 工業推薦系統整體架構是怎樣的?
工業推薦系統整體架構是怎樣的?
既然你點開這篇文章了,我假設你是在某司做推薦系統的算法工程師。這個假設的正確率我估計大約在20%左右,因為根據我的經驗,80%的算法工程師是很博愛的,只要標題里帶有“模型/算法/深度學習/震驚/美女….”等詞匯,他們都會好奇地點開看三秒,然后失望地關掉,技術性越強的反而越容易被關掉,很可能撐不過三秒。我說得沒錯吧?嘿嘿。
為了騙點擊,關于本文標題,其實我內心沖動里最想寫下的震驚部風格標題是這樣的:“連女神級美女程序媛看了都震驚!FM模型居然能夠做這么大規模推薦系統的召回!!!”,然后打開文章后,文章配上的背景音樂緩緩地傳來“路燈下昏黃的剪影,越走越漫長的林徑…….”
嗯,好吧,我承認連我自己也忍不了上面的場景,主要是這首歌我還挺喜歡的,單曲循環快半個月了,標題風格比較毀歌的意境。請收拾好您此刻看到上述標題后接近崩潰的心情,不開玩笑了。
讓我再次活回到幻想中,就勉強假設你是位推薦算法工程師吧,您堅持說您不是?別謙虛,您很快就是了,請立即辭職去申請相關工作……如果您真的是推薦工程師,那么首先我想揪住您問個問題:一說起推薦模型或者推薦場景下的排序模型,您腦子里第一個念頭冒出的模型是哪個或哪幾個?
如果你第一念頭冒出來的仍然是SVD/矩陣分解啥的,那么明顯你還停留在啃書本的階段,實踐經驗不足;如果你第一念頭是LR模型或者GBDT模型,這說明你是具備一定實踐經驗的算法工程師,但是知識更新不足。現在都9102年了,我們暫且把Wide&Deep/DeepFM這些模型拋開不提,因為在大規模場景下想要把深度推薦模型高性價比地用好發揮作用其實并不容易。
我們退而求其次,如果現在您仍然不能在日常工作中至少嘗試著用FM模型來搞事情,那只能說明一定概率下(30%到90%?),您是在技術方面對自我沒有太高要求的算法工程師,未來您的技術之路走起來,我猜可能會比較辛苦和坎坷,這里先向身處2025年的另一位您道聲辛苦啦。這是我對您的算法工程師之路的一個預測,至于這個預測準不準,往后若干年的經歷以及時間會告訴您正確答案,當然我個人覺得付出的這個代價可能有點高。
假設你第一念頭是在排序階段使用FM模型、GBDT+LR模型、DNN模型,這說明你算是緊追技術時代發展脈絡的技術人員,很好。那么,單獨給你準備的更專業的新問題來了,請問:樹上七只猴…..嗯,跑偏了,其實我想問的是:我們日常看到的推薦系統長什么樣子,我相信你腦子里很清楚,但是能否打破常規?比如下列兩個不太符合常規做法的技術問題,您可以考慮考慮:
第一個問題:我們知道在個性化推薦系統里,第一個環節一般是召回階段,而召回階段工業界目前常規的做法是多路召回,每一路召回可能采取一個不同的策略。那么打破常規的思考之一是:是否我們能夠使用一個統一的模型,將多路召回改造成單模型單路召回策略?如果不能,那是為什么?如果能,怎么做才可以?這樣做有什么好處和壞處?
第二個問題:我們同樣知道,目前實用化的工業界的推薦系統通常由兩個環節構成,召回階段和排序階段,那么為什么要這么劃分?它們各自的職責是什么?打破常規的另外一個思考是:是否存在一個模型,這個模型可以將召回階段和排序階段統一起來,就是把兩階段推薦環節改成單模型單環節推薦流程?就是說靠一個模型一個階段把傳統的兩階段推薦系統做的事情一步到位做完?如果不能,為什么不能?如果能,怎么做才可以?什么樣的模型才能擔當起這種重任呢?而在現實世界里是否存在這個模型?這個思路真的可行嗎?
上面列的兩個非常規問題,18年年末我自己也一直在思考,有些初步的思考結論,所以計劃寫四篇文章形成一個專題,主題集中在推薦系統的統一召回模型方面,也就是第一個問題,同時兼談下第二個問題,每篇文章會介紹一個或者一類模型,本文介紹的是FM模型。這個系列,我春節期間寫完了3篇,等我四篇都寫完后,會陸續發出來,供感興趣的“點開看三秒”同學參考。
不過這里需要強調一點:關于這兩個問題,因為非常規,網上也也沒有見到過類似的問題,說法及解決方案,所以沒什么依據,文章寫的只是我個人的思考結果,是否真能順利落地以及落地效果存疑,還請謹慎參考。不過,我覺得從目前算法的發展趨勢以及硬件條件的快速發展情況來看,單階段推薦模型從理論上是可行的。我會陸續給出幾個方案,建議從事中小型推薦業務的同學可以快速嘗試一下。
下面進入正題,我會先簡單介紹下推薦系統整體架構以及多路召回的基本模式,然后說明下FM模型,之后探討FM模型是否能夠解決上面提到的兩個非常規問題。
工業推薦系統整體架構是怎樣的?
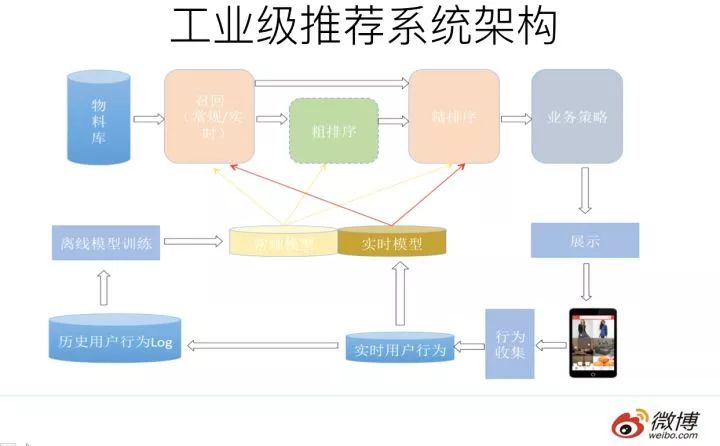
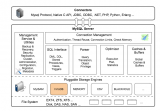
一個典型的工業級推薦系統整體架構可以參考上圖,一般分為在線部分,近線部分和離線部分。
對于在線部分來說,一般要經歷幾個階段。首先通過召回環節,將給用戶推薦的物品降到千以下規模;如果召回階段返回的物品還是太多,可以加入粗排階段,這個階段是可選的,粗排可以通過一些簡單排序模型進一步減少往后續環節傳遞的物品;再往后是精排階段,這里可以使用復雜的模型來對少量物品精準排序。
對某個用戶來說,即使精排推薦結果出來了,一般并不會直接展示給用戶,可能還要上一些業務策略,比如去已讀,推薦多樣化,加入廣告等各種業務策略。之后形成最終推薦結果,將結果展示給用戶。
對于近線部分來說,主要目的是實時收集用戶行為反饋,并選擇訓練實例,實時抽取拼接特征,并近乎實時地更新在線推薦模型。這樣做的好處是用戶的最新興趣能夠近乎實時地體現到推薦結果里。
對于離線部分而言,通過對線上用戶點擊日志的存儲和清理,整理離線訓練數據,并周期性地更新推薦模型。對于超大規模數據和機器學習模型來說,往往需要高效地分布式機器學習平臺來對離線訓練進行支持。
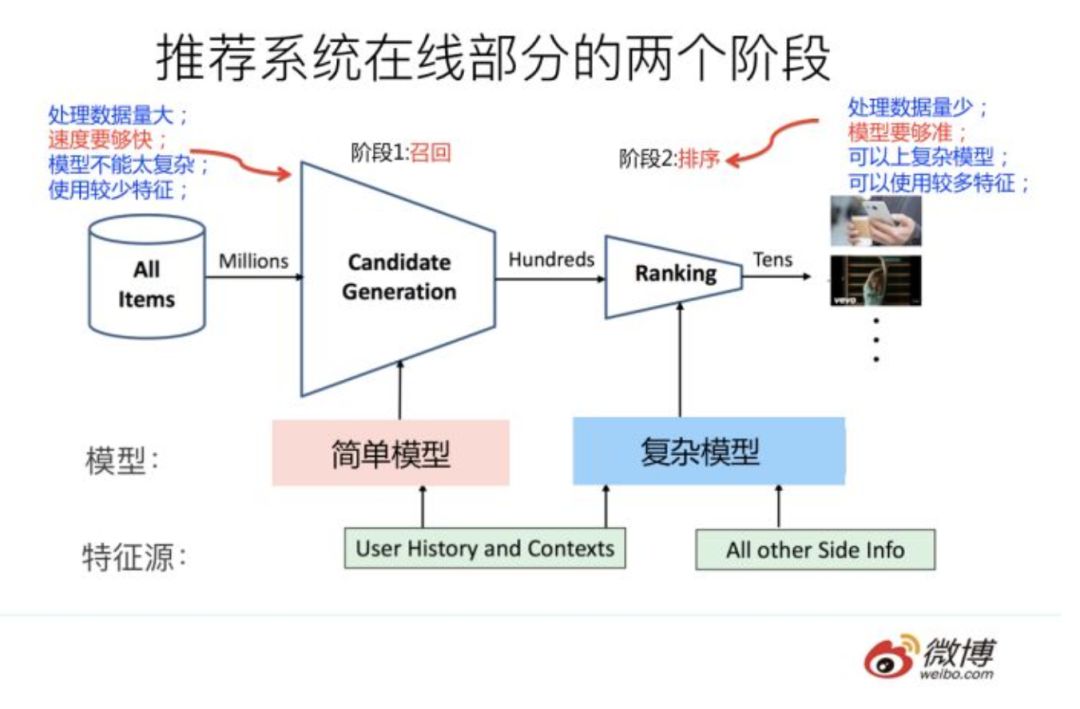
因為粗排是可選的,對于大多數推薦系統來說,通常在線部分的主體分為兩個階段就夠,第一個階段是召回,第二個階段是排序。因為個性化推薦需要給每個用戶展現不同的信息流或者物品流,而對于每個用戶來說,可供推薦的物品,在具備一定規模的公司里,是百萬到千萬級別,甚至上億。所以對于每一個用戶,如果對于千萬級別物品都使用先進的模型挨個進行排序打分,明顯速度上是算不過來的,資源投入考慮這么做也不劃算。從這里可以看出,召回階段的主要職責是:從千萬量級的候選物品里,采取簡單模型將推薦物品候選集合快速篩減到千級別甚至百級別,這樣將候選集合數量降下來,之后在排序階段就可以上一些復雜模型,細致地對候選集進行個性化排序。
從上面在線推薦兩階段任務的劃分,我們可以看出,召回階段因為需要計算的候選集合太大,所以要想速度快,就只能上簡單模型,使用少量特征,保證泛化能力,盡量讓用戶感興趣的物品在這個階段能夠找回來;而排序階段核心目標是要精準,因為它處理的物品數據量小,所以可以采用盡可能多的特征,使用比較復雜的模型,一切以精準為目標。
多路召回怎么做?
