") 什么是主動視覺跟蹤?讓目標(biāo)與跟蹤器“斗起來”
什么是主動視覺跟蹤?讓目標(biāo)與跟蹤器“斗起來”
本文是ICLR2019入選論文《AD-VAT: An Asymmetric Dueling mechanism for learning Visual Active Tracking》的深入解讀。該論文由北京大學(xué)數(shù)字視頻編解碼技術(shù)國家工程實(shí)驗(yàn)室博士生鐘方威、嚴(yán)汀沄在王亦洲老師和騰訊AI Lab研究員孫鵬、羅文寒的指導(dǎo)下合作完成。該研究也入選了2018騰訊AI Lab犀牛鳥專項(xiàng)研究計(jì)劃。
什么是主動視覺跟蹤?
主動視覺跟蹤(Visual Active Tracking)是指智能體根據(jù)視覺觀測信息主動控制相機(jī)的移動,從而實(shí)現(xiàn)對目標(biāo)物體的跟蹤(與目標(biāo)保持特定距離)。主動視覺跟蹤在很多真實(shí)機(jī)器人任務(wù)中都有需求,如用無人機(jī)跟拍目標(biāo)拍攝視頻,智能跟隨旅行箱等。要實(shí)現(xiàn)主動視覺跟蹤,智能體需要執(zhí)行一系列的子任務(wù),如目標(biāo)識別、定位、運(yùn)動估計(jì)和相機(jī)控制等。
然而,傳統(tǒng)的視覺跟蹤方法的研究僅僅專注于從連續(xù)幀中提取出關(guān)于目標(biāo)的2D包圍框,而沒有考慮如何主動控制相機(jī)移動。因此,相比于這種“被動”跟蹤,主動視覺跟蹤更有實(shí)際應(yīng)用價值,但也帶來了諸多挑戰(zhàn)。
左圖:一個機(jī)器人主動跟隨目標(biāo)移動(圖片來自網(wǎng)絡(luò))
右圖:對比基于強(qiáng)化學(xué)習(xí)的端到端主動跟蹤和傳統(tǒng)的跟蹤方法[1]
深度強(qiáng)化學(xué)習(xí)方法有前景,但仍有局限性
在前期的工作[1][2]中,作者提出了一種用深度強(qiáng)化學(xué)習(xí)訓(xùn)練端到端的網(wǎng)絡(luò)來完成主動視覺跟蹤的方法,不僅節(jié)省了額外人工調(diào)試控制器的精力,而且取得了不錯的效果,甚至能夠直接遷移到簡單的真實(shí)場景中工作。
然而,這種基于深度強(qiáng)化學(xué)習(xí)訓(xùn)練的跟蹤器的性能一定程度上仍然受限于訓(xùn)練的方法。因?yàn)樯疃葟?qiáng)化學(xué)習(xí)需要通過大量試錯來進(jìn)行學(xué)習(xí),而直接讓機(jī)器人在真實(shí)世界中試錯的代價是高昂的。一種常用的解決方案是使用虛擬環(huán)境進(jìn)行訓(xùn)練,但這種方法最大的問題是如何克服虛擬和現(xiàn)實(shí)之間的差異,使得模型能夠部署到真實(shí)應(yīng)用當(dāng)中。雖然已經(jīng)有一些方法嘗試去解決這個問題,如構(gòu)建大規(guī)模的高逼真虛擬環(huán)境用于視覺導(dǎo)航的訓(xùn)練,將各個因素(表面紋理/光照條件等)隨機(jī)化擴(kuò)增環(huán)境的多樣性。
