 Google又放大招,高效實時實現視頻目標檢測
Google又放大招,高效實時實現視頻目標檢測
圖像目標檢測是圖像處理領域的基礎。自從2012年CNN的崛起,深度學習在Detection的持續發力,為這個領域帶來了變革式的發展:一個是基于RPN的two-stage,RCNN/Fast RCNN/Faster RCNN、RetinaNet、Mask RCNN等,致力于檢測精度的提高。一類是基于SSD和YOLOv1/v2/3的one-stage,致力于提高檢測速度。
視頻目標檢測要解決的問題是對于視頻中每一幀目標的正確識別和定位。相對于圖像目標檢測,視頻是高度冗余的,包含了大量時間局部性(temporal locality,即在不同的時間是相似的)和空間局部性(spatial locality,即在不同場景中看起來是相似的),既Temporal Context(時間上下文)的信息。充分利用好時序上下文關系,可以解決視頻中連續幀之間的大量冗余的情況,提高檢測速度;還可以提高檢測質量,解決視頻相對于圖像存在的運動模糊、視頻失焦、部分遮擋以及形變等問題。
視頻目標檢測和視頻跟蹤不同。兩個領域解決相同點在于都需要對每幀圖像中的目標精準定位,不同點在于視頻目標檢測不考慮目標的識別問題,而跟蹤需要對初始幀的目標精確定位和識別。
圖1 高德地圖車載AR導航可識別前方車輛并提醒
視頻目標檢測應用廣泛,如自動駕駛,無人值守監控,安防等領域。如圖1所示,高德地圖車載AR導航利用視頻目標檢測,能夠對過往車輛、行人、車道線、紅綠燈位置以及顏色、限速牌等周邊環境,進行智能的圖像識別,從而為駕駛員提供跟車距離預警、壓線預警、紅綠燈監測與提醒、前車啟動提醒、提前變道提醒等一系列駕駛安全輔助。
視頻目標檢測算法一般包括單幀目標檢測、多幀圖像處理、光流算法、自適應關鍵幀選擇。Google提出基于Slownetwork 和Fast network分別提取不同特征,基于ConvLSTM特征融合后生成檢測框,實現實時性的state-of-art。

論文地址:https://arxiv.org/abs/1903.10172
1 Motivation
物體在快速運動時,當人眼所看到的影像消失后,人眼仍能繼續保留其影像,約0.1-0.4秒左右的圖像,這種現象被稱為視覺暫留現象。人類在觀看視頻時,利用視覺暫留機制和記憶能力,可以快速處理視頻流。借助于存儲功能,CNN同樣可以實現減少視頻目標檢測的計算量。