目前工業界推薦系統的召回階段一般是怎么做的呢?可以用一句江湖氣很重的話來總結,請您系好安全帶坐穩,怕嚇到您,這句話就是:“一只穿云箭,千軍萬馬來相見”。聽起來霸氣十足是吧?我估計看過古惑仔電影的都熟悉這句話,黑幫集結打群架的時候喜歡引用這句名言,以增加氣勢,自己給自己打氣。如果和推薦系統對應起來理解,這里的“穿云箭”就是召回系統,而千軍萬馬就是各路花式召回策略。

目前工業界的推薦系統,在召回階段,一般都采取多路召回策略。上圖展示了一個簡化版本的例子,以微博信息流排序為例,不同業務召回路數不太一樣,但是常用的召回策略,基本都會包含,比如興趣標簽,興趣Topic,興趣實體,協同過濾,熱門,相同地域等,多者幾十路召回,少者也有7/8路召回。
對于每一路召回,會拉回K條相關物料,這個K值是個超參,需要通過線上AB測試來確定合理的取值范圍。如果你對算法敏感的話,會發現這里有個潛在的問題,如果召回路數太多,對應的超參就多,這些超參組合空間很大,如何設定合理的各路召回數量是個問題。另外,如果是多路召回,這個超參往往不太可能是用戶個性化的,而是對于所有用戶,每一路拉回的數量都是固定的,這里明顯有優化空間。按理說,不同用戶也許對于每一路內容感興趣程度是不一樣的,更感興趣的那一路就應該多召回一些,所以如果能把這些超參改為個性化配置是很好的,但是多路召回策略下,雖然也不是不能做,但是即使做,看起來還是很Trick的。有什么好辦法能解決這個問題嗎?有,本文后面會講。
什么是FM模型?
什么是FM模型呢?我隱約意識到這個問題在很多人看起來好像有點過于簡單,因為一說起FM,開車的朋友們估計都熟悉,比如FM1039交通臺家喻戶曉,最近應該經常聽到交通臺這么提醒大家吧:“…春節返程高峰,北京市第三交通委提醒您:道路千萬條,安全第一條……”
一想到有可能很多人這么理解FM,我的眼淚就不由自主流了下來,同時對他們在心理上有種莫名的親切感,為什么呢?不是說“縮寫不規范,親人兩行淚”么。下面我鄭重地給各位介紹下,FM英文全稱是“Factorization Machine”,簡稱FM模型,中文名“因子分解機”。
FM模型其實有些年頭了,是2010年由Rendle提出的,但是真正在各大廠大規模在CTR預估和推薦領域廣泛使用,其實也就是最近幾年的事。
FM模型比較簡單,網上介紹的內容也比較多,細節不展開說它了。不過我給個個人判斷:我覺得FM是推薦系統工程師應該熟練掌握和應用的必備算法,即使你看很多DNN版本的排序模型,你應該大多數情況會看到它的影子,原因其實很簡單:特征組合對于推薦排序是非常非常重要的,而FM這個思路已經很簡潔優雅地體現了這個思想了(主要是二階特征組合)。
DNN模型一樣離不開這個特點,而MLP結構是種低效率地捕獲特征組合的結構,所以即使是深度模型,目前一樣還離不開類似FM這個能夠直白地直接去組合特征的部分。這是你會反復發現它的原因所在,當然也許是它本人,也許不一定是它本人,但是一定是它的變體。
既然談到這里了,那順手再多談談推薦排序模型。目前具備實用化價值的DNN版本的CTR模型一般采用MLP結構,看著遠遠落后CV/NLP的特征抽取器的發展水平,很容易讓人產生如下感覺:CTR的DNN模型還處于深度學習原始社會階段。那這又是為什么呢?因為CNN的特性天然不太適合推薦排序這個場景(為什么?您可以思考一下。
為了預防某些具備某種獨特個性特征的同學拿個別例子說事情,我先提一句:請不要跟我說某個已有的看上去比較深的CNN CTR模型,你自己試過效果如何再來說。這算是我的預防性回懟或者是假設性回懟,哈哈)。RNN作為捕捉用戶行為序列,利用時間信息的輔助結構還行,但是也不太適合作為CTR預估或者推薦排序的主模型(為什么?您可以思考一下,關于這點,我的看法以后有機會會提)。
好像剩下的選擇不多了(Transformer是很有希望的,去年年中左右,我覺得Self attention應該是個能很好地捕捉特征組合(包括二階/三階…多階)的工具,于是,我們微博也嘗試過用self attention和transformer作為CTR的主體排序模型,非業務數據測試的,當時測試效果和DeepFM等主流模型效果差不太多。我現在回頭看,很可能是哪些細節沒做對,當時覺得沒有特別的效果優勢,于是沒再繼續嘗試這個思路。
當然貌似18年下半年已經冒出幾篇用Transformer做CTR排序模型的論文了,我個人非常看好這個CTR模型進化方向),于是剩下的選擇貌似只有MLP了,意思是:對于CTR或者推薦排序領域來說,不是它不想進入模型共產主義階段,是大門關得太緊,它進不去,于是只能在MLP這個門檻徘徊。
在深度學習大潮下,從模型角度看,確實跟很多領域比,貌似推薦領域遠遠落后,這個是事實。我覺得主要原因是它自身的領域特點造成的,它可能需要打造適合自身特點的DNN排序模型。就像圖像領域里有Resnet時刻,NLP里面有Bert時刻,我覺得推薦排序深度模型目前還沒有,現在和未來也需要這個類似的高光時刻,而這需要一個針對它特性改造出的新結構,對此我是比較樂觀的,我預感這個時刻一年之內還無法出現,但是很可能已經在路上,距離我們不遠了。
又說遠了,本來我們主題是召回,說到排序模型里去了,我往主車道走走。上面本來是要強調好好學好好用FM模型的。下面我從兩個角度來簡單介紹下FM模型,一個角度是從特征組合模型的進化角度來講;另外一個角度從協同過濾模型的進化角度來講。FM模型就處于這兩類模型進化的交匯口。
從LR到SVM再到FM模型
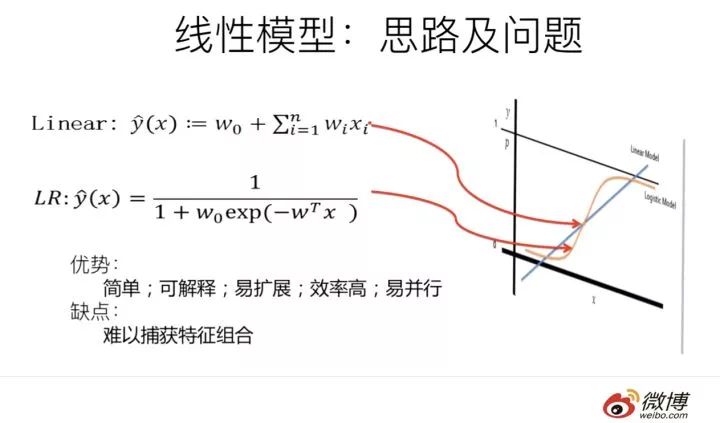
LR模型是CTR預估領域早期最成功的模型,大多工業推薦排序系統采取LR這種“線性模型+人工特征組合引入非線性”的模式。因為LR模型具有簡單方便易解釋容易上規模等諸多好處,所以目前仍然有不少實際系統仍然采取這種模式。但是,LR模型最大的缺陷就是人工特征工程,耗時費力費人力資源,那么能否將特征組合的能力體現在模型層面呢?

