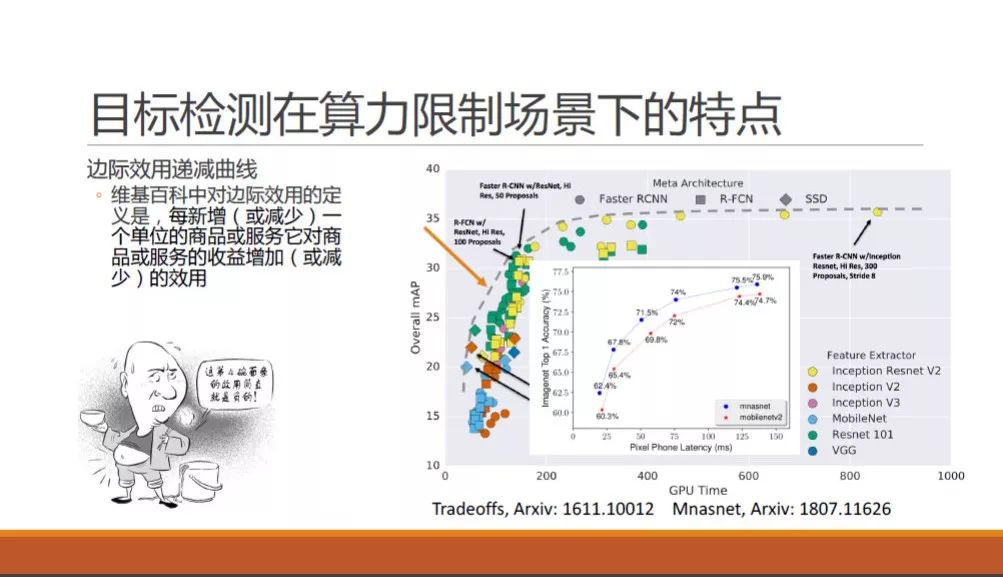
在這里,我們借用一個經濟學中非常常用的概念,就是邊際效用遞減曲線來描述這條論文中常出現的曲線。舉一個大家都熟悉的陳佩斯被朱時茂忽悠吃面的例子,當陳佩斯吃掉第一碗面的時候,他的幸福感可以從無到有提升到了七八成,吃完第二碗之后,可能幸福感就爆棚了,但是吃完第三碗和第四碗的時候,估計快要吐了,還談何幸福感。也就是說,每增加相同的一碗面,陳佩斯獲得的實際收益則越來越小,甚至變成負的了。
回到我們問題上面,算力就是陳佩斯的面,我們每給目標檢測方法多增加相同量的算力的時候,所能帶來的精度提升會越來越少,最后微乎其微,更有甚者,如果發生了過擬合,曲線還可能往下跌,也就是陳佩斯被撐吐了一樣。
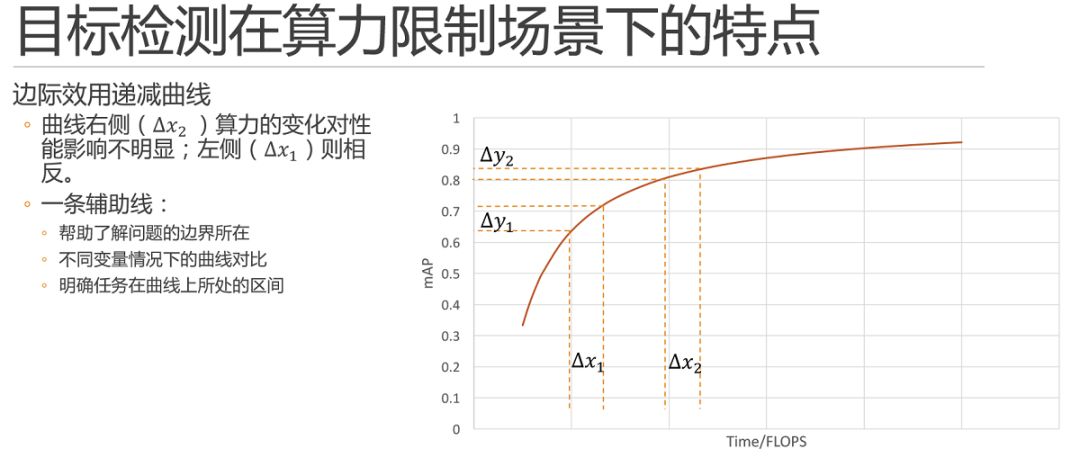
這里就可以隨手畫出一條曲線進行簡單的展示了。需要說明的是,實際的數據和曲線只會遵循大體的趨勢,一定不會嚴格擬合。同時,這條曲線既不是倒數,也不是多項式或是對數曲線,它究竟是什么數學公式,以當前深度學習的研究現狀來說并不可以推導和求解的。
簡單說,它只是一條輔助線,那它有什么用呢?首先,他可以幫助我們大體上去了解我們所探索的問題邊界所在。其次,當我們設計調參實驗的時候,可以通過繪制或者在腦子里假裝繪制不同變量條件下的曲線,這條輔助線可以幫助我們來對比變量優劣。例如,我們可以在某個變量固定時調整它的算力,當進行少量的實驗之后,就可以畫出這樣一條趨勢曲線出來了,同理,調整該變量的之后就可以再畫一條,兩條曲線的對比就可以幫助我們判斷該變量的優劣。最重要的,它可以幫助我們明確我們的任務在這個曲線上所處的區間。首先,不同的區間內解決問題的方法也不盡相同,不同變量在指定區間內的對比關系也不盡相同;同時,當你發現當前問題所處區間位于某個變量的曲線上升區,那么這個變量絕對是一個值得發力重點研究的變量。
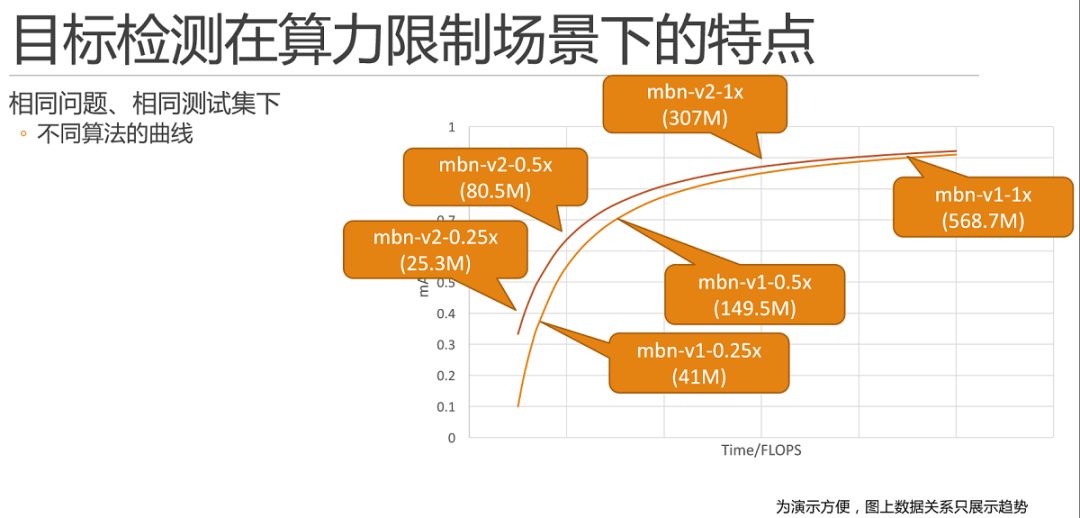
舉一個簡單的例子,如圖所示,mobilenet-v1和mobilenet-v2,根據論文或者自己的實驗,我們只需要將寥寥幾個點繪制上去就可以繪制兩條曲線。這里需要解釋一下,為了演示方便,圖上的數據關系只是展示了趨勢。
這里需要特殊說明的是,并不是所有方法對比圖都是理想的一上一下優者恒優的,例如,我們組18年發表的fast-downsampling mobilenet MobileNet 結構簡單微調的一點性能提升的方法(https://www.jianshu.com/p/681960b4173d),在100MFlops 以下的區間內,mAP 會高于mobilenet-v1,但是超過100MFlops 之后,就要弱于mobilenet-v1了。
因此,我們必須限定任務在曲線上所處的區間。
算力:硬件限制
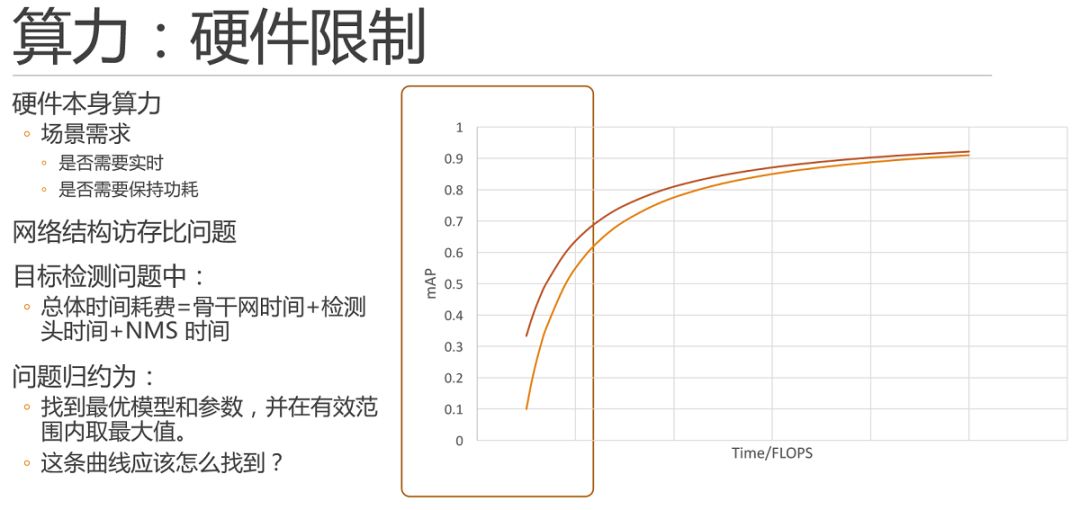
算力限制場景本身就是限定任務在曲線上所處的區間的一個最常見的因素。眾所周知,硬件本身主要就是芯片的算力是有當前芯片研發現狀,芯片的價格等等諸多因素決定的。并且,當場景需求不同時,相同的硬件條件下的情況也不盡相同。任務如果是實時的,就必須在30ms 左右計算完畢,當然如果不是實時的,慢一些就沒關系了。同時,在有些場景下還要求不能功耗滿載,那么我們就需要更快的時間算完,例如10ms 等等。
