") 谷歌大腦在構(gòu)建源代碼生成模型上實(shí)現(xiàn)了新突破!
谷歌大腦在構(gòu)建源代碼生成模型上實(shí)現(xiàn)了新突破!
預(yù)測(cè)源代碼,聽著就是一件非常炫酷的事情。最近,谷歌大腦的研究人員就對(duì)此高難度任務(wù)發(fā)起了挑戰(zhàn),在構(gòu)建源代碼生成模型上實(shí)現(xiàn)了新突破!
編程神技來了!
根據(jù)已經(jīng)編輯好的代碼預(yù)測(cè)源代碼的AI,對(duì)程序員來說是一個(gè)非常寶貴的工具。
最近,谷歌大腦團(tuán)隊(duì)就對(duì)這項(xiàng)難度頗高的任務(wù)發(fā)起了挑戰(zhàn)。

論文地址:
https://arxiv.org/pdf/1904.02818.pdf
改代碼是程序員經(jīng)常要做的事,需求一變,甚至可能要重頭再來。然而,編輯模式(edit pattern)是無法僅僅根據(jù)要插入/刪除的內(nèi)容或者寫好內(nèi)容后的代碼狀態(tài)來被理解。
它需要根據(jù)變化與其所處狀態(tài)的關(guān)系來理解,準(zhǔn)確地對(duì)代碼序列進(jìn)行建模需要學(xué)習(xí)舊代碼的表示方法,這就允許模型可以概括一種模式且對(duì)未來要編寫的代碼內(nèi)容進(jìn)行預(yù)測(cè)。
舉個(gè)例子:

有兩個(gè)歷史記錄A和B,這兩段代碼序列在經(jīng)過2次編輯后,得到了相同狀態(tài),即“狀態(tài)2”。但是在這個(gè)過程當(dāng)中,歷史記錄A是在向foo函數(shù)添加參數(shù),而歷史記錄B是在從foo函數(shù)中刪除參數(shù)。
這項(xiàng)工作,就是希望根據(jù)“狀態(tài)0”和“編輯 1&2 ”,可以預(yù)測(cè)接下來“編輯3”的操作內(nèi)容。
為了達(dá)到這個(gè)目的,他們首先開發(fā)了兩種表示方法來捕獲意圖信息,這些信息將隨著代碼序列的長度“優(yōu)雅地”擴(kuò)展:
顯式表示方法:在序列中“實(shí)例化”代碼內(nèi)容;
隱式表示方法:用于實(shí)例化后續(xù)要編寫的代碼。
然后它們構(gòu)建了一個(gè)機(jī)器學(xué)習(xí)模型,這個(gè)模型可以捕獲原始代碼和預(yù)測(cè)代碼之間的上下文關(guān)系。
構(gòu)建源代碼生成模型新突破
近年來,構(gòu)建源代碼的生成模型成為十分受重視的核心任務(wù)。
然而,以前的生成模型總是根據(jù)生成代碼的靜態(tài)快照(static snapshot)來構(gòu)建的。而在這項(xiàng)工作中,研究人員將源代碼視為一個(gè)動(dòng)態(tài)對(duì)象(dynamic object),并處理軟件開發(fā)人員對(duì)源代碼文件進(jìn)行編輯的建模問題。
對(duì)編輯序列建模的主要挑戰(zhàn)是如何開發(fā)良好的表示,既能捕獲有關(guān)意圖的所需信息,又能優(yōu)雅地對(duì)序列的長度進(jìn)行擴(kuò)展。
正如上述,這項(xiàng)工作主要考慮編輯的兩種表示方法,一是顯式表示方法,二是隱式表示方法。