其實想達到這一點并不難,如上圖在計算公式里加入二階特征組合即可,任意兩個特征進行組合,可以將這個組合出的特征看作一個新特征,融入線性模型中。而組合特征的權重可以用來表示,和一階特征權重一樣,這個組合特征權重在訓練階段學習獲得。其實這種二階特征組合的使用方式,和多項式核SVM是等價的。
雖然這個模型看上去貌似解決了二階特征組合問題了,但是它有個潛在的問題:它對組合特征建模,泛化能力比較弱,尤其是在大規模稀疏特征存在的場景下,這個毛病尤其突出,比如CTR預估和推薦排序,這些場景的最大特點就是特征的大規模稀疏。所以上述模型并未在工業界廣泛采用。那么,有什么辦法能夠解決這個問題嗎?
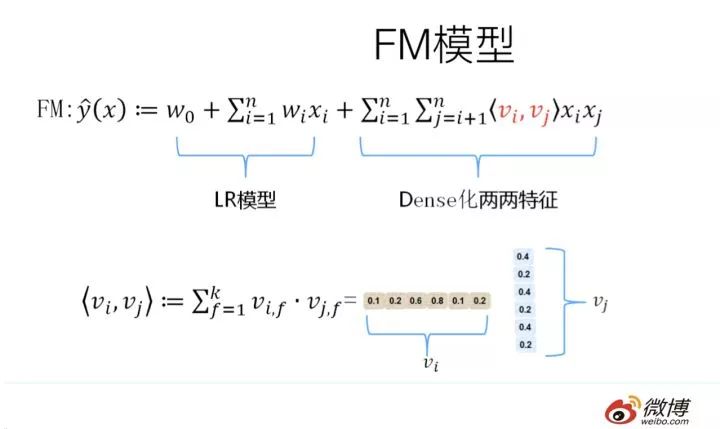
于是,FM模型此刻可以閃亮登場了。如上圖所示,FM模型也直接引入任意兩個特征的二階特征組合,和SVM模型最大的不同,在于特征組合權重的計算方法。FM對于每個特征,學習一個大小為k的一維向量,于是,兩個特征和的特征組合的權重值,通過特征對應的向量和的內積來表示。
這本質上是在對特征進行embedding化表征,和目前非常常見的各種實體embedding本質思想是一脈相承的,但是很明顯在FM這么做的年代(2010年),還沒有現在能看到的各種眼花繚亂的embedding的形式與概念。所以FM作為特征embedding,可以看作當前深度學習里各種embedding方法的老前輩。
當然,FM這種模式有它的前輩模型嗎?有,等會會談。其實,和目前的各種深度DNN排序模型比,它僅僅是少了2層或者3層MLP隱層,用來直接對多階特征非線性組合建模而已,其它方面基本相同。
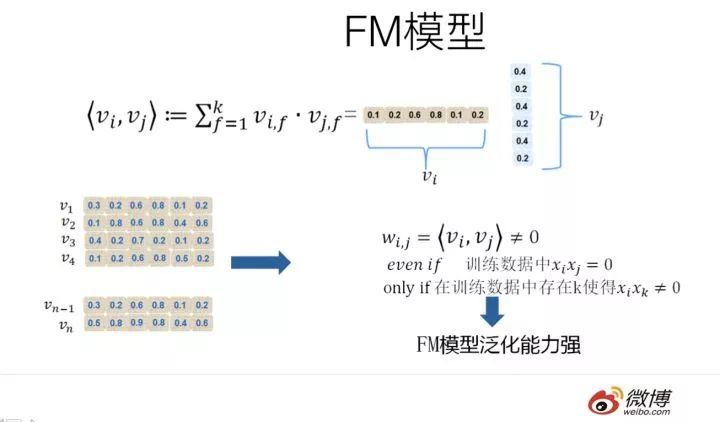
那么為什么說FM的這種特征embedding模式,在大規模稀疏特征應用環境下比較好用?為什么說它的泛化能力強呢?參考上圖說明。即使在訓練數據里兩個特征并未同時在訓練實例里見到過,意味著一起出現的次數為0,如果換做SVM的模式,是無法學會這個特征組合的權重的。
但是因為FM是學習單個特征的embedding,并不依賴某個特定的特征組合是否出現過,所以只要特征和其它任意特征組合出現過,那么就可以學習自己對應的embedding向量。于是,盡管這個特征組合沒有看到過,但是在預測的時候,如果看到這個新的特征組合,因為和都能學會自己對應的embedding,所以可以通過內積算出這個新特征組合的權重。這是為何說FM模型泛化能力強的根本原因。
其實本質上,這也是目前很多花樣的embedding的最核心特點,就是從0/1這種二值硬核匹配,切換為向量軟匹配,使得原先匹配不上的,現在能在一定程度上算密切程度了,具備很好的泛化性能。
從MF到FM模型
FM我們大致應該知道是怎么個意思了,這里又突然冒出個MF,長得跟FM貌似還有點像,那么MF又是什么呢?它跟FM又有什么關系?
請跟我念:“打東邊來了個FM,手里提著一斤撻嘛;打西邊來了個MF,腰里別著一個喇叭;提著一斤撻嘛的FM想要別著喇叭的MF腰里的喇叭……..”你要是能不打磕絆一遍念下來的話………你以為你就理解它們的錯綜復雜的關系了是嗎?不,你就可以去學說相聲了……
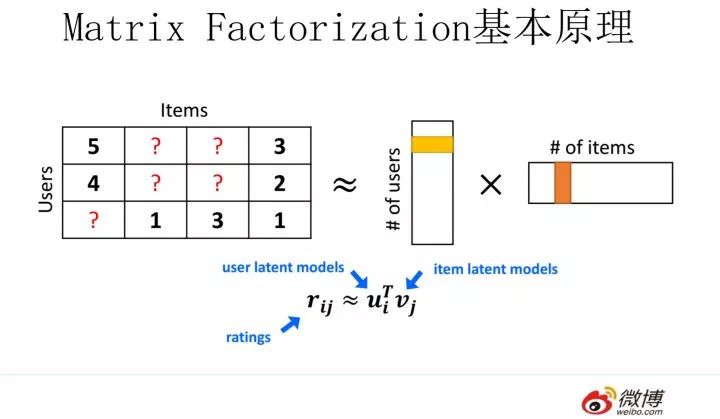
MF(Matrix Factorization,矩陣分解)模型是個在推薦系統領域里資格很深的老前輩協同過濾模型了。核心思想是通過兩個低維小矩陣(一個代表用戶embedding矩陣,一個代表物品embedding矩陣)的乘積計算,來模擬真實用戶點擊或評分產生的大的協同信息稀疏矩陣,本質上是編碼了用戶和物品協同信息的降維模型。
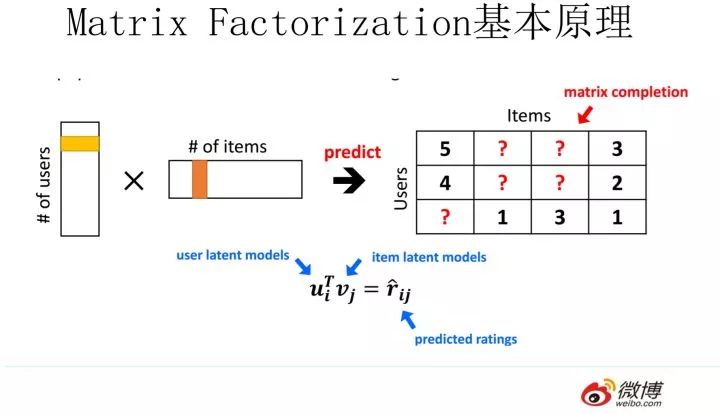
當訓練完成,每個用戶和物品得到對應的低維embedding表達后,如果要預測某個對的評分的時候,只要它們做個內積計算,這個得分就是預測得分。看到這里,讓你想起了什么嗎?
身為推薦算法工程師,我假設你對它還是比較熟悉的,更多的就不展開說了,相關資料很多,我們重點說MF和FM的關系問題。
MF和FM不僅在名字簡稱上看著有點像,其實他們本質思想上也有很多相同點。那么,MF和FM究竟是怎樣的關系呢?
