") 谷歌全神經(jīng)元的設(shè)備端語(yǔ)音識(shí)別器再推新品
谷歌全神經(jīng)元的設(shè)備端語(yǔ)音識(shí)別器再推新品
在近二十年來(lái),尤其是引入深度學(xué)習(xí)以后,語(yǔ)音識(shí)別取得了一系列重大突破,并一步步走向市場(chǎng)并搭載到消費(fèi)級(jí)產(chǎn)品中。然而在用戶(hù)體驗(yàn)上,「遲鈍」可以算得上這些產(chǎn)品最大的槽點(diǎn)之一,這也意味著語(yǔ)音識(shí)別的延遲問(wèn)題已經(jīng)成為了該領(lǐng)域研究亟待解決的難點(diǎn)。日前,谷歌推出了基于循環(huán)神經(jīng)網(wǎng)絡(luò)變換器(RNN-T)的全神經(jīng)元設(shè)備端語(yǔ)音識(shí)別器,能夠很好地解決目前語(yǔ)音識(shí)別所存在的延遲難題。谷歌也將這項(xiàng)成果發(fā)布在了官方博客上。
2012 年,語(yǔ)音識(shí)別研究表明,通過(guò)引入深度學(xué)習(xí)可以顯著提高語(yǔ)音識(shí)別準(zhǔn)確率,因此谷歌也較早地在語(yǔ)音搜索等產(chǎn)品中采用深度學(xué)習(xí)技術(shù)。而這也標(biāo)志著語(yǔ)音識(shí)別領(lǐng)域革命的開(kāi)始:每一年,谷歌都開(kāi)發(fā)出了從深度神經(jīng)網(wǎng)絡(luò)(DNN)到循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)、卷積網(wǎng)絡(luò)(CNNs)等一系列新的架構(gòu),進(jìn)一步地提高了語(yǔ)音識(shí)別的質(zhì)量。然而在此期間,延遲問(wèn)題依舊是該領(lǐng)域需要攻克的主要難點(diǎn)——當(dāng)語(yǔ)音助手能夠?qū)崿F(xiàn)快速回答問(wèn)題時(shí),用戶(hù)會(huì)感覺(jué)它有幫助得多。
日前,谷歌正式宣布推出端到端、全神經(jīng)元的設(shè)備端語(yǔ)音識(shí)別器,為 Gboard 中的語(yǔ)音輸入提供支持。在谷歌 AI 最近的一篇論文《移動(dòng)設(shè)備的流媒體端到端語(yǔ)音識(shí)別》(Streaming End-to-End Speech Recognition for Mobile Devices,論文閱讀地址:https://arxiv.org/abs/1811.06621)中,其研究團(tuán)隊(duì)提出了一種使用循環(huán)神經(jīng)網(wǎng)絡(luò)變換器(RNN-T,https://arxiv.org/pdf/1211.3711.pdf)技術(shù)訓(xùn)練的模型,該技術(shù)也足夠精簡(jiǎn)可應(yīng)用到手機(jī)端上。這就意味著語(yǔ)音識(shí)別不再存在網(wǎng)絡(luò)延遲或故障問(wèn)題——新的識(shí)別器即便處于離線狀態(tài)也能夠運(yùn)行。該模型處理的是字符水平的語(yǔ)音識(shí)別,因此當(dāng)人在說(shuō)話時(shí),它會(huì)逐個(gè)字符地輸出單詞,這就跟有人在實(shí)時(shí)鍵入你說(shuō)的話一樣,同時(shí)還能達(dá)到你對(duì)鍵盤(pán)聽(tīng)寫(xiě)系統(tǒng)的預(yù)期效果。
