 語義表征的無監督對比學習:一個新理論框架
語義表征的無監督對比學習:一個新理論框架
諸如圖像、文本、視頻等復雜數據類型的語義表征 (也稱為語義嵌入) 已成為機器學習的核心問題,并在機器翻譯、語言模型、GAN、域遷移等領域中出現。這些都會涉及學習表征函數,即每個數據點的表征信息都是“高級別” (保留語義信息,同時丟棄低級細節,如圖像中單個像素的顏色等) 和“緊湊“ (低維)。衡量語義表征好壞的一個標準是,它能夠通過少量標記數據,使用線性分類器 (或其他低復雜度分類器) 來解決它們,從而大大簡化新分類任務的求解過程。
使用未標記數據進行無監督表示學習研究是當前該領域最感興趣的一個研究話題。一種常用的方法是使用類似于 word2vec 算法進行詞嵌入 (word embedding),這種方法適用于各種數據類型,如社交網絡、圖像、文本等數據。
那么,為什么這些方法能夠適用于如此多樣化環境中?這得益于一種新的理論框架 “A Theoretical Analysis of Contrastive Unsupervised Representation Learning” 的提出。作為該框架的聯合提出者,Misha Khodak 提出了一種非常簡單的假設,因為類似 word2vec 算法需要適用于一些完全不同的數據類型,而這些數據無法共享一個通用的貝葉斯生成模型。(有關這個空間的生成模型例子在早期關于 RAND-WALK 模型的文章中有過描述。)因此,這個框架也提出了一些新方法,用于設計訓練時的目標函數變體。本篇文章將詳細解釋這些方法。
論文鏈接:https://arxiv.org/abs/1902.09229
語義表征學習
首先,是否存在良好且廣泛適用的表征呢?在計算機視覺等領域,答案是肯定的,因為深度卷積神經網絡 (CNN) 在大型含多類別標簽數據集 (如 ImageNet) 上以高精度訓練時,最終會學習得到非常強大而簡潔的表征信息。網絡的倒數第二層——輸入到最終的 softmax 層,可以在其他新的視覺任務中用作圖像的良好語義嵌入。(同樣,訓練后網絡中的其他層也可以作為良好的嵌入)。實際上,使用這種通過在大型多類別數據集上進行預訓練得到網絡,將其作為其他任務的語義嵌入已經在計算機視覺領域研究中廣泛使用,這允許一些新的分類任務只需要非常少的標記數據,使用低復雜度分類器 (如線性分類器) 來解決。因此,嘗試通過未標記的數據來學習語義嵌入信息,這已經成為一條黃金準則。
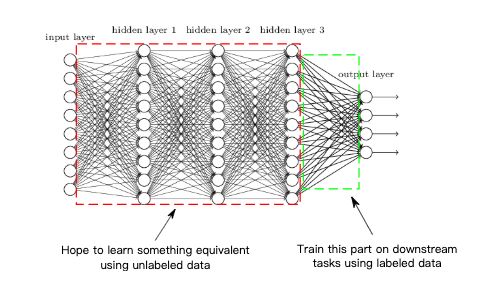
類似 word2vec 的方法:CURL
自 word2vec 方法取得成功以來,一些相似的方法也被用于學習諸如句子、段落、圖像和生物序列等數據的嵌入信息。所有這些方法都是基于一個關鍵性的想法:即利用相似數據點對 x、x+,并學習嵌入函數 f 。嵌入函數是 f(x) 和 f(x+) 的內積表示,通常高于 f(x) 和 f(x-) 的內積和 (這里的 x- 是一個與 x 不相似的隨機數據點)。在實踐中,尋找相似數據點通常需要使用一些啟發式方法,常用的方法是共現 (co-occurrences)。例如,在一個大型的文本語料庫中,相似數據點可以通過連續的句子、視頻剪輯中的相鄰幀,同一圖像中的不同補丁等找到。
