 解密最熱AI“芯”話題 2019全球人工智能應用創新峰會在深圳舉行
解密最熱AI“芯”話題 2019全球人工智能應用創新峰會在深圳舉行
2019年4月9日,第二屆全球人工智能應用創新峰會在深圳五洲賓館舉行,這場由深圳市科學技術協會、福田區科技創新局主辦,鯤云科技、鯤云人工智能應用創新研究院和源創力創新中心承辦的AI開年盛會上,鯤云科技發布全球第一款基于數據流技術打造的通用人工智能底層架構-定制數據流CAISA架構和端到端自動編譯工具鏈RainBuilder,實現了國內完全自主產權的AI芯片架構,有效計算效率大幅領先國際水平,為人工智能算法的快速應用落地提供高性能算力支撐,推動我國人工智能芯片領域的技術革新和發展。
深圳市人大常委會副主任、深圳市科協主席蔣宇揚,深圳市福田區委常委、副區長黃偉,深圳市源創力離岸創新中心總裁周路明,深圳市科協秘書長、辦公室主任林肇武,深圳市福田區科技創新局、發展和改革局和工業和信息化局等單位負責同志出席峰會。
蔣宇揚主席致辭
黃偉副區長致辭
打破摩爾定律局限,鯤云發布全球首款通用底層AI架構-定制數據流CAISA架構
牛昕宇博士
作為本次峰會的重頭戲,鯤云科技創始人&CEO牛昕宇博士在會上發布了定制數據流CAISA2.0架構。依托創始團隊在數據流架構領域近三十年的積累,鯤云的CAISA架構拋棄了傳統基于指令集的架構方式,是全球第一款基于數據流技術打造的通用人工智能底層架構,可發揮90%以上的芯片峰值計算性能,大幅領先國際主流AI芯片。同時,鯤云還在會上發布了針對數據流架構定制開發的RainBuilder編譯工具鏈,CAISA2.0架構可支持Tensorflow,Caffe等開源框架下開發的主流深度學習算法的無縫遷移,無需用戶進行面向CAISA架構的編程。基于Arria10 SX160、SX660、GX1150,Straix10 GX2800系列的FPGA加速卡已完成開發并應用于產品落地中。
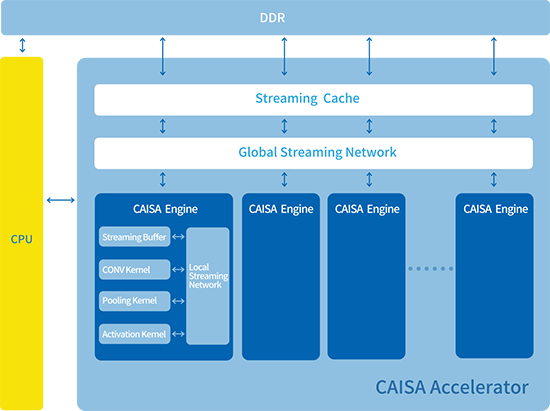
(定制數據流CAISA2.0架構)
隨著人工智能技術的深入發展,對人工智能芯片的算力提出了更高的要求,算力成為了決定算法落地的重中之重。尤其是在云計算、自動駕駛、安防工業等領域,算力的提升更是能夠直接帶來更多的用戶量、更多的前端設備智能升級和更安全的自動駕駛汽車。正如圖靈獎得主John Hennessey和 David Patterson在圖靈獎頒獎典禮所言,未來十年,隨著摩爾定律逐步飽和,人工智能芯片的峰值算力將逐步趨近飽和,而架構效率將成為芯片性能的決定因素,未來十年將是計算架構的“黃金十年”。鯤云科技自主研發的CAISA2.0架構以及RainBuilder編譯工具鏈,沒有采用主流計算機架構下大規模并行指令集設計的思路,通過完全不同的數據流架構突破底層架構的效率瓶頸,最大化發揮底層硬件的效率,在同等峰值芯片性能情況下可以為人工智能應用提供更高的算力支撐。
打造最好用的AI芯片編譯工具,CAISA架構的端到端自動編譯工具鏈RainBuilder面世,讓人工智能更簡單
要實現更快的AI應用落地,滿足不同算法開發的需求,需要一個可以兼容各類算法框架和方便快捷實現算法到硬件寫入的編譯工具。為了降低使用門檻,鯤云發布了端到端自動編譯工具鏈RainBuilder,它是一款針對深度學習算法優化加速的開發工具鏈。依托于CAISA架構的高性能特性,RainBuilder提供從算法模型到芯片級算法部署的一整套開發套件。該套件主要由Compiler和Runtime兩部分組成,其中Compiler包含了一系列命令行接口,支持主流AI開發框架模型的解析和優化,并將模型轉化為適用于CAISA架構的中間表達和數據。Runtime以Compiler生成的中間表達和數據為輸入,為用戶提供了豐富易用的開發接口以完成對底層AI芯片硬件的高效應用。