這里需要說明計算量Flops(浮點運算次數)或者是MAC(加乘數)與實際運行時間之間的關系:首先,由于網絡結構具有不同計算訪存比的特點,導致硬件算力和網絡flops之間無法形成線性對比關系。這里可參考:Momenta王晉瑋:讓深度學習更高效運行的兩個視角。比如,在輕量級網絡中很常見的depthwise 卷積中,單位取到的數據所支撐的計算量小于普通卷積,也就是計算訪存比小,因此對芯片的緩存訪存需求更大。
同時,在目標檢測問題中,除了骨干神經網絡花費的時間,檢測頭和nms 也花費了一些時間。例如nms 的數量是不固定的,這部分的時間開銷和計算量更加無法準確計算。
因此,如果在測試中直接使用時間對模型進行速度衡量,則必須到設備進行實測,這里還涉及到設備端的如ARM/NOEN、定點算浮點、量化等優化,是非常復雜的,所以一般情況下,我們都會使用Flops對計算能力進行估算。
因此,截止目前,我們可以將問題歸約為,通過曲線的輔助,找到最優模型和參數,并在有效范圍內取最大值。最關鍵的問題來了,這條曲線該怎么找到呢?這條曲線其實是沒法求的,我們會在后邊進行調參舉例來進行一定的說明,接下來我們再花些時間在我們的邊際效用遞減曲線上面。
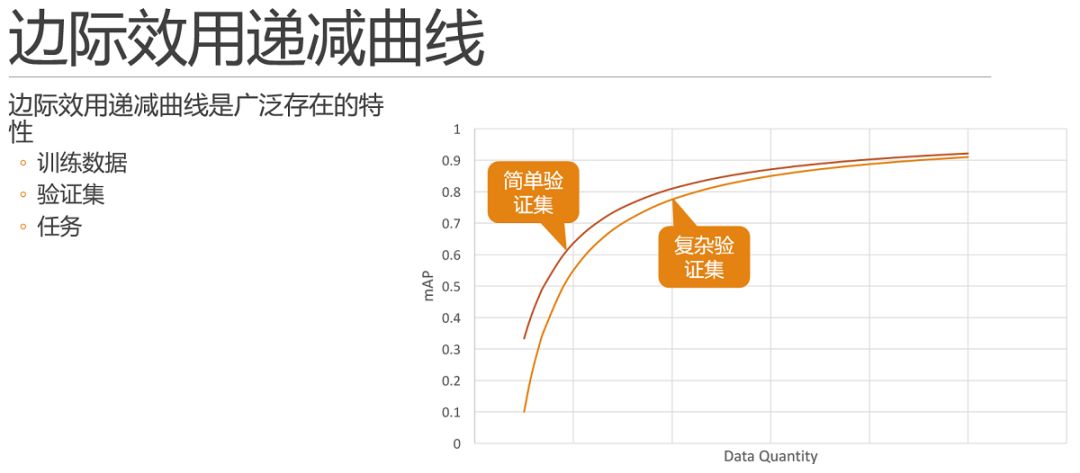
首先,該曲線是廣泛存在的。
除去算力,當橫軸是數據量的時候,往往情況下也是可以體現出來類似的邊際效用特點的,也就是說當我們在數據不足夠充分的時候,每次增加單位數量的同分布數據時,相同模型相同參數,所能提高的精度也是符合邊際效用遞減曲線的。
所以,如果在測試中,你發現增減數據對結果的影響非常大,那么極有可能你的問題當前處在數據量不夠的階段,需要想辦法增加數據。這也就是前面所說的這條曲線可以幫助我們明確問題所在的區間。此外,驗證集和評價標準也不是一成不變的,在其他因素不變的情況下,相同方法在簡單驗證集下,結果的數值上顯然是要優于復雜驗證集的。關于訓練集和驗證集的問題我們后邊會再展開講解,我們這里看一下不同任務的情況下,邊際效用遞減曲線之間的對比關系是怎樣的?
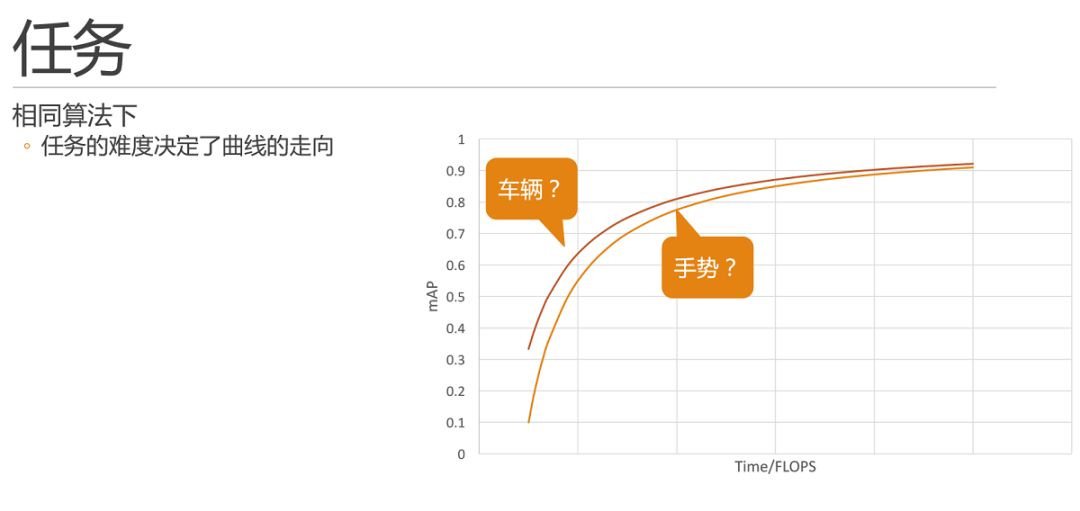
通過實踐,我們了解到,相同算法下,任務的難度決定了曲線的走向。那么,在前文提到的車輛和手勢兩個任務,我們能否把任務和曲線進行如圖的對比關系呢?
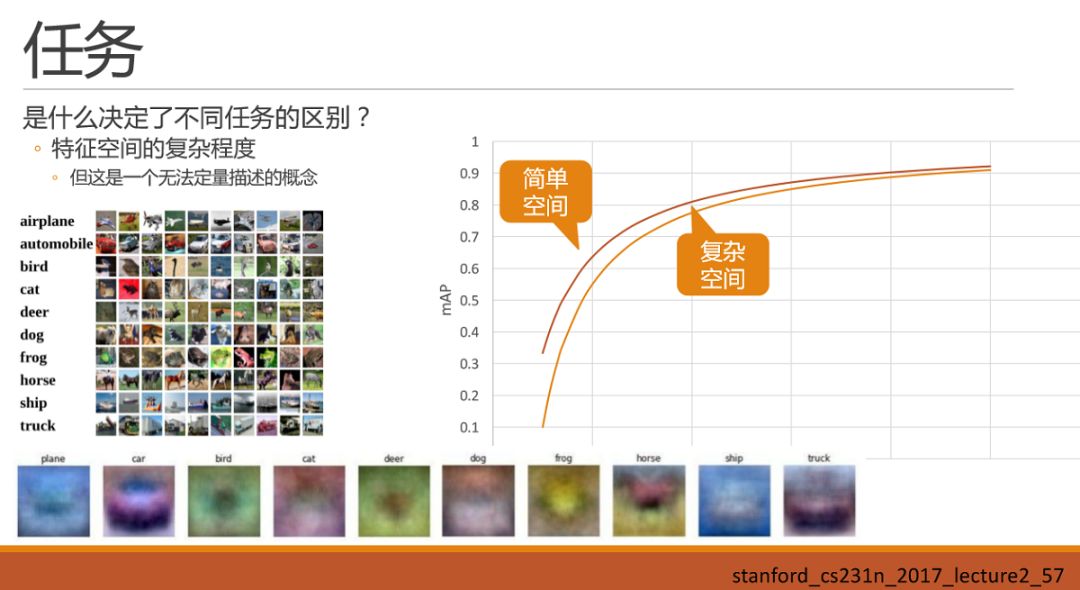
先把車輛和手勢放一邊,先看:是什么決定了不同任務的區別呢?直接拋出一個小的直觀的感覺:即特征空間的復雜程度,決定了任務的區別。暫時我還只能稱之為感覺,而不是結論,這里還真不敢下結論。雖然是感覺,但是建立這樣一種感覺,可能對我們后續調參會有一些幫助。
那么什么是特征空間的復雜程度呢?這暫時還是一個無法定量描述,甚至無法準確定義的概念。我們可以就看一下什么樣的空間復雜,什么樣的空間簡單:我們都知道深度學習最核心的能力就是對數據特征的描述以及泛化,那么我們再來看一下數據特征具體長什么樣子加深再這個理解。在Stanford cs231n課程中曾經提到cifar10 的數據集中,如果對每一類圖的采樣并進行平均化的話,可以得到如圖的平均圖,我們直觀的去觀察這個平均圖,會發現最容易辨認的是第二類car。那么車輛檢測就是簡單空間嗎?我們繼續看下一個例子。

