 端到端駕駛模型的發展歷程
端到端駕駛模型的發展歷程
在搭建無人車時,我和小伙伴們的主要工作是建立一個駕駛模型。所謂的駕駛模型是控制無人車行駛的軟件,在功能上類似于一名司機,其輸入為車輛狀態、周圍環境信息,輸出為對無人車的控制信號。在所有駕駛模型中,最簡單直接的是端到端駕駛模型。端到端駕駛模型直接根據車輛狀態和外部環境信息得出車輛的控制信號。從輸入端(傳感器的原始數據)直接映射到輸出端(控制信號),中間不需要任何人工設計的特征。通常,端到端駕駛模型使用一個深度神經網絡來完成這種映射,網絡的所有參數為聯合訓練而得。這種方法因它的簡潔高效而引人關注。
端到端駕駛模型的發展歷程
尋找端到端駕駛模型的最早嘗試,至少可以追溯到1989年的ALVINN模型【2】。ALVINN是一個三層的神經網絡,它的輸入包括前方道路的視頻數據、激光測距儀數據,以及一個強度反饋。對視頻輸入,ALVINN只使用了其藍色通道,因為在藍色通道中,路面和非路面的對比最為強烈。對測距儀數據,神經元的激活強度正比于拍攝到的每個點到本車的距離。強度反饋描述的是在前一張圖像中,路面和非路面的相對亮度。ALVINN的輸出是一個指示前進方向的向量,以及輸入到下一時刻的強度反饋。具體的網絡結構如圖一所示。
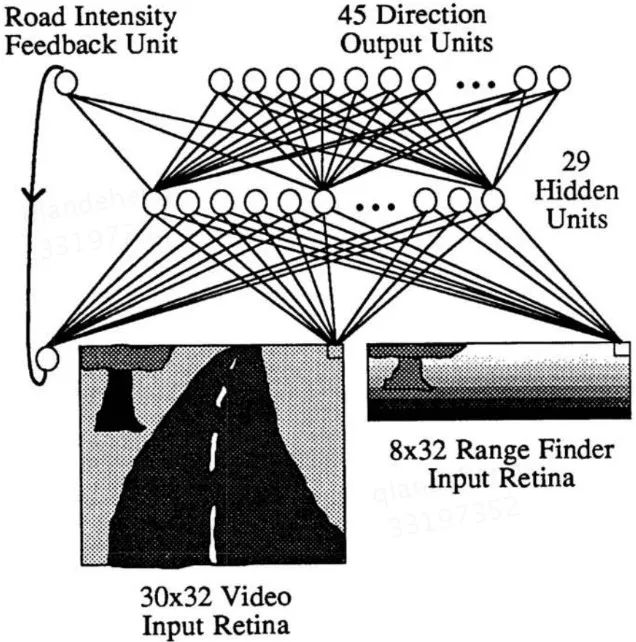
圖一:ALVINN的網絡結構示意圖,圖片引用于【2】
在訓練ALVINN時,其輸出的真值被設為一個分布。該分布的中心位置對應于能讓車輛行駛到前方7米處的道路中心的那個方向,分布由中心向兩邊迅速衰減到0。此外,在訓練過程中使用了大量合成的道路數據,用于提高ALVINN的泛化能力。該模型成功地以0.5米每秒的速度開過一個400米長的道路。來到1995年,卡內基梅隆大學在ALVINN的基礎上通過引入虛擬攝像頭的方法,使ALVINN能夠檢測到道路和路口【3】。另外,紐約大學的Yann LeCun在2006年給出了一個6層卷積神經網絡搭建的端到端避障機器人【4】。
近年來,比較有影響力的工作是2016年NVIDIA開發的PilotNet【5】。如圖二所示,該模型使用卷積層和全連層從輸入圖像中抽取特征,并給出方向盤的角度(轉彎半徑)。相應地,NVIDIA還給出了一套用于實車路測的計算平臺NVIDIA PX 2。在NVIDIA的后續工作中,他們還對PilotNet內部學到的特征進行了可視化,發現PilotNet能自發地關注到障礙物、車道線等對駕駛具有重要參考價值的物體【6】。