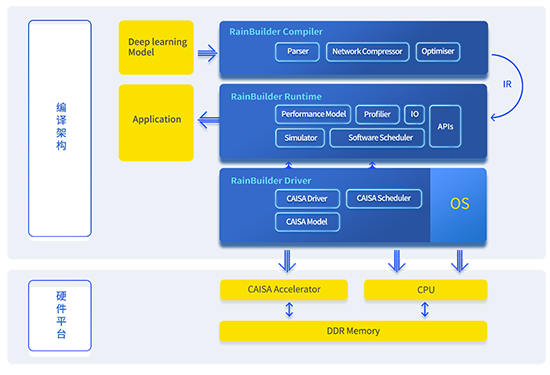
(RainBuilder端到端自動編譯工具鏈)
RainBuilder使用過程非常簡單便捷,用戶無需對于底層硬件有深入的了解,即可快速開發適用于AI專用芯片的算法方案。從訓練好的模型文件,只需兩步,即可實現整個神經網絡的推演。第一步,調用Compiler的命令行接口完成模型的離線準備,對于一個模型,該步驟只需進行一次。Compiler提供了一套端到端的優化流程,包括模型解析、冗余節點裁剪、節點融合、模型量化壓縮等。第二步,用戶只需編寫針對特定算法的前后處理函數,Runtime會自動完成算法模型對于CAISA架構的高效調用。Runtime中包含了大量針對CAISA架構的深層優化,如硬件資源調配、運行時資源調度、軟硬件并行、異常處理等。另外,RainBuilder通過支持用戶自定義算子實現了對于不同算法的高拓展性。用戶只需根據提供的接口即可完成自定義模塊的實現,RainBuilder會自動將自定義算子整合進計算圖中,并針對其特點完成相應的計算優化。
提供下一代人工智能計算平臺,鯤云公布基于CAISA架構的系列AI產品,鯤云高性能AI芯片切入工業市場
會上,鯤云還公布了基于CAISA架構的一系列產品,包括針對前端和邊緣計算的“雨人”AI芯片加速卡3代和應用于NVR和服務器的“星空”AI加速卡2代,目前已經在電力、安防、工業等領域實現了規模落地。同合作伙伴聯合開發的搭載雨人加速卡的AI攝像頭、智能無人機、智能ops系統盒子,搭載星空加速卡的兩款AI服務器也同時披露。
(雨人加速卡3代)
“雨人”加速卡可嵌入前端IoTs設備,提供深度學習目標定位、去重一體化前端方案,支持1080p高清實時視頻對于60x60像素特定目標全檢測,具有50幀/秒的處理能力。
(星空加速卡2代)
“星空”加速卡嵌入小型主機和服務器設備,即插即用,可同時支持16路1080p視頻中對最小60×60像素的特定目標全檢測及視頻結構化分析,實現1080P高清實時視頻200-800幀/秒的檢測性能,延時低至5毫秒,實測性能達理論峰值的90%。充分體現了自主研發的定制數據流CAISA架構芯片高性能、低功耗、低延時的特性,最大化資源能效比。可為安防行業中交通、商場和住宅等場景數字安全監控及行人、車輛、路況等提供深度學習目標定位、去重、識別、屬性分析一體化的邊緣后端人工智能加速方案。
鯤云高校計劃發布,聯合高校開展人工智能教學科研合作
為滿足高校日益增長的在人工智能領域教學培訓、科研平臺方面的需求,鯤云科技結合自身在人工智能芯片、開發平臺和垂直領域解決方案等方向的研發和技術優勢,以及與市場端廣泛的互動關系,由鯤云人工智能應用創新研究院發起,鯤云正式發布鯤云高校計劃CUP (Corerain University Program),與全球高校在人工智能課程、科研合作和國際交流等領域實現深度合作。
在課程方面,鯤云提供基于CAISA架構FPGA加速卡的人工智能課程及實驗內容,支持高校相關課程升級;在科研方面,鯤云支持高校基于CAISA架構運行最新人工智能算法,以及圍繞CAISA架構拓展硬件平臺;在國際合作領域,鯤云提供人工智能峰會、人工智能硬件加速暑期峰會等國際交流平臺,全方位支持與高校在AI領域的合作,加速最新AI技術的產學研合作。