這里是在100張城市數據集車輛尾部數據中采樣并得到一張平均圖。可以發現一整輛車的輪廓已經出來了。再繼續深入去定性分析的話,因為車輛首先是剛體數據,其次線條簡單清晰,不同車型的部件基本相同,如后窗、尾燈、牌照、車輪還有車輪下方的陰影區域。這里面圖是隨機挑選的,感覺白車有點多哈,可能是因為白車不容易臟,買的人本來就多吧?
這里需要注意的是任務需求,這個需求到底是檢出來車屁股即可,還是說必須分辨出來是顏色車型等具體信息,甚至需要車輛牌照信息。因為當任務需求發生變化時,神經網絡需要去描述的特征的量也會隨之發生變化。

再看一下貨車的。和轎車的大體相同。
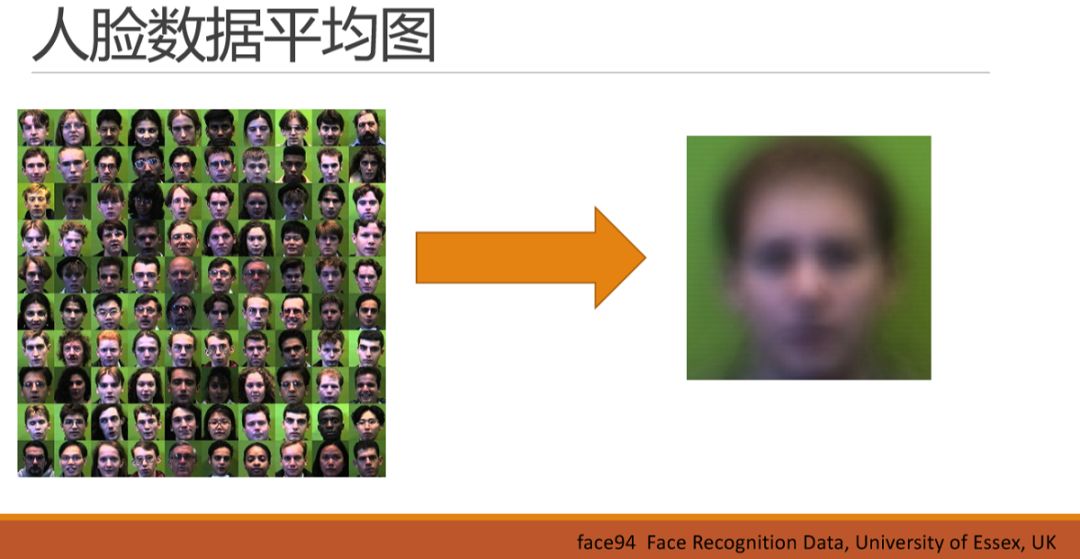
好,我們再看一下人臉數據集的平均圖,和車輛差不多,人臉的平均圖也差不多出來了一個人,有鼻有嘴,就是看不清。但因為數據中西方人男性居多,所以我們還能大概看出來是個西方男人的感覺。同理,如果任務需要區分人臉的情緒,也就是眼角、嘴型的細微變化,這個新的需求對神經網絡所需要描述的特征量的要求也就變得非常大了,也就不簡單了。
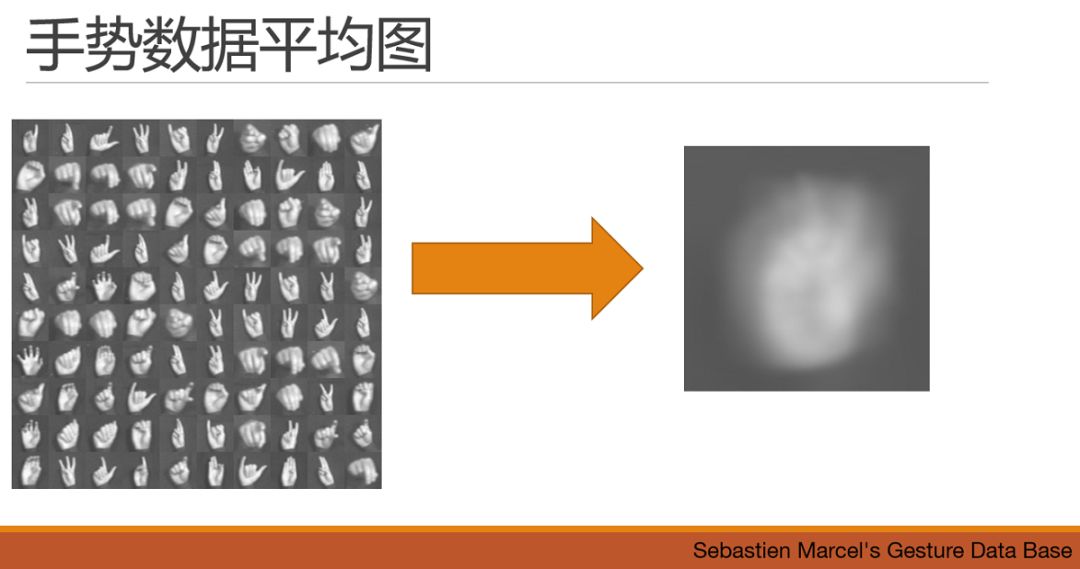
繼續看例子,手勢,貌似隱隱約約能看出來一個勝利V的手勢,但是,這個數據集顯然是需要能夠識別出這些手勢的基本含義。直觀看起來,需要的基礎特征的形狀也是很多的。
特征空間的復雜程度

