 何愷明團隊最新研究:提出一個端到端的3D目標檢測器VoteNet
何愷明團隊最新研究:提出一個端到端的3D目標檢測器VoteNet
FAIR何愷明等人團隊提出3D目標檢測新框架VoteNet,直接處理原始數據,不依賴任何2D檢測器。該模型設計簡單,模型緊湊,效率高,在兩大真實3D掃描數據集上實現了最先進的3D檢測精度。
當前的3D目標檢測方法受2D檢測器的影響很大。為了利用2D檢測器的架構,它們通常將3D點云轉換為規則的網格,或依賴于在2D圖像中檢測來提取3D框。很少有人嘗試直接檢測點云中的物體。
近日,Facebook AI實驗室(FAIR)和斯坦福大學的Charles R. Qi,Or Litany,何愷明,Leonidas J. Guibas等人發表最新論文,提出一個端到端的3D目標檢測器VoteNet。
論文地址:
https://arxiv.org/pdf/1904.09664.pdf
在這篇論文中,研究人員回歸第一原則,為點云數據構建了一個盡可能通用的3D檢測pipeline。
然而,由于數據的稀疏性,直接從場景點預測邊界框參數時面臨一個主要挑戰:一個3D物體的質心可能遠離任何表面點,因此很難用一個步驟準確地回歸。
為了解決這一問題,研究人員提出VoteNet,這是一個基于深度點集網絡和霍夫投票的端到端3D目標檢測網絡。
該模型設計簡單,模型尺寸緊湊,而且效率高,在ScanNet和SUN RGB-D兩大真實3D掃描數據集上實現了最先進的3D檢測精度。值得注意的是,VoteNet優于以前的方法,而且不依賴彩色圖像,使用純幾何信息。
VoteNet點云框架:直接處理原始數據,不依賴2D檢測器
3D目標檢測的目的是對3D場景中的對象進行定位和識別。更具體地說,在這項工作中,我們的目標是估計定向的3D邊界框以及點云對象的語義類。
與2D圖像相比,3D點云具有精確的幾何形狀和對光照變化的魯棒性。但是,點云是不規則的。因此,典型的CNN不太適合直接處理點云數據。
為了避免處理不規則點云,目前的3D檢測方法在很多方面都嚴重依賴基于2D的檢測器。例如,將Faster/Mask R-CNN等2D檢測框架擴展到3D,或者將點云轉換為常規的2D鳥瞰圖像,然后應用2D檢測器來定位對象。然而,這會犧牲幾何細節,而這些細節在雜亂的室內環境中可能是至關重要。
在這項工作中,我們提出一個直接處理原始數據、不依賴任何2D檢測器的點云3D檢測框架。這個檢測網絡稱為VoteNet,是點云3D深度學習模型的最新進展,并受到用于對象檢測的廣義霍夫投票過程的啟發。
圖1:基于深度霍夫投票模型的點云3D目標檢測
我們利用了PointNet++,這是一個用于點云學習的分層深度網絡,以減少將點云轉換為規則結構的需要。通過直接處理點云,不僅避免了量化過程中信息的丟失,而且通過僅對感測點進行計算,利用了點云的稀疏性。