對于主動視覺跟蹤的訓(xùn)練問題,不僅僅前背景物體外觀的多樣性,目標(biāo)運(yùn)動軌跡的復(fù)雜程度也將直接影響跟蹤器的泛化能力。可以考慮一種極端的情況:如果訓(xùn)練時目標(biāo)只往前走,那么跟蹤器自然不會學(xué)會適應(yīng)其它的運(yùn)動軌跡,如急轉(zhuǎn)彎。但對目標(biāo)的動作、軌跡等因素也進(jìn)行精細(xì)建模將會是代價高昂的且無法完全模擬所有真實(shí)情況。
讓目標(biāo)與跟蹤器“斗起來”
因此,作者提出了一種基于對抗博弈的強(qiáng)化學(xué)習(xí)框架用于主動視覺跟蹤的訓(xùn)練,稱之為AD-VAT(Asymmetric Dueling mechanism for learning Visual Active Tracking)。
在這個訓(xùn)練機(jī)制中,跟蹤器和目標(biāo)物體被視作一對正在“決斗”的對手(見下圖),也就是跟蹤器要盡量跟隨目標(biāo),而目標(biāo)要想辦法脫離跟蹤。這種競爭機(jī)制,使得他們在相互挑戰(zhàn)對方的同時相互促進(jìn)共同提升。
當(dāng)目標(biāo)在探索逃跑策略時,會產(chǎn)生大量多種多樣的運(yùn)動軌跡,并且這些軌跡往往會是當(dāng)前跟蹤器仍不擅長的。
在這種有對抗性的目標(biāo)的驅(qū)動下,跟蹤器的弱點(diǎn)將更快地暴露隨之進(jìn)行強(qiáng)化學(xué)習(xí),最終使得其魯棒性得到顯著提升。
在訓(xùn)練過程中,因?yàn)楦櫰骱湍繕?biāo)的能力都是從零開始同步增長的,所以他們在每個訓(xùn)練階段都能夠遇到一個能力相當(dāng)?shù)膶κ峙c之競爭,這就自然得構(gòu)成了從易到難的課程,使得學(xué)習(xí)過程更加高效。
然而,直接構(gòu)造成零和游戲進(jìn)行對抗訓(xùn)練是十分不穩(wěn)定且難以收斂的。
AD-VAT概覽
如何讓對抗更加高效且穩(wěn)定?
為解決訓(xùn)練的問題,作者提出了兩個改進(jìn)方法:不完全零和的獎賞函數(shù)(partial zero-sum reward)和用于目標(biāo)的跟蹤可知模型(tracker-aware model)。
不完全零和獎賞是一種混合的獎賞結(jié)構(gòu),僅鼓勵跟蹤器和目標(biāo)在一定相對范圍內(nèi)進(jìn)行零和博弈,當(dāng)目標(biāo)到達(dá)一定距離外時給予其額外的懲罰,此時將不再是零和博弈,因此稱之為不完全零和獎賞。
這么設(shè)計(jì)獎賞函數(shù)是為了避免一個現(xiàn)象,當(dāng)目標(biāo)快速遠(yuǎn)離跟蹤器時,跟蹤器將不能觀察到目標(biāo),以至于訓(xùn)練過程變得低效甚至不穩(wěn)定。
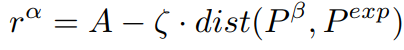
上式為跟蹤器的獎賞函數(shù),沿用了[1]中的設(shè)計(jì)思想,懲罰項(xiàng)由期望位置與目標(biāo)之間的距離所決定。
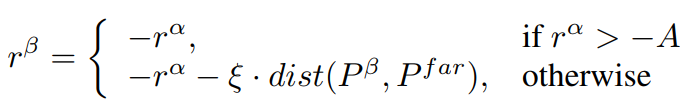
上式為目標(biāo)的獎賞函數(shù),在觀測范圍內(nèi),目標(biāo)與跟蹤器進(jìn)行零和博弈,即獎賞函數(shù)為跟蹤器的獎賞直接取負(fù)。在觀測范圍外,將在原來的基礎(chǔ)上得到一個額外的懲罰項(xiàng),懲罰項(xiàng)的取值取決于目標(biāo)與跟蹤器的觀測邊界的距離。
