 富士通實驗室在74.7秒內完成了ImageNet上訓練ResNet-50網絡
富士通實驗室在74.7秒內完成了ImageNet上訓練ResNet-50網絡
ImageNet 訓練紀錄再次被刷新!富士通實驗室在 74.7 秒內完成了 ImageNet 上訓練 ResNet-50 網絡,使用 2048 個 GPU,準確率為 75.08%,刷新了此前谷歌 1.8 分鐘的記錄。
在過去兩年中,深度學習的速度加速了 30 倍。但是人們還是對 “快速執行機器學習算法” 有著強烈的需求。
Large mini-batch 分布式深度學習是滿足需求的關鍵技術。但是由于難以在不影響準確性的情況下在大型集群上實現高可擴展性,因此具有較大的挑戰難度。
最近,富士通實驗室的一項研究刷新了一項紀錄:

論文地址:
https://arxiv.org/pdf/1903.12650.pdf
這項研究在74.7 秒內完成了 ImageNet 上訓練 ResNet-50 網絡,使用 2048 個 GPU,準確率為 75.08%,刷新了此前谷歌 1.8 分鐘的記錄。

表1:ImageNet上訓練ResNet-50的記錄
增加 mini-batch 大小,實現短時間內的高準確性
基于大數據集的深度神經網絡 (DNN) 模型在對象檢測、語言翻譯等領域取得了令人矚目的成果。然而,隨著 DNN 模型和數據集規模的增大,DNN 訓練的計算量也隨之加劇。
具有數據并行性的分布式深度學習是加速集群訓練的一種有效方法。
在這種方法中,集群上啟動的所有進程都具有相同的 DNN 模型和權重。每個過程都用不同的 mini-batch 訓練模型,但是來自所有過程的權重梯度被組合以更新所有權重。
對于大型集群,這種通信開銷成為一個重要的問題。
為了減少大型集群的開銷,該研究增加了 DNN 的 mini-batch 大小,且并行計算了 DNN 訓練。然而,在 minni-batch 訓練中,DNN 模型的驗證精度普遍較差。
因此,研究者們采用了幾種技術來增加 mini-batch 的大小,這表明了在迭代中計算的輸入圖像的數量,而不會影響驗證的準確性。
在實驗過程中,本文使用了人工智能橋接云基礎設備 (AI Bridging Cloud Infrastructure,ABCI) 集群 GPU和自優化的 MXNet 深度學習框架。并在 ImageNet 上使用 81,920 mini-batch 大小,74.7 秒內實現了 ResNet-50 的 75.08%驗證準確度。
技術方法三部曲
本文的技術方法主要分為三個部分:準確性改良、框架優化和通信優化。
A. 準確性改良
這部分采用了通常用于深度學習優化器的隨機梯度下降(SGD)。在對 large mini-batch 進行訓練時,SGD 更新的數量隨著小型批大小的增加而減少,因此提高 large mini-batch 的最終驗證精度是一個很大的挑戰,本文采用了以下技術。
學習速率控制:由于更新數量較少,需要使用高學習率來加速訓練。 然而,高學習率使得模型訓練在早期階段不穩定。 因此,我們通過使用逐漸提高學習率的預熱 (warmup) 來穩定 SGD。此外,對于某些層,所有層的學習速率都太高了,還通過使用層次自適應速率縮放(LARS)來穩定訓練,LARS 根據規范權重和梯度調整每層的學習速率。
其它技術:據報道,標簽平滑提高了 32,768 個 mini-batch 的準確性。本文也采用了這種方法,并對 81920 個 mini-batch 進行了精度改進。
batch 標準化層的均值和方差的移動平均 (moving average) 在每個過程中獨立計算,而權重是同步的。這些值在 large mini-batch 上變得不準確;因此,本文調整了一些超參數來優化移動平均線。
B. 框架優化
我們使用了 MXNet,MXNet 具有靈活性和可擴展性,能夠在集群上高效地訓練模型。然而,在中小型集群環境中只占總時間的一小部分的處理方式可能成為大規模集群環境中的瓶頸。我們使用了幾個分析器來分析 CPU 和 GPU 性能,找出了瓶頸。我們對瓶頸進行了優化,提高了訓練吞吐量。
1) 并行 DNN 模型初始化:
在數據并行分布式深度學習中,必須初始化所有層,使所有進程的權重相同。通常,根進程初始化模型的所有權重。然后,進程將這些權重傳遞 (broadcast) 給所有進程。傳遞時間隨著進程數量的增加而增加,在有成千上萬個進程進行分布式深度學習時,其成本不可忽視。
因此,我們采用了其他初始化方法,即每個進程具有相同的種子并并行地初始化權重。這種方法無需 broadcast 操作就可以同步初始權重。
2) GPU 上的 Batch Norm 計算:
每層的 norm 計算都需要使用 LARS 更新權重。與 GPU 上的內核數量相比,ResNet-50 的大多數層沒有足夠的權重。如果我們在 GPU 上計算每一層的 weight norm,線程數不足以占據所有 CUDA 核心。因此,我們實現了一個特殊的 GPU 內核,用于 batched norm 計算到 MXNet。該 GPU 內核可以啟動足夠數量的線程,并且可以并行計算層的范數。
C. 通信優化
分布式并行深度學習要求所有 reduce 通信在所有進程之間交換每一層的梯度。在大集群環境中,由于每個 GPU 的 batch size 較小,使得通信時間變長,計算時間變短,因此 reduce communication 開銷是不可忽略的。為了克服這些問題,我們采用了以下兩種優化方法。
1) 調整通信的數據大小
2) 通信的優化調度
實驗設置與實驗結果
我們使用 ABCI 集群來評估基于 MXNet 的優化框架的性能。ABCI 集群的每個節點由兩個 Xeon Gold 6148 CPU 和四個 NVIDIA Tesla V100 SXM2 GPU 組成。此外,節點上的 GPU 由 NVLink 連接,節點也有兩個 InfiniBand 網絡接口卡。圖 1 為 ABCI 集群節點結構示意圖。