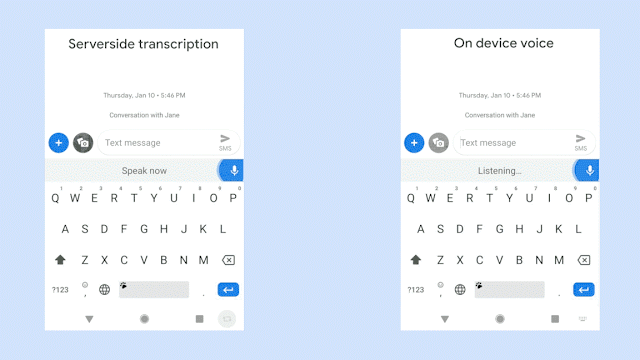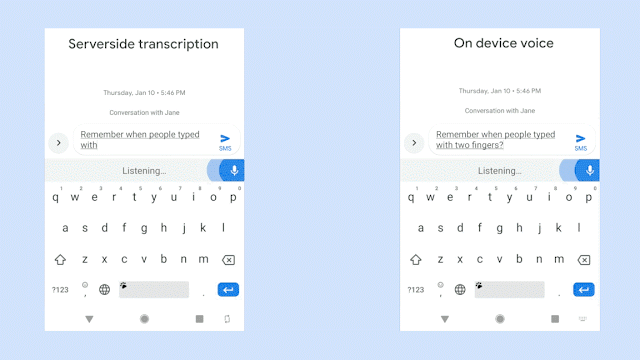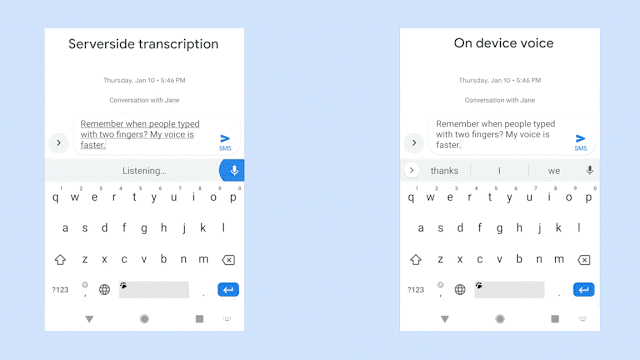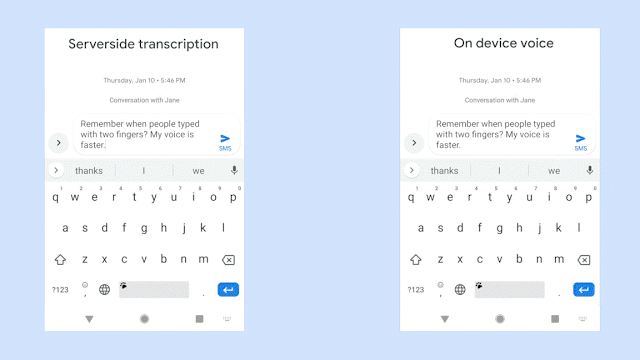
該圖對(duì)比了識(shí)別同一句語(yǔ)音時(shí),服務(wù)器端語(yǔ)音識(shí)別器(左邊)以及新的設(shè)備端語(yǔ)音識(shí)別器(右邊)的生成情況。
關(guān)于語(yǔ)音識(shí)別的一點(diǎn)歷史
傳統(tǒng)而言,語(yǔ)音識(shí)別系統(tǒng)由幾個(gè)部分組成:一個(gè)將語(yǔ)音分割(一般為 10 毫秒的框架)映射到音素的聲學(xué)模型;一個(gè)將因素合成單詞的發(fā)音模型;以及一個(gè)表達(dá)給定短語(yǔ)可能性的語(yǔ)言模型。在早期的系統(tǒng)中,對(duì)這些組成部分的優(yōu)化都是單獨(dú)進(jìn)行的。
在 2014 年左右,研究人員就開(kāi)始重點(diǎn)訓(xùn)練單個(gè)神經(jīng)網(wǎng)絡(luò),來(lái)直接將一個(gè)輸入語(yǔ)音波形映射到一個(gè)輸出句子。研究人員采用這種通過(guò)給定一系列語(yǔ)音特征生成一系列單詞或字母的序列到序列(sequence-to-sequence)方法開(kāi)發(fā)出了「attention-based」(https://arxiv.org/pdf/1506.07503.pdf)和「listen-attend-spell」(https://arxiv.org/pdf/1508.01211.pdf)模型。雖然這些模型在準(zhǔn)確率上表現(xiàn)很好,但是它們一般通過(guò)回顧完整的輸入序列來(lái)識(shí)別語(yǔ)音,同時(shí)當(dāng)輸入進(jìn)來(lái)的時(shí)候也無(wú)法讓數(shù)據(jù)流輸出一項(xiàng)對(duì)于實(shí)時(shí)語(yǔ)音轉(zhuǎn)錄必不可少的特征。
與此同時(shí),當(dāng)時(shí)的一項(xiàng)叫做CTC(connectionist temporal classification)的技術(shù)幫助將生產(chǎn)式識(shí)別器的延遲時(shí)間減半。事實(shí)證明,這項(xiàng)進(jìn)展對(duì)于開(kāi)發(fā)出 CTC 最新版本(改版本可以看成是 CTC 的泛化)中采用的 RNN-T 架構(gòu)來(lái)說(shuō),是至關(guān)重要的一步。
循環(huán)神經(jīng)網(wǎng)絡(luò)變換器(RNN-T)