現在又要祭出這張經典的特征可視化圖了,簡單的說,就是淺層特征基本就是直線和點,之后的每一層都是再對上一層特征進行概率意義上的組合。回到特征空間復雜程度的問題上面來,我們再舉一個極端的例子,mnist 手寫數據集中所需要的特征,直觀感覺上就是些直線折線和圈圈,而imagenet 是幾乎要應對整個自然圖像中所能涉及到的方方面面的情況,需要的特征和特征的組合關系幾乎是無法想象的。而在實踐中,大家都知道可以讓兩者跑的好的神經網絡,容量相差甚遠。好,我們直觀上現在知道了,對于一個特定問題,其實一定程度上可以說它所需要的特征量一般是確定的。當然我們沒法準確的得到具體的值,神經網絡要基本上能匹配上這個量,才能盡可能的做到精準。當你減少網絡參數時,勢必會削減網絡對某些情況的判斷能力,進而減少精度。這里不得不提一下二八定律,即在正常概率的世界中,我們一般可能需要20%的精力去處理80%的情況,反之需要80%的精力去處理剩下20%的疑難雜癥。通過經驗我們認為,神經網絡大概也是用80%的特征組合關系去處理了那20%的疑難雜癥情況,所以如果拋棄部分甚至全部疑難雜癥,可能20%的特征組合關系就夠用了。也是為什么邊際效用遞減曲線畫出來是一條向左上方凸出的曲線的原因吧。
實戰中的實驗設計

