") 中山大學(xué)HCP實(shí)驗(yàn)室PAMI論文:低成本、可擴(kuò)展的三維人體位姿預(yù)測(cè)應(yīng)用
中山大學(xué)HCP實(shí)驗(yàn)室PAMI論文:低成本、可擴(kuò)展的三維人體位姿預(yù)測(cè)應(yīng)用
論文提出的3D人體位姿預(yù)測(cè)框架:先使用一個(gè)輕量級(jí)CNN提取2D人體位姿特征和粗略估計(jì)3D人體位姿,然后用RNN學(xué)習(xí)時(shí)序相關(guān)性以得到流暢的三維人體位姿初步預(yù)測(cè)結(jié)果,最后使用自監(jiān)督學(xué)習(xí)引導(dǎo)機(jī)制,根據(jù)三維幾何一致性,優(yōu)化從2D到3D的預(yù)測(cè)結(jié)果。項(xiàng)目主頁:http://www.sysu-hcp.net/3d_pose_ssl/
中山大學(xué)使用自監(jiān)督學(xué)習(xí)精準(zhǔn)預(yù)測(cè)三維人體位姿。新方法減少了對(duì)3D標(biāo)記數(shù)據(jù)的依賴,還能通過使用現(xiàn)有的大量2D標(biāo)記數(shù)據(jù)提高最終預(yù)測(cè)結(jié)果,實(shí)現(xiàn)低成本、可擴(kuò)展的3D人體位姿估計(jì)實(shí)際應(yīng)用。
3D人體位姿估計(jì)是當(dāng)前的一個(gè)熱點(diǎn)研究課題,也具有廣泛的應(yīng)用潛力。
深度神經(jīng)網(wǎng)絡(luò)已經(jīng)在2D人體位姿估計(jì)上取得了優(yōu)異的結(jié)果,如果想使用深度學(xué)習(xí),在3D人體位姿估計(jì)中也取得同樣的效果,那么首先就需要大量的3D人體位姿標(biāo)記數(shù)據(jù)。
但問題是,現(xiàn)在沒有大量帶精準(zhǔn)標(biāo)記的3D人體位姿數(shù)據(jù)。
在一篇最新發(fā)表于《IEEE模式分析與機(jī)器智能會(huì)刊》(PAMI) 的論文[1]中,中山大學(xué)的研究人員提出了一種新的方法,讓計(jì)算機(jī)通過自監(jiān)督學(xué)習(xí)的方式,精準(zhǔn)預(yù)測(cè)視頻片段中的三維人體位姿,大幅減少對(duì)3D標(biāo)記數(shù)據(jù)的依賴。
“我們通過有效結(jié)合二維時(shí)空關(guān)系和三維幾何知識(shí),提出了一個(gè)由自監(jiān)督學(xué)習(xí)引導(dǎo)的快速精準(zhǔn)三維人體位姿估計(jì)方法。”論文一作、目前在加州大學(xué)洛杉磯分校 (UCLA) 朱松純教授實(shí)驗(yàn)室擔(dān)任博士后研究員的王可澤博士告訴新智元。在完成這篇論文時(shí),王可澤還是中山大學(xué)和香港理工大學(xué)的博士生,導(dǎo)師是中山大學(xué)HCP人機(jī)物智能融合實(shí)驗(yàn)室的林倞教授 (林教授也參與了這項(xiàng)工作) 和香港理工大學(xué)的張磊博士。
新方法在Human3.6M基準(zhǔn)測(cè)試中的一些可視化結(jié)果。(a)為2D-to-2D位姿變換模塊估計(jì)的中間3D人體位姿,(b)為3D-to-2D位姿映射模塊細(xì)化的最終3D人體位姿,(c)為ground-truth。估計(jì)的3D位姿被重新映射到圖像中,并在側(cè)面 (圖像旁邊) 顯示出來。如圖所示,與(a)相比,(b)中預(yù)測(cè)的3D位姿得到了顯著的修正。紅色和綠色分別表示人體左側(cè)和右側(cè)。來源:論文《自監(jiān)督學(xué)習(xí)引導(dǎo)的人體三維位姿估計(jì)》[1]
“該方法采用輕量級(jí)的神經(jīng)網(wǎng)絡(luò),有效減少了計(jì)算量,并克服了三維人體位姿標(biāo)注數(shù)據(jù)不夠豐富的難點(diǎn),能在實(shí)際應(yīng)用場(chǎng)景中流暢穩(wěn)定地進(jìn)行三維人體位姿預(yù)測(cè)。”
在單個(gè)的Nvidia GTX1080 GPU上運(yùn)行時(shí),新方法處理一幅圖像只需要51毫秒,而其他方法需要880毫秒。
使用自監(jiān)督學(xué)習(xí),減少對(duì)3D標(biāo)記數(shù)據(jù)的依賴
這篇論文題為《自監(jiān)督學(xué)習(xí)引導(dǎo)的人體三維位姿估計(jì)》(3D Human Pose Machines with Self-supervised Learning),作者是王可澤,林倞,江宸瀚,錢晨和魏朋旭。