這種方法的一個代表性例子是來自 Logeswaran 和 Lee 提出的 Quick Thoughts (QT),這是當前許多無監督文本嵌入任務中最先進的方法。對于一個大型文本語料庫中,為了學習一個表征函數 f,QT 將損失函數最小化,其數學表達式如下:
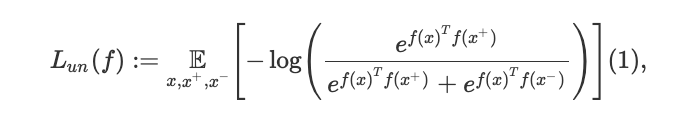
這里,(x,x+) 表示的是連續句子中語義相似的數據點,x- 代表一個隨機的負樣本。例如,對于圖像而言, x 和 x+ 可能是視頻中的相鄰幀。對于文本而言,兩個連續的句子是選擇相似數據點的良好選擇。例如,以下是維基百科中對 word2vec 進行解釋的的兩個連續句子案例:“High frequency words often provide little information”和“Words with frequency above a certain threshold may be subsampled to increase training speed”。顯然,這兩個句子的相似數據點,比起任意隨機得到的句子對更多,學習者正好可以利用這一點。因此,從現在開始使用對比度無監督表示學習 (CURL) 來指代那些用于尋找相似數據對的方法,而本文的目標就是要分析這些方法。
需要一個新的框架
標準的機器學習框架都涉及最小化一些損失函數,且當在訓練數據點和測試數據點上的平均損失大致相同時,則認為模型的學習是成功的 (或具有泛化能力)。然而,在對比學習(contrastive learning,CL )中,測試時使用的目標函數通常與訓練的目標函數不同:泛化誤差并不能作為解決這類問題的正確方法。
早期在這方面所使用的方法包括核學習 (kernel learning) 和半監督學習 (semi-supervised learning),但在訓練時通常至少需要一些帶標簽的數據,這些樣本來自未來感興趣的分類任務。使用簡單的設置也可以構建帶生成模型的貝葉斯方法,但這種方法已被證明難以解決諸如圖像和文本等復雜數據問題。此外,上面所說的類似 word2vec 的簡單方法似乎無法像貝葉斯優化器那樣,以清楚直接的方式操作,且同時適用于一些不同的數據類型。
因此,本文通過提出一個新的框架來解決這個問題,該框架規范地定義了 “語義相似” 的概念,這是其他算法所沒有的。此外,它還進一步說明為什么對比學習 能夠提供良好的表征,以及在這種情況下一個良好表征的意義。
框架
顯然,對比學習中使用隱式 / 啟發式定義的相似性概念,以某種方式與下游任務 (downstream tasks) 相關聯。例如,相似性帶有強烈的隱含意義,即在許多下游任務中 “相似對” 往往被分配相同的標簽 (雖然這本身沒有硬性保證)。而本文提出了一種極簡的框架來簡單形式化這種相似性概念。為了方便說明,以下將數據點稱為“圖像”。
語義相似性
我們假設大自然有許多類圖像,所有類集合 C 有一個度量標準 ρ。因此,當需要選擇一個類時,我們將以概率 ρ(c) 選擇類別 c。每個類別 c 在圖像上都具有一個相關分布 Dc,即在需要提供類別 c 的示例 (如選擇類別“狗”),則它將以概率 Dc (x) 選擇圖像 x。請注意,在這里類別之間可以有任意的重疊,也可以互相獨立不重疊。為了公式化語義相似性的概念,在這里假設當需要提供相似圖像時,使用度量 ρ 從集合 C 中選擇一個類別 c+,然后選擇兩個來自 Dc + 的獨立同分布樣本 x,x+。隨后再從度量 ρ 中選擇另一個類別 c-,并從 Dc- 中隨機挑選不相似樣本 x-。