雖然PointNet++在對象分類和語義分割方面都很成功,但很少有研究使用這種架構來檢測點云中的3D對象。
一個簡單的解決方案是遵循2D檢測器的常規做法,并執行dense object proposal,即直接從感測點提出3D邊界框。然而,點云的固有稀疏性使得這種方法不適宜。
在圖像中,通常在目標中心附近存在一個像素,但在點云中卻不是這樣。由于深度傳感器僅捕獲物體的表面,因此3D物體的中心很可能在遠離任何點的空白空間中。因此,基于點的網絡很難在目標中心附近聚集場景上下文。簡單地增加感知域并不能解決這個問題,因為當網絡捕獲更大的上下文時,它也會導致包含更多的附近的對象和雜物。
為此,我們提出賦予點云深度網絡一種類似于經典霍夫投票(Hough voting)的投票機制。通過投票,我們基本上生成了靠近對象中心的新的點,這些點可以進行分組和聚合,以生成box proposals。
與傳統的多獨立模塊、難以聯合優化的霍夫投票相比,VoteNet是端到端優化的。具體來說,在通過主干點云網絡傳遞輸入點云之后,我們對一組種子點進行采樣,并根據它們的特征生成投票。投票的目標是到達目標中心。因此,投票集群出現在目標中心附近,然后可以通過一個學習模塊進行聚合,生成box proposals。其結果是一個強大的3D物體檢測器,它是純幾何的,可以直接應用于點云。
我們在兩個具有挑戰性的3D目標檢測數據集上評估了我們的方法:SUN RGB-D數據集和ScanNet數據集。在這兩個數據集上,僅使用幾何信息的VoteNet明顯優于使用RGB和幾何甚至多視圖RGB圖像的現有技術。我們的研究表明,投票方案支持更有效的上下文聚合,并驗證了當目標中心遠離目標表面時,VoteNet能夠提供最大的改進。
綜上所述,我們工作的貢獻如下:
在通過端到端可微架構進行深度學習的背景下,重新制定了霍夫投票,我們稱之為VoteNet。
在SUN RGB-D和ScanNet兩個數據集上實現了最先進的3D目標檢測性能。
深入分析了投票在點云3D目標檢測中的重要性。
深度霍夫投票(Deep Hough Voting)
傳統的霍夫投票2D檢測器包括離線和在線兩個步驟。
首先,給定一組帶有帶注釋的對象邊界框的圖像集,使用存儲在圖像補丁(或它們的特性)和它們到相應目標中心的偏移量之間的映射構建一個codebook。
在推理時,從圖像中選擇興趣點以提取周圍的補丁(patch)。然后將這些補丁與codebook中的補丁進行比較,以檢索偏移量并計算投票。由于對象補丁傾向于一致投票,因此集群將在目標中心附近形成。最后,通過將集群投票追溯到它們生成的補丁來檢索對象邊界。
我們確定這種技術非常適合我們感興趣的問題,有兩個方面:
首先,投票是針對稀疏集合設計的,因此很自然地適合于點云。
其次,它基于自底向上的原理,積累少量的局部信息以形成可靠的檢測。