好了,虛的講完了。結果遺憾的是,前面所講的虛的東西,全部都是不能通過數學公式進行推導的。
這咋整?
秀了半天虛的,其實也沒什么特別高明的方法,就是試。但是怎么設計實驗,也就是說怎么試,每次試什么,試完之后改什么,還是很有文章可以做的。也就是這里所說的通過實驗設計逐步獲得最優值。這也是本次報告要分享的核心點。其實,最近研究界大熱的automl 或者是network architecture search 的方法,就是以替代掉人類的這部分調參過程為目標的。但是本次報告我還是寄希望于完全通過手工方法來還原調優過程,通過還原這個調優過程,給大家展示調優過程中的一些小的trick 和機理。這件事雖說未來有可能要失業,但是在automl和nas仍存在學術研究階段的情況下還是很重要的,也可能會幫助我們去認識和研究automl吧。

先再放個虛的框架,然后一一展開說一下。

先說數據集,數據集有可能是一個被忽略的因素。為什么這么說呢,因為我們對學術界論文的依賴度還是非常高的,而做論文的思路呢,一般都會使用公開數據集和通用評價標準,因為不使用這些你怎么跟同行進行比較呢?同理做比賽也有這樣的問題,雖然比賽已經比較貼近實際任務了,但是也必須有一個公平的評價標準,不然排名靠前靠后憑什么呢?
但是在做實際任務的時候,數據集就必須需要適應問題本身的需求,首先是驗證集。大家都知道,其實機器學習就好比訓練小學生去應付期末考試。驗證集就是期末考試,日常小朋友練習的題目不管怎樣也得和期末考試差不多,不然一定懵逼。驗證集做簡單了,數據分布上可能沒有覆蓋到實際情況中的大部分情況,也有可能做難了,對于一些不會出現的情況上花費了太多精力。還有一種情況就是驗證集和訓練集的重復關系,小心驗證集達標的時候其實有可能只是過擬合了訓練集。所以這時候沒人給做驗證集,只能靠自己。訓練集數據,根據前文所講的數據與mAP的邊際效用關系,這里肯定是能盡量搞定足夠多的數據才是王道。數據量不夠的情況下可能還需要使用一些遷移學習的方法來彌補,這里因為時間關系就不展開了。本文的最后還會對imagenet 等數據集對輕量級模型下的遷移學習進行一些補充。評價標準的重要性在這里也就顯現出來了,一般情況下我們會用通用的目標檢測評價標準(mAP)來描述我們的目標檢測方法。必須承認,mAP 確實是綜合的描述了一個模型的基本和平均能力,但是它不能同時兼顧漏檢率和誤撿率。由于mAP 是一個隨著confidence 下降來同時加入tp和fp繪制曲線并計算總面積的,因此fp 也就是誤撿的sample 并不會很明顯的體現出來,針對比較關注誤撿率的問題,最好還是不要用mAP。