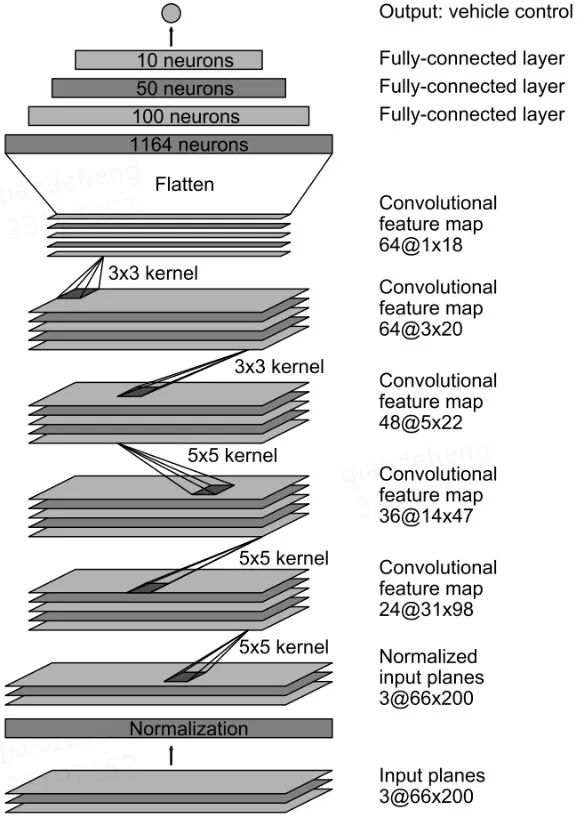
圖二:PilotNet的網絡結構示意圖,圖片引用于【5】
PilotNet之后的模型如雨后春筍般涌現。一個重要的代表是加州大學伯克利分校提出的FCN-LSTM網絡【7】。如圖三所示,該網絡首先通過全卷積網絡將圖像抽象成一個向量形式的特征,然后通過長短時記憶網絡將當前的特征和之前的特征融合到一起,并輸出當前的控制信號。值得指出的是,該網絡使用了一個圖像分割任務來輔助網絡的訓練,用更多監督信號使網絡參數從“無序”變為“有序”,這是一個有趣的嘗試。以上這些工作都只關注無人車的“橫向控制”,也就是方向盤的轉角。羅徹斯特大學提出的Multi-modal multi-task網絡【8】在前面工作的基礎上,不僅給出方向盤的轉角,而且給出了預期速度,也就是包含了“縱向控制”,因此完整地給出了無人車所需的最基本控制信號,其網絡結構如圖四所示。
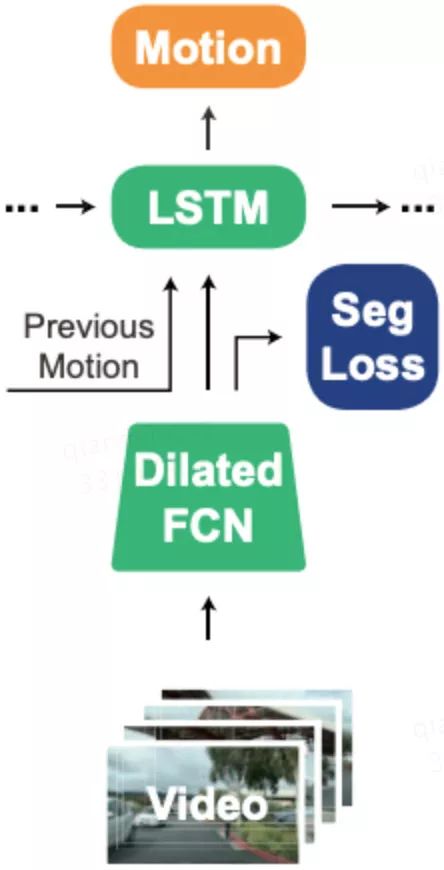
圖三:FCN-LSTM網絡結構示意圖,圖片引用于【7】
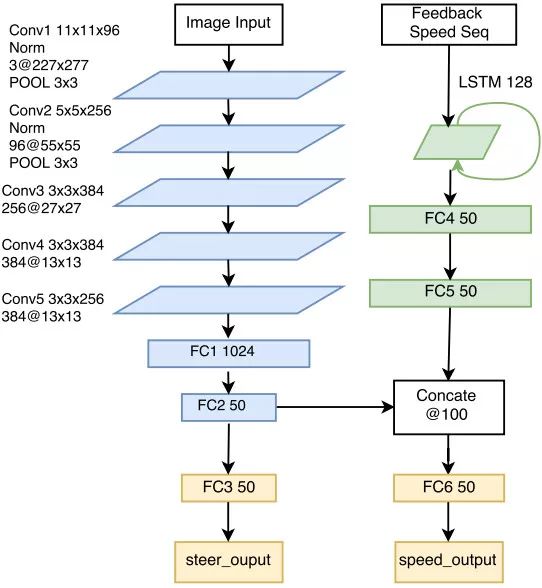
圖四:Multi-modal multi-task網絡結構示意圖,圖片引用于【8】
北京大學提出的ST-Conv + ConvLSTM + LSTM網絡更加精巧【9】。如圖五所示,該網絡大致分成兩部分,即特征提取子網絡和方向角預測子網絡。特征提取子網絡利用了時空卷積,多尺度殘差聚合,卷積長短時記憶網絡等搭建技巧或模塊。方向角預測子網絡主要做時序信息的融合以及循環。該網絡的作者還發現,無人車的橫向控制和縱向控制具有較強的相關性,因此聯合預測兩種控制能更有效地幫助網絡學習。

圖五:ST-Conv+ConvLSTM+LSTM網絡結構示意圖,圖片引用于【9】
端到端駕駛模型的特點
講到這里,大家也許已經發現,端到端模型得益于深度學習技術的快速發展,朝著越來越精巧的方向不斷發展。從最初的三層網絡,逐步武裝上了最新模塊和技巧。在這些最新技術的加持下,端到端駕駛模型已經基本實現了直道、彎道行駛,速度控制等功能。為了讓大家了解目前的端到端模型發展現狀,我們從算法層面將這種模型與傳統模型做一個簡單對比,見下表一:
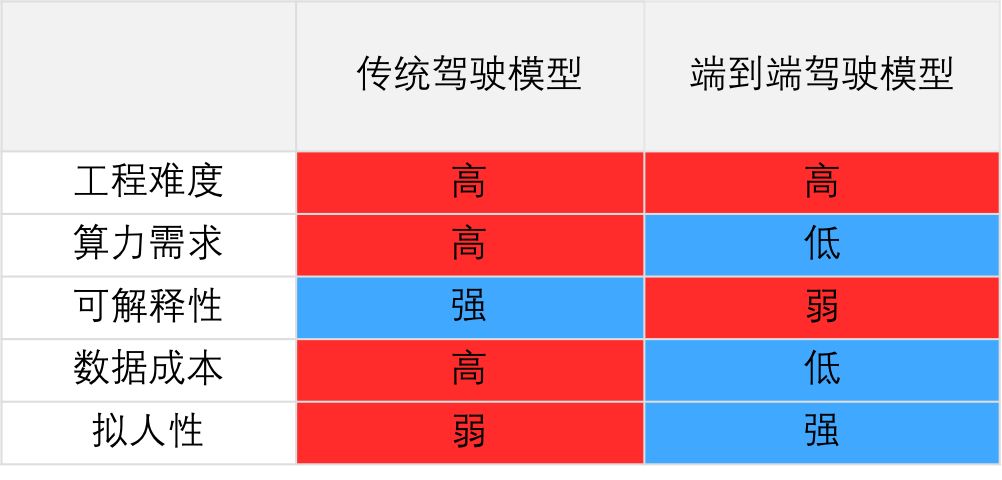
表一:傳統駕駛模型和端到端模型對比