如下式,表征學習訓練的目標函數使用早期的 QT 目標,但基于當前的框架繼承了以下解釋:
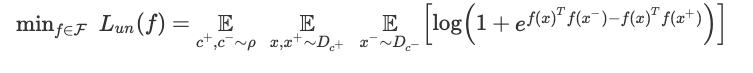
值得注意的是,函數類 F 是一個任意的深度網絡結構。該架構將圖像映射到嵌入空間 (神經網絡沒有最后一層),并通過梯度下降 / 反向傳播法來學習 f。當然,目前還沒有理論可以解釋復雜的深度網絡在什么時候算訓練成功,因此,這里提出的框架會假設當梯度下降已經導致某些表征 f 達到很低的損失時認為達到了最優狀態,并研究它在下游分類任務中的表現。
測試表征
用什么來定義一個好的表征呢?這里我們假設通過它,使用一個線性分類器解決二進制分類任務,來衡量表征的質量。(此外,本文還研究了下游任務中 k 類分類任務的情況)。那么如何選擇這個二進制分類任務?我們根據度量 ρ 隨機選取兩個類別 c1、c2,并根據相關的概率分布 Dc1、Dc2 為每個類別選擇數據點。然后使用該表征,通過邏輯回歸來解決該二進制任務:即找到兩個向量 w1、w2 來最小化以下損失。
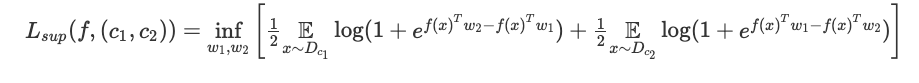
這里用二分類任務的平均損失來衡量表征的質量:
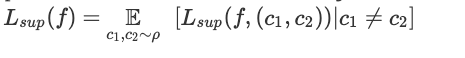
還值得注意的是,對于潛在類別中的未標記數據,將以相同類別在分類任務中出現。這允許我們可以公式化上面所提到的 “語義相似性” 的意義:即數據點更頻繁地出現在一起的類別,構成了相關分類任務的類別。如果類別數很大的話,那么在無監督訓練時使用的數據可能不會在測試階段涉及。實際上,我們希望所學習的表征能夠對那些潛在的、看不見的分類任務有用。
無監督學習的保證
該理論框架的理想結果是什么?假設我們固定一種類別的表征函數 F,并可以通過 ResNet 50 結構,選擇結構層尺寸來計算它。
雖然可以使用 Rademacher complexity arguments 來控制學習近似最小化器時所需的未標記數據對的數量,但實際上,這種理想環境中的原理是不可能實現的。因為我們可以展示一個簡單類別 F,它的對比目標無法產生可媲美最好類別所產生的表征。無需驚訝,這只是表明:想要實現這樣一個理想結果,需要比上述結果做出更多的假設。
相反,本文所提出的框架證明,當對比學習結束時無監督損失恰好較小,則所得到的表征在下游的分類任務中能夠表現良好。
這表明無監督損失函數可以被視為是使用線性分類方法解決下游任務時的一種性能替代,因此對其進行最小化是有意義的。此外,在未來的下游任務中,線性分類器學習只需要少數帶標簽的樣本數據。因此,所提出的框架可以為對比學習提供保證,同時也能夠突出它所提供的在標簽樣本復雜性方面的優勢。
鏈接:https://arxiv.org/abs/1902.09229
理論分析的擴展
這個理論框架不僅能夠推理 (1) 成功的變體,還能夠設計理論上新的無監督目標函數。
先驗(priori),可以想象是 (1) 中關于對數和指數的一些信息論解釋;同時,將函數形式與用于下游分類任務的邏輯回歸聯系起來。類似地,如果通過 hinge loss 進行分類的話,那么在 (2) 中將使用 hinge-like loss 作為不同的無監督損失。例如,Wang 和 Gupta 論文中的目標函數被用于從視頻中學習圖像表征。此外,通常在實踐中,k> 1 個負樣本與每個正樣本 (x,x+) 形成對比,而無監督的目標函數看起來像 k 類交叉熵損失形式。對于這種設置,事實上監督損失是與 (2) 中類似的 k + 1 類的分類損失。
