") 英偉達(dá)GPU Direct不可或缺的RMDA技術(shù)到底有多厲害?
英偉達(dá)GPU Direct不可或缺的RMDA技術(shù)到底有多厲害?
和娛樂圈的明星八卦一樣,IT行業(yè)里面的各種并購也是非常有市場的。畢竟,像EMC,Cisco,Broadcom 這樣的公司都是一路并購成長起來的。最近比較熱門的應(yīng)該是Mellanox說自己準(zhǔn)備賣自己了。在25G/50G/100G市場上占據(jù)了69%的市場份額,2018年前三個季度,出貨了2.1M的網(wǎng)絡(luò)端口。[1] 這么好的標(biāo)的,一時各種傳聞都出來了。Xilinx[2],Microsoft[3],Intel[4],估計還有Broadcom[5]都在準(zhǔn)備,以色列人的確有水平,已經(jīng)從5.5B到了6B。陳福陽在華爾街籌錢的能力,估計還有大招。
Mellanox是個什么公司,一句話,就是目前RDMA技術(shù)的事實的技術(shù)定義者。雖然海有很多公司也有RDMA技術(shù),但是在IB和Ethernet兩個市場都能夠呼風(fēng)喚雨,只有它了。
Remote DMA技術(shù)在Ethernet上的應(yīng)用不能不提微軟,目前微軟是目前在數(shù)據(jù)中心大規(guī)模部署RDMA的第一家HyperScale公司。微軟在2015/6/7/8年的Sigcomm [6]有大量的論文來講RDMA在數(shù)據(jù)中心的部署,很多人講微軟的風(fēng)格是自己做了100分,但是對外只講1分。因此可以想象Microsoft對于Mellanox準(zhǔn)備賣身的關(guān)注,自己的技術(shù)投入不能打水漂,不僅自己下手,而且鼓勵合作伙伴一起團購。
RDMA的技術(shù)是在一個有Mellanox主導(dǎo)的行業(yè)組織OFA[7]主導(dǎo)的。目前的成員如下圖,可以看到還是集中在HPC的專業(yè)領(lǐng)域。

OFA是2004年成立的工業(yè)組織,在整個HPC行業(yè)從Myrinet[8]轉(zhuǎn)換到IB的時候成立的。在2005年, Myrinet在TOP500的市場份額占到了28%,之后就一路下降,被IB替換掉了。對于誕生于HPC專業(yè)的領(lǐng)域,可用性一直是個大問題,HPC一切為了性能,不要虛擬化,不要通用操作系統(tǒng)和架構(gòu),每臺超算恨不得自成一臺體系。大家看看Mellanox的Linux 驅(qū)動的家族就知道這個有多復(fù)雜了。[7]
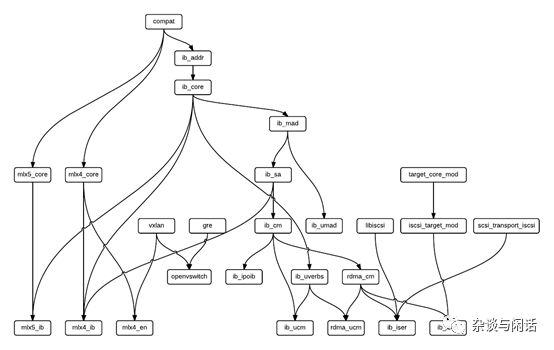
這路吐一個槽,作為Mellanox卡的資深用戶,我很早就自己畫了一份他們的OFED驅(qū)動的加載流程,作為Mellanox,這么基本的文檔在2018年12月才發(fā)布,而且很多模塊沒有upstream,讓人無奈的是,到現(xiàn)在為止我還沒有找到卸載rdma_cm ( connection mangament ) 的有效方法。每次都需要重啟。
因此看到AWS說要發(fā)布他們的EFA的時候,覺得他們還是真有勇氣,但是仔細(xì)一看,原來和AWS的HPC業(yè)務(wù)緊密結(jié)合,而且利用了libfabric 的生態(tài)[8]
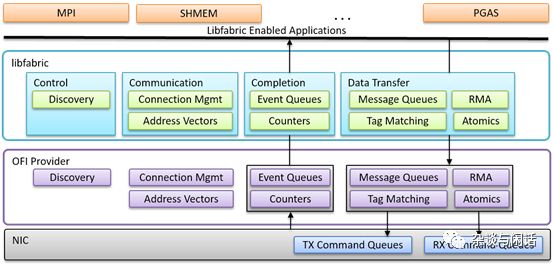
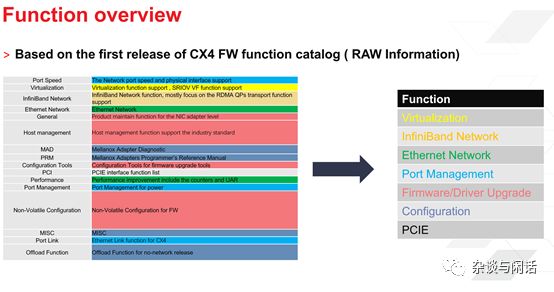