跟蹤可知模型是為了讓目標(biāo)能夠針對跟蹤策略學(xué)會更優(yōu)的對抗策略,所謂“知己知彼,百戰(zhàn)不殆”。具體的,除了其自身的視覺觀測外,還額外獲得了跟蹤器的觀測和動作輸出作為模型的輸入。
為了更好地學(xué)習(xí)關(guān)于跟蹤器的特征表示,作者還引入了一個輔助任務(wù):預(yù)測跟蹤器的即時獎賞值。
基于以上改進(jìn),“決斗(Dueling)”雙方在觀測信息、獎賞函數(shù)、目標(biāo)任務(wù)上將具備不對稱性(Asymmetric),因此將這種對抗機(jī)制稱之為“非對稱決斗(Asymmetric Dueling)”。
實(shí)驗(yàn)環(huán)境
作者在多種不同的2D和3D環(huán)境開展了實(shí)驗(yàn)以更進(jìn)一步驗(yàn)證該方法的有效性。2D環(huán)境是一個簡單的矩陣地圖,用不同的數(shù)值分別表示障礙物、目標(biāo)、跟蹤器等元素。
作者設(shè)計(jì)了兩種規(guī)則生成地圖中的障礙物分布(Block, Maze)。作者設(shè)計(jì)了兩種基于規(guī)則的目標(biāo)運(yùn)動模型作為基準(zhǔn):漫步者(Rambler)和導(dǎo)航者(Navigator)。
漫步者是隨機(jī)從選擇動作和持續(xù)的時間,生成的軌跡往往在一個局域范圍內(nèi)移動(見Block-Ram中的黃色軌跡)。
導(dǎo)航者則是從地圖中隨機(jī)采樣目標(biāo)點(diǎn),然后沿著最短路徑到達(dá)目標(biāo),因此導(dǎo)航者將探索更大范圍(見Block-Nav中的黃色軌跡)。
將這些不同種的地圖和目標(biāo)依次組合,構(gòu)成了不同的訓(xùn)練和測試環(huán)境。作者只用其中的一種地圖(Block)用作訓(xùn)練,然后在所有可能的組合環(huán)境中測試,從而證明模型的泛化能力。
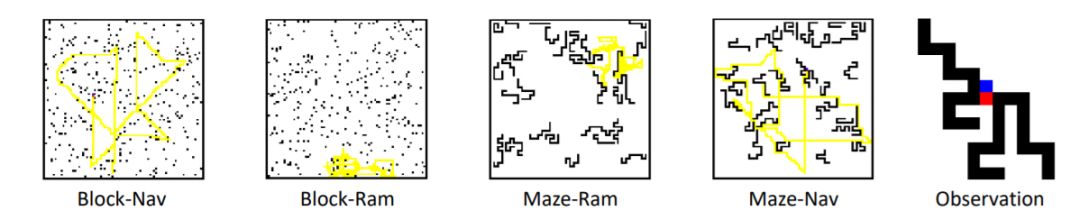
3D環(huán)境是基于UE4和UnrealCV[3]構(gòu)建的虛擬環(huán)境。作者只用一個采取域隨機(jī)技術(shù)(環(huán)境中物體表面紋理、光照條件都可以進(jìn)行隨機(jī)設(shè)置)的房間(DR Room, Domain Randomized Room)進(jìn)行訓(xùn)練,然后在三個不同場景的近真實(shí)場景中測試模型的性能。
實(shí)驗(yàn)結(jié)果
在2D環(huán)境中,作者首先驗(yàn)證了AD-VAT相比基準(zhǔn)方法能夠帶來有效提升,同時進(jìn)行了消融實(shí)驗(yàn)來證明兩個改進(jìn)方法的有效性。
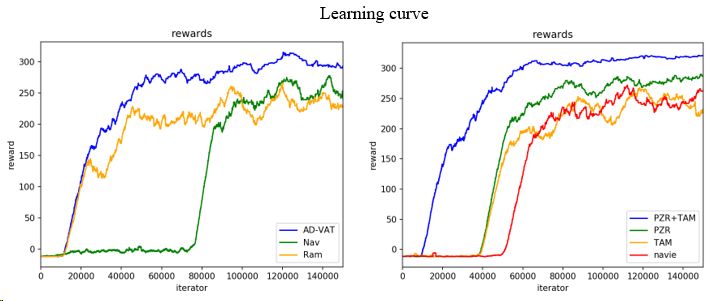
左圖為AD-VAT(藍(lán)線)和基準(zhǔn)方法在2D環(huán)境中的訓(xùn)練曲線,可見AD-VAT能夠讓跟蹤器學(xué)得更快更好。右圖為消融實(shí)驗(yàn)的結(jié)果,對比刪減不同模塊后的學(xué)習(xí)曲線,作者提出的兩個改進(jìn)方法能夠使對抗強(qiáng)化學(xué)習(xí)的訓(xùn)練更高效。