好,我們開始跑了。一般的,我會花一些時間來建立baseline,這個下一頁詳解。然后開始迭代,核心思路是使用對照實驗(control experiment),只改變一個變量,固定其他所有變量。既然每次都只能調整一個參數與變量,那就最好沿著最有可能提高性能的方向調整,那么哪個是最大的變量呢?這需要熟悉神經網絡的原理和研究現狀,等下我們具體舉例來說明一下。這時我們前面講的輔助線可能就能用上了,幾次實驗之后,你心目中大概可以形成一個或者多個邊際效用遞減曲線了,就可以估算一下某個變量在上面所處的位置。嗯,上升趨勢比較明顯的變量值得著重考慮。所有維度都嘗試之后再重頭逐一嘗試,因為畢竟每次只調整一個參數沒有考慮到參數和參數之間的相互作用關系。
什么時候停止呢?調參小能手一般是沒有止境的,yeah。不過一般也就是驗證集達標,但是前面也提到了,手頭這個驗證集符合實際情況嗎?要去實際情況跑一跑你的模型了。
舉例

剛剛是原則性的套路,現在我們來舉一個例子。要求如圖所示,根據我們前面對任務特征空間的描述,這個問題應該有可能能在這個量級下完成吧,我們來試試。

首先我需要一個baseline,雖然我現在要用的是10M 的網絡,10M 的論文可能不多,但是我這時還是會先去復現mobilenet-v1,mobilenet-v2,shufflenet-v1/v2,以及各種坊間反饋還比較優秀的所有輕量級網絡結構。為什么要先做這件事呢,除了作為參考系方便進行比較之外,最大的目的是可以最大限度的保證方法本身、你用的框架等等沒有問題,如果這時不搞清楚,未來長期在坑里待著,顯然完成不了任務了。同時這樣會很容易幫你發現論文中的細節部分,論文搞得多的同學都知道,論文不可以沒有創新性,所以很有可能一篇論文中號稱的自己最核心的算法點在實測中不是對性能提升最優的點,相反,可能論文中會有些很實用但是看起來不是很有創新性的東西,而你不真的去跑一下,是不知道的。另外,如果一篇論文已經是一兩年前的,這一兩年之中有些其他論文會提出一些有趣的小trick 和小參數或者小調整,這些東西有的時候也可以在復現經典論文和方法的時候一起揉進去,例如何凱明提出的fan-in,fan-out參數初始化方法,就可以應用到其前面就發表的論文或者項目中去。總之,這是一個磨刀不誤砍柴工的工作,也是一個積累基礎經驗的過程。
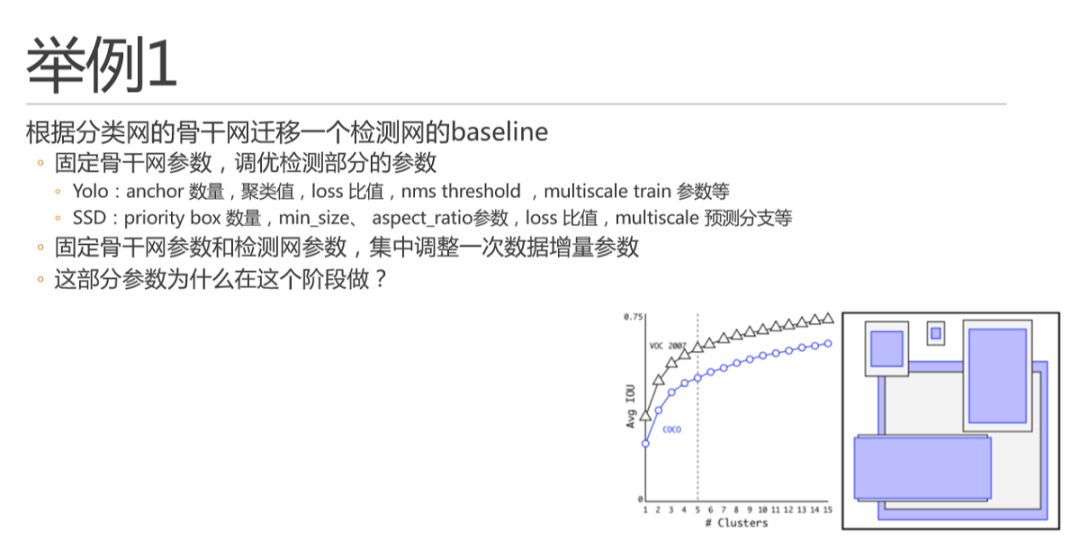
由于不少論文是分類網的論文,或者是不同檢測頭做的檢測模型,比如faster-rcnn 兩階段方法,我們需要換成自己使用的檢測頭,比如Yolo。這時我就需要再做一個baseline,并獲得自有訓練數據集下的檢測結果。首先,我會先固定骨干網參數,直接檢測部分的參數進行調優。例如Yolo 和SSD 中如圖所示的這些參數,簡單說原則還是迭代嘗試,每次只調整其中一個。這里多說一嘴,不管是yolo 還是ssd ,他們的anchor 或者priority box 機制,其數量也是符合邊際效用遞減曲線的,如yolo v2 論文中的這幅圖。大家看,這曲線無處不在是吧。所以當其數量適當增加的時候對精度提升是很有用的,但是在算力有限場景下也不能加太多,因為總的proposal 會太多,nms 也會變的很多。另外,這里anchor聚類出來的具體長寬,只要大體符合數據分布,就可以了,不用很精確,每次增加了同分布數據的時候也不用重復做聚類,因為回歸器會自動完成回歸過程的,不要離的太遠就好。這里不展開了。調整完檢測參數之后,還要再集中調整一次數據增量參數。數據增量也是非常重要的,其實同理,數據增量也是符合邊際效用遞減曲線的,做太多了也就沒啥用了,該增加數據還是增加數據吧。這里里其實是可以提出這樣一個問題的,就是這部分參數為什么在這個階段做?為什么不在先裁剪出來一個10M 的骨干網再加檢測頭。這里我個人更加傾向于在后續調優過程中的測試過程更加end2end,因為你的目的就是目標檢測嘛。同時,需要注意的是這時的參數并不是最優參數,只是一個起始baseline,未來骨干網確定之后還會再來迭代。