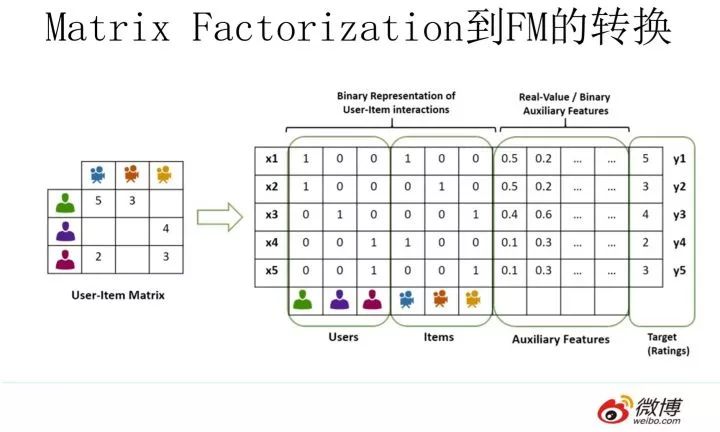
本質上,MF模型是FM模型的特例,MF可以被認為是只有User ID 和Item ID這兩個特征Fields的FM模型,MF將這兩類特征通過矩陣分解,來達到將這兩類特征embedding化表達的目的。
而FM則可以看作是MF模型的進一步拓展,除了User ID和Item ID這兩類特征外,很多其它類型的特征,都可以進一步融入FM模型里,它將所有這些特征轉化為embedding低維向量表達,并計算任意兩個特征embedding的內積,就是特征組合的權重,如果FM只使用User ID 和Item ID,你套到FM公式里,看看它的預測過程和MF的預測過程一樣嗎?
從誰更早使用特征embedding表達這個角度來看的話,很明顯,和FM比起來,MF才是真正的前輩,無非是特征類型比較少而已。而FM繼承了MF的特征embedding化表達這個優點,同時引入了更多Side information作為特征,將更多特征及Side information embedding化融入FM模型中。所以很明顯FM模型更靈活,能適應更多場合的應用范圍。
鑒于MF和FM以上錯綜復雜剪不斷理還亂的關系,我推論出下面的觀點(個人意見):
其一:在你有使用MF做協同過濾的想法的時候,暫時壓抑一下這種沖動,可以優先考慮引入FM來做的,而非傳統的MF,因為可以在實現等價功能的基礎上,很方便地融入其它任意你想加入的特征,把手頭的事情做得更豐富多彩。
其二:從實際大規模數據場景下的應用來講,在排序階段,絕大多數只使用ID信息的模型是不實用的,沒有引入Side Information,也就是除了User ID/Item ID外的很多其它可用特征的模型,是不具備實戰價值的。原因很簡單,大多數真實應用場景中,User/Item有很多信息可用,而協同數據只是其中的一種,引入更多特征明顯對于更精準地進行個性化推薦是非常有幫助的。而如果模型不支持更多特征的便捷引入,明顯受限嚴重,很難真正實用,這也是為何矩陣分解類的方法很少看到在Ranking階段使用,通常是作為一路召回形式存在的原因。
簡單談談算法的效率問題
從FM的原始數學公式看,因為在進行二階(2-order)特征組合的時候,假設有n個不同的特征,那么二階特征組合意味著任意兩個特征都要進行交叉組合,所以可以直接推論得出:FM的時間復雜度是n的平方。但是如果故事僅僅講到這里,FM模型是不太可能如此廣泛地被工業界使用的。因為現實生活應用中的n往往是個非常巨大的特征數,如果FM是n平方的時間復雜度,那估計基本就沒人帶它玩了。
對于一個實用化模型來說,效果是否足夠好只是一個方面,計算效率是否夠高也很重要,這兩點是一個能被廣泛使用算法的一枚硬幣的兩面,缺其中任何一個可能都不能算是優秀的算法。如果在兩者之間硬要分出誰更重要的話,怎么選?
這里插入個題外話,是關于如何做選擇的。這個話題如果你深入思考的話,會發現很可能是個深奧的哲學問題。在說怎么選之前,我先復述兩則關于選擇的笑話,有兩個版本,男版和女版的。
男版是這樣的:“一個兄弟跟我說他最近很困惑,有三個姑娘在追他,一直猶豫不決,到底應該選哪個當女朋友呢?一個溫柔賢惠,一個聰明伶俐,另外一個膚白貌美。太難選…..三天后當我再次遇到他的時候,他說他做出了選擇,選了那個胸最大的!”
女版是這樣的:“一個姐妹跟我說她很困惑,最近有三個優秀的男人在追她,一直猶豫不決,到底應該嫁給誰呢?一個努力上進,一個高大帥氣,另外一個脾氣好顧家。實在太難選…..三天后當我再次遇到她的時候,她說她做出了選擇,選了那個最有錢的!”
參考這個模版,算法選擇版應該是這樣的:“一個算法工程師一直猶豫不決該選哪個模型去上線,他有三個優秀算法可選,一個算法理論優雅;一個算法效果好;另外一個算法很時髦,實在太難做決定…..三天后當我再遇見他的時候,他說他們算法總監讓他上了那個跑得最快的!”
怎么樣?生活或者工作中的選擇確實是個很玄妙的哲學問題吧?這個算法版的關于選擇的笑話,應該已經回答了上面那個還沒給答案的問題了吧?在數據量特別大的情況下,如果在效果好和速度快之間做選擇,很多時候跑得快的簡單模型會勝出,這是為何LR模型在CTR預估領域一直被廣泛使用的原因。
而FFM模型則是反例,我們在幾個數據集合上測試過,FFM模型作為排序模型,效果確實是要優于FM模型的,但是FFM模型對參數存儲量要求太多,以及無法能做到FM的運行效率,如果中小數據規模做排序沒什么問題,但是數據量一旦大起來,對資源和效率的要求會急劇升高,這是嚴重阻礙FFM模型大規模數據場景實用化的重要因素。