RNN-T 是不采用注意力機(jī)制的序列到序列模型的一種形式。與大多數(shù)序列到序列模型需要處理整個(gè)輸入序列(本文案例中的語(yǔ)音波形)以生成輸出(句子)不同,RNN-T 能持續(xù)地處理輸入的樣本和數(shù)據(jù)流,并進(jìn)行符號(hào)化的輸出,這種符號(hào)化的輸出有助于進(jìn)行語(yǔ)音聽(tīng)寫(xiě)。在谷歌研究人員的實(shí)現(xiàn)中,符號(hào)化的輸出就是字母表中的字符。當(dāng)人在說(shuō)話時(shí),RNN-T 識(shí)別器會(huì)逐個(gè)輸出字符,并進(jìn)行適當(dāng)留白。在這一過(guò)程中,RNN-T 識(shí)別器還會(huì)有一條反饋路徑,將模型預(yù)測(cè)的符號(hào)輸回給自己以預(yù)測(cè)接下來(lái)的符號(hào),具體流程如下圖所示:
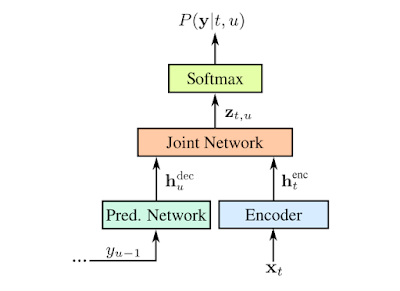
RNN-T 的表示:用 x 表示輸入語(yǔ)音樣本;用 y 表示預(yù)測(cè)的符號(hào)。預(yù)測(cè)的符號(hào)(Softmax 層的輸出)y(u-1)通過(guò)預(yù)測(cè)網(wǎng)絡(luò)被輸回給模型,確保預(yù)測(cè)同時(shí)考慮到當(dāng)前的語(yǔ)音樣本以及過(guò)去的輸出。預(yù)測(cè)和解碼網(wǎng)絡(luò)都是LSTM RNN,聯(lián)合的模型則是前饋網(wǎng)絡(luò)(feedforward network ,相關(guān)論文查看地址:https://www.isca-speech.org/archive/Interspeech_2017/pdfs/0233.PDF)。預(yù)測(cè)網(wǎng)絡(luò)由 2 個(gè)擁有 2048 個(gè)單元的層和 1 個(gè)有著 640 個(gè)維度的投射層組成。解碼網(wǎng)絡(luò)則由 8 個(gè)這樣的層組成。圖源:Chris Thornton
有效地訓(xùn)練這樣的模型本來(lái)就已經(jīng)很難了,然而使用谷歌開(kāi)發(fā)的這項(xiàng)能夠進(jìn)一步將單詞錯(cuò)誤率減少 5% 的新訓(xùn)練技術(shù),對(duì)計(jì)算能力也提出了更高的要求。對(duì)此,谷歌開(kāi)發(fā)了一種平行實(shí)現(xiàn)的方法,讓 RNN-T 的損失函數(shù)能夠大批地在谷歌的高性能云平臺(tái) TPUv2 芯片上高效運(yùn)行。
離線識(shí)別
在傳統(tǒng)的語(yǔ)音識(shí)別引擎中,上文中提到的聲學(xué)、發(fā)音和語(yǔ)言模型被「組合」成一個(gè)邊緣用語(yǔ)音單元及其概率標(biāo)記的大搜索圖(search graph)。在給定輸入信號(hào)的情況下,當(dāng)語(yǔ)音波形抵達(dá)識(shí)別器時(shí),「解碼器」就會(huì)在圖中搜索出概率最大的路徑,并讀出該路徑所采用的單詞序列。一般而言,解碼器假設(shè)基礎(chǔ)模型由 FST(Finite State Transducer)表示。然而,盡管現(xiàn)在已經(jīng)有精密的解碼技術(shù),但是依舊存在搜索圖太大的問(wèn)題——谷歌的生成式模型的搜索圖大小近 2GB。由于搜索圖無(wú)法輕易地在移動(dòng)電話上托管,因此采用這種方法的模型只有在在線連接的情況中才能正常工作。