圖 1:ABCI 集群中一個計算節點的示意圖。它由兩個 GPU、四個 GPU 和兩個連接到相應 CPU 的 HCA 組成。
我們使用混合精度方法,使用半精度浮點數計算和通信,并使用單精度浮點數更新權重。我們使用了原始優化器,它可以很好地控制學習率。除了穩定訓練精度外,我們還使用了 warmup 和 LARS 技術。
我們對 ResNet-50 訓練的測量依據 MLPerf v0.5.0 規則。也就是說,我們度量了從 “run start” 到 “run final” 的運行時間,其中包括初始化和內存分配時間。
結果表明,優化后的 DNN 框架在 74.7 秒內完成了 ImageNet 上 ResNet-50 的訓練,驗證精度為 75.08%。

圖 2:優化后的框架的可擴展性用實線表示,虛線表示理想曲線。
我們還測量了 ResNet-50 的可擴展性。圖 2 顯示了根據 GPU 數量計算的吞吐量。在圖 2 中,虛線表示理想的每秒圖像吞吐量,實線表示我們的結果。如圖表明,直到 2048 個 GPU,我們的框架的可擴展性都非常好。使用 2048 個 GPU 的吞吐量為每秒 170 萬張圖像,可擴展性為 77.0%。
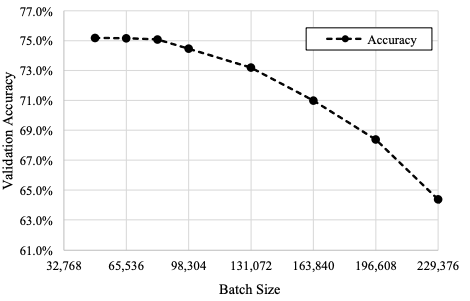
圖 3:在 49152 個或更大的 mini-batch 訓練中,top-1 驗證精度的變化
圖 3 顯示了 81,920 個或更大的 mini-batch 訓練中 top-1 驗證精度的結果。從圖 3 中可以看出, mini-batches 超過 81,920 個的驗證精度低于 74.9%,不符合 MLPerf 規定。因此,ImageNet 數據集一個 epoch 的圖像數量為 1,280,000 張,如果使用 81,920 mini-batch,一個 epoch 中的更新數量僅為 16 張,其中更新總數為 1,440 張。這個數字太小,SGD 求解器無法訓練 DNN 權重。因此,使用大的 mini-batch 是一個很大的挑戰,我們嘗試使用盡可能大的 mini-batch。
如表 1 所示,與其他工作相比,81,920 mini-batch size 已經很大,驗證精度達到 75% 以上。

圖 4:訓練精度與驗證精度之比較
圖 4 顯示了訓練精度與驗證精度的對比。從圖中可以看出,使用 batch normalization 和 label smoothing 技術,我們的驗證精度結果并沒有過擬合。
結論
我們開發了一種新的技術,可以在大規模 GPU 集群上使用 large mini-batch,而不會降低驗證精度。我們將該技術應用到基于 MXNet 的深度學習框架中。使用 81920 minibatch size,我們的 DNN 訓練結果在 74.7 秒內訓練完 ResNet-50,驗證精度達到 75.08%。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101082 -
gpu
+關注
關注
28文章
4768瀏覽量
129261 -
機器學習
+關注
關注
66文章
8438瀏覽量
132973
原文標題:74.7秒訓練完ImageNet!刷新記錄,2048 GPU暴力出奇跡
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
錘子手機發布會羅永浩提到的富士通
【FireBLE申請】無線智能實驗室管理系統的研究
網絡實驗室的構建及其在實驗教學中的應用
富士通微電子攜手西安電子科技大學成立MCU“聯合實驗室”
芯片實驗室15秒就可完成流感檢測
網絡虛擬實驗室及實現方法
富士通在廣東設立信息通信技術實驗室 全面部署中國
美國實驗室特寫:等離子物理實驗室制造的微型太陽

深度學習上演“皇帝的新衣”如何剖析CoordConv?
索尼發布新的方法,在ImageNet數據集上224秒內成功訓練了ResNet-50
華為云刷新深度學習加速紀錄
AI可識別語音情感模型 在1.2秒內判斷你的憤怒
富士通宣布打破了ImageNet的訓練速度記錄——在74.7秒內達到75%的準確率
基于改進ResNet50網絡的自動駕駛場景天氣識別算法






 工商網監
工商網監
評論