") 自然語言處理頂會NAACL近日公布了本屆會議的最佳論文,谷歌BERT論文獲得最佳長論文
自然語言處理頂會NAACL近日公布了本屆會議的最佳論文,谷歌BERT論文獲得最佳長論文
自然語言處理頂會NAACL近日公布了本屆會議的最佳論文,谷歌BERT論文獲得最佳長論文,可謂名至實歸。
自然語言處理四大頂會之一NAACL2019將于6月2日-7日在美國明尼阿波利斯市舉行。
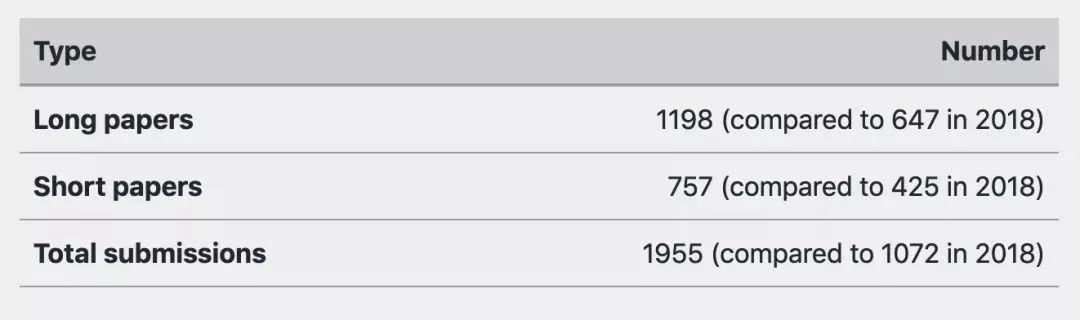
據(jù)官方統(tǒng)計,NAACL2019共收到1955篇論文,接收論文424篇,錄取率僅為22.6%。其中長論文投稿1198篇,短論文757篇。
今天,大會揭曉了本屆會議的最佳論文獎項,包括最佳專題論文、最佳可解釋NLP論文、最佳長論文、最佳短論文和最佳資源論文。
其中,谷歌BERT論文獲得最佳長論文獎項,可謂名至實歸。
最佳長論文:谷歌BERT模型
最佳長論文(Best Long Paper)
BERT:PretrainingofDeepBidirectionalTransformersforLanguageUnderstanding
JacobDevlin,Ming-WeiChang,KentonLeeandKristinaToutanova
https://arxiv.org/abs/1810.04805
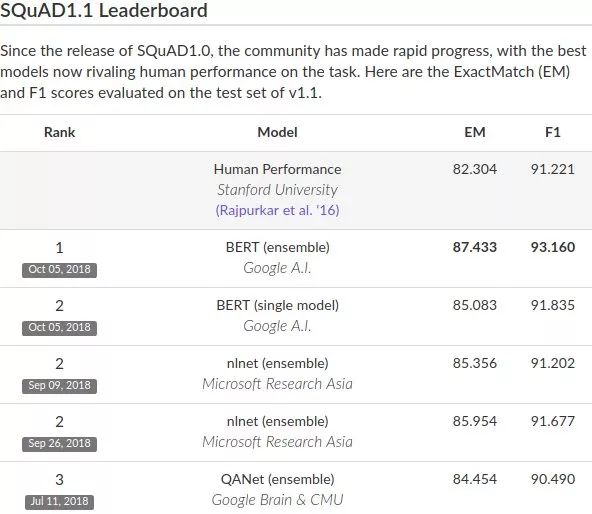
谷歌AI團隊在去年10月發(fā)布的BERT模型,在機器閱讀理解頂級水平測試SQuAD1.1中表現(xiàn)出驚人的成績:全部兩個衡量指標上全面超越人類!并且還在11種不同NLP測試中創(chuàng)出最佳成績,包括將GLUE基準推至80.4%(絕對改進7.6%),MultiNLI準確度達到86.7%(絕對改進率5.6%)等。
自BERT模型發(fā)布以來,許多基于BERT的改進模型不斷在各種NLP任務刷新成績。毫不夸張地說,BERT模型開啟了NLP的新時代!
首先來看下谷歌AI團隊做的這篇論文。