在顯式表示方法中,將分層循環(huán)指針網(wǎng)絡(luò)模型視為強(qiáng)大但計(jì)算成本較高的基線。在隱式表示方法中,考慮一個(gè)vanilla序列到序列模型,以及一個(gè)基于注意力的雙頭模型。這些模型展示了由不同問題公式產(chǎn)生的權(quán)衡,并為未來的編輯序列模型提供設(shè)計(jì)決策。
在精心設(shè)計(jì)的合成數(shù)據(jù)和對(duì)Python源代碼進(jìn)行細(xì)粒度編輯的大型數(shù)據(jù)集上,研究人員評(píng)估了模型的可伸縮性和準(zhǔn)確性,以及模型觀察以往編輯序列并預(yù)測(cè)未來編輯內(nèi)容的能力。
實(shí)驗(yàn)表明,雙頭注意力模型特別適合實(shí)現(xiàn)對(duì)真實(shí)數(shù)據(jù)的高精度、校準(zhǔn)良好的置信度和良好的可擴(kuò)展性。
總之,這項(xiàng)工作形式化了從編輯序列中學(xué)習(xí)和預(yù)測(cè)編輯序列的問題,提供了對(duì)模型空間的初步探索,并演示了從開發(fā)人員對(duì)源代碼進(jìn)行的編輯中學(xué)習(xí)的實(shí)際問題的適用性。
問題定義:如何表示編輯序列數(shù)據(jù)
隱式和顯式數(shù)據(jù)表示
第一個(gè)問題是如何表示編輯序列數(shù)據(jù)。我們定義了兩種具有不同權(quán)衡的數(shù)據(jù)格式。
顯式格式 (圖 2 (a)) 將編輯序列表示為 2D 網(wǎng)格中 tokens 序列的序列。內(nèi)部序列對(duì)文件中的 tokens 建立索引,外部序列對(duì)時(shí)間建立索引。任務(wù)是消耗前 t 行并預(yù)測(cè)在時(shí)間 t 進(jìn)行的編輯的位置和內(nèi)容。
隱式格式 (圖 2 (b)) 將初始狀態(tài)表示為 tokens 序列,將編輯表示為 (position, content) 對(duì)的序列。

圖 2:將 “BACA” 轉(zhuǎn)換為 “BABBCACC” 的編輯序列的顯式表示 (a) 和隱式表示 (b)。
問題描述
顯式問題的目標(biāo)是學(xué)習(xí)一個(gè)模型,該模型使給定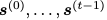 的
的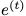 的可能性最大化;隱式問題是學(xué)習(xí)一個(gè)模型,該模型使給定所有 t 的
的可能性最大化;隱式問題是學(xué)習(xí)一個(gè)模型,該模型使給定所有 t 的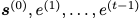 的
的 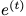
基線模型
基線顯式模型 (Baseline Explicit Model)
基線顯式模型是一個(gè)兩級(jí)長短時(shí)記憶 (LSTM) 神經(jīng)網(wǎng)絡(luò),類似于 Serban 等人 (2016) 的分層 RNN 模型。
基線隱式模型 (Baseline Implicit Model)