視頻幀具有較高的時序冗余。如圖2所示,模型[1]提出使用兩個特征提取子網絡:Slow network 和Fast network。Slow network負責提取視頻幀的精確特征,速度較慢,Fast network負責快速提取視頻幀的特征提取,準確率較差,兩者交替處理視頻幀圖像。Fast network和Slow network特征經過ConvLSTM層融合并保存特征。檢測器在當前幀特征和上下文特征融合基礎上生成檢測框。論文提取基于強化學習策略的特征提取調度機制和需要保存特征的更新機制。
論文提出的算法模型在Pixel 3達到72.3 FPS,在VID 2015數據集state-of-art性能。
論文創新點:
1、提出基于存儲引導的交替模型框架,使用兩個特征提取網絡分別提取不同幀特征,減少計算冗余。
2、提出基于Q-learning學習自適應交替策略,取得速度和準確率的平衡。
3、在手機設備實現迄今為止已知視頻目標檢測的最高速度。
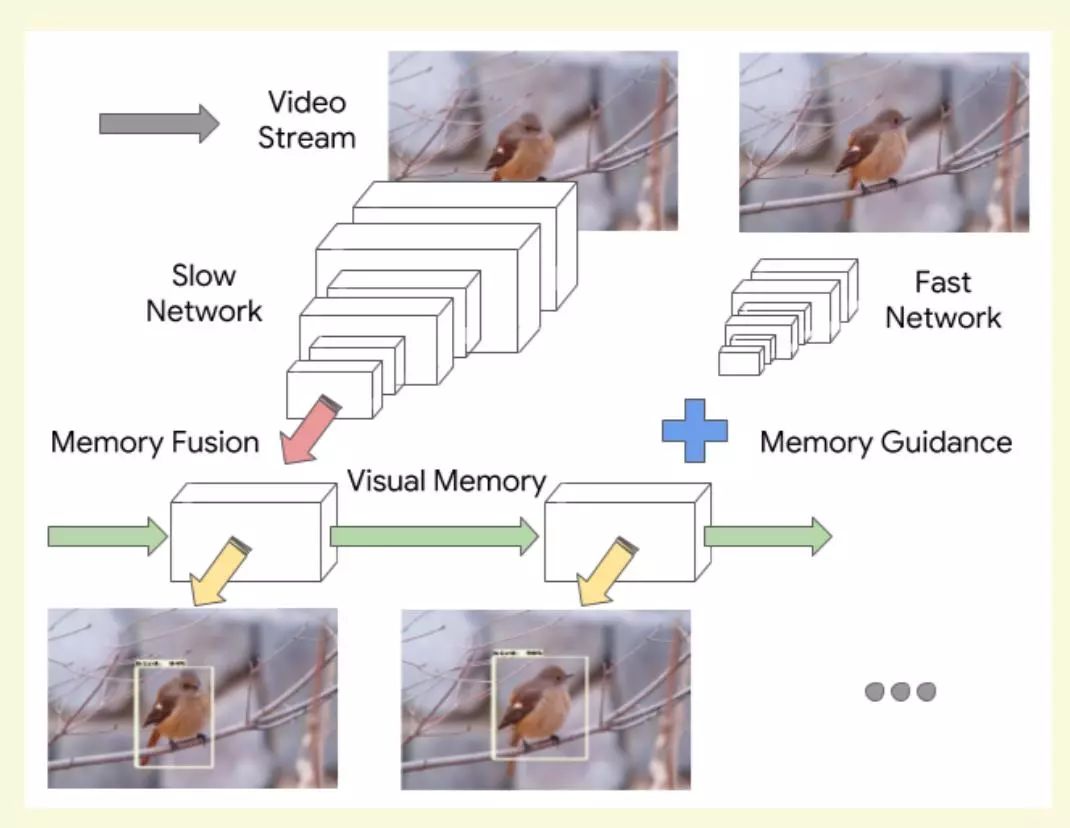
圖2 存儲引導的交錯模型
2網絡架構
2.1交錯模型
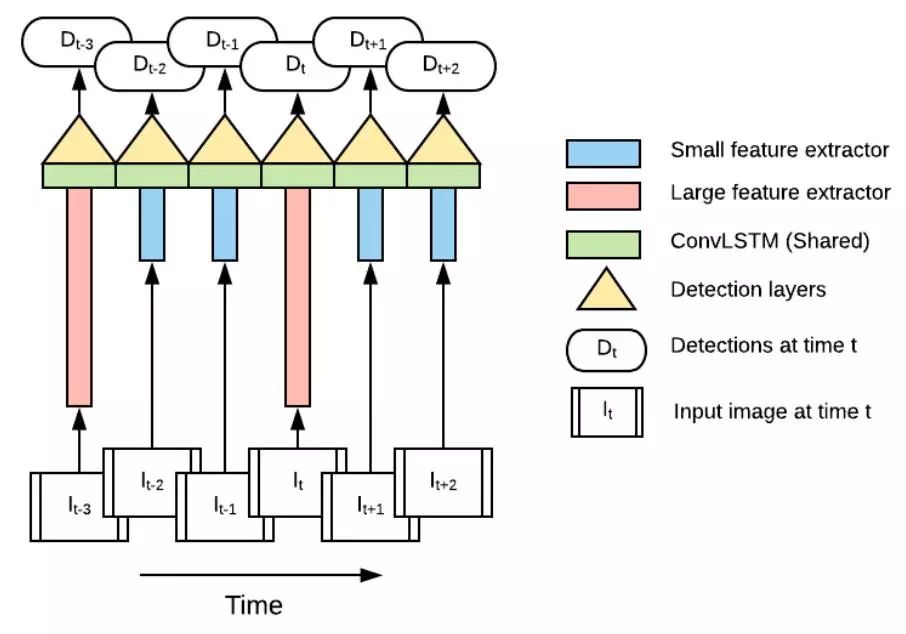
圖3交錯模型
如圖3所示論文提出的交錯模型(τ = 2),Slow network(Large featureextractor)和Fastnetwork(Small feature extractor)均由MobileNetV2構成(兩個模型的depth multiplier不同,前者為1.4,后者為0.35),anchors比率限制為{1.0,0.5,2.0}。
2.2存儲模型
LSTM可以高效處理時序信息,但是卷積運算量較大,并且需要處理所有視頻幀特征。論文提出改進的ConvLSTM模型加速視頻幀序列的特征處理。
ConvLSTM是一種將CNN與LSTM在模型底層結合,專門為時空序列設計的深度學習模塊。ConvLSTM核心本質還是和LSTM一樣,將上一層的輸出作下一層的輸入。不同的地方在于加上卷積操作之后,為不僅能夠得到時序關系,還能夠像卷積層一樣提取特征,提取空間特征。這樣就能夠得到時空特征。并且將狀態與狀態之間的切換也換成了卷積計算。