傳統的模型一般將駕駛任務分割成多個子模塊,例如感知、定位、地圖、規劃、控制等等。每個子模塊完成特定的功能,某個模塊的輸出作為其它模塊的輸入,模塊間相互連接,形成有向圖的結構。這種方法需要人工解耦無人車的駕駛任務,設計各個子模塊,而子模塊的數量甚至高達上千個,導致這項工作費時費力,維護成本高昂。如此多的子模塊又對車載計算平臺提出了極高的要求,需要強大的算力保證各個模塊能快速響應環境的變化。
此外,傳統駕駛模型往往依賴高精地圖,導致其數據成本高昂。這類模型通過規則化的邏輯來做無人車的運動規劃與控制,又導致其駕駛風格的擬人化程度弱,影響乘坐的舒適性。作為對比,端到端模型以其簡單、易用、成本低、擬人化等特點表現出很強的優勢。
人們通常認為端到端駕駛模型和模塊化的傳統模型之間是彼此對立的,有了模塊化模型就不需要端到端了。但在無人配送領域,我認為兩者應該是互補的。首先,無人配送車“小、輕、慢、物”的特點【10】極大降低了其安全風險。使端到端模型的部署成為可能。然后,端到端模型可以很好地處理常見場景,而且功耗低。模塊化的方法能覆蓋更多場景,但功耗高。因此,一個很有價值的方向應該是聯合部署端到端模型和模塊化模型。在常見場景中使用端到端,在復雜場景中,切換到模塊化模型。這樣,我們可以在保證整體模型性能的同時,盡最大可能降低配送車的功耗。
那么是不是很快就能見到端到端駕駛模型控制的無人配送車了呢?其實,現在端到端駕駛模型還處在研究階段。我從自己的實際工作經驗中總結出以下幾個難點:
1、端到端駕駛模型因其近乎黑盒的特點導致調試困難。
由于端到端模型是作為一個整體工作的,因此當該模型在某種情況下失敗時,我們幾乎無法找到模型中應該為這次失敗負責的“子模塊”,也就沒辦法有針對性地調優。當遇到失敗例子時,通常的做法只能是添加更多的數據,期待重新訓練的模型能夠在下一次通過這個例子。
2、端到端駕駛模型很難引入先驗知識。
目前的端到端模型更多地是在模仿人類駕駛員動作,但并不了解人類動作背后的規則。想要通過純粹數據驅動的方式讓模型學習諸如交通規則、文明駕駛等規則比較困難,還需要更多的研究。
3、端到端駕駛模型很難恰當地處理長尾場景。
對于常見場景,我們很容易通過數據驅動的方式教會端到端模型正確的處理方法。但真實路況千差萬別,我們無法采集到所有場景的數據。對于模型沒有見過的場景,模型的性能往往令人擔憂。如何提高模型的泛化能力是一個亟待解決的問題。
4、端到端駕駛模型通常通過模仿人類駕駛員的控制行為來學習駕駛技術。
但這種方式本質上學到的是駕駛員的“平均控制信號”,而“平均控制信號”甚至可能根本就不是一個“正確”的信號。
