 完成一個簡單的端到端的機器學習模型需要幾步?
完成一個簡單的端到端的機器學習模型需要幾步?
【導語】完成一個簡單的端到端的機器學習模型需要幾步?在本文中,我們將從一個完整的工作流:下載數據→圖像分割與處理→建模→發布模型,教大家如何對 900 萬張圖像進行分類,分類標簽多達 600 個。可是如此龐大的數據集又是從何而來呢?上周,AI科技大本營為大家介紹過一篇文章在過去十年間,涵蓋 CV、NLP 和語音等領域,有 68 款大規模數據集,本文所用的數據集也在其中,大家也可以以此為借鑒,學習如何利用好這些數據。
前言
如果您想構建一個圖像分類器,哪里可以得到訓練數據呢?這里給大家推薦 Google Open Images,這個巨大的圖像庫包含超過 3000 萬張圖像和 1500 萬個邊框,高達 18tb 的圖像數據!并且,它比同級別的其他圖像庫更加開放,像 ImageNet 就有權限要求。
但是,對單機開發人員來說,在這么多的圖像數據中篩選過濾并不是一件易事,需要下載和處理多個元數據文件,還要回滾自己的存儲空間,也可以申請使用谷歌云服務。另一方面,實際中并沒有那么多定制的圖像訓練集,實話講,創建、共享這么多的訓練數據是一件頭疼的事情。
在今天的教程中,我們將教大家如何使用這些開源圖像創建一個簡單的端到端機器學習模型。
先來看看如何使用開源圖像中自帶的 600 類標簽來創建自己的數據集。下面以類別為“三明治”的照片為例,展示整個處理過程。
谷歌開源圖像-三明治圖片
一、下載數據
首先需要下載相關數據,然后才能使用。這是使用谷歌開源圖像(或其他外部數據集)的第一步。而下載數據集需要編寫相關腳本,沒有其他簡單的方法,不過不用擔心,我寫了一個Python腳本,大家可以直接用。思路:首先根據指定的關鍵字,在開源數據集中搜索元數據,找到對應圖像的原始 url(在 Flickr 上),然后下載到本地,下面是實現的 Python 代碼:
1importsys 2importos 3importpandasaspd 4importrequests 5 6fromtqdmimporttqdm 7importratelim 8fromcheckpointsimportcheckpoints 9checkpoints.enable()101112defdownload(categories):13#Downloadthemetadata14kwargs={'header':None,'names':['LabelID','LabelName']}15orig_url="https://storage.googleapis.com/openimages/2018_04/class-descriptions-boxable.csv"16class_names=pd.read_csv(orig_url,**kwargs)17orig_url="https://storage.googleapis.com/openimages/2018_04/train/train-annotations-bbox.csv"18train_boxed=pd.read_csv(orig_url)19orig_url="https://storage.googleapis.com/openimages/2018_04/train/train-images-boxable-with-rotation.csv"20image_ids=pd.read_csv(orig_url)2122#GetcategoryIDsforthegivencategoriesandsub-selecttrain_boxedwiththem.23label_map=dict(class_names.set_index('LabelName').loc[categories,'LabelID']24.to_frame().reset_index().set_index('LabelID')['LabelName'])25label_values=set(label_map.keys())26relevant_training_images=train_boxed[train_boxed.LabelName.isin(label_values)]2728#Startfrompriorresultsiftheyexistandarespecified,otherwisestartfromscratch.29relevant_flickr_urls=(relevant_training_images.set_index('ImageID')30.join(image_ids.set_index('ImageID'))31.loc[:,'OriginalURL'])32relevant_flickr_img_metadata=(relevant_training_images.set_index('ImageID').loc[relevant_flickr_urls.index]33.pipe(lambdadf:df.assign(LabelValue=df.LabelName.map(lambdav:label_map[v]))))34remaining_todo=len(relevant_flickr_urls)ifcheckpoints.resultsisNoneelse35len(relevant_flickr_urls)-len(checkpoints.results)3637#Downloadtheimages38withtqdm(total=remaining_todo)asprogress_bar:39relevant_image_requests=relevant_flickr_urls.safe_map(lambdaurl:_download_image(url,progress_bar))40progress_bar.close()4142#Writetheimagestofiles,addingthemtothepackageaswegoalong.43ifnotos.path.isdir("temp/"):44os.mkdir("temp/")45for((_,r),(_,url),(_,meta))inzip(relevant_image_requests.iteritems(),relevant_flickr_urls.iteritems(),46relevant_flickr_img_metadata.iterrows()):47image_name=url.split("/")[-1]48image_label=meta['LabelValue']4950_write_image_file(r,image_name)515253@ratelim.patient(5,5)54def_download_image(url,pbar):55"""DownloadasingleimagefromaURL,rate-limitedtooncepersecond"""56r=requests.get(url)57r.raise_for_status()58pbar.update(1)59returnr606162def_write_image_file(r,image_name):63"""Writeanimagetoafile"""64filename=f"temp/{image_name}"65withopen(filename,"wb")asf:66f.write(r.content)676869if__name__=='__main__':70categories=sys.argv[1:]71download(categories)
該腳本可以下載原始圖像的子集,其中包含我們選擇的類別的邊框信息:
1$gitclonehttps://github.com/quiltdata/open-images.git2$cdopen-images/3$condaenvcreate-fenvironment.yml4$sourceactivatequilt-open-images-dev5$cdsrc/openimager/6$pythonopenimager.py"Sandwiches""Hamburgers"
圖像類別采用多級分層的方式。例如,類別三明治和漢堡包還都屬于食物類標簽。我們可以使用 Vega 將其可視化為徑向樹:

并不是開源圖像中的所有類別都有與之關聯的邊框數據。但這個腳本可以下載 600 類標簽中的任意子集,本文主要通過”漢堡包“和”三明治“兩個類別展開討論。
football,toy,bird,cat,vase,hairdryer,kangaroo,knife,briefcase,pencilcase,tennisball,nail,highheels,sushi,skyscraper,tree,truck,violin,wine,wheel,whale,pizzacutter,bread,helicopter,lemon,dog,elephant,shark,flower,furniture,airplane,spoon,bench,swan,peanut,camera,flute,helmet,pomegranate,crown…
二、圖像分割和處理
我們在本地處理圖像時,可以使用 matplotlib 顯示這些圖片:
1importmatplotlib.pyplotasplt2frommatplotlib.imageimportimread3%matplotlibinline4importos5fig,axarr=plt.subplots(1,5,figsize=(24,4))6fori,imginenumerate(os.listdir('../data/images/')[:5]):7axarr[i].imshow(imread('../data/images/'+img))
可見這些圖像并不容易訓練,也存在其他網站的源數據集所面臨的所有問題。比如目標類中可能存在不同大小、不同方向和遮擋等問題。有一次,我們甚至沒有成功下載到實際的圖像,只是得到一個占位符——我們想要的圖像已經被刪除了!
我們下載得到了幾千張這樣的圖片之后就要利用邊界框信息將這些圖像分割成三明治,漢堡。下面給出一組包含邊框的圖像:
帶邊界框
此處省略了這部分代碼,它有點復雜。下面要做的就是重構圖像元數據,剪裁分割圖像;再提取匹配的圖像。在運行上述代碼之后,本地會生成一個 images_cropped 文件夾,其中包含所有分割后的圖像。
三、建模
完成了下載數據,圖像分割和處理,就可以訓練模型了。接下來,我們對數據進行卷積神經網絡(CNN)訓練。卷積神經網絡利用圖像中的像素點逐步構建出更高層次的特征。然后對圖像的這些不同特征進行得分和加權,最終生成分類結果。這種分類的方式很好的利用了局部特征。因為任何一個像素與附近像素的特征相似度幾乎都遠遠大于遠處像素的相似度。
CNNs 還具有其他吸引之處,如噪聲容忍度和(一定程度上的)尺度不變性。這進一步提高了算法的分類性能。
接下來就要開始訓練一個非常簡單的卷積神經網絡,看看它是如何訓練出結果的。這里使用 Keras 來定義和訓練模型。
1、首先把圖像放在一個特定的目錄下
1images_cropped/2sandwich/3some_image.jpg4some_other_image.jpg5...6hamburger/7yet_another_image.jpg8...