2019年2 月24日,鯤云高校計劃啟動,聯手英特爾開展的基于Intel? FPGA的人工智能芯片應用設計培訓的交流活動完美落幕,來自清華大學、武漢大學、華中科技大學、山東大學、天津大學、重慶大學、電子科技大學等近30所高校的40余位老師參加。除與Intel合作進行人工智能課程培訓外,鯤云人工智能應用創新研究院已同帝國理工學院、哈爾濱工業大學、天津大學等成立聯合實驗室,在定制計算、AI芯片安全、工業智能等領域開展前沿研究合作。
高端會晤,國際AI領域權威分享人工智能前沿技術突破
作為年度重量級AI峰會,此次活動匯聚了政府領導、全球人工智能領域頂尖學術大師、世界頂級科技企業、互聯網巨頭,產業界、投資界行業領袖,共同探討人工智能實戰落地和產學研發展方向。整個峰會由政府致辭、主題演講和產業論壇三個環節組成。會上,幾位人工智能領域的國際權威分享了各自領域的最新進展和應用方向。
貢三元教授
IEEE終身會士Sun Yuan Kung(貢三元)教授是人工智能神經網絡學界大咖,他分享了反向傳播算法的問題及如何解決這些問題,將AI帶入3.0時代。眾所周知,今年的圖靈獎授予給發明反向傳播算法,也就是BP算法的Geoffrey Hinton教授。可以說BP算法是深度學習的基石之一,但是它也存在不可解釋性和梯度消失等缺陷,就是將深度學習網絡變成了一個無法理解的黑盒子,并且在網絡深度增加的時候學習率變低,從而很難完成算法的訓練。貢教授團隊提出了一種可以學習內部神經元結構的新型神經網絡結構,可有效解決這個問題,是下一代AI算法的基礎,預期將AI引入3.0時代。
Wayne Luk陸永青院士
英國皇家工程院院士、帝國理工陸永青院士是鯤云科技的聯合創始人&CSO,是定制計算領域的國際權威,他做了關于定制計算的可驗證性主題分享。定制計算是可重構計算的一個重要分支,此次分享陳述了神經網絡在運行時的功能準確性驗證。雖然神經網絡已經在許多領域中得到了有效應用和落地,但由于其底層的運行機制導致深度學習網絡很難用數學完全解釋。為了避免神經網絡輸入噪音導致推斷結果的錯誤,陸院士提出了一種基于可重構硬件并對推斷結果進行驗證的方法。這種驗證方法通過使用少量的硬件資源,在電路中對推斷過程的功能,數據和時序進行監控,從而有效的檢測出推斷過程中可能產生的錯誤。
魏少軍教授
IEEE會士、中國電子學會會士、清華大學魏少軍教授是中國芯片領域的領軍人物,此次他做了題為軟件定義芯片:一種引向智能計算的方式的分享。介紹了一個可通過軟件定義芯片的架構和設計,與傳統的CPU,FPGA和ASIC設計相比,該架構可實現軟件編程和硬件編程的高效結合。該架構設計允許硬件隨著軟件的變化實時動態地改變芯片功能,其核心設計原理思想是通過粗粒度的可重構架構來實現軟件對硬件算子的調用。 Thinker芯片便是基于此設計理念所實現的,該芯片將這種軟件可定義的硬件設計應用于AI算法中,可顯著的提高運算的性能,功效和算法兼容性。
Viktor K. Prasanna教授
IEEE會士、ACM會士、南加州大學Viktor K. Prasanna教授是FPGA邊緣計算領域的國際專家,他分享了一種輕量化FPGA計算架構在邊緣AI邊緣計算中的應用。該架構使用HIVE處理器和SHARP軟件框架,構建了一個基于FPGA的高性能AI加速器。其核心為通過對模型運算進行分區,從而實現對實際AI應用中有效數據區域的高速處理,避免了無效運算。除此之外,該FPGA加速器會在數據處理前,通過數據頻域轉換分析數據的稀疏策略,進一步實現有效數據的稀疏化處理并在系統運行時對模型進行剪枝、量化等性能優化,從而使得FPGA運行性能得到顯著提高。
