 并行MAC/減少內存訪問,東芝發布第五代Visconti系列圖像識別SoC
并行MAC/減少內存訪問,東芝發布第五代Visconti系列圖像識別SoC
自動駕駛需要相當復雜的傳感器組合,而這些傳感器提供的數據量遠遠高于現有汽車搭載的傳感器。
為了滿足對更強大的圖像處理的需求,東芝歐洲公司(TEE)宣布推出一種集成了深度學習加速器的圖像識別SoC。測試數據顯示,新款SoC與該公司現有產品相比,圖像識別速度提高了10倍,能效提高了4倍。
深度神經網絡(Deep neural network, DNN)是一種以大腦神經網絡為模型的算法,與傳統的模式識別和機器學習相比,它能更準確地進行識別處理,并在自動駕駛技術研發領域被大量應用。
然而,傳統處理器基于DNN的圖像識別需要時間,因為它依賴于大量的multiply- aggregation (MAC)計算。使用傳統高速處理器的DNN也會消耗太多電能。
與L3級及以下自動輔助駕駛系統相比,L4/L5級自動駕駛汽車對計算能力的要求提高了100倍。這包括需要處理來自汽車周圍多個攝像頭、雷達和激光雷達傳感器的輸入,解釋數據,并使用這些數據做出駕駛決策。
芯片制造商英偉達去年10月發布的一份有關自動駕駛車載計算能力的報告。該公司稱,一輛裝有10個高分辨率攝像頭的汽車每秒產生20億像素的數據,每秒處理這些數據需要250萬億次操作。
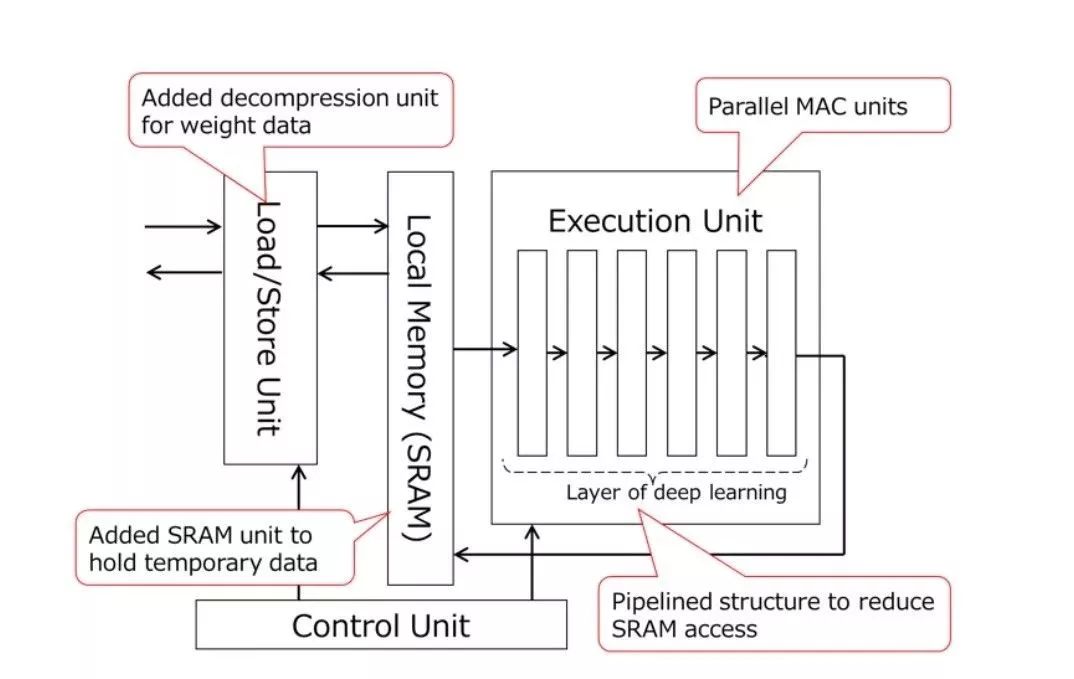
三年前,東芝與日本汽車零部件供應商DENSO合作,共同開發上述深度神經網絡技術。目前,東芝已經通過DNN加速器克服了這一問題,該加速器實現了硬件級的深度學習加速。
它有三個特點:
? 并行的MAC單元。DNN處理需要很多MAC計算。東芝的新設備有四個處理器,每個處理器有256個MAC單元。這提高了DNN的處理速度。
? 減少DRAM訪問。傳統的SoC沒有本地內存來保持DNN執行單元附近的時間數據,并且訪問本地內存會消耗大量的電能,加載權重數據(用于MAC計算)也會消耗電能。
在東芝的新產品中,SRAM是集成在DNN執行單元中,DNN處理分為子處理塊,將時間數據保存在SRAM中,減少了DRAM的訪問。
此外,東芝還為加速器增加了一個解壓裝置。通過解壓縮單元加載預先壓縮并存儲在DRAM中的權重數據,這減少了從DRAM加載權重數據所涉及的功耗。
? 減少SRAM訪問。傳統的深度學習需要在處理完DNN的每一層后訪問SRAM,這消耗了太多的能量。這款加速器在DNN執行單元中具有流水線的層結構,允許通過一個SRAM訪問執行一系列DNN計算。
新的SoC符合ISO26262汽車應用功能安全標準。東芝還表示,將繼續提高開發的SoC的功率效率和處理速度,并將于今年9月開始對下一代東芝圖像識別處理器Visconti5(DNN硬件IP與傳統圖像處理技術集成)進行樣品發貨。