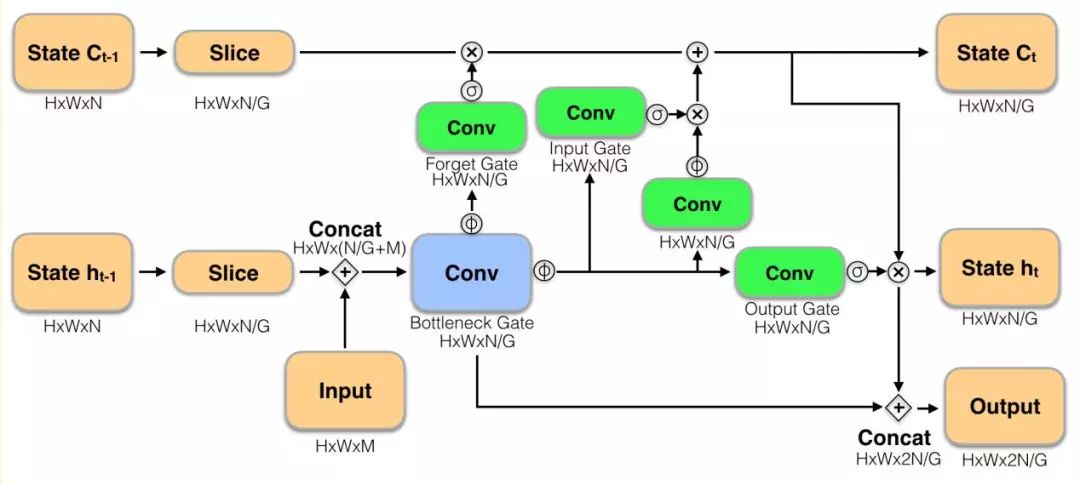
圖4 存儲模型LSTM單元
如所示,論文的ConvLSTM有一下改進:
1、增加Bottleneck Gate和output跳躍連接。
2、LSTM單元分組卷積。特征圖HxWxN分為G組,每個LSTM僅處理HxWxN/G的特征,加速ConvLSTM計算。論文中G = 4。
3、LSTM有一固有弱點,sigmoid激活輸入和忘記門很少完全飽和,導致緩慢的狀態衰減,長期依賴逐漸喪失,更新中無法保留完整的前期狀態。導致Fast network運行中,Slownetwork特征緩慢消失。論文使用簡單的跳躍連接,既第一個Fast network輸出特征重復使用。
2.3推斷優化
論文提出基于異步模式和量化模型,提高系統的計算效率。
1、異步模式。交錯模型的短板來自于Slow network。論文采用Fastnetwork提取每幀圖像特征,τ = 2幀采用Slow network計算特征和更新存儲特征。Slownetwork和Fast network異步進行,提高計算效率。
2、在有限資源的硬件設備上布置性能良好的網絡,就需要對網絡模型進行壓縮和加速,其中量化模型是一種高效手段。基于[2]算法,論文的ConvLSTM單元在數學運算(addition,multiplication, sigmoid and ReLU6)后插入量化計算,確保拼接操作的輸入范圍相同,消除重新縮放的需求。
3 實驗
模型在Imagenet DET 和COCO訓練,在Imagenet VID 2015測試結果如圖5所示。
從測試結果看,系統只有Slow network模塊時準確率最高, 只有Fast network模塊時準確率最低,但是速度沒有交錯模型快,比較詫異。另外基于強化學習的adaptive對精度和速度幾乎沒有影響,而異步模式和模型量化提高系統的實時性。
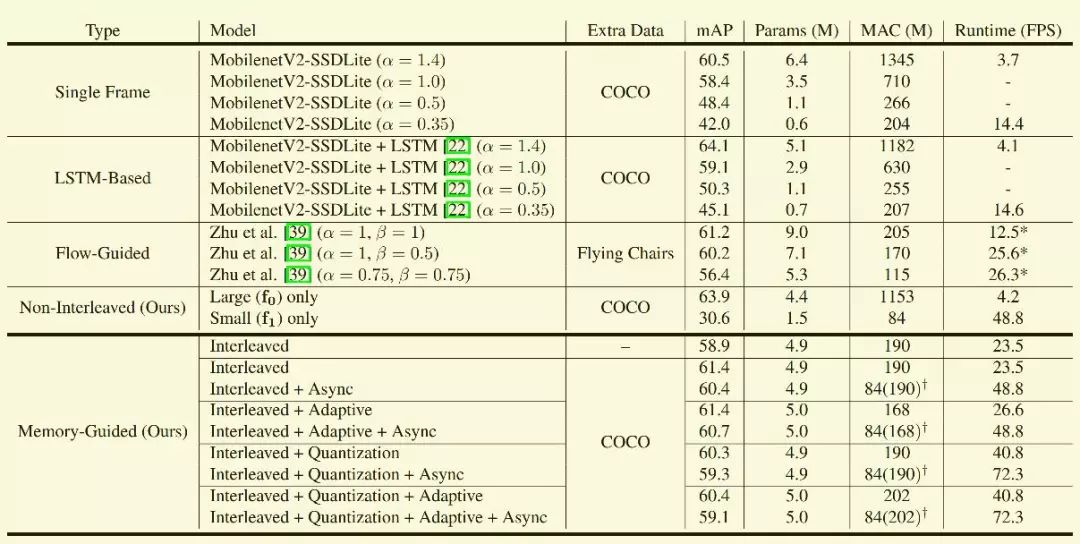
圖5 Imagenet VID 2015測試結果
4 優缺點分析
視頻處理策略
1、基于強化學習的交錯模型調度是偽命題。論文的Slow network提取強特征,Fastnetwork提取弱特征,交錯模型的τ越大,模型性能越差。理論上τ=2時模型的準確率越高。綜合考慮準確率和實時性,論文中τ=9。