Cristina Silvano教授
IEEE會士、米蘭理工大學Cristina Silvano教授介紹了一種高性能集群系統(mARGOt)通過自動調節達到性能優化的方法。該優化過程可根據運行時狀態,自動調整應用程序的運行參數從而實現對系統性能的優化.通過歷史數據信息,將應用中的關鍵性能參數提取并生成性能參考數據庫。系統運行時,可根據具體場景信息和參考數據對核心性能參數及內核運行狀態進行實時的動態調節,以達到系統對于場景的自適應,從而在實際場景中,針對應用領域實現性能優化,例如新型藥物研發和智能城市自適應導航系統等。
樊文飛院士
英國皇家學會會士、歐洲科學院院士、愛丁堡大學信息學院樊文飛院士分享了如何將多種并行圖引擎應用于大數據分析場景。傳統并行圖引擎優化難度大且成本較高,難以在實際場景中得到大規模應用。為了解決這一問題,樊院士將分布式的思想引入并行圖查詢引擎中,并以此為基礎開發了一種分布式并行圖處理系統。其核心思想是通過最小化重復的計算和操作以實現增量查詢。系統中采用了一種新的自適應異步并行機制(AAP)調節不同進程之間的協作以提升整體性能。該系統應用于社交媒體,智庫,欺詐檢查等多種應用場景和領域。
重量專家,AI加速行業落地進行時
除了諸位院士、會士嘉賓的學術分享以外,Intel PSG戰略市場總監的Tony Kau、浪潮人工智能與產品總經理劉軍,也分享了英特爾和浪潮在人工智能的落地應用以及創新技術等方面的技術革新和新進展。
Tony Kau
隨著深度學習算法的不斷發展,AI對算力的需求也越來越高,為異構計算加速的發展提供了土壤。2018年底,英特爾在重慶成立了全球最大的FPGA創新中心,在AI領域動作有很多亮眼的動作,此次峰會上,Tony Kau就英特爾FPGA在人工智能的落地應用進行了分享和交流,也分享了同鯤云在AI加速應用和高校推廣等方面的深入合作。
劉軍
作為國內最大的AI服務器廠商,浪潮的市場占有率為57%,擁有最強的AI計算產品陣列和端到端AI應用加速方案。這次劉軍總經理帶來了題為“AI計算創新與產業發展”的分享,探討人工智能技術創新和浪潮的應用落地戰略。
圓桌論壇
此外,峰會還邀請到星瀚資本楊歌、雷鋒網麥廣煒、天津大學電子信息學院副院長劉強、JWIPC副總經理劉迪科、CCE-YOCSEF深圳主席盧昱明等專家學者與鯤云科技CTO蔡權雄博士就人工智能芯片產業與生態落地等話題進行了探討。
2019年人工智能應用創新峰會順利結束,干貨滿滿,在未來計算架構的黃金十年,鯤云科技是否能夠憑借自己多年積累的數據流架構厚積薄發,在AI芯片性能上實現單點突破?我們拭目以待。
-
人工智能系統
+關注
關注
0文章
38瀏覽量
10592
發布評論請先 登錄
相關推薦
潤芯微科技獲評2024 AI蘇州“人工智能+”融合應用企業
美光科技受邀出席GMIF2024創新峰會
聚焦智聯!2024中國(秋季)智能家居技術創新峰會順利落幕!

《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
全球人工智能峰會呼吁全球行動,確保人工智能創新“造福人類”
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
創新領先,效能躍遷 英飛凌2024汽車創新峰會舉行

創芯引擎·智繪生活:2024年華東智能家居技術創新峰會圓滿落幕!

捷科亮相2024阿里云金融創新峰會,推動金融科技領域數智轉型





 工商網監
工商網監
評論