 人類終于找到了如何處理“抽象概念”這個亙古難題的方法
人類終于找到了如何處理“抽象概念”這個亙古難題的方法
人工智能,就像長生不老和星際漫游一樣,是人類最美好的夢想之一。雖然計算機技術已經取得了長足的進步,但是到目前為止,還沒有一臺電腦能產生“自我”的意識。但是自 2006 年以來,機器學習領域,取得了突破性的進展。圖靈試驗,至少不是那么可望而不可及了。至于技術手段,不僅僅依賴于云計算對大數據的并行處理能力,而且依賴于算法。這個算法就是深度學習Deep Learning。借助于 Deep Learning 算法,人類終于找到了如何處理“抽象概念”這個亙古難題的方法。
機器學習(Machine Learning)是一門專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構市值不斷改善自身的性能的學科,簡單地說,機器學習就是通過算法,使得機器能從大量的歷史數據中學習規律,從而對新的樣本做智能識別或預測未來。
機器學習在圖像識別、語音識別、自然語言理解、天氣預測、基因表達、內容推薦等很多方面的發展還存在著沒有良好解決的問題。
傳統的模式識別方法:通過傳感器獲取數據,然后經過預處理、特征提取、特征選擇、再到推理、預測或識別。

開始的通過傳感器(例如CMOS)來獲得數據。然后經過預處理、特征提取、特征選擇,再到推理、預測或者識別。最后一個部分,也就是機器學習的部分,絕大部分的工作是在這方面做的,也存在很多的paper和研究。
而中間的三部分,概括起來就是特征表達。良好的特征表達,對最終算法的準確性起了非常關鍵的作用,而且系統主要的計算和測試工作都耗在這一大部分。但,這塊實際中一般都是人工完成的,靠人工提取特征。而手工選取特征費時費力,需要專業知識,很大程度上靠經驗和運氣,那么機器能不能自動的學習特征呢?深度學習的出現就這個問題提出了一種解決方案。
人腦的視覺機理
1981 年的諾貝爾醫學獎,頒發給了 David Hubel(出生于加拿大的美國神經生物學家)和TorstenWiesel,以及 Roger Sperry。前兩位的主要貢獻,是“發現了視覺系統的信息處理”可視皮層是分級的。
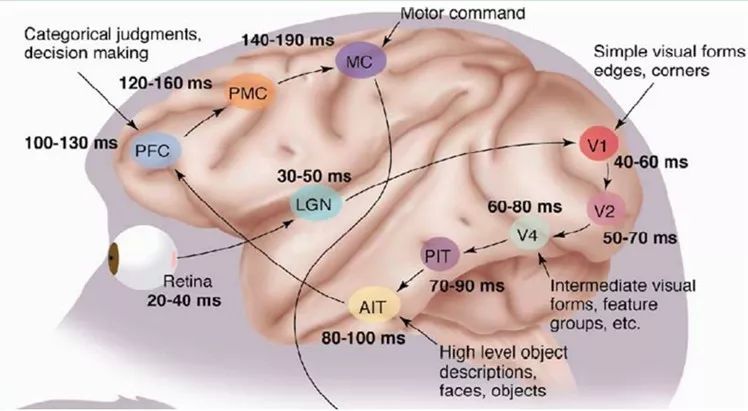
1958 年,DavidHubel 和Torsten Wiesel 在 JohnHopkins University,研究瞳孔區域與大腦皮層神經元的對應關系。他們在貓的后腦頭骨上,開了一個3 毫米的小洞,向洞里插入電極,測量神經元的活躍程度。