現在我們要開始裁剪網絡結構了,雖然這部分最前沿的研究工作表示完全可以有NAS來完成。比如Google 2017年的NasNet 和2018年的MNasNet,不過我倒是覺得一般情況下一般人可能也部署不起能快速進行網絡結構搜索的分布式搜索框架。右圖即為NasNet 搜索出來的網絡結構,確實看起來也不像是設計出來的。我們還是在baseline 的基礎上逐步手工調整吧,可能確實相比搜索達不到最優,但是因為有跡可循,有經驗的時候還是有可能會比nas 上使用強化學習學出來的過程快一點。不過這塊不敢說大話,說不好未來有可能就不行了。
根據mobilenet-v1 論文,有幾個方向可以調整:寬度、深度、分辨率。先說寬度,這塊有兩篇比較相關的論文,主要是ADC和AMC,是同一個組做的。這兩篇論文可以做到逐層選擇最優的層寬度,效果還不錯。這里我們還是跟mobilenet-v1一樣進行等比例的寬度壓縮,不過有的時候也可能會進行一些相應層的區別性調整。深度,就是加減層。這里的問題是,既然是壓縮為什么還要加層,因為可能寬度下來了,計算量已經大幅下來了,增加深度還可以在計算量和運行時間上達標。深度這里還有一個很重要的就是選擇幾個stage 的問題,一般的分類網都是32x downsampling ,5個stage,曠視在2018年提出DetNet 中使用了16x downsampling ,4個標準stage。這樣的好處是,224x224 輸入下檢測頭的featuremap 是14x14 的,可以兼顧細節和語義,同時速度也不慢。對于語義信息和細節信息保持更好的檢測方法,FPN 是個不錯的選擇,但是FPN 在算力限制的條件下略顯笨重,實時運行壓力有點大。對于分辨率,我們則大膽的假設這是一個可以暫時忽略的維度,原因是高分辨率可能帶來的只是小目標和邊框精度的提升。一般的,可以在一個可行的分辨率下面專注于其他超參數的調整。這里還會涉及一些其他微調,例如使用其他形狀或者大小的卷積核,提升感受野等。例如有孔卷積和5x5 卷積。不過有孔卷積在移動設備的性能一般般。
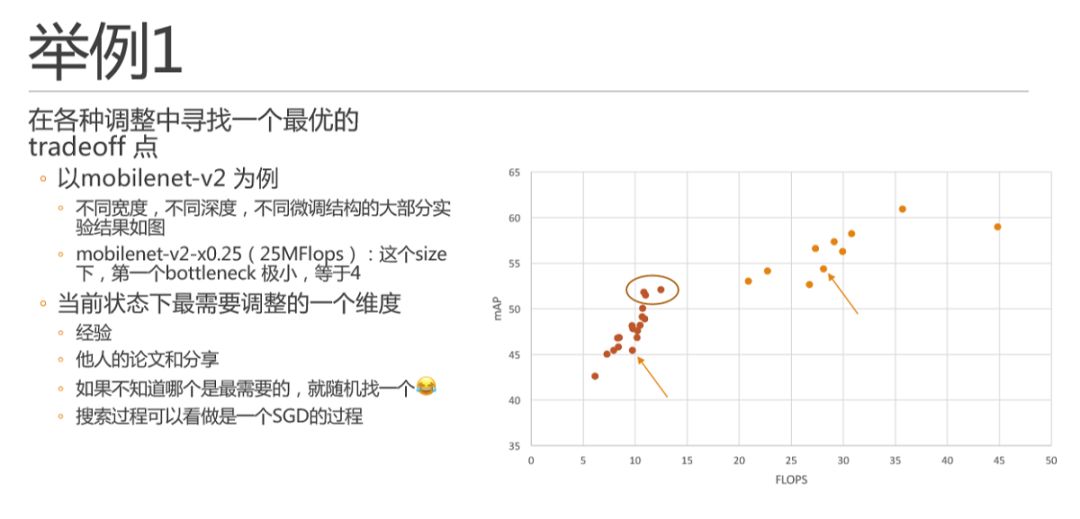
接下來就是在各種調整中找一個最優的tradeoff 點了,如圖是我在mobilenet-v2 這個網絡結構上嘗試的結果,嘗試了一些不同寬度、深度和微調結構等調整。左半側的點基本是3/8這個寬度的,右半側的點是3/4這個寬度的。箭頭指向的是簡單按stage裁剪完深度之后的baseline。舉個小例子,這里針對mobilenet-v2 有一個小的點是我著重去調整的,就是1/4 這個尺寸下,第一個bottleneck極小只有4,是否這個值太小會導致對特征的描述太弱,而調大它對網絡整體計算量影響并不大,則可以嘗試。這里總結一下,簡單說就是在當前狀態找一個最需要調整的維度,有哪些維度就靠經驗和他山之石了。另外,一般情況下,如果某個變量會明顯提高,那么就著重優化一下它唄,也就是前文所說的在邊際效用遞減曲線上上升趨勢比較明顯的變量值得著重考慮。而哪一個是最需要調整的呢,如果靠經驗都想不出的時候,那就隨便挑一個,因為真的可能有奇效哦。其實我的感覺是,這個人肉搜索過程其實完全可以看做是一個隨機梯度下降的過程,每次自己都是用自己的評價函數找到了一個最佳維度然后往最優迭代。并且有的時候嘗試的調整可以超出預期的值一定范圍,例如裁窄網絡之后加深的時候可以超量多加一些層,看看趨勢。這個就可以好比是使用大的學習率或者時模擬退火算法了。而人肉調整的好處是,我不需要每次都按相同的學習率調整,有的時候可以走一大步,節省不少迭代次數。