BERT的新語言表示模型,它代表Transformer的雙向編碼器表示。與最近的其他語言表示模型不同,BERT旨在通過聯(lián)合調節(jié)所有層中的上下文來預先訓練深度雙向表示。因此,預訓練的BERT表示可以通過一個額外的輸出層進行微調,適用于廣泛任務的最先進模型的構建,比如問答任務和語言推理,無需針對具體任務做大幅架構修改。
論文作者認為現(xiàn)有的技術嚴重制約了預訓練表示的能力。其主要局限在于標準語言模型是單向的,這使得在模型的預訓練中可以使用的架構類型很有限。
在論文中,作者通過提出BERT:即Transformer的雙向編碼表示來改進基于架構微調的方法。
BERT提出一種新的預訓練目標:遮蔽語言模型(maskedlanguagemodel,MLM),來克服上文提到的單向性局限。MLM的靈感來自Cloze任務(Taylor,1953)。MLM隨機遮蔽模型輸入中的一些token,目標在于僅基于遮蔽詞的語境來預測其原始詞匯id。
與從左到右的語言模型預訓練不同,MLM目標允許表征融合左右兩側的語境,從而預訓練一個深度雙向Transformer。除了遮蔽語言模型之外,本文作者還引入了一個“下一句預測”(nextsentenceprediction)任務,可以和MLM共同預訓練文本對的表示。
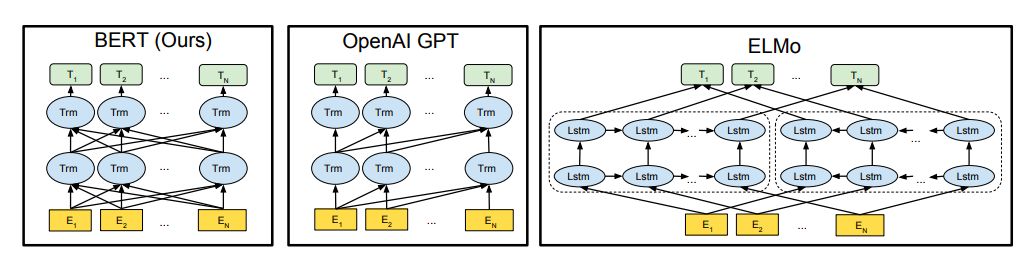
預訓練模型架構的差異。BERT使用雙向Transformer。OpenAIGPT使用從左到右的Transformer。ELMo使用經(jīng)過獨立訓練的從左到右和從右到左LSTM的串聯(lián)來生成下游任務的特征。三個模型中,只有BERT表示在所有層中共同依賴于左右上下文。
參考閱讀:
NLP歷史突破!谷歌BERT模型狂破11項紀錄,全面超越人類!
最佳專題論文:減輕機器學習系統(tǒng)的偏見
最佳專題論文(Best Thematic Paper)
What’sinaName?ReducingBiasinBiosWithoutAccesstoProtectedAttributes
AlexeyRomanov,MariaDeArteaga,HannaWallach,JenniferChayes,ChristianBorgs,AlexandraChouldechova,SahinGeyik,KrishnaramKenthapadi,AnnaRumshiskyandAdamKalai
https://128.84.21.199/abs/1904.05233

越來越多的研究提出了減輕機器學習系統(tǒng)偏見的方法。這些方法通常依賴于對受保護屬性(如種族、性別或年齡)的可用性。
然而,這提出了兩個重要的挑戰(zhàn):
(1)受保護的屬性可能不可用,或者使用它們可能不合法;
(2)通常需要同時考慮多個受保護的屬性及其交集。
在減輕職業(yè)分類偏見的背景下,我們提出了一種方法,用于阻隔個人真實職業(yè)的預測概率與他們名字的單詞嵌入之間的相關性。
這種方法利用了詞嵌入中編碼的社會偏見,從而無需訪問受保護屬性。最重要的是,這種方法只要求在訓練時訪問個人姓名,而不是在部署時。
我們使用了一個大規(guī)模的在線傳記數(shù)據(jù)集來評估我們提出的方法的兩種變體。我們發(fā)現(xiàn),這兩種變體同時減少了種族和性別偏見,而分類器的總體真實陽性率幾乎沒有降低。
最佳可解釋NLP論文:用量子物理的數(shù)學框架建模人類語言
最佳可解釋NLP論文 (Best Explainable NLP Paper)
CNM:AnInterpretableComplex-valuedNetworkforMatching
QiuchiLi,BenyouWangandMassimoMelucci
https://128.84.21.199/abs/1904.05298