再順手談談DNN排序模型,現在貌似看著有很多版本的DNN排序模型,但是考慮到上面講的運算效率問題,你會發現太多所謂效果好的模型,其實不具備實用價值,算起來太復雜了,效果好得又很有限,超大規模訓練或者在線 Serving速度根本跟不上。除非,你們公司有具備相當強悍實力的工程團隊,能夠進行超大數據規模下的大規模性能優化,那當我上面這句話沒說。
我對排序模型,如果你打算推上線真用起來的話,建議是,沿著這個序列嘗試:FM-->DeepFM。你看著路徑有點短是嗎?確實比較短。如果DeepFM做不出效果,別再試著去嘗試更復雜的模型了,還是多從其它方面考慮考慮優化方案為好。有些復雜些的模型,也許效果確實好一些,在個別大公司也許真做上線了,但是很可能效果好不是算法的功勞,是工程能力強等多個因素共同導致的,人家能做,你未必做的了。
至于被廣泛嘗試的Wide &Deep,我個人對它有偏見,所以直接被我跳過了。當然,如果你原始線上版本是LR,是可以直接先嘗試Wide&Deep的,但是即使如此,要我做升級方案,我給的建議會是這個序列:LR—>FM-->DeepFM—>干點其他的。
如何優化FM的計算效率
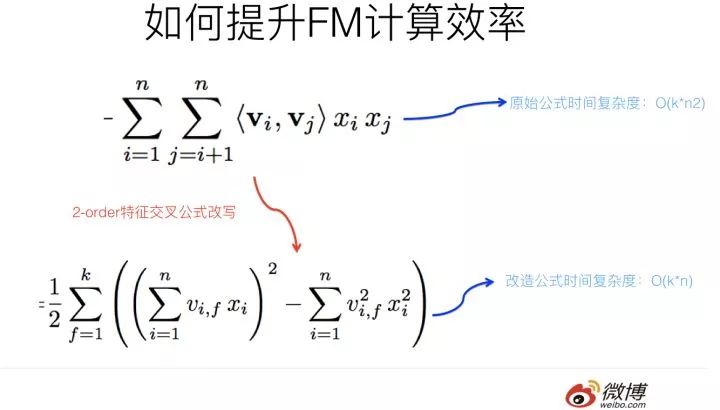
再說回來,FM如今被廣泛采用并成功替代LR模型的一個關鍵所在是:它可以通過數學公式改寫,把表面貌似是的復雜度降低到,其中n是特征數量,k是特征的embedding size,這樣就將FM模型改成了和LR類似和特征數量n成線性規模的時間復雜度了,這點非常好。
那么,如何改寫原始的FM數學公式,讓其復雜度降下來呢?因為原始論文在推導的時候沒有給出詳細說明,我相信不少人看完估計有點懵,所以這里簡單解釋下推導過程,數學公式帕金森病患者可以直接跳過下面內容往后看,這并不影響你理解本文的主旨。
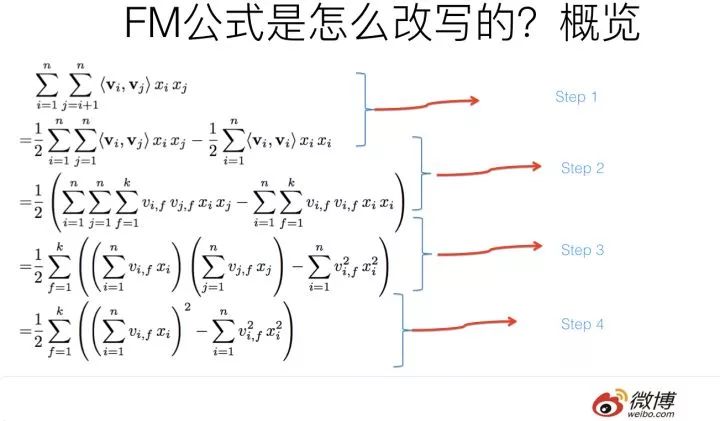
上圖展示了整個推導過程,我相信如果數學基礎不太扎實的同學看著會有點頭疼,轉換包括四個步驟,下面分步驟解釋下。

第一個改寫步驟及為何這么改寫參考上圖,比較直觀,不解釋了。
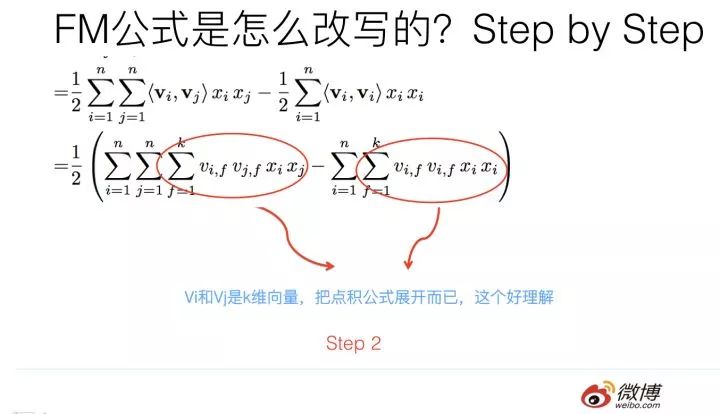
第二步轉換更簡單,更不用解釋了。
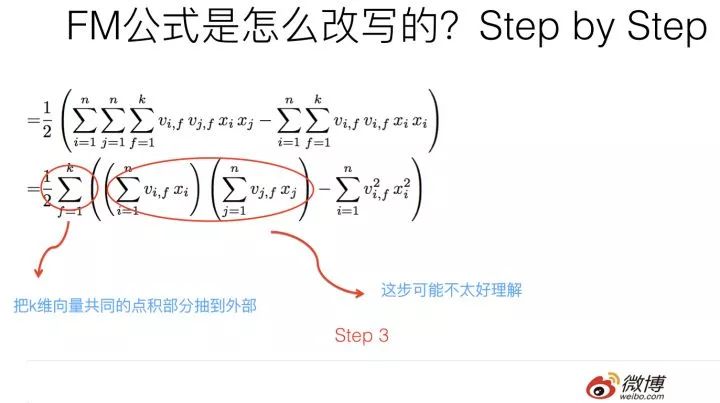
第三步轉換不是太直觀,可能需要簡單推導一下,很多人可能會卡在這一步,所以這里解釋解釋。
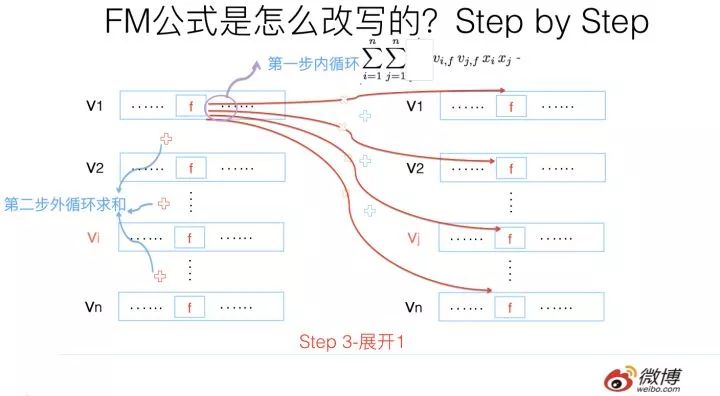
其實吧,如果把k維特征向量內積求和公式抽到最外邊后,公式就轉成了上圖這個公式了(不考慮最外邊k維求和過程的情況下)。它有兩層循環,內循環其實就是指定某個特征的第f位(這個f是由最外層那個k指定的)后,和其它任意特征對應向量的第f位值相乘求和;而外循環則是遍歷每個的第f位做循環求和。這樣就完成了指定某個特征位f后的特征組合計算過程。最外層的k維循環則依此輪循第f位,于是就算完了步驟三的特征組合。

對上一頁公式圖片展示過程用公式方式,再一次改寫(參考上圖),其實就是兩次提取公共因子而已,這下應該明白了吧?要是還不明白,那您的診斷結果是數學公式帕金森晚期,跟我一個毛病,咱倆病友同病相憐,我也沒轍了。

第四步公式變換,意思參考上圖,這步也很直白,不解釋。
于是,通過上述四步的公式改寫,可以看出在實現FM模型時,時間復雜度就降低了,而雖說看上去n還有點大,但是其實真實的推薦數據的特征值是極為稀疏的,就是說大量xi其實取值是0,意味著真正需要計算的特征數n是遠遠小于總特征數目n的,無疑這會進一步極大加快FM的運算效率。
這里需要強調下改寫之后的FM公式的第一個平方項,怎么理解這個平方項的含義呢?這里其實蘊含了后面要講的使用FM模型統一多路召回的基本思想,所以這里特殊提示一下。
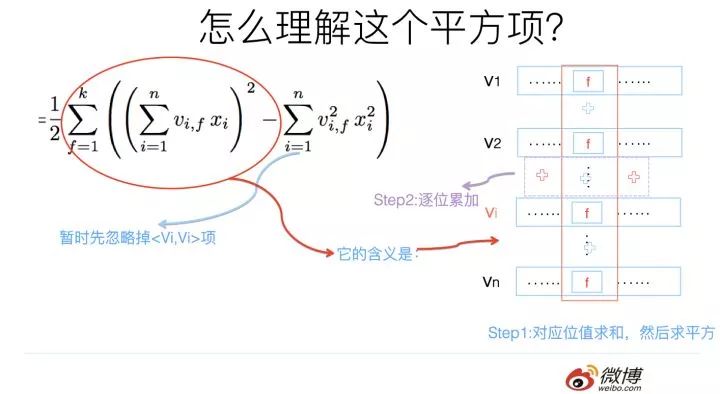
參考上圖,你體會下這個計算過程。它其實等價于什么?
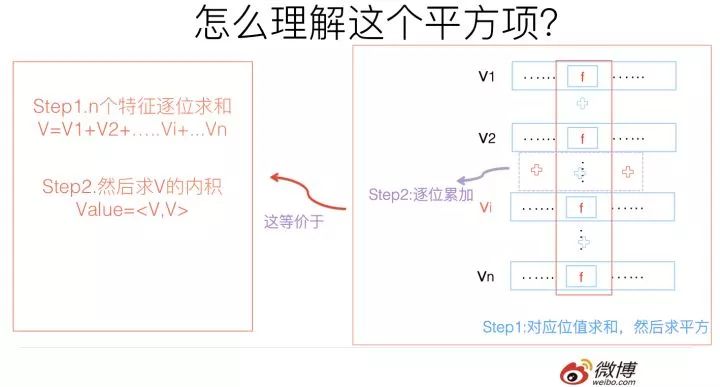
這個平方項,它等價于將FM的所有特征項的embedding向量累加,之后求內積。我再問下之前問過的問題:“我們怎樣利用FM模型做統一的召回?”這個平方項的含義對你有啟發嗎?你可以仔細想想它們之間的關聯。
如何利用FM模型做統一的召回模型?
上文書提到過,目前工業界推薦系統在召回階段,大多數采用了多路召回策略,比如典型的召回路有:基于用戶興趣標簽的召回;基于協同過濾的召回;基于熱點的召回;基于地域的召回;基于Topic的召回;基于命名實體的召回等等,除此外還有很多其它類型的召回路。
現在我們來探討下第一個問題:在召回階段,能否用一個統一的模型把多路召回招安?就是說改造成利用單個模型,單路召回的模式?具體到這篇文章,就是說能否利用FM模型來把多路召回統一起來?