sequence-to-sequence 框架的自然應(yīng)用是使用編碼器的初始狀態(tài) s (0),并在解碼器中生成 (p (t) i, c (t)) 對(duì)的序列。編碼器是一個(gè)標(biāo)準(zhǔn)的 LSTM。解碼器不太標(biāo)準(zhǔn),因?yàn)槊總€(gè)動(dòng)作都是成對(duì)的。為了將對(duì)作為輸入處理,我們將 p (t) i 的嵌入與 c (t) 的嵌入連接起來。為了產(chǎn)生成對(duì)的輸出,我們先預(yù)測(cè)位置,然后給出給定位置的內(nèi)容。
隱式注意力模型
我們開發(fā)了一個(gè)模型,它對(duì)隱式表示進(jìn)行操作,但是能夠更好地捕獲編輯內(nèi)容與編輯上下文之間關(guān)系的序列。
該模型深受 Vaswani 等人 (2017) 的啟發(fā)。在訓(xùn)練時(shí),編輯的完整序列在單個(gè)前向傳遞中被預(yù)測(cè)。
有一個(gè)編碼器計(jì)算初始狀態(tài)和所有編輯的隱藏表示,然后有兩個(gè) decoder heads:第一個(gè)解碼每個(gè)編輯的位置,第二個(gè)解碼給定位置的每個(gè)編輯的內(nèi)容。
圖 3 (b, c) 對(duì)模型的整體結(jié)構(gòu)進(jìn)行了概述。
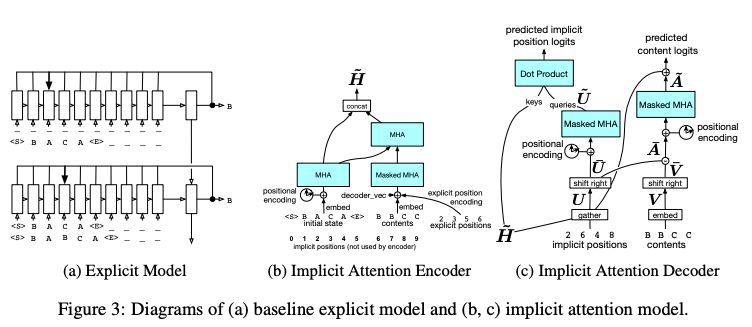
圖 3:(a) 基線顯式模型;(b, c) 隱式注意力模型
實(shí)驗(yàn)和結(jié)果:模型可以解決幾乎所有任務(wù)
實(shí)驗(yàn)的目的是了解上述模型的能力和局限性,并在實(shí)際數(shù)據(jù)上進(jìn)行評(píng)估。
實(shí)驗(yàn)有兩個(gè)主要因素,一是模型如何準(zhǔn)確地學(xué)習(xí)識(shí)別編輯序列中的模式,二是模型如何擴(kuò)展到大數(shù)據(jù)。
在第一組實(shí)驗(yàn)中,我們?cè)谝粋€(gè)簡單的環(huán)境中研究了這些問題;在第二組實(shí)驗(yàn)中,我們根據(jù)真實(shí)數(shù)據(jù)進(jìn)行了評(píng)估。
本節(jié)中,我們?cè)u(píng)估了三種方法:顯式模型縮寫為 E,隱式 RNN 模型縮寫為 IR,隱式注意力模型縮寫為 IA。
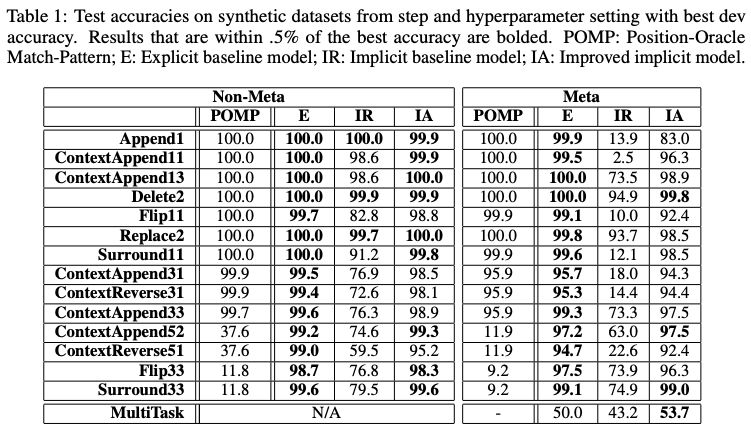
表 1:在合成數(shù)據(jù)集上的準(zhǔn)確性
表 1 報(bào)告了產(chǎn)生最佳開發(fā)性能的超參數(shù)設(shè)置和步驟的測(cè)試性能。結(jié)果表明,顯式模型和改進(jìn)的隱式模型可以解決幾乎所有的任務(wù),甚至包括那些涉及元字符和相對(duì)較長的替換序列的任務(wù)。
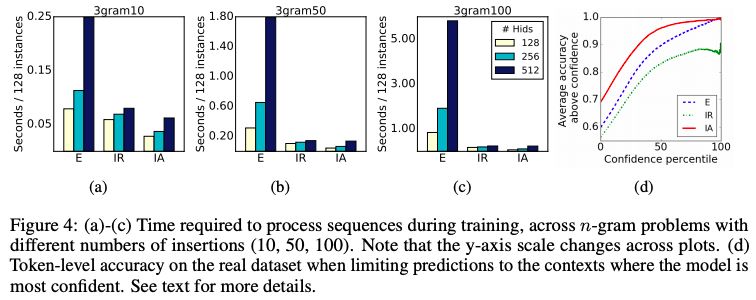
圖 4:(a)-(c) 在訓(xùn)練期間處理序列所需的時(shí)間,跨越不同插入數(shù) (10,50,100) 的 n-gram 問題。(d) 當(dāng)將預(yù)測(cè)限制在模型最有信心的上下文中時(shí),實(shí)際數(shù)據(jù)集的 token 級(jí)精度。