研究人員向新智元介紹,他們這項(xiàng)工作的背景,是現(xiàn)有的基于彩色圖像視頻數(shù)據(jù)的三維人體位姿估計(jì)研究,在實(shí)際場(chǎng)景應(yīng)用中有兩大明顯的不足:
一是所需要的計(jì)算量大:當(dāng)前,絕大多數(shù)的現(xiàn)有三維人體位姿估計(jì)方法,都依賴最先進(jìn)的二維人體位姿估計(jì)來獲得精準(zhǔn)的二維人體位姿,然后再構(gòu)建神經(jīng)網(wǎng)絡(luò),實(shí)現(xiàn)從2D到3D人體位姿的映射。由于采用的二維人體位姿估計(jì)方法往往需要龐大的計(jì)算量,再加上所構(gòu)建的神經(jīng)網(wǎng)絡(luò)自身的運(yùn)算開銷,難以滿足三維人體位姿估計(jì)在實(shí)際應(yīng)用中的時(shí)間需求;
二是應(yīng)用效果不理想:當(dāng)前的三維人體位姿數(shù)據(jù)集都是在受控的實(shí)驗(yàn)環(huán)境下創(chuàng)建的 (攝像機(jī)視角固定、背景單一),所包含的三維標(biāo)注信息不夠豐富,不能全面反映真實(shí)生活場(chǎng)景,使得現(xiàn)有方法所預(yù)測(cè)出的三維人體位姿質(zhì)量參差不齊,魯棒性差。
為了解決上述的問題,研究人員進(jìn)行了深入的研究和分析,嘗試?yán)煤A康亩S人體位姿數(shù)據(jù)來彌補(bǔ)三維標(biāo)注信息不豐富的問題。
同時(shí),他們受二維和三維空間彼此存在的聯(lián)系啟發(fā),根據(jù)三維人體位姿的映射是二維人體位姿這一幾何特性,結(jié)合之前的自監(jiān)督學(xué)習(xí)工作(參考王可澤博士等人此前的論文[2]),制定了2D到3D變換和3D到2D映射的自監(jiān)督學(xué)習(xí)任務(wù)。
這一關(guān)鍵的2D和3D相互轉(zhuǎn)換自監(jiān)督學(xué)習(xí)模塊架構(gòu)示意如下:

3D到2D人體位姿映射模塊訓(xùn)練階段示意圖

3D到2D人體位姿映射模塊測(cè)試階段示意圖
在這項(xiàng)研究中,作者使用MPII數(shù)據(jù)集,從圖像中提取2D人體位姿。然后,使用另一個(gè)名為“Human3.6M”的數(shù)據(jù)集,提取3D的ground truth數(shù)據(jù)。Human3.6M數(shù)據(jù)集包含有360萬張?jiān)趯?shí)驗(yàn)室拍攝的照片,任務(wù)包括跑步、散步、吸煙、吃飯,等等。
初始化后,他們將預(yù)測(cè)的2D人體位姿和3D人體位姿替換為2D和3D的 ground-truth,從而以自監(jiān)督學(xué)習(xí)的方式優(yōu)化模型。
3D-to-2D人體位姿映射模塊的學(xué)習(xí)目標(biāo),就是將3D人體位姿的2D映射與預(yù)測(cè)的2D人體位姿兩者間的差異最小化,以實(shí)現(xiàn)對(duì)中間3D人體位姿預(yù)測(cè)的雙向校正 (或細(xì)化)。
“模型采用了序列訓(xùn)練的方法來捕獲人體多個(gè)部位之間的長(zhǎng)期時(shí)間一致性,并通過一種新的自監(jiān)督校正機(jī)制進(jìn)一步增強(qiáng)這種一致性,這包含兩個(gè)對(duì)偶學(xué)習(xí)任務(wù),即2D-to-3D位姿變換和3D-to-2D位姿映射,從而生成幾何一致的3D位姿預(yù)測(cè)。”
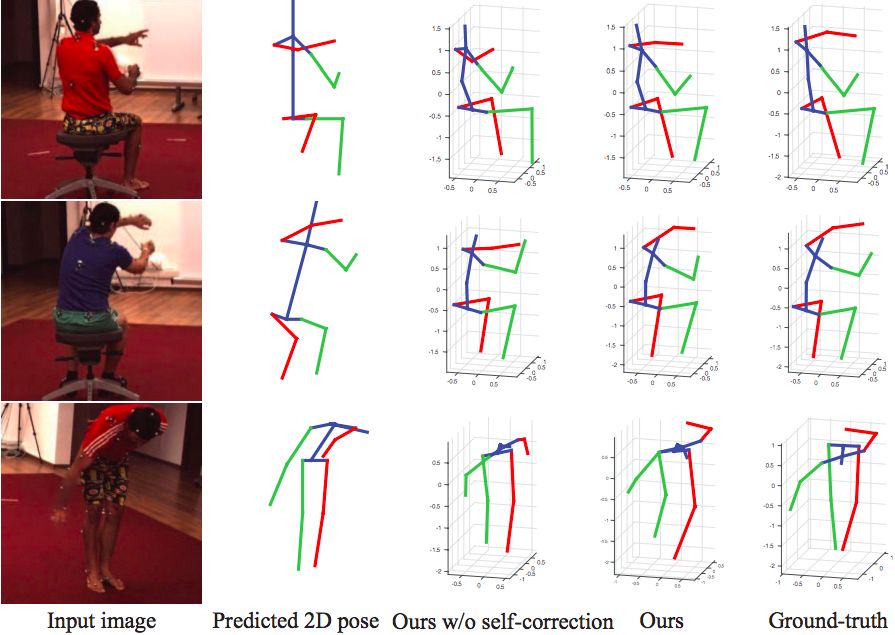
經(jīng)過自監(jiān)督校正以后的結(jié)果 (Ours) 比沒有經(jīng)過校正的 (Ours w/o self-correction) 更接近 Ground-truth。來源:論文
未來方向:非受限條件下三維人體位姿預(yù)測(cè)
研究人員在論文中指出,這項(xiàng)工作的主要貢獻(xiàn)有三方面:
提出了一種新的模型,可以學(xué)習(xí)整合豐富的時(shí)空長(zhǎng)程依賴性和3D幾何約束,而不是依賴于特定的手動(dòng)定義的身體平滑度或運(yùn)動(dòng)學(xué)約束;
開發(fā)了一種簡(jiǎn)單有效的自監(jiān)督校正機(jī)制,以結(jié)合3D位姿幾何結(jié)構(gòu)信息;這一創(chuàng)新機(jī)制也可能啟發(fā)其他3D視覺任務(wù);
提出了自監(jiān)督校正機(jī)制,使模型能夠使用足夠的2D人體位姿數(shù)據(jù),顯著提高3D人體位姿估計(jì)的性能。
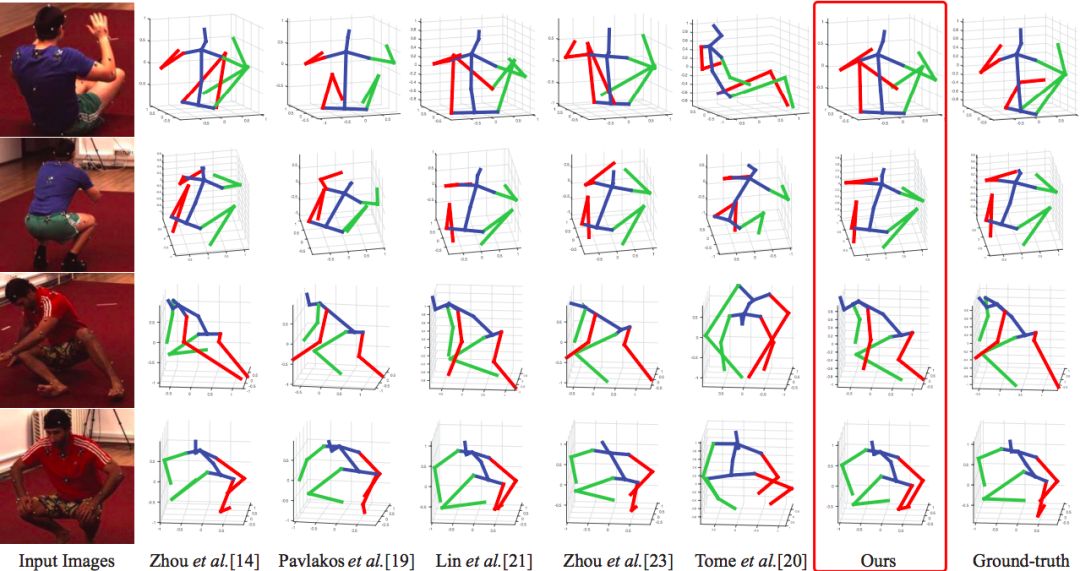
新方法 (Ours,紅框標(biāo)識(shí)) 顯著優(yōu)于其他同類方法,綠色代表右側(cè)手腳,紅色代表左側(cè) (下同):最右邊一列為Ground-truth;使用Human3.6M數(shù)據(jù)集。