例如在一個可以左拐和右拐的丁字路口,其平均控制信號——“直行”——就是一個錯誤的控制信號。因此,如何學習人類駕駛員的控制策略也有待研究。
在這個問題上,我和小伙伴們一起做了一點微小的工作,在該工作中,我們認定駕駛員在不同狀態下的操作滿足一個概率分布。我們通過學習這個概率分布的不同矩來估計這個分布。這樣一來,駕駛員的控制策略就能很好地通過其概率分布的矩表達出來,避免了簡單求“平均控制信號”的缺點。該工作已被 ROBIO 2018 接收。
端到端駕駛模型中常用方法
為了解決上面提到的各種問題,勇敢的科學家們提出了許多方法,其中最值得期待的要數深度學習技術【11】和強化學習技術【12】了。隨著深度學習技術的不斷發展,相信模型的可解釋性、泛化能力會進一步提高。這樣以來,我們或許就可以有針對性地調優網絡,或者在粗糙的仿真下、在較少數據的情況下,成功地泛化到實車場景、長尾場景。強化學習這項技術在近年來取得了令人驚嘆的成就。通過讓無人車在仿真環境中進行強化學習,也許可以獲得比人類駕駛員更優的控制方法也未可知。此外,遷移學習、對抗學習、元學習等技術高速發展,或許也會對端到端駕駛模型產生巨大影響。
我對端到端駕駛模型今后的發展充滿了期待。“Two roads diverged in a wood, and I took the one less traveled by”【13】。
-
傳感器
+關注
關注
2552文章
51288瀏覽量
755157 -
神經網絡
+關注
關注
42文章
4776瀏覽量
100952 -
圖像分割
+關注
關注
4文章
182瀏覽量
18024
原文標題:美團技術部解析:無人車端到端駕駛模型概述
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
端到端自動駕駛技術研究與分析
理想汽車智能駕駛團隊調整:端到端部門獨立
爆火的端到端如何加速智駕落地?

Waymo利用谷歌Gemini大模型,研發端到端自動駕駛系統
智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
Mobileye端到端自動駕駛解決方案的深度解析

實現自動駕駛,唯有端到端?


小鵬汽車發布國內首個量產上車的端到端大模型

牽手NVIDIA 元戎啟行端到端模型將搭載 DRIVE Thor芯片
端到端模型卷入智駕圈 周光:今年上車!






 工商網監
工商網監
評論