好,好不容易找幾個模型,但是事情還沒完,現在需要翻回頭去在現在的結構上,再次調整之前的參數了。而在這些參數確定之后,還要再次回頭把挑出來的網絡結構再驗證一次。因為這里存在多變量聯合作用影響結果的情況,以及評價標準缺陷或者訓練過程隨機因素導致的偶然因素。不過這里的工作量相比之前已經不大了,因為前面已經排除掉了一些明顯不行的選項嘛。最后還要通過任務本身的實際測試去根據實測問題調整驗證集。如果有問題還要再回去前面某個點上再調一遍。

剛剛的例子暫時告一段落吧,現在拋出第二個問題,畢竟預告里面提了要說一說,其實答案相比大家心中已經有了答案。
根據之前的背景,這兩個問題中數據特征空間差異是巨大的,所以,其實兩個問題不可能直接進行遷移學習,但是,這里方法論是適用的,這里偷個懶,就不再展開介紹如何重新適配了一遍了,相信有了第一個任務的經驗,這個任務做起來并不難,迭代次數也會大幅下降。而通過講解,相信開篇的問題也可以得到一定的解答。
總結
首先,基礎知識很重要,需要掌握大量的基礎性調參經驗,這里強烈推薦大家去查閱學習曠視大神魏秀參的博客。其次,需要嚴格做到對比實驗方法,幫助自己準確獲得這一次調整帶來的性能提升,并就此思考這次調整所帶來改變的原因。因為一旦有多維參數發生變化,就很難確定到底是哪一維的問題,不能準確的確定原因。另外,這里雖然排除了多維參數交叉作用的成分,但是可以通過螺旋迭代方法進行彌補。特別需要提醒大家的是,精細的實驗設計會導致嘗試路徑和次數很長,非常需要耐心。這時是很有必要先大膽降維,避免多個因素不知從何下手;而遇到瓶頸時則可以大膽猜測并假設問題,小心設計實驗進行驗證,很大概率會有驚喜。最后,輔助性的工作/工具至關重要,是保證快速迭代的基礎。所以選擇一個方便上手的框架至關重要,維護框架的細節也非常重要。這里值得建議的是,能用多卡加速就用多卡加速,然后有必要關注一下硬盤讀寫瓶頸,建議換SSD固態硬盤。不過有一點值得慶幸,小模型的單模型訓練速度很快,多因素嘗試的時候,迭代速度還可以接受。最后,一個良好的筆記軟件以及使用習慣可以幫你梳理嘗試過程中的邏輯和細節。不然,間隔幾個小時的訓練工作完成之后,只怕你已經忘記上次調整的是什么了。
問題回答
后邊回答環節問題較多,回答的時間比較倉促,這邊挑三個出來簡單再說一下。
第一是關于超參數方面的,也就是學習率batch size,iteration等等超參數的配置。這里也是需要嚴格的對比實驗設計來嘗試的。同時,超參數是一般情況下變化不大,總的嘗試次數(batchsize * iteration)基本是隨著數據集總量來的。所以一般確定了的超參數,在數據量變化不大的時候可以保持不動。第二是關于檢出率和召回率如何兼顧?這個問題現場時候我理解錯了,講的更多的是如何挑選一個好的評價標準。事實上,如果回到本文所最長提到的邊際效用遞減曲線來說,兼顧檢出率和召回率,就是找到一個最靠上的模型和超參數。具體找到這個模型,就是文中所講的方法論來做了。第三是輕量級模型下,用imagenet預訓練有沒有意義?回到特征空間的背景,因為輕量級模型的網絡結構容量本身較小,所能容納的特征量不大。但是imagenet的數據集特征空間非常大,遠超了輕量級模型的能力。會導致預訓練模型中對特征的描述和目標問題領域相距過大,預訓練學出來的特征后邊都會被新問題訓練過程中覆蓋掉。所以,數據不夠時合理的解決方法是,可以使用特征相比比較相似的數據集進行預訓練,例如車輛檢測問題中,數據量不夠,可以使用kitti、bdd100k等數據集進行一定的遷移工作。
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100974 -
嵌入式設備
+關注
關注
0文章
110瀏覽量
16991 -
深度學習
+關注
關注
73文章
5511瀏覽量
121356
原文標題:算力限制場景下的目標檢測實戰淺談
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
“算力”的分層定義-初級算力
RISC-V與ARM在相同頻率下的算力相同嗎?

rx580算力,rx580顯卡算力,rx588算力,rx588顯卡算力 精選資料分享
MXM 算力平臺在邊緣計算領域的應用
在復雜場景中多目標物的檢測識別方法
海雜波背景下艦船目標檢測

曙光攜手“算力互聯公共服務平臺”提高全國算力匹配效率
智算中心會取代通用算力中心嗎?

算智算中心的算力如何衡量?





 工商網監
工商網監
評論