作者在3D環(huán)境中的實(shí)驗(yàn)更進(jìn)一步證明該方法的有效性和實(shí)用性。
在訓(xùn)練過程中,作者觀測到了一個有趣的現(xiàn)象,目標(biāo)會更傾向于跑到背景與其自身紋理接近的區(qū)域,以達(dá)到一種“隱身”的效果來迷惑跟蹤器。而跟蹤器在被不斷“難倒”后,最終學(xué)會了適應(yīng)這些情況。
作者對比了由AD-VAT和兩種基準(zhǔn)方法訓(xùn)練的跟蹤器在不同場景中的平均累計(jì)獎賞(左圖)和平均跟蹤長度(右圖)。
其中,雪鄉(xiāng)(Snow Village)和地下停車場(Parking Lot)是兩個十分有挑戰(zhàn)性的環(huán)境,每個模型的性能都有不同程度的下降,但該論文提出的模型取得了更好的結(jié)果,說明了AD-VAT跟蹤器對復(fù)雜場景的適應(yīng)能力更強(qiáng)。
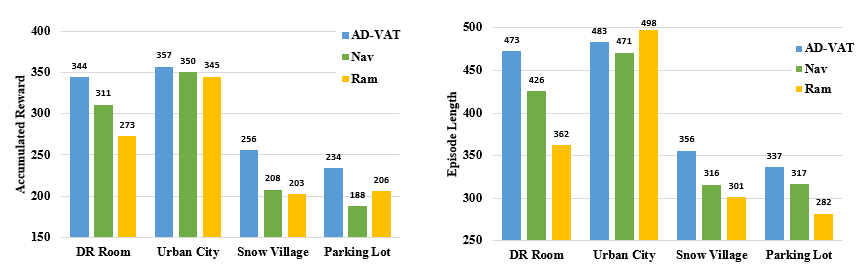
雪鄉(xiāng)主要的挑戰(zhàn)在于地面崎嶇不平,且相機(jī)會被下落的雪花、逆光的光暈等因素干擾導(dǎo)致目標(biāo)被遮擋:
左圖為跟蹤器第一人稱視角,右圖為第三人稱視角
停車場中光線分布不均勻(亮暗變化劇烈),且目標(biāo)可能被立柱遮擋:
左圖為跟蹤器第一人稱視角,右圖為第三人稱視角
-
跟蹤器
+關(guān)注
關(guān)注
0文章
131瀏覽量
20051 -
視覺跟蹤
+關(guān)注
關(guān)注
0文章
11瀏覽量
8831 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
268瀏覽量
11270
原文標(biāo)題:ICLR2019 | 你追蹤,我逃跑:一種用于主動視覺跟蹤的對抗博弈機(jī)制
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
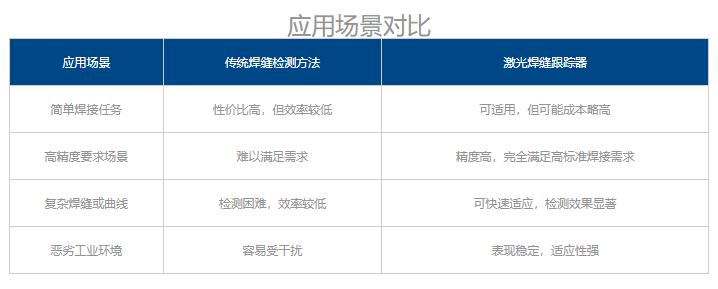
激光焊縫跟蹤器與傳統(tǒng)焊縫檢測方法的對比
深入解析激光焊縫跟蹤器的工作原理與應(yīng)用優(yōu)勢

視頻目標(biāo)跟蹤從0到1,概念與方法

TRKRLDOEVM-119通用跟蹤器LDO評估模塊

使用TMS320C40 DSP實(shí)現(xiàn)單脈沖雷達(dá)的數(shù)字跟蹤器

用邏輯和翻譯用例優(yōu)化資產(chǎn)跟蹤器
創(chuàng)想智控激光焊縫跟蹤器協(xié)同專機(jī)在風(fēng)機(jī)高精度自動焊接的應(yīng)用

光學(xué)跟蹤器接口連接方法有哪些
光學(xué)跟蹤器信號源手機(jī)怎么設(shè)置
光學(xué)跟蹤器使用的技術(shù)有哪幾種
創(chuàng)想智控激光焊縫跟蹤器在醫(yī)療攪拌罐反應(yīng)釜自動焊接的應(yīng)用

創(chuàng)想智控激光焊縫跟蹤器在機(jī)械法蘭盤自動掃描焊接的應(yīng)用

多目標(biāo)跟蹤算法總結(jié)歸納





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論