2、視頻具有很強的上下文相關性。視頻理解領域的目標檢測、分割、識別,跟蹤,等領域,都需要提取前后幀的運動信息,而傳統采用光流方式,無法保證實時性。本文提出的分組ConvLSTM,可加速計算,量化模型保持準確率,具有借鑒意義。
以上僅為個人閱讀論文后的理解、總結和思考。觀點難免偏差,望讀者以懷疑批判態度閱讀,歡迎交流指正。
參考文獻
[1] MasonLiu, Menglong Zhu, Marie White, Yinxiao Li, Dmitry Kalenichenko.Looking Fastand Slow: Memory-Guided Mobile Video Object Detection.arXivpreprint arXiv:1903.10172,2019.
[2] B.Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard,H. Adam, and D.Kalenichenko. Quantization and training of neural networks for efficientinteger-arithmetic-only inference. In CVPR, 2018.
-
Google
+關注
關注
5文章
1765瀏覽量
57559 -
目標檢測
+關注
關注
0文章
209瀏覽量
15613
原文標題:Google又發大招:高效實時實現視頻目標檢測
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
案例分享 ▏基于HZ-EVM-RK3576開發板實現YOLOv5目標檢測應用

在樹莓派上部署YOLOv5進行動物目標檢測的完整流程
使用OpenVINO C# API部署YOLO-World實現實時開放詞匯對象檢測

目標檢測與識別技術的關系是什么
目標檢測識別主要應用于哪些方面
基于FPGA的實時邊緣檢測系統設計,Sobel圖像邊緣檢測,FPGA圖像處理
在控道AI盒子上基于YOLOv9實現實時目標檢測實戰

OpenVINO工具包部署YOLO9模型實現實時目標檢測
百度開源DETRs在實時目標檢測中勝過YOLOs
AI驅動的雷達目標檢測:前沿技術與實現策略

在ELF 1 開發板上實現讀取攝像頭視頻進行目標檢測






 工商網監
工商網監
評論