為了提高語(yǔ)音識(shí)別的有效性,谷歌研究人員還試圖通過(guò)直接將在設(shè)備上托管新模型來(lái)避免通信網(wǎng)絡(luò)的延遲及其固有的不可靠性。因此,谷歌提出的這一端到端的方法,不需要在大型解碼器圖上進(jìn)行搜索。相反,它采取對(duì)單個(gè)神經(jīng)網(wǎng)絡(luò)進(jìn)行一系列搜索的方式進(jìn)行解碼。同時(shí),谷歌研究人員訓(xùn)練的 RNN-T 實(shí)現(xiàn)了基于服務(wù)器的傳統(tǒng)模型同樣的準(zhǔn)確度,但是該模型大小僅為 450MB,本質(zhì)上更加密集、更加智能地利用了參數(shù)和打包信息。不過(guò),即便對(duì)于如今的智能手機(jī)來(lái)說(shuō),450 MB 依舊太大了,這樣的話當(dāng)它通過(guò)如此龐大的網(wǎng)絡(luò)進(jìn)行網(wǎng)絡(luò)信號(hào)傳輸時(shí),速度就會(huì)變得很慢。
對(duì)此,谷歌研究人員通過(guò)利用其于 2016 年開(kāi)發(fā)的參數(shù)量化(parameter quantization )和混合內(nèi)核(hybrid kernel)技術(shù)(https://arxiv.org/abs/1607.04683),來(lái)進(jìn)一步縮小模型的大小,并通過(guò)采用 ensorFlow Lite 開(kāi)發(fā)庫(kù)中的模型優(yōu)化工具包來(lái)對(duì)外開(kāi)放。與經(jīng)過(guò)訓(xùn)練的浮點(diǎn)模型相比,模型量化的壓縮高出 4 倍,運(yùn)行速度也提高了 4 倍,從而讓 RNN-T 比單核上的實(shí)時(shí)語(yǔ)音運(yùn)行得更快。經(jīng)過(guò)壓縮后,模型最終縮小至 80MB。
谷歌全新的全神經(jīng)元設(shè)備端 Gboard 語(yǔ)音識(shí)別器,剛開(kāi)始僅能在使用美式英語(yǔ)的 Pixel 手機(jī)上使用。考慮到行業(yè)趨勢(shì),同時(shí)隨著專(zhuān)業(yè)化硬件和算法的融合不斷增強(qiáng),谷歌表示,希望能夠?qū)⑦@一技術(shù)應(yīng)用到更多語(yǔ)言和更廣泛的應(yīng)用領(lǐng)域中去。
-
谷歌
+關(guān)注
關(guān)注
27文章
6176瀏覽量
105680 -
語(yǔ)音識(shí)別
+關(guān)注
關(guān)注
38文章
1742瀏覽量
112745
原文標(biāo)題:語(yǔ)音識(shí)別如何突破延遲瓶頸?谷歌推出了基于 RNN-T 的全神經(jīng)元設(shè)備端語(yǔ)音識(shí)別器
文章出處:【微信號(hào):CAAI-1981,微信公眾號(hào):中國(guó)人工智能學(xué)會(huì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
神經(jīng)元芯片的主要特點(diǎn)和優(yōu)勢(shì)
神經(jīng)元是什么?神經(jīng)元在神經(jīng)系統(tǒng)中的作用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論