在回答上述問題之前,我估計你會提出疑問:目前大家用多路召回用的好好的,為啥要多此一舉,用一個模型把多路召回統一起來呢?這個問題非常好,我們確實應該先看這么做的必要性。
統一召回和多路召回優缺點比較
我們先來說明下統一召回和多路召回各自的優缺點,我覺得使用統一召回模式,相對多路召回有如下優點:
首先,采用多路召回,每一路召回因為采取的策略或者模型不同,所以各自的召回模型得分不可比較,比如利用協同過濾召回找到的候選Item得分,與基于興趣標簽這一路召回找到的候選Item得分,完全是不可比較的。這也是為何要用第二階段Ranking來將分數統一的原因。而如果采取統一的召回模型,比如FM模型,那么不論候選項Item來自于哪里,它們在召回階段的得分是完全可比的。
其次,貌似在目前“召回+Ranking”兩階段推薦模型下,多路召回分數不可比這個問題不是特別大,因為我們可以依靠Ranking階段來讓它們可比即可。但是其實多路召回分數不可比會直接引發一個問題:對于每一路召回,我們應該返回多少個Item是合適的呢?如果在多路召回模式下,這個問題就很難解決。既然分數不可比,那么每一路召回多少候選項K就成為了超參,需要不斷調整這個參數上線做AB測試,才能找到合適的數值。
而如果召回路數特別多,于是每一路召回帶有一個超參K,就是這一路召回多少條候選項,這樣的超參組合空間是非常大的。所以到底哪一組超參是最優的,就很難定。其實現實情況中,很多時候這個超參都是拍腦袋上線測試,找到最優的超參組合概率是很低的。
而如果假設我們統一用FM模型來做召回,其實就不存在上面這個問題。這樣,我們可以在召回階段做到更好的個性化,比如有的用戶喜歡看熱門的內容,那么熱門內容在召回階段返回的比例就高,而其它內容返回比例就低。所以,可以認為各路召回的這組超參數就完全依靠FM模型調整成個性化的了,很明顯這是使用單路單模型做召回的一個特別明顯的好處。
再次,對于工業界大型的推薦系統來說,有極大的可能做召回的技術人員和做Ranking的技術人員是兩撥人。這里隱含著一個潛在可能會發生的問題,比如召回階段新增了一路召回,但是做Ranking的哥們不知道這個事情,在Ranking的時候沒有把能體現新增召回路特性的特征加到Ranking階段的特征中。這樣體現出來的效果是:新增召回路看上去沒什么用,因為即使你找回來了,而且用戶真的可能點擊,但是在排序階段死活排不上去。
也就是說,在召回和排序之間可能存在信息鴻溝的問題,因為目前召回和排序兩者的表達模式差異很大,排序階段以特征為表達方式,召回則以“路/策略/具體模型”為表達方式,兩者之間差異很大,是比較容易產生上述現象的。
但是如果我們采用FM模型來做召回的話,新增一路召回就轉化為新增特征的問題,而這一點和Ranking階段在表現形式上是相同的,對于召回和排序兩個階段來說,兩者都轉化成了新增特征問題,所以兩個階段的改進語言體系統一,就不太容易出現上述現象。
上面三點,是我能想到的采用統一召回模型,相對多路召回的幾個好處。但是是不是多路召回一定不如統一召回呢?其實也不是,很明顯多路召回這種策略,上線一個新召回方式比較靈活,對線上的召回系統影響很小,因為不同路召回之間沒有耦合關系。但是如果采用統一召回,當想新增一種召回方式的時候,表現為新增一種或者幾種特征,可能需要完全重新訓練一個新的FM模型,整個召回系統重新部署上線,靈活性比多路召回要差。
上面講的是必要性,講完了必要性,我們下面先探討如何用FM模型做召回,然后再討論如何把多路召回改造成單路召回,這其實是兩個不同的問題。
如何用FM模型做召回模型
如果要做一個實用化的統一召回模型,要考慮的因素有很多,比如Context上下文特征怎么處理,實時反饋特征怎么加入等。為了能夠更清楚地說明,我們先從極簡模型說起,然后逐步加入必須應該考慮的元素,最后形成一個實用化的統一召回模型。
不論是簡化版本FM召回模型,還是復雜版本,首先都需要做如下兩件事情:
第一,離線訓練。這個過程跟在排序階段采用FM模型的離線訓練過程是一樣的,比如可以使用線上收集到的用戶點擊數據來作為訓練數據,線下訓練一個完整的FM模型。在召回階段,我們想要的其實是:每個特征和這個特征對應的訓練好的embedding向量。這個可以存好待用。
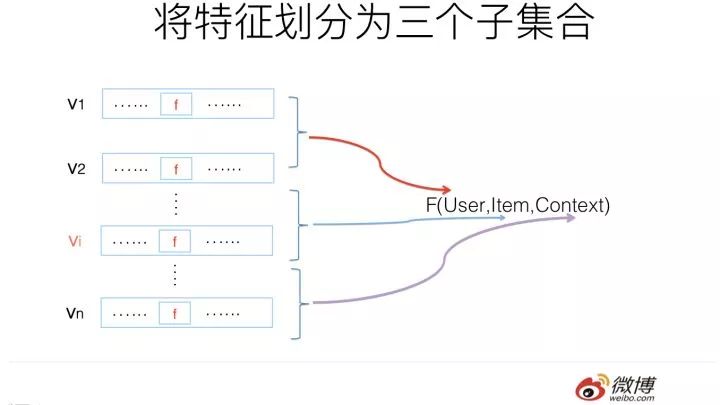
第二,如果將推薦系統做個很高層級的抽象的話,可以表達成學習如下形式的映射函數:
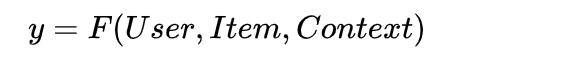
意思是,我們利用用戶(User)相關的特征,物品(Item)相關的特征,以及上下文特征(Context,比如何時何地用的什么牌子手機登陸等等)學習一個映射函數F。學好這個函數后,當以后新碰到一個Item,我們把用戶特征,物品特征以及用戶碰到這個物品時的上下文特征輸入F函數,F函數會告訴我們用戶是否對這個物品感興趣。如果他感興趣,就可以把這個Item作為推薦結果推送給用戶。
說了這么多,第二個我們需要做的事情是:把特征劃分為三個子集合,用戶相關特征集合,物品相關特征集合以及上下文相關的特征集合。而用戶歷史行為類特征,比如用戶過去點擊物品的特征,可以當作描述用戶興趣的特征,放入用戶相關特征集合內。至于為何要這么劃分,后面會講。
做完上述兩項基礎工作,我們可以試著用FM模型來做召回了。
極簡版FM召回模型
我們先來構建一個極簡的FM召回模型,首先,我們先不考慮上下文特征,晚點再說。
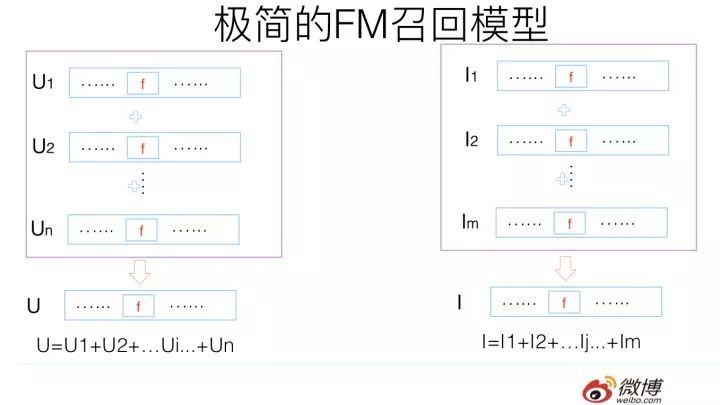
第一步,對于某個用戶,我們可以把屬于這個用戶子集合的特征,查詢離線訓練好的FM模型對應的特征embedding向量,然后將n個用戶子集合的特征embedding向量累加,形成用戶興趣向量U,這個向量維度和每個特征的維度是相同的。
類似的,我們也可以把每個物品,其對應的物品子集合的特征,查詢離線訓練好的FM模型對應的特征embedding向量,然后將m個物品子集合的特征embedding向量累加,形成物品向量I,這個向量維度和每個特征的維度也是是相同的。
對于極簡版FM召回模型來說,用戶興趣向量U可以離線算好,然后更新線上的對應內容;物品興趣向量I可以類似離線計算或者近在線計算,問題都不大。
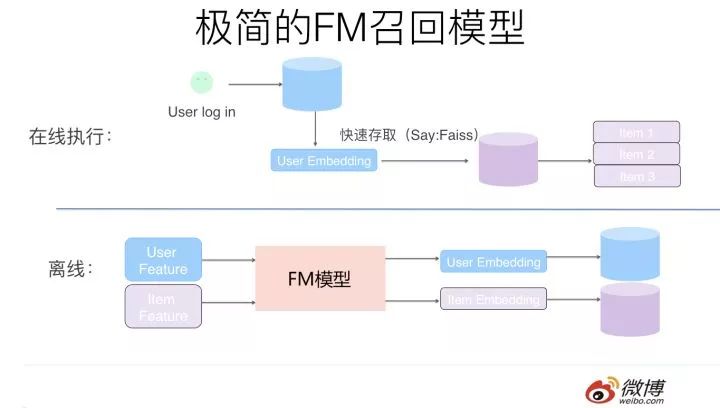
第二步,對于每個用戶以及每個物品,我們可以利用步驟一中的方法,將每個用戶的興趣向量離線算好,存入在線數據庫中比如Redis(用戶ID及其對應的embedding),把物品的向量逐一離線算好,存入Faiss(Facebook開源的embedding高效匹配庫)數據庫中。
當用戶登陸或者刷新頁面時,可以根據用戶ID取出其對應的興趣向量embedding,然后和Faiss中存儲的物料embedding做內積計算,按照得分由高到低返回得分Top K的物料作為召回結果。提交給第二階段的排序模型進行進一步的排序。這里Faiss的查詢速度至關重要,至于這點,后面我們會單獨說明。
這樣就完成了一個極簡版本FM召回模型。但是這個版本的FM召回模型存在兩個問題。
問題一:首先我們需要問自己,這種累加用戶embedding特征向量以及累加物品embedding特征向量,之后做向量內積。這種算法符合FM模型的原則嗎?和常規的FM模型是否等價?