然而,傳統的霍夫投票是由多個獨立的模塊組成的,將其集成到點云網絡仍然是一個開放的研究課題。為此,我們建議對不同的pipeline部分進行以下調整:
興趣點(Interest points)由深度神經網絡來描述和選擇,而不是依賴手工制作的特性。
投票(Vote)生成是通過網絡學習的,而不是使用代碼本。利用更大的感受野,可以使投票減少模糊,從而更有效。此外,還可以使用特征向量對投票位置進行增強,從而實現更好的聚合。
投票聚合(Vote aggregation)是通過可訓練參數的點云處理層實現的。利用投票功能,網絡可以過濾掉低質量的選票,并生成改進的proposals。
Object proposals的形式是:位置、維度、方向,甚至語義類,都可以直接從聚合特征生成,從而減少了追溯投票起源的需要。
接下來,我們將描述如何將上述所有組件組合成一個名為VoteNet的端到端網絡。
VoteNet 的架構
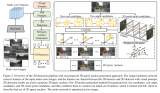
圖2描述了我們提出的端到端檢測網絡VoteNet的架構。整個網絡可以分為兩部分:一部分處理現有的點來生成投票;另一部分處理虛擬點——投票——來提議和分類對象。
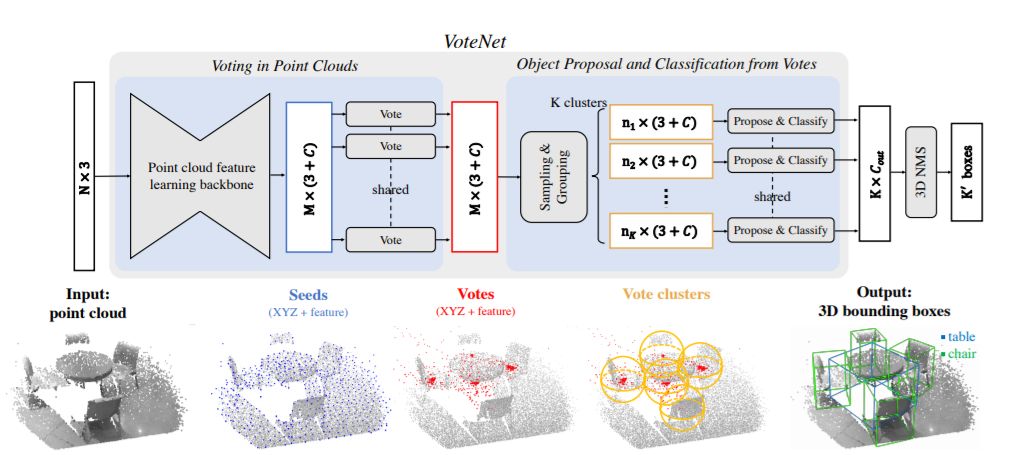
圖2:用于點云中3D目標檢測的VoteNet架構
給定一個包含N個點和XYZ坐標的輸入點云,一個主干網絡(使用PointNet++實現),對這些點進行采樣和學習深度特性,并輸出M個點的子集。這些點的子集被視為種子點。每個種子通過投票模塊獨立地生成一個投票。然后將投票分組為集群,并由proposal模塊處理,生成最終的proposal。
實驗和結果
我們首先在兩個大型3D室內目標檢測基準上,將我們基于霍夫投票的檢測器與之前最先進的方法進行比較。
然后,我們提供了分析實驗來了解投票的重要性、不同的投票聚合方法的效果,并展示了我們的方法在緊湊性和效率方面的優勢。
最后,我們展示了我們的檢測器的定性結果。論文附錄中提供了更多的分析和可視化。
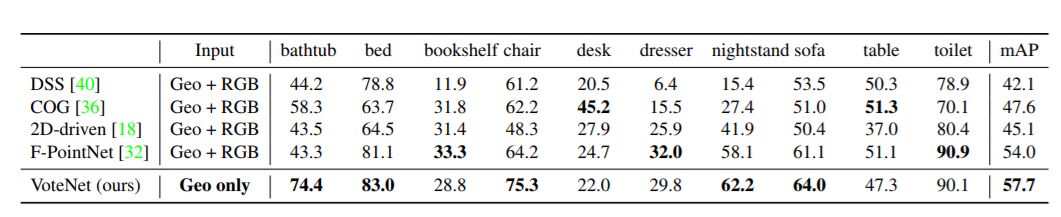
表1:SUN RGB-D val數據集上的3D目標檢測結果
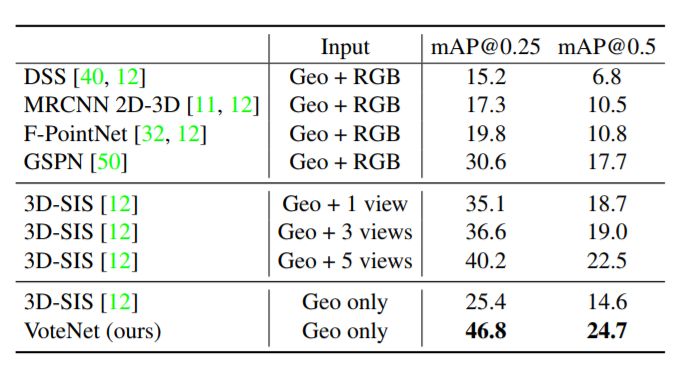
表2:ScanNetV2 val數據集上的3D目標檢測結果
結果如表1和表2所示。在SUN RGB-D和ScanNet兩個數據集中,VoteNet的性能都優于所有先前的方法,分別增加了3.7和6.5 mAP。
表1表明,當類別是訓練樣本最多的“椅子”時,我們的方法比以前的最優方法提高11 AP。
表2表明,僅使用幾何輸入時,我們的方法顯著優于基于3D CNN的3D-SIS方法,超過了20 AP。
分析實驗:投票好還是不投票好呢?
投票好還是不投票好呢?