最后,在相似數據可用時,該框架提供了用于設計新的無監督目標的方法 (如段落中的句子)。將 (1) 中的 f(x+) 和 f(x-) 分別替換為正、負樣本表征的平均值,那么將得到一個新的目標函數,它在實踐中具有更強的保證和更好的性能。最后,本文將通過實驗來驗證該變體的有效性,具體結果如下。
實驗
接下來,我們將通過一些對照實驗來驗證所提出的理論。由于缺乏對多類別文本的規范說明,實驗中使用一個新的含 3029 個類別的標簽數據集,這些類別是來自維基百科網站上 3029 篇文章,每個數據點對應這些文章中 200 條句子中的一條。所學習的表征信息將在隨機的二進制分類任務上進行測試,該分類任務涉及兩篇文章,其中數據點對應的類別是其所屬的兩篇文章中的一篇 (同樣,以這種方式定義 10 分類任務)。在訓練表征時,將保持測試任務的數據點。句子表征 F 是基于門控遞歸單元 (GRU) 的簡單多層結構。
基于上述的黃金標準,在這里通過有監督地訓練 3029 類分類器并在最終的 softmax 層輸出之前層所學習的表征得到最終的結果。
而根據所提出的理論,無監督方法用于生成相似的數據點對:這些相似的數據點只是從同一篇文章中采樣得到的句子對。隨后通過最小化上述的無監督損失目標來學習表征。
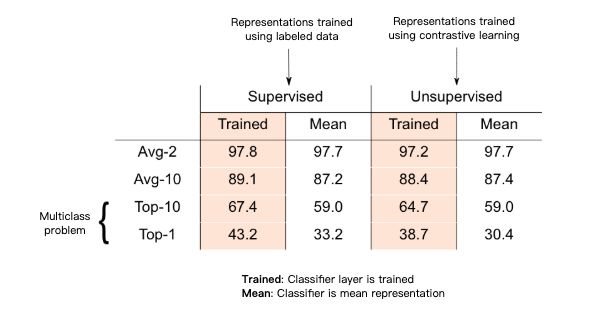
在上表中突出顯示的部分表明,無監督表征與在 k 分類監督任務上 (k = 2,10) 所習得的表征相當。
此外,即使在所提出的理論中沒有涉及,該表征也能夠在完整的多分類問題上表現出色:即每個類別的無監督表征均值 (質心) 是能夠在 k 分類監督任務中表現良好。而所得到的無監督表征和監督表征都是正確的。
此外,其他的實驗進一步研究負樣本數量和較大塊相似數據點的影響,包括 CIFAR-100 圖像數據集上的實驗等。
結論
盡管對比學習是一種眾所周知的直觀算法,但是否真正有效卻一直還未在實踐中得到證實。本文所提出的理論框架,為使用此類算法學習表征提供了保證。在闡述這些算法的同時,該框架還能進一步提出并分析它的變體,并提供相應的解釋證明,以便形成并探索更強保證的新假設。此外,基于該框架,還能進行一些擴展,包括對潛在類別強加一個度量結構,元學習 (meta-learning) 與遷移學習 (transfer learning) 之間建立聯系等。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100792 -
圖像
+關注
關注
2文章
1085瀏覽量
40475 -
函數
+關注
關注
3文章
4332瀏覽量
62641
原文標題:語義表征的無監督對比學習:一個新理論框架
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于半監督學習框架的識別算法
無監督學習的理論解釋與實踐教程
你想要的機器學習課程筆記在這:主要討論監督學習和無監督學習
機器學習算法中有監督和無監督學習的區別
分析總結基于深度神經網絡的圖像語義分割方法






 工商網監
工商網監
評論