 斯坦福攜手MIT發布巨大量級X光胸片數據集
斯坦福攜手MIT發布巨大量級X光胸片數據集
今天,吳恩達發推公布了斯坦福發布的兩個大型的醫療數據集公開:CheXpert和MIMIC-CXR。其中,CheXpert內含224316X光胸部圖片,MIMIC-CXR內含371,920張帶標簽的圖片。兩個數據集的數據量級和標注精準度都非常高,可以說是造福了一大批相關從業者了。
數據集下載方式
先給出數據集介紹的地址和下載方式。
https://stanfordmlgroup.github.io/competitions/chexpert/

因為是醫學數據集,斯坦福采取了相對謹慎的態度。根據說明,用戶需要遵守下載規則,填寫資料然后通過電子郵件給出的鏈接進行下載。為了保持數據集的完整性以及有效性,嚴禁進行“濫用”分享。
數據集概況
CheXpert數據集里面有224316張胸部X光圖片,共涉及65,240名患者。數據集的時間跨度為2002年10月到2017年7月,都是患者在斯坦福醫院進行胸部X光檢查之后的留存。除此之外,數據集還附有相關的放射學報告。
如何為CheXpert數據集打標簽
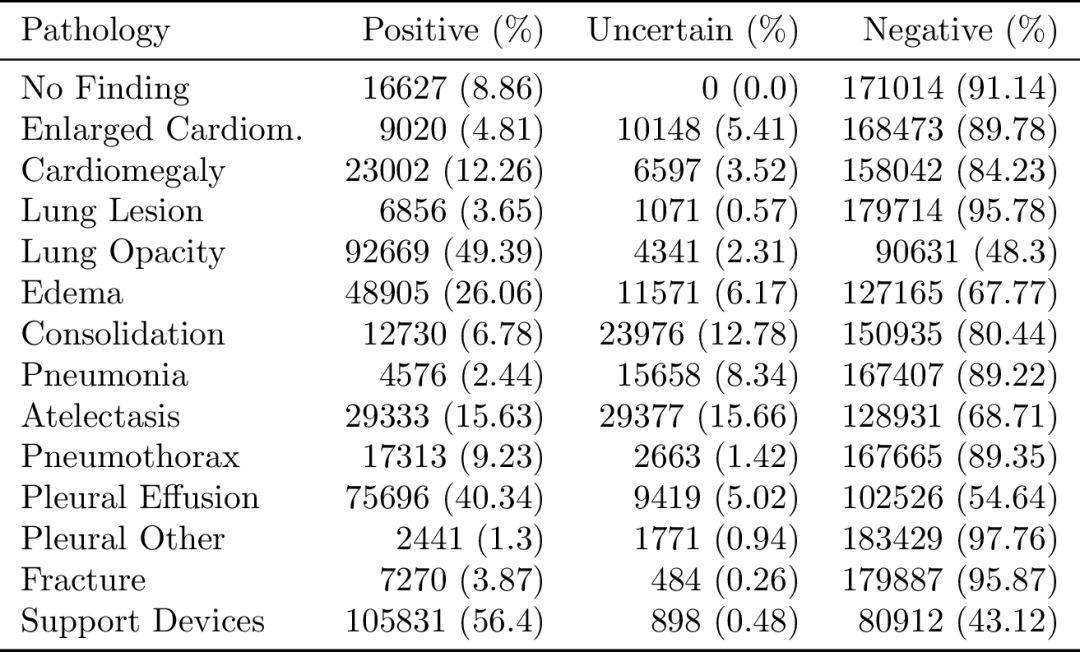
每份報告都對14項觀察進行標記,標記可能是陽性,陰性或不確定性。
14項觀察是根據報告中的流行程度和臨床相關性確定的,并在適用的情況下符合Fleischner Society推薦的術語表。
此外,還開發了一種基于規則的自動貼標機,用于從放射學報告中提取觀察結果,用作圖像的結構化標簽。貼標機工作分為三個不同的階段:提及提取,提及分類和提及聚合。
自動貼標機github地址:
https://github.com/stanfordmlgroup/chexpert-labeler
在提及提取階段,貼標機從放射學報告的“印象”部分的觀察列表中提取提及,這一部分總結了放射研究中的關鍵發現。在提及分類,則是用每一個提及來分類,把觀察到的歸類為陰性的,不確定的或陽性的。在提到聚合階段,使用每次提及觀察的分類,就會得到14個觀察的最終標簽。
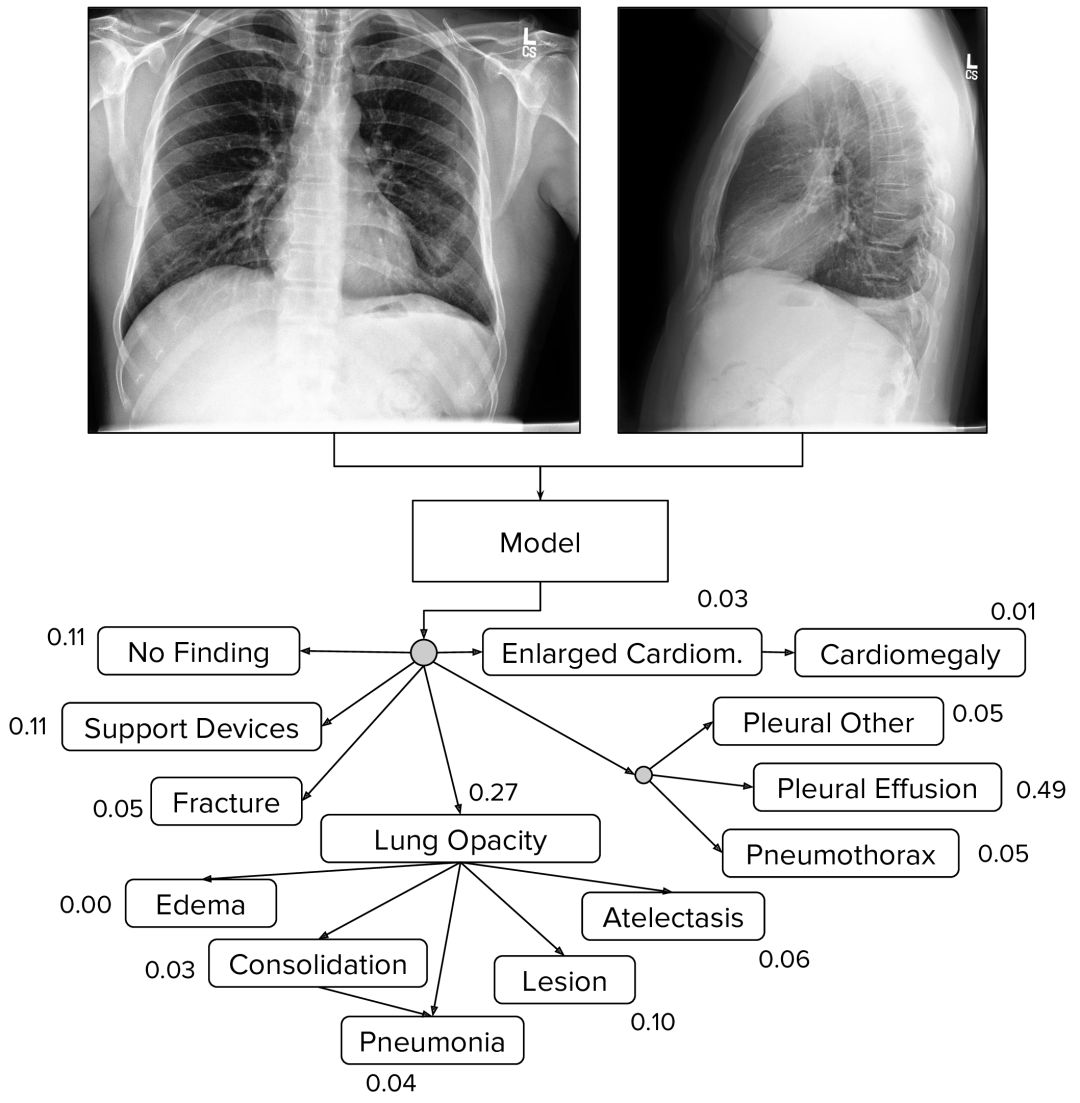
基準模型