對于低成本的自動駕駛方案來說,攝像頭和圖像識別的作用更為明顯。同時,在多傳感器融合中,圖像識別也被視為主傳感器的角色。
此前,東芝已經提供了TMPV75和TMPV76兩個系列的圖像識別處理器,它們集成了RISC架構的媒體處理引擎(MPEs),以提高圖像數據處理性能。該處理器能夠實時處理1到4個攝像頭的輸入圖像,并允許最多連接8個攝像頭。
ARM等其他芯片制造巨頭也都在推陳出新。去年9月,ARM推出了Cortex-A76AE (Automotive Enhanced),這是ARM專門為自動駕駛汽車設計的CPU架構。
ARM對A76平臺進行了重新設計,增加了一種名為Split-Lock的功能,允許兩個CPU內核以鎖定步進(都執行相同的任務)或分割模式(執行不同的任務和應用程序)進行操作。
-
東芝
+關注
關注
6文章
1401瀏覽量
121281 -
圖像識別
+關注
關注
9文章
520瀏覽量
38273
原文標題:并行MAC/減少內存訪問,東芝發布第五代Visconti系列圖像識別SoC | GGAI視角
文章出處:【微信號:ilove-ev,微信公眾號:高工智能汽車】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
聯想發布基于第五代AMD EPYC處理器的服務器產品
艾為第五代線性馬達驅動IC賦能vivo X200系列
Snap發布第五代Spectacles AR眼鏡
第五代AMD EPYC處理器預計下半年發布
三星第五代DDR產品良率不達標
【機器視覺】歡創播報 | 比亞迪第五代DM混動技術正式發布
今日看點丨續航超2500公里!比亞迪第五代DM技術正式發布;華為“享界”商標轉讓北汽,聯合設計享界 S9

中國混動汽車油耗再次突破新低 比亞迪第五代DM技術發布油耗低至2.9L
capsense第四代和第五代在感應模式上的具體區別是什么?

第五代英特爾至強處理器,AI特化的通用服務器CPU

Vishay推出30V N溝道TrenchFET第五代功率MOSFET
第五代英特爾至強,以卓越性能為多元化工作負載“保駕護航”
Vishay推出多功能新型30 V N溝道TrenchFET第五代功率MOSFET






 工商網監
工商網監
評論