我們采用了一個簡單的基線網絡,稱之為BoxNet,它直接從采樣的場景點提出檢測框,而不需要投票。
BoxNet具有與VoteNet相同的主干,但它不采用投票機制,而是直接從種子點生成框。
表3顯示,在SUN RGB-D和ScanNet上,相比BoxNet,投票機制的網絡性能分別提高了7 mAP和~5 mAP。

表3:VoteNet和no-vote基線的比較
那么,投票在哪些方面有幫助呢?我們認為,由于在稀疏的3D點云中,現有的場景點往往遠離目標中心點,直接提出的方案可能置信度較低或不準確。相反,投票讓這些較低的置信點更接近,并允許通過聚合來強化它們的假設。
在圖3中,我們在一個典型的ScanNetV2場景中演示了這種現象。從圖中可以看出,與BoxNet(圖左)相比,VoteNet(圖右)提供了更廣泛的“好”種子點的覆蓋范圍,顯示了投票帶來的穩健性。
圖3:投票有助于增加檢測上下文,從而增加了準確檢測的可能性。
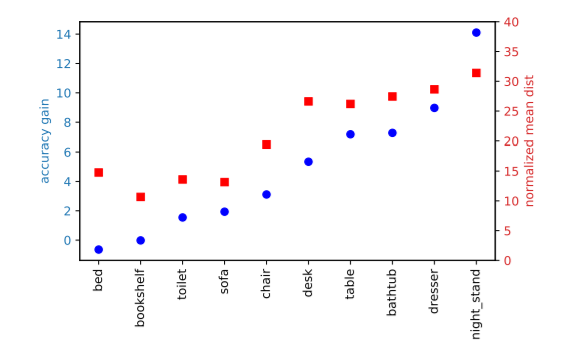
圖4:當目標點遠離目標中心的情況下,投票更有幫助
定性結果和討論
圖6和圖7分別展示了ScanNet和SUN RGB-D場景中VoteNet檢測結果的幾個代表性例子。
可以看出,場景是非常多樣化的,并提出了多種挑戰,包括雜亂,偏見,掃描的偽像等。盡管有這些挑戰,我們的網絡仍顯示出相當強大的結果。
例如,圖6展示了如何在頂部場景中正確地檢測到絕大多數椅子。我們的方法能夠很好地區分左下角場景中連起來的沙發椅和沙發;并預測了右下角那張不完整的、雜亂無章的桌子的完整邊界框。
圖6:ScanNetV2中3D目標檢測的定性結果。左:VoteNet的結果,右: ground-truth
圖7:SUN RGB-D中3D目標檢測的定性結果。(從左到右):場景的圖像,VoteNet的3D對象檢測,以及ground-truth注釋
結論
在這項工作中,我們介紹了VoteNet:一個簡單但強大的3D對象檢測模型,受到霍夫投票的啟發。
該網絡學習直接從點云向目標質心投票,并學會通過它們的特性和局部幾何信息來聚合投票,以生成高質量的object proposals。
該模型僅使用3D點云,與之前使用深度和彩色圖像的方法相比,有了顯著的改進。
在未來的工作中,我們將探索如何將RGB圖像納入這個檢測框架,并在下游應用(如3D實例分割)匯總利用我們的檢測器。我們相信霍夫投票和深度學習的協同作用可以推廣到更多的應用領域,如6D姿態估計、基于模板的檢測等,并期待在這方面看到更多的研究。
-
檢測器
+關注
關注
1文章
869瀏覽量
47768 -
數據集
+關注
關注
4文章
1209瀏覽量
24800 -
深度學習
+關注
關注
73文章
5512瀏覽量
121452
原文標題:何愷明團隊最新研究:3D目標檢測新框架VoteNet,兩大數據集刷新最高精度
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于ToF的3D活體檢測算法研究
谷歌開發pipeline,在移動設備上可實時計算3D目標檢測
自動駕駛檢測器可同時實現3D檢測精讀和速度的提升
華為發布“5G+8K”3D VR端到端解決方案
洲明以裸眼3D技術助力數字經濟
如何利用車載環視相機采集到的圖像實現精準的3D目標檢測
基于BEV的視覺3D目標檢測器

CCV 2023 | SparseBEV:高性能、全稀疏的純視覺3D目標檢測器


Sparse4D-v3:稀疏感知的性能優化及端到端拓展
Nullmax提出多相機3D目標檢測新方法QAF2D





 工商網監
工商網監
評論