如圖 4 (d) 所示,顯式模型始終比隱式模型成本更高,并且隨著數(shù)據(jù)大小的增加,這種差距也會(huì)增大。長度為 100 的插入序列比實(shí)際數(shù)據(jù)集中的序列小十倍,但在運(yùn)行時(shí)已經(jīng)存在一個(gè)數(shù)量級(jí)的差異。注意力模型通常占隱式 RNN 模型的 50% ~ 75% 的時(shí)間。
結(jié)論和未來研究
在這項(xiàng)工作中,我們提出了從過去的編輯中學(xué)習(xí),以預(yù)測(cè)未來編輯的問題,開發(fā)了具有很強(qiáng)泛化能力的編輯序列模型,并證明了該方案對(duì)大規(guī)模源代碼編輯數(shù)據(jù)的適用性。
我們做了一個(gè)不切實(shí)際的假設(shè),即快照之間的編輯是按從左到右的順序執(zhí)行的。另一種值得探索的方案是,將其視為從弱監(jiān)督中學(xué)習(xí)。可以想象這樣一個(gè)公式,其中快照之間的編輯順序是一個(gè)潛在變量,必須在學(xué)習(xí)過程中推斷出來。
該研究有多種可能的應(yīng)用。在開發(fā)人員工具的背景中,我們特別感興趣的是調(diào)整過去的編輯以做出其他類型的預(yù)測(cè)。例如,我們還可以設(shè)置光標(biāo)位置的條件,并研究如何使用編輯歷史來改進(jìn)忽略編輯歷史的傳統(tǒng)自動(dòng)完成系統(tǒng)。另一個(gè)例子是,根據(jù)開發(fā)人員最近的編輯,預(yù)測(cè)他們接下來會(huì)發(fā)出哪些代碼搜索查詢。一般來說,我們希望預(yù)測(cè)開發(fā)人員接下來要做的事情。我們認(rèn)為,編輯歷史包含了重要的有用信息,在這項(xiàng)工作中提出的公式和模型是學(xué)習(xí)使用這些信息的良好起點(diǎn)。
-
編碼器
+關(guān)注
關(guān)注
45文章
3655瀏覽量
134875 -
谷歌
+關(guān)注
關(guān)注
27文章
6176瀏覽量
105677 -
源代碼
+關(guān)注
關(guān)注
96文章
2946瀏覽量
66831
原文標(biāo)題:程序員再也不怕需求改來改去!谷歌大腦新突破:AI預(yù)測(cè)源代碼
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于擴(kuò)散模型的圖像生成過程

PSPICE 生成的模型和datasheet對(duì)應(yīng)不上
怎么根據(jù)源代碼文件中的注釋生成源代碼文檔
請(qǐng)問怎么在樹莓派上從源代碼構(gòu)建Golang?
基于模型設(shè)計(jì)的HDL代碼自動(dòng)生成技術(shù)綜述
Simulink模型生成代碼
Simulink 自動(dòng)代碼生成原理分享
在Raspberry Pi上從源代碼構(gòu)建OpenVINO 2021.3收到錯(cuò)誤怎么解決?
UDP穿透NAT的原理與實(shí)現(xiàn)(附源代碼)
谷歌大腦的“世界模型”簡述與啟發(fā)
編程神技來了!谷歌新研究根據(jù)已經(jīng)編輯好的代碼預(yù)測(cè)源代碼的 AI

MBD的Simulink使用技巧:詳解代碼生成中的模型與代碼(2)
從HumanEval到CoderEval: 你的代碼生成模型真的work嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論