我們來分析一下。這種做法其實是在做用戶特征集合U和物品特征集合I之間兩兩特征組合,是符合FM的特征組合原則的,考慮下列公式是否等價就可以明白了:
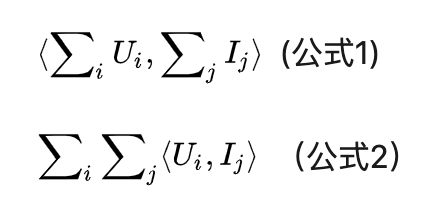
其實兩者是等價的,建議您可以推導一下(這其實不就是上面在介紹FM公式改寫的第三步轉換嗎?當然,跟完全版本的FM比,我們沒有考慮U和I特征集合內部任意兩個特征的組合,等會會說這個問題)。
也可以這么思考問題:在上文我們說過,FM為了提升計算效率,對公式進行了改寫,改寫后的高效計算公式的第一個平方項其實等價于:把所有特征embedding向量逐位累加成一個求和向量V,然后自己和自己做個內積操作
而上面描述的方法,和標準的FM的做法其實是一樣的,區別無非是將特征集合劃分為兩個子集合U和I,分別代表用戶相關特征及物品相關特征。而上述做法其實等價于在用戶特征和物品特征之間做兩兩特征組合,只是少了U內部之間特征,及I內部特征之間的特征組合而已。
一般而言,其實我們不需要做U內部特征之間以及I內部特征之間的特征組合,對最終效果影響很小。于是,沿著這個思考路徑,我們也可以推導出上述做法基本和FM標準計算過程是等價的。
第二個問題是:這個版本FM是個簡化版本模型,因為它沒考慮場景上下文特征,那么如果再將上下文特征引入,此時應該怎么做呢?
加入場景上下文特征
上面敘述了如何根據FM模型做一個極簡版本的召回模型,之所以說極簡,因為我們上面說過,抽象的推薦系統除了用戶特征及物品特征外,還有一類重要特征,就是用戶發生行為的場景上下文特征(比如什么時間在什么地方用的什么設備在刷新),而上面版本的召回模型并沒有考慮這一塊。
之所以把上下文特征單獨拎出來,是因為它有自己的特點,有些上下文特征是近乎實時變化的,比如刷新微博的時間,再比如對于美團嘀嘀這種對地理位置特別敏感的應用,用戶所處的地點可能隨時也在變化,而這種變化在召回階段就需要體現出來。所以,上下文特征是不太可能像用戶特征離線算好存起來直接使用的,而是用戶在每一次刷新可能都需要重新捕獲當前的特征值。動態性強是它的特點。
而考慮進來上下文特征,如果我們希望構造和標準的FM等價的召回模型,就需要多考慮兩個問題:
問題一:既然部分上下文特征可能是實時變化的,無法離線算好,那么怎么融入上文所述的召回計算框架里?
問題二:我們需要考慮上下文特征C和用戶特征U之間的特征組合,也需要考慮C和物品特征I之間的特征組合。上下文特征有時是非常強的特征。那么,如何做能夠將這兩對特征組合考慮進來呢?
我們可以這么做:
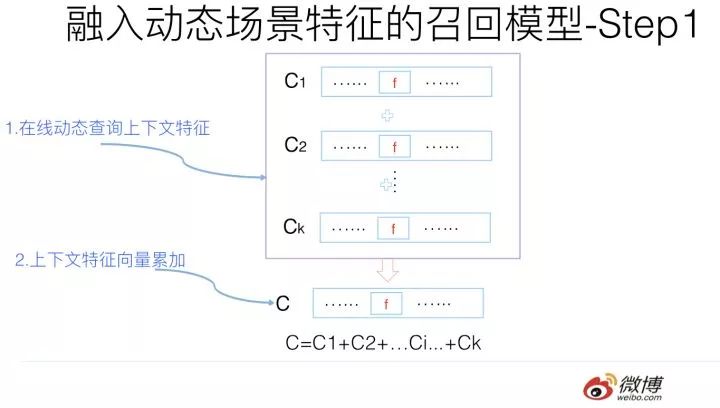
首先,由于上下文特征的動態性,所以給定用戶UID后,可以在線查詢某個上下文特征對應的embedding向量,然后所有上下文向量求和得到綜合的上下文向量C。這個過程其實和U及I的累加過程是一樣的,區別無非是上下文特征需要在線實時計算。而一般而言,場景上下文特征數都不多,所以在線計算,速度方面應可接受。
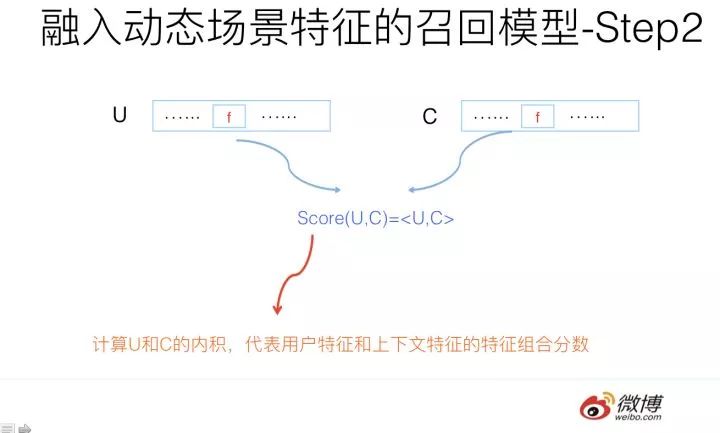
然后,將在線算好的上下文向量C和這個用戶的事先算好存起來的用戶興趣向量U進行內積計算Score=
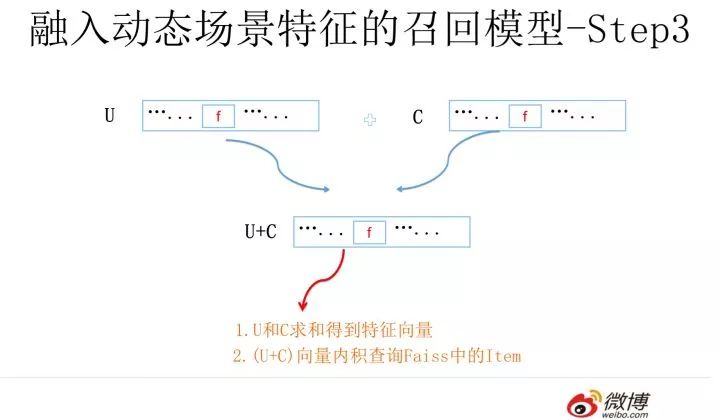
再然后,將U和C向量累加求和,利用(U+C)去Faiss通過內積方式取出Top K物品,這個過程和極簡版是一樣的,無非查詢向量由U換成了(U+C)。通過這種方式取出的物品同時考慮到了用戶和物品的特征組合
假設返回的Top K物品都帶有內積的得分Score1,再考慮上一步
于是我們通過這種手段,構造出了一個完整的FM召回模型。這個召回模型通過構造user embedding,Context embedding和Item embedding,以及充分利用類似Faiss這種高效embedding計算框架,就構造了高效執行的和FM計算等價的召回系統。
如何將多路召回融入FM召回模型
上文所述是如何利用FM模型來做召回,下面我們討論下如何將多路召回統一到FM召回模型里來。
我們以目前不同類型推薦系統中共性的一些召回策略來說明這個問題,以信息流推薦為例子,傳統的多路召回階段通常包含以下策略:協同過濾,興趣分類,興趣標簽,興趣Topic,興趣實體,熱門物品,相同地域等。這些不同角度的召回策略都是較為常見的。
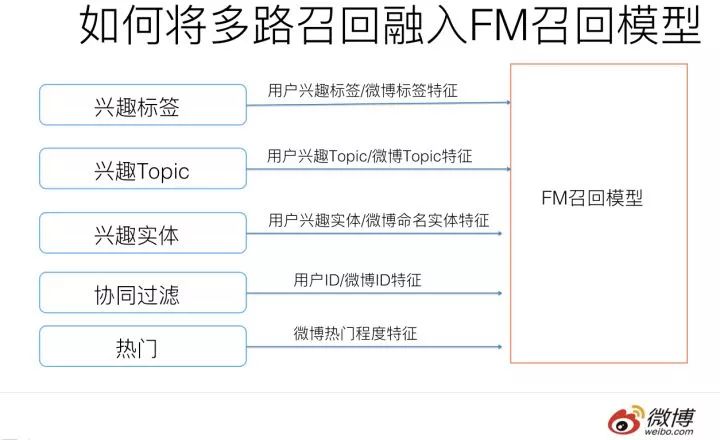
我們再將上述不同的召回路分為兩大類,可以把協同過濾作為一類,其它的作為一類,協同過濾相對復雜,我們先說下其它類別。
對于比如興趣分類,興趣標簽,熱門,地域等召回策略,要把這些召回渠道統一到FM模型相對直觀,只需要在訓練FM模型的時候,針對每一路的特性,在用戶特征端和物品特征端新增對應特征即可。比如對于地域策略,我們可以把物品所屬地域(比如微博所提到的地域)和用戶的感興趣地域都作為特征加入FM模型即可。興趣標簽,Topic,興趣實體等都是類似的。所以大多數情況下,在多路召回模式下你加入新的一路召回,在FM統一召回策略下,對應地轉化成了新增特征的方式。
然后我們再說協同過濾這路召回。其實本質上也是將一路召回轉化為新加特征的模式。我們上文在介紹FM模型和MF模型關系的時候提到過:本質上MF模型這種典型的協同過濾策略,是FM模型的一個特例,可以看作在FM模型里只有User ID和Item ID這兩類(Fields)特征的情形。
意思是說,如果我們將user ID和Item ID作為特征放入FM模型中進行訓練,那么FM模型本身就是包含了協同過濾的思想的。當然,對于超大規模的網站,用戶以億計,物品可能也在千萬級別,如果直接把ID引入特征可能會面臨一些工程效率問題以及數據稀疏的問題。對于這個問題,我們可以采取類似在排序階段引入ID時的ID 哈希等降維技巧來進行解決。
所以綜合來看,在多路召回下的每一路召回策略,絕大多數情況下,可以在FM召回模型模式中轉化為新增特征的方式。
在具體實施的時候,可以沿著這個路徑逐步替換線上的多路召回:先用FM模型替換一路召回,線上替換掉;再新加入某路特征,這樣上線,就替換掉了兩路召回;如此往復逐漸把每一路召回統一到一個模型里。這是比較穩的一種替換方案。當然如果你是個猛人,直接用完整的FM召回模型一步替換掉線上的各路召回,也,未嘗不可。只要小流量AB測試做好也沒啥。
FM模型能否將召回和排序階段一體化
前文有述,之所以目前常見的工業推薦系統會分為召回排序兩個階段,是因為這兩個階段各司其職,職責分明。召回主要考慮泛化性并把候選物品集合數量降下來;排序則主要負責根據用戶特征/物品特征/上下文特征對物品進行精準排名。
那么,我們現在可以來審視下本文開頭提出的第二個問題了:FM模型能否將常見的兩階段模型一體化?即是否能將實用化的推薦系統通過FM召回模型簡化為單階段模型?意思是推薦系統是否能夠只保留FM召回這個模塊,扔掉后續的排序階段,FM召回按照得分排序直接作為推薦結果返回。我們可以這么做嗎?