然后,他們在小貓的眼前,展現各種形狀、各種亮度的物體。并且,在展現每一件物體時,還改變物體放置的位置和角度。他們期望通過這個辦法,讓小貓瞳孔感受不同類型、不同強弱的刺激。
之所以做這個試驗,目的是去證明一個猜測。位于后腦皮層的不同視覺神經元,與瞳孔所受刺激之間,存在某種對應關系。一旦瞳孔受到某一種刺激,后腦皮層的某一部分神經元就會活躍。經歷了很多天反復的枯燥的試驗,David Hubel 和Torsten Wiesel 發現了一種被稱為“方向選擇性細胞(Orientation Selective Cell)”的神經元細胞。當瞳孔發現了眼前的物體的邊緣,而且這個邊緣指向某個方向時,這種神經元細胞就會活躍。
這個發現激發了人們對于神經系統的進一步思考。神經-中樞-大腦的工作過程,或許是一個不斷迭代、不斷抽象的過程。
例如,從原始信號攝入開始(瞳孔攝入像素 Pixels),接著做初步處理(大腦皮層某些細胞發現邊緣和方向),然后抽象(大腦判定,眼前的物體的形狀,是圓形的),然后進一步抽象(大腦進一步判定該物體是只氣球)。
這個生理學的發現,促成了計算機人工智能,在四十年后的突破性發展。
總的來說,人的視覺系統的信息處理是分級的。從低級的V1區提取邊緣特征,再到V2區的形狀或者目標的部分等,再到更高層,整個目標、目標的行為等。也就是說高層的特征是低層特征的組合,從低層到高層的特征表示越來越抽象,越來越能表現語義或者意圖。而抽象層面越高,存在的可能猜測就越少,就越利于分類。例如,單詞集合和句子的對應是多對一的,句子和語義的對應又是多對一的,語義和意圖的對應還是多對一的,這是個層級體系。
機器學習的特征
特征是機器學習系統的原材料,對最終模型的影響是毋庸置疑的。如果數據被很好的表達成了特征,通常線性模型就能達到滿意的精度。
特征表示的粒度
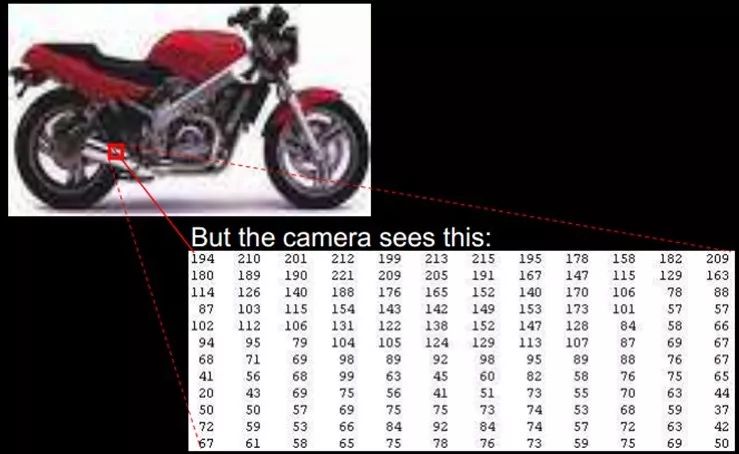
學習算法在一個什么粒度上的特征表示,才有能發揮作用?就一個圖片來說,像素級的特征根本沒有價值。例如下面的摩托車,從像素級別,根本得不到任何信息,其無法進行摩托車和非摩托車的區分。而如果特征是一個具有結構性(或者說有含義)的時候,比如是否具有車把手(handle),是否具有車輪(wheel),就很容易把摩托車和非摩托車區分,學習算法才能發揮作用。
初級(淺層)特征表示
既然像素級的特征表示方法沒有作用,那怎樣的表示才有用呢?