新方法 (Ours) 與ICCV-17微軟危夷晨組在MPII數(shù)據(jù)集上的結(jié)果比較,后者使用弱監(jiān)督遷移學(xué)習(xí)將2D和3D標(biāo)記混合在一個(gè)統(tǒng)一的深度學(xué)習(xí)框架里,在2D和3D基準(zhǔn)上都取得了較好的結(jié)果。新方法在3D預(yù)測(cè)上更進(jìn)一步。
自監(jiān)督學(xué)習(xí)的價(jià)值顯然是人工智能研究的一個(gè)重點(diǎn)。
其他方法也采用了類似的“弱監(jiān)督”方法來預(yù)測(cè)位姿,甚至捕捉人體運(yùn)動(dòng)。例如,加州大學(xué)伯克利分校Sergey Levine教授的機(jī)器人實(shí)驗(yàn)室去年10月發(fā)表論文稱,他們能夠訓(xùn)練模擬機(jī)器人模仿人類活動(dòng),只使用YouTube視頻的無標(biāo)注數(shù)據(jù)。中山大學(xué)的這一工作未來或許能與伯克利的方法實(shí)現(xiàn)某種結(jié)合。
研究人員告訴新智元,接下來,“我們會(huì)針對(duì)于實(shí)際非受限場(chǎng)景中更加復(fù)雜多變的三維人體位姿預(yù)測(cè)問題,開展進(jìn)一步研究;另外,進(jìn)一步優(yōu)化我們的方法,希望能在移動(dòng)端實(shí)現(xiàn)實(shí)時(shí)精準(zhǔn)的預(yù)測(cè)效果”。
-
3D
+關(guān)注
關(guān)注
9文章
2885瀏覽量
107610 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4772瀏覽量
100845
原文標(biāo)題:中山大學(xué)新突破:自監(jiān)督學(xué)習(xí)實(shí)現(xiàn)精準(zhǔn)3D人體姿態(tài)估計(jì)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器視覺教學(xué)創(chuàng)新實(shí)驗(yàn)室設(shè)備維視圖像
[招聘]中山大學(xué)中山眼科中心招聘工程師
歐姆龍公司攜手中山大學(xué)建自動(dòng)化實(shí)驗(yàn)室
中山大學(xué)研發(fā)出首個(gè)基于人工智能的眼病篩查指導(dǎo)系統(tǒng)
中山大學(xué)應(yīng)用基于RFID技術(shù)的智能圖書館
中山大學(xué)提出新型行人重識(shí)別方法和史上最大最新評(píng)測(cè)基準(zhǔn)

中山大學(xué)研發(fā)一種基于介孔微針離子泳的集成可穿戴診療一體化系統(tǒng)
高校大學(xué)數(shù)字孿生教學(xué)實(shí)驗(yàn)室,虛擬仿真實(shí)訓(xùn)系統(tǒng)中心

三維天地智能大腦解決方案助力實(shí)驗(yàn)室智慧化管理
三維天地助力計(jì)量實(shí)驗(yàn)室全方位資源管理
浙江大學(xué)機(jī)械工程學(xué)院—思看科技三維掃描實(shí)踐教學(xué)實(shí)驗(yàn)室正式揭牌!

中山大學(xué)中山眼科中心與華為聯(lián)合發(fā)布ChatZOC眼科大模型
千呼萬喚始出來!中山大學(xué)-創(chuàng)龍教儀RK3568教學(xué)實(shí)驗(yàn)室項(xiàng)目正式落地!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論