很明顯,libfabric在網(wǎng)路傳輸層和流行的HPC編程框架之間做了一個統(tǒng)一。更重要的是,對于原來OFA的功能定義做了一個大大減法。俺曾經(jīng)自己研究總結(jié)了Mellanox CX系列網(wǎng)卡的功能。大家可以自己看看這個復(fù)雜度。
對于像AWS這樣的Hyperscale公司也要部署RDMA,這個做法和之前的微軟有很大的不同。對于微軟,他們從40G開始規(guī)模部署RDMA,就是為了Azure的云環(huán)境的低延時網(wǎng)絡(luò),目前微軟的網(wǎng)絡(luò)還是天下第一。[9]當(dāng)然微軟為了大規(guī)模部署RoCEv2的所作的各種流控算法以及應(yīng)用的優(yōu)化對于整個業(yè)界都是非常有用的,但是他們主要停留在傳統(tǒng)的網(wǎng)絡(luò)上面。
AWS則不同,對于低延時網(wǎng)絡(luò)來講,在2014年之前,大部分的場景就是SDS,太多的存儲startup公司,使用PCIE Flash和RDMA 網(wǎng)卡來構(gòu)建自己的分布式存儲系統(tǒng),比較典型就是EMC收購的ScaleI/O了。[10]
2014年之后,由于ALexnet的出色表現(xiàn),RMDA和Nvidia有了深度合作,利用GPU Direct,在GPU集群中快速傳遞數(shù)據(jù)成了RDMA的另一個
大眾應(yīng)用。[11]
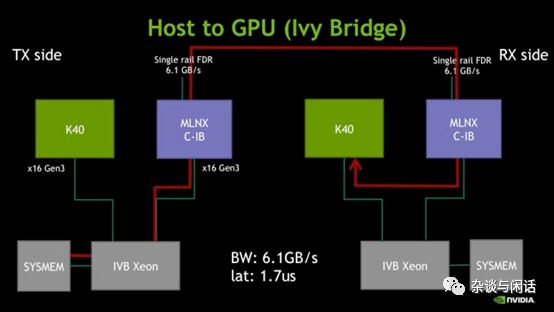
GPU+RDMA也是目前在TOP500部署量最大的應(yīng)用,因此可以很明確地看出AWS使用Nitro做EFA的目的了。
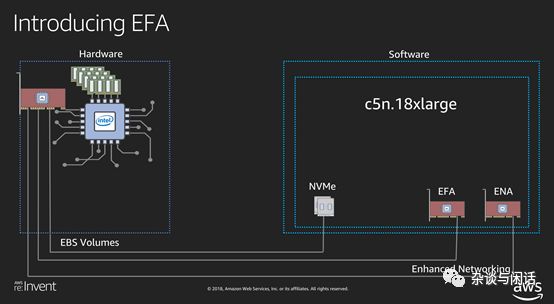
貌似只有一款機型部署了EFA。[12] 對于這個機型,定位很清楚,HPC和分布式機器學(xué)習(xí)的訓(xùn)練,因此功能實現(xiàn)也非常有目的,不要指望EFA會和Mellanox一樣功能強大。
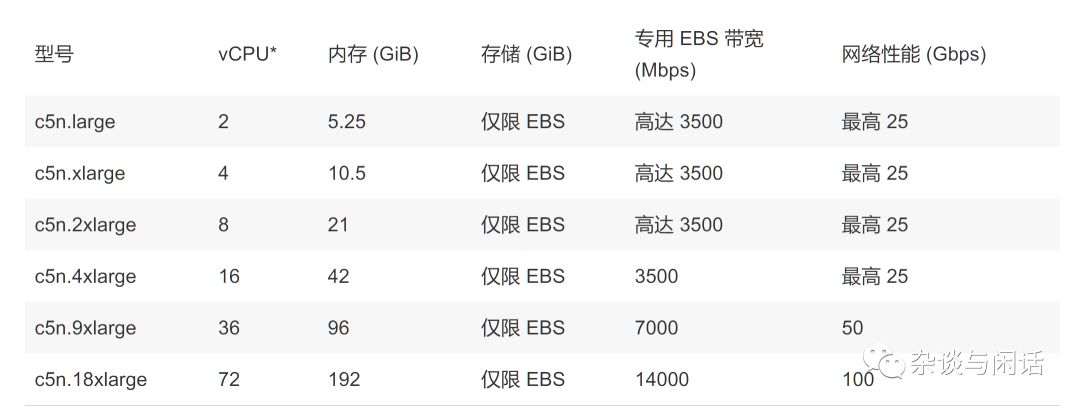
因此,可以看出,傳統(tǒng)的Nitro芯片在升級了25G的Serdes之后,利用libfabric的生態(tài)實現(xiàn)了部分的RDMA的功能,可以滿足AWS上的HPC和ML的業(yè)務(wù)需求。這個和國內(nèi)的大廠的想法類似。
因此,對于未來RDMA在數(shù)據(jù)中心的使用場景,存儲和HPC是兩個比較明確的方向。對于存儲,如何和NVMe這樣的存儲介質(zhì),以及NVMeoF和Cephover RDMA這樣的存儲后端結(jié)合是一個方向,在這個方向上,是不是要支持IB的編程框架并不重要。對于HPC的方向,則是如何和GPU這樣的計算引擎結(jié)合,簡單數(shù)據(jù)傳輸?shù)难訒r,和上層的ML的框架緊密結(jié)合。
廣告時間: Xilinx在2018.1 中就推出了自己的RDMA的實現(xiàn),目前主要關(guān)注在存儲應(yīng)用這個方向。[13]實現(xiàn)了對10G/25G/40G/100G的網(wǎng)絡(luò)速率的支持,在Vivado 2019.1中會在延時上有進一步的提升,在512Byte上和標(biāo)準(zhǔn)的Mellanox類似,當(dāng)然我們也是兼容Mellanox。歡迎大家垂詢。
