 自然語言的語義表示學習方法與應用
自然語言的語義表示學習方法與應用
引言
近年來,以深度學習為代表的表示學習技術在語音識別、圖像分析和自然語言處理(NLP)領域獲得了廣泛關注。表示學習旨在將研究對象的語義信息表示為低維稠密實值向量。表示學習得到的低維向量表示是一種分布式表示,孤立地看向量中的每一維,都沒有明確對應的含義;而綜合各維形成一個向量,則能夠表示對象的語義信息。
與更簡單的獨熱(one-hot)表示方法相比,表示學習的向量維度較低,有助于提高計算效率,同時能夠充分利用對象間的語義信息,從而有效緩解數據稀疏問題。由于表示學習的這些優點,最近出現了大量關于單詞、短語、實體、句子、文檔和社會網絡的表示學習研究。
1
自然語言的詞表示方法
在NLP 中,文本表示是一個極為關鍵的問題。最初,詞袋模型是最常用的文本表示模型之一。隨著深度神經網絡的興起,人們提出了一種新的獲得詞向量的詞嵌入(Word Embedding)方法[1-3],以解決詞匯表過大帶來的“維度爆炸”問題。詞和句子的嵌入已成為所有基于深度學習的NLP系統的重要組成部分,它們在固定長度的稠密向量中編碼單詞和句子,從而大幅度提高神經網絡處理文本數據的能力。詞向量的獲取方式可以大體分為基于統計的方法(例如基于共現矩陣、SVD)和基于語言模型[4-5] 的方法兩類。2013 年,Google 團隊發表了基于語言模型獲取詞向量的word2vec工具[6]。它的核心思想是通過詞的上下文得到詞的向量化表示,包括CBOW(通過附近詞預測中心詞)和Skip-gram(通過中心詞預測附近詞)兩種方法,以及負采樣和層次softmax 兩種近似訓練法。word2vec 的詞向量可以較好地表達不同詞之間的相似和類比關系,自提出后被廣泛應用在NLP任務中。進一步地,由于word2vec 的詞向量是固定不變的,不能有效地解決多義詞的問題,產生了根據上下文隨時變化詞向量的ELMO 模型[7]。該模型從深層的雙向語言模型的內部狀態學習得到詞的表示,能夠處理單詞用法中的復雜特性,以及這些用法在不同的語言上下文中的變化,從而解決了多義詞的問題。
2
自然語言的結構表示方法
在獲取句子或文檔的語義表示時,一段話的語義由其各組成部分的語義,以及它們之間的組合方法所確定[8]。由此,一些工作開始嘗試根據輸入的結構設計模型的結構。比如卷積神經網絡(CNN)以n-gram作為基本單位建立句子表示[9-10]。而遞歸神經網絡(Recursive Neural Network) 則根據輸入的樹結構構建句子的表示[11-12]。此外,循環神經網絡(RNN)及各種改進(如長短時記憶網絡(LSTM))被證明是有效的句子級別表示方法[13]。在此基礎上,一些更為優越的結構增強型LSTM 和之前模型的各種組合的方法也在之后被提出。事實上,LSTM 引入一個近似線性依賴的記憶單元來存儲遠距離的信息,以解決簡單RNN 的長期依賴問題。記憶單元的存儲能力和其大小有關,增加記憶單元的大小將導致網絡參數的增加。針對這種情況,產生了注意力機制和外部記憶的改進方法。其中注意力機制[14] 是近年來在NLP 任務中被廣泛應用的一種十分有效的技術,在諸多領域都展示出了其優越性。進一步地,產生了一種只基于注意力機制對序列進行表示的Transformer 結構[15]。它摒棄了固有的定式,沒有使用任何CNN 或者RNN 的結構。Transformer 可以綜合考慮句子兩個方向的信息,而且有很好的并行性質,可以大大減少訓練時間。
3
預訓練在NLP 中的應用