然后 Keras 調用這些文件夾,Keras會檢查輸入的文件夾,并確定是二分類問題,并創建“圖像生成器”。如以下代碼:
1fromkeras.preprocessing.imageimportImageDataGenerator 2 3train_datagen=ImageDataGenerator( 4rotation_range=40, 5width_shift_range=0.2, 6height_shift_range=0.2, 7rescale=1/255, 8shear_range=0.2, 9zoom_range=0.2,10horizontal_flip=True,11fill_mode='nearest'12)1314test_datagen=ImageDataGenerator(15rescale=1/25516)1718train_generator=train_datagen.flow_from_directory(19'../data/images_cropped/quilt/open_images/',20target_size=(128,128),21batch_size=16,22class_mode='binary'23)2425validation_generator=test_datagen.flow_from_directory(26'../data/images_cropped/quilt/open_images/',27target_size=(128,128),28batch_size=16,29class_mode='binary'30)
我們不只是返回圖像本身,而是要對圖像進行二次采樣、傾斜和縮放等處理(通過train_datagen.flow_from_directory)。其實,這就是實際應用中的數據擴充。數據擴充為輸入數據集經過圖像分類后的裁剪或失真提供必要的補償,這有助于我們克服數據集小的問題。我們可以在單張圖像上多次訓練算法模型,每次用稍微不同的方法預處理圖像的一小部分。
2、定義了數據輸入后,接下來定義模型本身
1fromkeras.modelsimportSequential 2fromkeras.layersimportConv2D,MaxPooling2D 3fromkeras.layersimportActivation,Dropout,Flatten,Dense 4fromkeras.lossesimportbinary_crossentropy 5fromkeras.callbacksimportEarlyStopping 6fromkeras.optimizersimportRMSprop 7 8 9model=Sequential()10model.add(Conv2D(32,kernel_size=(3,3),input_shape=(128,128,3),activation='relu'))11model.add(MaxPooling2D(pool_size=(2,2)))1213model.add(Conv2D(32,(3,3),activation='relu'))14model.add(MaxPooling2D(pool_size=(2,2)))1516model.add(Conv2D(64,(3,3),activation='relu'))17model.add(MaxPooling2D(pool_size=(2,2)))1819model.add(Flatten())#thisconvertsour3Dfeaturemapsto1Dfeaturevectors20model.add(Dense(64,activation='relu'))21model.add(Dropout(0.5))22model.add(Dense(1))23model.add(Activation('sigmoid'))2425model.compile(loss=binary_crossentropy,26optimizer=RMSprop(lr=0.0005),#halfofthedefaultlr27metrics=['accuracy'])
這是一個簡單的卷積神經網絡模型。它只包含三個卷積層:輸出層之前的后處理層,強正則化層和 Relu 激活函數層。這些層因素共同作用以保證模型不會過擬合。這一點很重要,因為我們的輸入數據集很小。
3、最后一步是訓練模型
1importpathlib 2 3sample_size=len(list(pathlib.Path('../data/images_cropped/').rglob('./*'))) 4batch_size=16 5 6hist=model.fit_generator( 7train_generator, 8steps_per_epoch=sample_size//batch_size, 9epochs=50,10validation_data=validation_generator,11validation_steps=round(sample_size*0.2)//batch_size,12callbacks=[EarlyStopping(monitor='val_loss',min_delta=0,patience=4)]13)1415model.save("clf.h5")
epoch 步長的選擇是由圖像樣本大小和批處理量決定的。然后對這些數據進行 50 次訓練。因為回調函數 EarlyStopping 訓練可能會提前暫停。如果在前 4 個 epoch 中沒有看到訓練性能的改進,那么它會在 50 epoch 內返回一個相對性能最好的模型。之所以選擇這么大的步長,是因為模型驗證損失存在很大的可變性。
這個簡單的訓練方案產生的模型的準確率約為75%。
precisionrecallf1-scoresupport00.900.590.71139910.640.920.751109microavg0.730.730.732508macroavg0.770.750.732508weightedavg0.780.730.732508
有趣的是,我們的模型在分類漢堡包為第 0 類時信心不足,而在分類漢堡包為第 1 類時信心十足。90% 被歸類為漢堡包的圖片實際上是漢堡包,但是只分類得到 59% 的漢堡。
另一方面,只有 64% 的三明治圖片是真正的三明治,但是分類得到的是 92% 的三明治。這與 Francois Chollet 采用相似的模型,應用到一個相似大小的經典貓狗數據集中,所得到的結果為 80% 的準確率基本是一致的。這種差異很可能是谷歌 Open Images V4 數據集中的遮擋和噪聲水平增加造成的。數據集還包括其他插圖和照片,使分類更加困難。如果自己構建模型時,也可以先刪除這些。
使用遷移學習技術可以進一步提高算法性能。要了解更多信息,可以查閱 Francois Chollet 的博客文章:Building powerful image classification models using very little data,使用少量數據集構建圖像分類模型
https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html
四、模型發布
現在我們構建好了一個定制的數據集和訓練模型,非常高興可以與大家分享。基于此也進行了一些總結,機器學習項目應該是模塊化的可復制的,體現在:
將模型因素分為數據、代碼和環境組件
數據版本控制模型定義和訓練數據
代碼版本控制訓練模型的代碼
環境版本控制用于訓練模型的環境。比如環境可能是一個Docker文件,也可能在本地使用pip或conda
如果其他人要使用該模型,提供相應的{數據、代碼、環境}元組即可
遵循這些原則,就可以通過幾行代碼,訓練出需要的模型副本:
gitclonehttps://github.com/quiltdata/open-images.gitcondaenvcreate-fopen-images/environment.ymlsourceactivatequilt-open-images-devpython-c"importt4;t4.Package.install('quilt/open_images',dest='open-images/',registry='s3://quilt-example')"
結論
在本文中,我們演示了一個端到端的圖像分類的機器學習實現方法。從下載/轉換數據集到訓練模型的整個過程。最后以一種模塊化的、可復制的便于其他人重構的方式發布出來。由于自定義數據集很難生成和發布,隨著時間的積累,形成了這些廣泛使用的示例數據集。并不是因為他們好用,而是因為它們很簡單。例如,谷歌最近發布的機器學習速成課程大量使用了加州住房數據集。這些數據有將近 20 年的歷史了!在此基礎上應用新的數據,使用現實生活的一些有趣的圖片,或許會變得比想象中更容易!