1995 年前后,Bruno Olshausen和 David Field 兩位學者任職 Cornell University,他們試圖同時用生理學和計算機的手段,雙管齊下,研究視覺問題。
他們收集了很多黑白風景照片,從這些照片中,提取出400個小碎片,每個照片碎片的尺寸均為 16x16 像素,不妨把這400個碎片標記為 S[i], i = 0,.. 399。接下來,再從這些黑白風景照片中,隨機提取另一個碎片,尺寸也是 16x16 像素,不妨把這個碎片標記為 T。
他們提出的問題是,如何從這400個碎片中,選取一組碎片,S[k], 通過疊加的辦法,合成出一個新的碎片,而這個新的碎片,應當與隨機選擇的目標碎片 T,盡可能相似,同時,S[k] 的數量盡可能少。用數學的語言來描述,就是:Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在疊加碎片 S[k] 時的權重系數。
為解決這個問題,Bruno Olshausen和 David Field 發明了一個算法,稀疏編碼(Sparse Coding)。
稀疏編碼是一個重復迭代的過程,每次迭代分兩步:
1)選擇一組 S[k],然后調整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 個碎片中,選擇其它更合適的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
經過幾次迭代后,最佳的 S[k] 組合,被遴選出來了。令人驚奇的是,被選中的 S[k],基本上都是照片上不同物體的邊緣線,這些線段形狀相似,區別在于方向。
Bruno Olshausen和 David Field 的算法結果,與 David Hubel 和Torsten Wiesel 的生理發現,不謀而合!
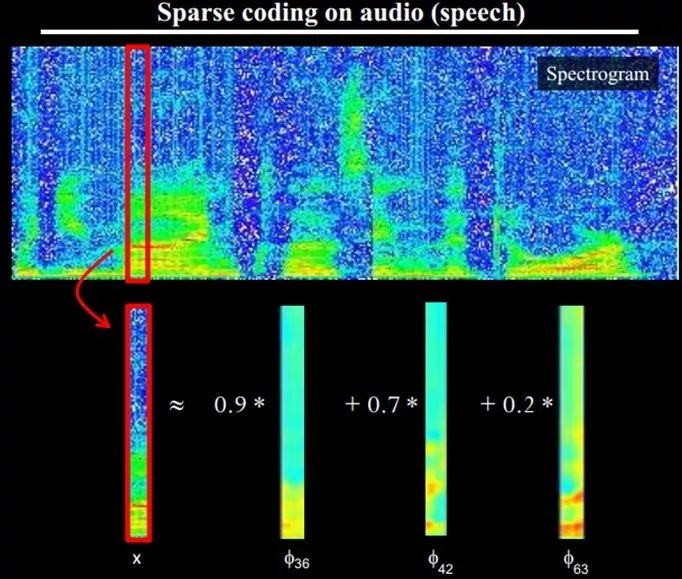
也就是說,復雜圖形,往往由一些基本結構組成。比如下圖:一個圖可以通過用64種正交的edges(可以理解成正交的基本結構)來線性表示。比如樣例的x可以用1-64個edges中的三個按照0.8,0.3,0.5的權重調和而成。而其他基本edge沒有貢獻,因此均為0 。
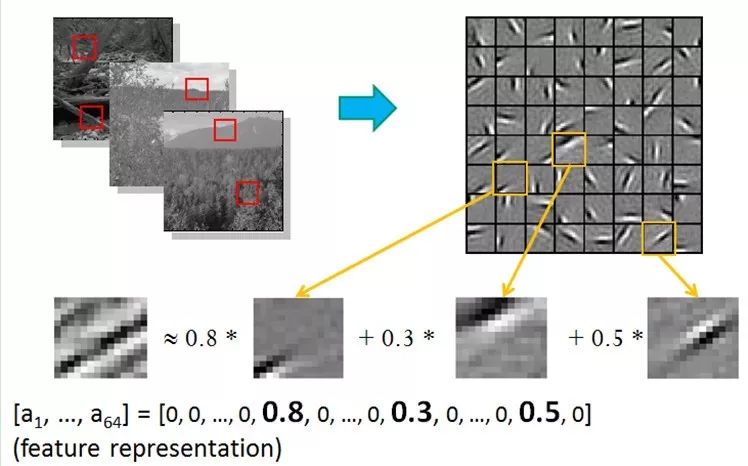
另外,不僅圖像存在這個規律,聲音也存在。人們從未標注的聲音中發現了20種基本的聲音結構,其余的聲音可以由這20種基本結構合成。