[1]https://www.businesswire.com/news/home/20181025005197/en/Mellanox-Ships-2.1-Million-Ethernet-Adapters-Quarters
[2]https://www.cnbc.com/2018/11/07/xilinx-working-with-barclays-to-buy-mellanox-possible-december-deal.html
[3]https://www.cbronline.com/news/microsoft-mellanox
[4]https://www.hpcwire.com/2019/01/30/intel-reportedly-in-6b-bid-for-mellanox/
[5]https://en.globes.co.il/en/article-mellanox-acquisition-fits-broadcom-like-a-glove-1001258241
[6]http://www.sigcomm.org/
[7]https://community.mellanox.com/s/article/mellanox-linux-driver-modules-relationship--mlnx-ofed-x
[8]https://ofiwg.github.io/libfabric/
[9]https://mspoweruser.com/report-microsoft-azure-beats-google-cloud-and-amazon-aws-in-network-performance/
[10]https://en.wikipedia.org/wiki/Dell_EMC_ScaleIO
[11]https://devblogs.nvidia.com/benchmarking-gpudirect-rdma-on-modern-server-platforms/
[12]https://aws.amazon.com/cn/ec2/instance-types/
[13]https://www.xilinx.com/products/intellectual-property/etrnic.html
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3815瀏覽量
91492
原文標(biāo)題:深度好文:RDMA,到底有多厲害?
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
BGA芯片封裝:現(xiàn)代電子產(chǎn)業(yè)不可或缺的技術(shù)瑰寶

高鐵站網(wǎng)約車數(shù)智出行到底有多智能?
軟銀升級人工智能計算平臺,安裝4000顆英偉達(dá)Hopper GPU
挑戰(zhàn)英偉達(dá):聚焦本土GPU領(lǐng)軍企業(yè)崛起
英偉達(dá)將全面轉(zhuǎn)向開源GPU內(nèi)核模塊
英偉達(dá)數(shù)據(jù)中心GPU出貨量飆升,市場份額持續(xù)領(lǐng)跑
英偉達(dá)GPU新品規(guī)劃與HBM市場展望
進一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級芯片
英偉達(dá)、AMD、英特爾GPU產(chǎn)品及優(yōu)勢匯總
國內(nèi)GPU新勢力:能否成為英偉達(dá)的“終結(jié)者”?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論