這取決于FM召回模型是否能夠一并把原先兩階段模型的兩個職責都能承擔下來。這句話的意思是說,FM召回模型如果直接輸出推薦結果,那么它的速度是否足夠快?另外,它的精準程度是否可以跟兩階段模型相媲美?不會因為少了第二階段的專門排序環節,而導致推薦效果變差?如果上面兩個問題的答案都是肯定的,那么很明顯FM模型就能夠將現有的兩階段推薦過程一體化。
我們分頭來分析這個問題的答案:準確性和速度。先從推薦精準度來說明,因為如果精準度沒有辦法維持,那么速度再快也沒什么意義。
所以現在的第一個子問題是:FM召回模型推薦結果的質量,是否能夠和召回+排序兩階段模式接近?
我們假設一個是FM統一召回模型直接輸出排序結果;而對比模型是目前常見的多路召回+FM模型排序的配置。從上文分析可以看出,盡管FM召回模型為了速度夠快,做了一些模型的變形,但是如果對比的兩階段模型中的排序階段也采取FM模型的話,我們很容易推理得到如下結論:如果FM召回模型采用的特征和兩階段模型的FM排序模型采用相同的特征,那么兩者的推薦效果是等價的。
這意味著:只要目前的多路召回都能通過轉化為特征的方式加入FM召回模型,而且FM排序階段采用的特征在FM召回模型都采用。那么兩者推薦效果是類似的。這意味著,從理論上說,是可以把兩階段模型簡化為一階段模型的。
既然推理的結論是推薦效果可以保證,那么我們再來看第二個問題:只用FM召回模型做推薦,速度是否足夠快?
我們假設召回階段FM模型對User embedding和Item embedding的匹配過程采用Facebook的Faiss系統,其速度快慢與兩個因素有關系:
物品庫中存儲的Item數量多少,Item數量越多越慢;
embedding大小,embedding size越大,速度越慢。
微博機器學習團隊18年將Faiss改造成了分布式版本,并在業務易用性方面增加了些新功能,之前我們測試的查詢效率是:假設物品庫中存儲100萬條微博embedding數據,而embedding size=300的時候,TPS在600左右,平均每次查詢小于13毫秒。而當庫中微博數量增長到200萬條,embedding size=300的時候,TPS在400左右,平均查詢時間小于20毫秒。
這意味著如果是百萬量級的物品庫,embedding size在百級別,一般而言,通過Faiss做embedding召回速度是足夠實用化的。如果物品庫大至千萬量級,理論上可以通過增加Faiss的并行性,以及減少embedding size來獲得可以接受的召回速度。
當然,上面測試的是純粹的Faiss查詢速度,而事實上,我們需要在合并用戶特征embedding的時候,查詢用戶特征對應的embedding數據,而這塊問題也不太大,因為絕大多數用戶特征是靜態的,可以線下合并進入用戶embedding,Context特征和實時特征需要線上在線查詢對應的embedding,而這些特征數量占比不算太大,所以速度應該不會被拖得太慢。
綜上所述,FM召回模型從理論分析角度,其無論在實用速度方面,還是推薦效果方面,應該能夠承載目前“多路召回+FM排序”兩階段推薦模式的速度及效果兩方面功能,所以推論它是可以將推薦系統改造成單模型單階段模式的。
當然,上面都是分析結果,并非實測,所以不能確定實際應用起來也能達到上述理論分析的效果。
總結
最后我簡單總結一下,目前看貌似利用FM模型可以做下面兩個事情:
首先,我們可以利用FM模型將傳統的多路召回策略,改為單模型單召回的策略,傳統的新增一路召回,可以轉換為給FM召回模型新增特征的方式;其次,理論上,我們貌似可以用一個FM召回模型,來做掉傳統的“多路召回+排序”的兩項工作,可行的原因上文有分析。
這是本文的主要內容,謝謝觀看。本文開頭說過,關于統一召回模型,我打算寫一個四篇系列,后面會逐步介紹其它三類模型,它們是誰呢?它們可以用來做統一的召回模型嗎?如果能,怎么做?如果不能,又是為什么?它們可以替代掉兩階段推薦模型,一步到位做推薦嗎?這些問題的答案會是什么呢?
關于上面這一系列《走近科學》風格的問題,因為我第一遍寫完的時間比較早,過了好一陣子翻開來看,當讀到上面這些問題的時候,自己都把自己吸引住了,對著問題思考了半天。這說明什么?說明這些問題真的很有吸引力是嗎?其實不是,這只能說明過去時間太長了,連我自己都記不清這些問題的答案是什么了,哈哈。
我其實是個直率的人,要不,還是先主動劇透掉下篇文章的標題吧:
“連女神級程序媛美女看了都震驚!FFM模型居然能夠做這么大規模推薦系統的召回!”背景音樂準備配置:房東的貓之《云煙成雨》……那么,女神級程序員到底是誰?她到底有多神?她到底有多美?她到底是不是女性?預知詳情,請聽下回分解。
致謝:感謝過去一段時間內,陸續和我討論統一多路召回模型及一體化推薦模型的微博機器學習團隊的雪逸龍,黃通文,佘青云,張童,邸海波等同學,以及馮凱同學提供的Faiss性能測試數據。也許你們并不想讓自己的名字出現在這種風格的文章后邊,但是其實仔細想想,能看到這里的人估計少得可憐,所以別介意想開點,哈哈。
-
模型
+關注
關注
1文章
3279瀏覽量
48974 -
機器學習
+關注
關注
66文章
8428瀏覽量
132843 -
推薦系統
+關注
關注
1文章
43瀏覽量
10088
原文標題:推薦系統召回四模型之全能的FM模型
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
包裝印刷企業實現性生產中不需要點表工業網關部署架構是怎樣的?


工業電源應用提供最佳整體效率 工業級一體成型電感CSEG系列

【書籍評測活動NO.53】鴻蒙操作系統設計原理與架構
工業能耗在線監測系統應用
請問PCM3070的pin18(REF)的電壓是如何產生的,3070內部的電源架構是怎樣的?
車載以太網的整體架構解析


智慧部隊建設整體解決方案
一體式IO與分布式IO:工業控制系統的兩種架構

基于FPGA的CCD工業相機系統設計
龍芯CPU統一系統架構規范及參考設計下載
MySQL的整體邏輯架構
智慧工地管理系統平臺架構
工業機器人系統集成整體解決方案商中設智能在新三板正式掛牌





 工商網監
工商網監
評論