值得一提的是,很多自然語言特征表示方法及詞表示方法都采用一種兩階段的訓練方法,即首先在無標記數據上通過預訓練學習特征或者詞的表示;再以這些表示作為特征,在標記數據上進行監督訓練。前文所提到的word2vec 和ELMO 方法就經常被用于詞向量的預訓練。隨著深度學習在表示學習領域成為主流方法,以及Transformer等序列表示模型的發展,自然語言的表示學習從特征和詞的粒度被推廣到了更大的粒度,如短語和句子。這些深度學習模型也同樣受益于這種兩階段的訓練方法。在ELMO 之后,新的語言表征預訓練模型GPT 使用Transformer 來編碼[16], 克服了ELMO 使用LSTM 作為語言模型而帶來的并行計算能力差的缺點。而BERT 模型在采用Transformer 進行編碼的同時雙向綜合地考慮上下文特征來對詞進行預測[17]。與word2vec 和ELMO 不同,GPT 和BERT 在進行第一階段的預訓練之后只需要根據第二階段的任務對模型結構進行改造,精加工(fine-tuning)模型進行監督訓練,使之適用于具體的任務。BERT 具有很強的普適性,幾乎所有 NLP 任務都可以套用這種兩階段解決思路,并且獲得效果的明顯提升。
4
其他NLP 表示學習方法與應用
除了上文中通用的NLP 表示學習方法,自然語言仍存在很多性質需要進行深入研究。例如,漢語具有部首共享和漢字共享的特殊性質,即幾個漢字共同的部首通常是它們之間的核心語義關聯;相應地,一個漢語詞的意思可以通過其包含的漢字來表達。如圖1所示,基于部首感知和注意力機制的四粒度模型RAFG[18] 對這兩種性質加以挖掘和利用,并將這些特征系統地融入到中文文本分類的任務中,從而實現對中文文本更為準確的語義表示。
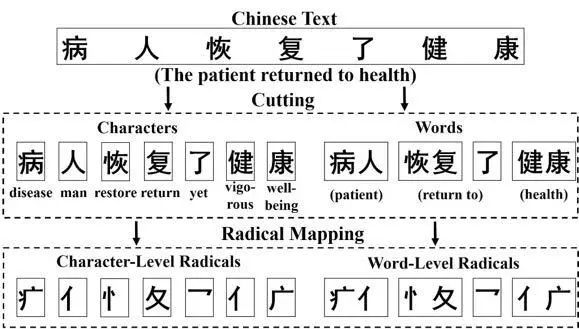
圖1:RAFG 獲得中文文本四個粒度特征的說明
此外,語言所處的環境信息(如圖像)會對語言的語義產生影響。進一步地,圖像所包含的信息可能與句子語義的不同的粒度表示有關聯。為此,如圖2所示,圖像增強的層次化句子語義表示網絡IEMLRN[19]利用圖像信息從不同粒度來增強句子的語義理解與表示,實現了更為準確的句子語義表示,以及句子對的語義關系分類。
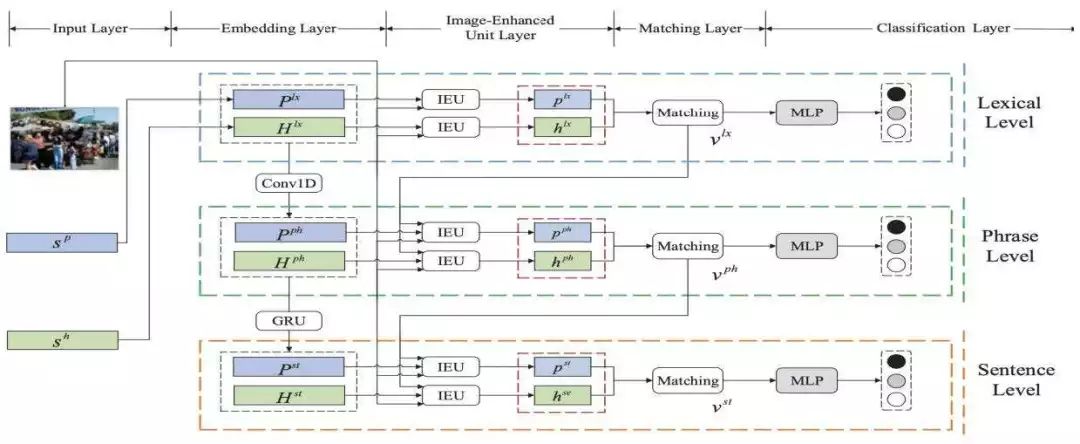
圖2:圖像增強的層次化句子語義表示網絡IEMLRN結構
最后,語義表示技術的發展使得多媒體信息的有效建模與語義表示成為可能,進而為推薦、檢索等實際應用場景提供支撐。近年來,多媒體共享平臺取得了突飛猛進的發展。其中一種叫做“彈幕”的視頻實時評論愈發流行。為了有效理解視頻片段的內容,如圖3 所示,基于深度神經網絡的彈幕語義表征方法[20] 通過利用彈幕與視頻情節之間的關聯性,對彈幕進行表示學習,實現了對視頻片段的標注。這種方法突破了常規視頻推薦/ 檢索系統只關注整段視頻的局限性,可以滿足細粒度的要求。
圖3:基于彈幕語義表征的視頻片段標注框架會對語言的語義產生影響
5
結束語
自然語言的語義表示學習方法的發展為各種NLP 任務帶來了更多的可能性。新型網絡結構的出現使我們可以得到更加有效的語義表征。而兩階段的預訓練方法可以把大量的無標注文本利用起來,對大量的通用語言學知識進行抽取與表示,從而提升NLP 下游任務的效果。
自然語言的語義表示學習方法取得了令人矚目的成就,但在很多方面都仍值得繼續研究。無論是更強的特征抽取器還是引入大量數據中包含的語言學知識,對更加精確的語義表示都有著重要作用。盡管現有的很多NLP 任務還無法達到人類的水平, 但相信對自然語言語義表征的不斷研究、新技術的不斷出現,會創造出更豐富的成果。
-
語音識別
+關注
關注
38文章
1739瀏覽量
112659 -
圖像分析
+關注
關注
0文章
82瀏覽量
18679 -
自然語言
+關注
關注
1文章
288瀏覽量
13350
原文標題:學會原創 | 自然語言的語義表示學習方法與應用
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學會】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
python自然語言
自然語言處理怎么最快入門?
語義理解和研究資源是自然語言處理的兩大難題
什么是自然語言處理_自然語言處理常用方法舉例說明






 工商網監
工商網監
評論