基準模型采用以單視角胸片作為輸入,并輸出14次觀測中每一次的概率。當多個視圖可用的時候,模型給出最大概率。
利用不確定性標簽
數據集中的訓練數據集的標簽分別為0、1或u。其中,0表示負,1表示正,u表示不確定。在模型訓練中,使用了不確定性標簽的不同方法。
U-Ignore:在訓練期間忽略了不確定的標簽。
U-Zeroes:將不確定標簽的所有實例映射到0。
U-Ones:將不確定標簽的所有實例映射到1。
U-SelfTrained:首先使用U-Ignore方法訓練模型進行收斂,然后使用該模型進行預測,利用模型輸出的概率預測重新標記每個不確定性標簽。
U-MultiClass:將不確定性標簽視為自己的類別。
專注于評估5項觀察,進行“競爭任務”,根據臨床經驗和患病率分為:(a)肺不張,(b)心臟擴大,(c)肺實變,(d)水腫(e)胸腔積液。通過比較了不同不確定性方法在200個研究的驗證集上的表現,其中三個放射科醫師的注釋作為基礎事實。基準模型根據驗證集上每個競賽任務的最佳表現方法選擇的:U- Ones用于肺不張和水腫,U-MultiClass用于心臟擴大和胸腔積液,U-SelfTrained用于肺實變。
測試集如何設計
CheXpert中的測試集由來自500“未知”患者的500張X光胸片組成。八名權威認證的放射科醫師分別對測試集中的每張圖片進行了注釋。他們將每張圖片標記為:現存(present)、不確定(uncertain likely)、不可能(uncertain unlikely)和缺失(absent)。
然后將標簽二值化,將現存和不確定病例視為陽性,而缺失和不可能病例視為陰性。根據5位專家的投票確定圖片標簽,然后用剩下的三位專家檢驗五位專家的表現。
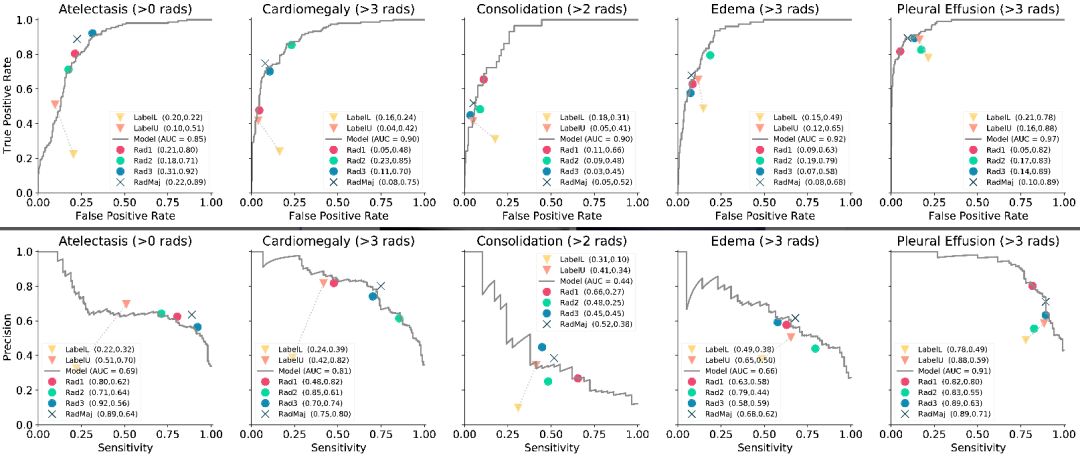
基準模型在測試集上表現如何
該模型在胸腔積液(0.97)上達到最佳AUC,在肺不張(0.85)上達到最差。所有其他觀測的AUC至少為0.9。在心臟擴大,水腫和胸腔積液上,該模型比所有3位放射科醫師獲得更高的表現,但卻不是他們的多數投票。在肺實變方面,模型性能超過3位放射科醫師中的2位,而在Atelectasis上,所有3位放射科醫師的表現均優于模型。
與麻省理工學院的聯合發布MIMIC-CXR數據集