有關文中使用的數據、代碼、環境等信息,可通過下面的鏈接獲取更多:
https://storage.googleapis.com/openimages/web/index.html
https://github.com/quiltdata/open-images
https://alpha.quiltdata.com/b/quilt-example/tree/quilt/open_images/
https://blog.quiltdata.com/reproduce-a-machine-learning-model-build-in-four-lines-of-code-b4f0a5c5f8c8
原文鏈接:
https://medium.freecodecamp.org/how-to-classify-photos-in-600-classes-using-nine-million-open-images-65847da1a319
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100995 -
圖像分類
+關注
關注
0文章
92瀏覽量
11944 -
數據集
+關注
關注
4文章
1209瀏覽量
24767
原文標題:輕松練:如何從900萬張圖片中對600類照片進行分類|技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
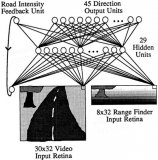
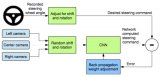
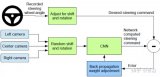
針對端到端自主駕駛模型的簡單對抗實例
基于生成式對抗網絡的端到端圖像去霧模型

一種對紅細胞和白細胞圖像分類任務的主動學習端到端工作流程

小鵬汽車發布端到端大模型

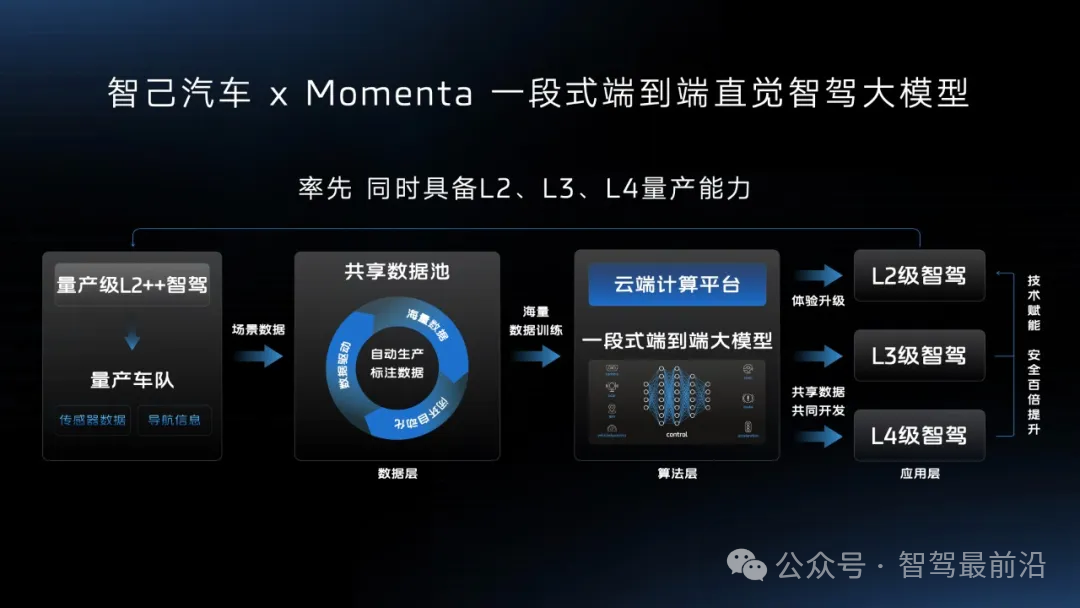
智己汽車“端到端”智駕方案推出,老司機真的會被取代嗎?
連接視覺語言大模型與端到端自動駕駛






 工商網監
工商網監
評論