 什么是科學假設?什么是統計假設?什么又是機器學習假設呢?
什么是科學假設?什么是統計假設?什么又是機器學習假設呢?
什么是科學假設?什么是統計假設?什么又是機器學習假設呢?
雖然同為假說,這三個東西其實還真不太一樣!
今天,就帶你來區分一下“假設”三兄弟。
了解完它們的區別后,你會對假設一詞在不同領域會有更深刻的認識,對于更好的使用假設會有更深入的理解。同時,對于機器學習的入門者來說,這樣一篇文章對于個人今后在該領域的發展就是如虎添翼。
通常,我們所理解的監督性機器學習,是一個類似于研究從輸入映射到輸出的目標函數問題。
這個過程可以被分為如何選取假設空間,以及評估候選的假設空間。
作為一個機器學習領域的初學者來說,假設這個詞的概念可能讓他們會產生困惑,有時會產生歧義,比如在統計領域我們會有假設檢驗,而在科學領域我們又會有科學假說。
這些定義互有關聯,卻不盡相同。
所以什么是假設呢?
假設是一種對事物的解釋。
它是一種憑借經驗和知識所提出的猜測性想法,需要一定的評估依據。
一個好的假設是可驗證的,驗證結果有可能是對的,也可能是錯的。
在科學界,假說一定是可以被證偽的,即通過觀察檢驗結果,可以證實這個假說是錯誤的。同時,在驗證結果出來之前,假說的框架結構一定要確定好。
...任何一個或一系列假說想要成為科學定理或者科學理論,一定要滿足這樣一個基本條件—那就是,它是可以被證偽的。
選自《What is This Thing Called Science?》1999年,第三版,第61-62頁
一個好的假說既能滿足現有證據,又可以用來預測新的觀察或新的情況。
一個假說如果說完全滿足現有證據,同時可以被驗證,那么它將會成為理論或者成為理論的一部分。
小結一下,科學假說是指符合證據、同時可以被證實或者被反駁的猜測性解釋。
統計學中的假設又該如何定義呢?
大多統計問題是研究觀測樣本之間潛在關系。
統計學上的假設檢驗通常是計算產生“影響”的臨界值,通過計算臨界值可以來判定觀測樣本之間是否存在某種關系。
如果似然值很小,這種影響結果就可能會是真實的,如果似然值很大,那我們可能觀測到了統計波動,這種影響可能并不真實。
舉例來說,通過推斷兩組樣本之間均值所存在的關系,可以判斷它們是否具有相同的統計分布,或者它們之間又有哪些差異。
舉個例子,我們可以假設兩組樣本的均值相同。
這種假設對我們來說沒什么影響,也叫作零假設。通過假設檢驗,我們可以得到拒絕該假設或者保留該假設。即便我們不能拒絕零假設,也不等于我們接受零假設是對的,因為結果只是一個概率。
..在社會科學研究中,我們通過建立假設、制定標準來衡量是否保留或拒絕我們的假設,通常都是零假設。
《Statistics in plain English》2010年第三版,64-65頁
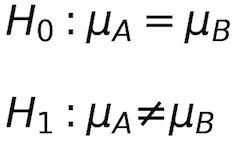
在我們的例子中,如果零假設被否定,其相對立的備擇假設就認為均值之間存在差異。
零假設(H0):沒有影響
備擇假設(H1):存在影響
統計學中的假設檢驗通常不會評判影響的大小,只會近似估計被觀測樣本之間是否存在差異。
小結一下,統計學中的假設指的是用概率來解釋樣本觀測值之間是否存在關系。
最后,什么是機器學習中的假設呢?
機器學習,尤其是監督性學習,是用已有數據學習得到一個最佳的函數來表示輸入到輸出之間的映射關系。
說的專業些,這個叫做函數逼近。就是說我們想找到一個接近于我們目標函數(我們假設它存在)的方程,可以滿足在問題定義域里所有觀測結果都可以從輸入映射到輸出結果。
在機器學習中,一個近似目標函數并且將輸入映射到輸出的模型被稱為假設。
算法選取(比如神經網絡)和算法配置(如網絡拓撲和超參數)決定了模型可能表示的假設空間。
機器學習算法的學習是尋找最接近目標函數的假設,即將已選取的假設空間轉化成最佳或最優的假設。
“學習”是在可能的假設空間中尋找一個表現良優的假設空間,即使在訓練集之外新樣本上也能適用。
選自《Artificial Intelligence: A Modern Approach》2009年第二版,第695頁。
這種機器學習的框架很常見,通常可以幫助我們選取算法、理解學習和泛化問題,甚至是“偏差-方差”的權衡。舉例來說,訓練集通常是學習假設,而測試數據集是用來評估假設。
我們通常會用小寫(h)來表示給予的特定假設,用大寫(H)來表示被探索的假設空間。
假設(h):單一假設,如一個實例或特定的候選模型,可以將輸入映射到輸出,同時也可以對模型進行評估和預測。
假設集(H):一個包括所有可能的輸入映射到輸出之間關系的假設空間,通常受選取的問題框架、模型和模型調參所限制。
在選擇算法和配置過程中,我們需要選取一個對目標函數來說是最好的逼近函數作為假設空間。這是非常具有挑戰的,通常對于一系列不同的假設空間進行抽查會更為有效。
如果假設空間包含真函數,則學習問題是可實現的。不幸的是,我們不能總是判斷一個給定的學習問題是否可以實現,因為真正的函數是未知的。
選自《Artificial Intelligence: A Modern Approach》2009年第二版,697頁。
這是一個困難的問題。通常,我們通過限制假設空間的大小和評估假設的復雜性來簡化搜索過程。
假設空間的表達性和假設搜索的復雜性之間存在一種權衡關系。
選自《Artificial Intelligence: A Modern Approach》2009年第二版,697頁。
小結一下,機器學習中的假設是一個近似目標函數的候選模型,用于表示輸入樣本到輸出樣本之間的映射關系。
總 結
讓我們重新梳理一遍對假設的三個定義:
科學假說是一種對于觀察現象的猜測性解釋,并且是可以被證偽的。
統計中的假設是用概率的方式來解釋數據樣本之間的關系。
機器學習中的假設是一個近似目標函數的候選模型,用于表示輸入樣本到輸出樣本之間的映射關系。
機器學習的假設定義要比科學中的定義更加廣泛。
和科學假說一樣,機器學習也是基于現有證據,可以被證偽,并對新情況進行預測。
在機器學習中的假設:
涵蓋現有證據:即訓練數據集
可以被證偽:有一個測試集來評估模型表現,并且與基礎模型作對比,確定訓練過程是否有效。
適用于新的情況:可被用來對新數據集進行預測。
-
神經網絡
+關注
關注
42文章
4773瀏覽量
100890 -
函數
+關注
關注
3文章
4338瀏覽量
62738 -
機器學習
+關注
關注
66文章
8424瀏覽量
132765
原文標題:“假設”家族大起底!如何正確區分科學假設、統計假設和機器學習假設?
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何選擇云原生機器學習平臺
為什么噪聲功率在低采樣率和過采樣率的情況下是相同的呢?
Minitab 在統計分析中的應用
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
雙開關控制一個燈怎么接線
LM311單電源5V比較器,輸入的信號假設是音頻信號,能進行比較嗎?
【《時間序列與機器學習》閱讀體驗】+ 了解時間序列

相控陣雷達信號處理的原理和術語

什么是元宇宙,AR/VR和它又是什么關系呢?
LED陣列:一個電阻器還是多個?





 工商網監
工商網監
評論