本文試圖用量子物理的數(shù)學框架對人類語言進行建模。
這個框架利用了量子物理中精心設計的數(shù)學公式,將不同的語言單元統(tǒng)一在一個復值向量空間中,例如,將單詞作為量子態(tài)的粒子,句子作為混合系統(tǒng)。我們構建了一個復值網(wǎng)絡來實現(xiàn)該框架的語義匹配。
由于具有良好約束的復值組件,網(wǎng)絡允許對顯式物理意義進行解釋。所提出的復值匹配網(wǎng)絡(complex-valuednetworkformatching,CNM)在兩個基準問題回答(QA)數(shù)據(jù)集上具有與強大的CNN和RNN基線相當?shù)男阅堋?/p>
最佳短論文:視覺模態(tài)對機器翻譯的作用
最佳短論文(Best Short Paper)
Probing the Need for Visual Context in Multimodal Machine Translation
OzanCaglayan,PranavaMadhyastha,LuciaSpeciaandLo?cBarrault
https://arxiv.org/abs/1903.08678

目前關于多模態(tài)機器翻譯(MMT)的研究表明,視覺模態(tài)要么是不必要的,要么僅僅是有幫助的。
我們假設這是在任務的惟一可用數(shù)據(jù)集(Multi30K)中使用的非常簡單、簡短和重復的語句的結果,其中源文本被呈現(xiàn)為上下文。
然而,在一般情況下,我們認為可以將視覺信息和文本信息結合起來進行實際的翻譯。
在本文中,我們通過系統(tǒng)的分析探討了視覺模態(tài)對最先進的MMT模型的貢獻。我們的結果表明,在有限的文本上下文中,模型能夠利用視覺輸入生成更好的翻譯。這與當前的觀點相矛盾,即要么是因為圖像特征的質量,要么是因為它們集成到模型中的方式,MMT模型忽視了視覺模態(tài)。
最佳資源論文:常識性問答的新數(shù)據(jù)集
最佳資源論文(Best Resource Paper)
CommonsenseQA:AQuestionAnsweringChallengeTargetingCommonsenseKnowledge
AlonTalmor,JonathanHerzig,NicholasLourieandJonathanBerant
https://arxiv.org/abs/1811.00937

在回答一個問題時,除了特定的上下文外,人們往往會利用他們豐富的世界知識。
最近的工作主要集中在回答一些有關文件或背景的問題,很少需要一般常識背景。
為了研究基于先驗知識的問答任務,我們提出了CommonsenseQA:一個具有挑戰(zhàn)性的用于常識性問答的新數(shù)據(jù)集。
為了獲取超出關聯(lián)之外的常識,我們從ConceptNet(Speeretal.,2017)中提取了與單個源概念具有相同語義關系的多個目標概念。參與者被要求撰寫多項選擇題,其中要提到源概念,并依次區(qū)分每個目標概念。這鼓勵參與人員創(chuàng)建具有復雜語義的問題,這些問題通常需要先驗知識。
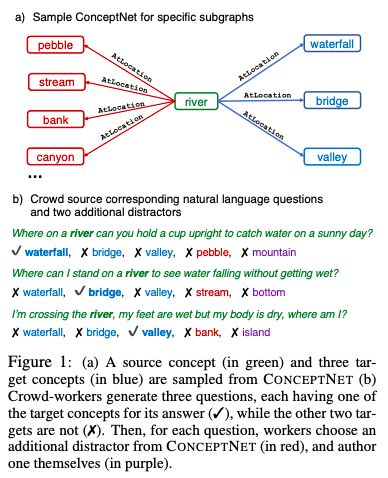
我們通過這個過程創(chuàng)建了12247個問題,并用大量強大的基線說明了我們任務的難度。我們最好的基線是基于BERT-large(Devlinetal.,2018)的,獲得56%的準確率,遠低于人類表現(xiàn),即89%的準確度。
-
谷歌
+關注
關注
27文章
6168瀏覽量
105382 -
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13561
原文標題:自然語言處理頂會NAACL最佳論文出爐!谷歌BERT名至實歸獲最佳長論文
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
自然語言處理與機器學習的關系 自然語言處理的基本概念及步驟
ASR與自然語言處理的結合
自然語言處理與機器學習的區(qū)別
經(jīng)緯恒潤功能安全AI 智能體論文成功入選EMNLP 2024!

中科馭數(shù)聯(lián)合處理器芯片全國重點實驗室獲得“CCF芯片大會最佳論文獎”
地平線科研論文入選國際計算機視覺頂會ECCV 2024
谷歌DeepMind被曝抄襲開源成果,論文還中了頂流會議






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論