此外還有和MIMIC-CXR共同發布包含371,920張胸部X射線圖片的大型數據集。該數據集的時間跨度為2011年~2016年。這些數據與Beth Israel Deaconess醫療中心的227,943個影像學研究相關。每個成像研究可能包含一個或多個圖像,但一般是兩個圖像:正面視圖和側視圖。
相關論文下載地址:https://arxiv.org/pdf/1901.07042.pdf
圖像提供有14個標簽,這些標簽來自放射學報告的自然語言處理工具。CheXpert數據集和MIMIC-CXR共享一個共同的貼標機,CheXpert貼標機,用于從放射學報告中獲取相同的標簽集。
最后展望
阻礙胸部X光片解釋模型發展之一是,缺乏具有強放射學家注釋的地面真實性和專家評分的數據集。研究人員可以根據這些數據對其模型進行比較。希望CheXpert將填平這一溝谷,以便在臨床重要任務中隨時跟蹤模型的進展。
此外,吳恩達團隊本次開發并開源了CheXpert貼標機,這是一種基于規則的自動貼標機,用于從自由文本放射學報告中提取觀察結果,用作圖像的結構化標簽。我們希望這可以幫助其他機構輕松地從報告中提取結構化標簽,并發布其他大型數據庫,以便對醫學成像模型進行跨機構測試。
最后,斯坦福也作出展望,希望該數據集能夠幫助開發和驗證胸部X光片解釋模型,以改善全球醫療服務的獲取和交付。
-
MIT
+關注
關注
3文章
253瀏覽量
23440 -
數據集
+關注
關注
4文章
1209瀏覽量
24789
原文標題:斯坦福聯合MIT,發布兩類巨大量級X光胸片數據集
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
上能電氣助力巴基斯坦綠色發展
斯坦福STANFORD FS725銣鐘
斯坦福研究:電動汽車電池實際壽命比預估長得多
STANFORD斯坦福SR830 鎖相放大器
國產儀器崛起:斯坦福替代方案來了!

斯坦福團隊抄襲國產大模型,主要責任人失聯
斯坦福大學研發全新AI輔助全息成像技術
斯坦福發布《2024 AI指數報告》

斯坦福、伯克利大神教授創業給機器人造大腦,OpenAI紅杉搶著投5億

廣和通發布基于高通高算力芯片的具身智能機器人開發平臺Fibot
廣和通發布具身智能機器人開發平臺Fibot






 工商網監
工商網監
評論