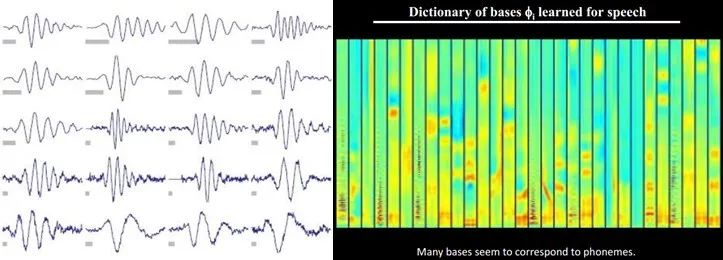
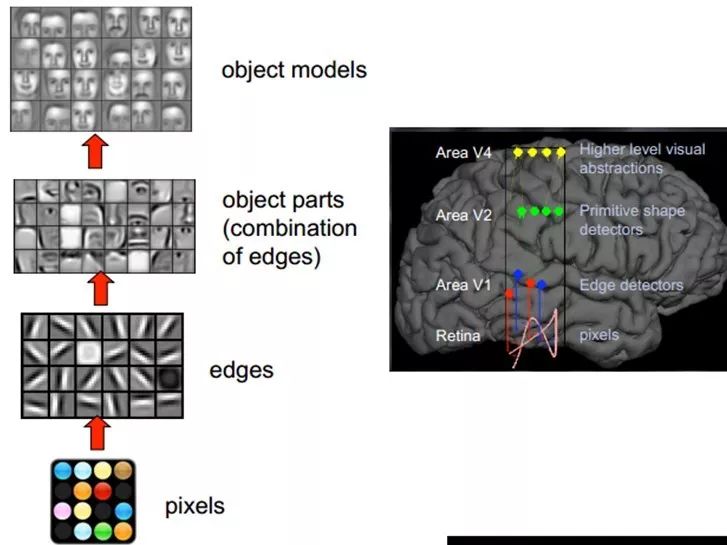
結構性特征表示
小塊的圖形可以由基本edge構成,更結構化,更復雜的,具有概念性的圖形如何表示呢?這就需要更高層次的特征表示,比如V2,V4。因此V1看像素級是像素級。V2看V1是像素級,這個是層次遞進的,高層表達由底層表達的組合而成。專業點說就是基basis。V1取提出的basis是邊緣,然后V2層是V1層這些basis的組合,這時候V2區得到的又是高一層的basis。即上一層的basis組合的結果,上上層又是上一層的組合basis……(所以有大牛說Deep learning就是“搞基”,因為難聽,所以美其名曰Deep learning或者Unsupervised Feature Learning)

直觀上說,就是找到make sense的小patch再將其進行combine,就得到了上一層的feature,遞歸地向上learning feature。
在不同object上做training是,所得的edge basis 是非常相似的,但object parts和models 就會completely different了(那咱們分辨car或者face是不是容易多了)。

我們知道需要層次的特征構建,由淺入深,但每一層該有多少個特征呢?
任何一種方法,特征越多,給出的參考信息就越多,準確性會得到提升。但特征多意味著計算復雜,探索的空間大,可以用來訓練的數據在每個特征上就會稀疏,都會帶來各種問題,并不一定特征越多越好。
深度學習的基本思想
假設我們有一個系統S,它有n層(S1,…Sn),它的輸入是I,輸出是O,形象地表示為:I =>S1=>S2=>…..=>Sn => O,如果輸出O等于輸入I,即輸入I經過這個系統變化之后沒有任何的信息損失(呵呵,大牛說,這是不可能的。信息論中有個“信息逐層丟失”的說法(信息處理不等式),設處理a信息得到b,再對b處理得到c,那么可以證明:a和c的互信息不會超過a和b的互信息。這表明信息處理不會增加信息,大部分處理會丟失信息。當然了,如果丟掉的是沒用的信息那多好啊),保持了不變,這意味著輸入I經過每一層Si都沒有任何的信息損失,即在任何一層Si,它都是原有信息(即輸入I)的另外一種表示。現在回到我們的主題Deep Learning,我們需要自動地學習特征,假設我們有一堆輸入I(如一堆圖像或者文本),假設我們設計了一個系統S(有n層),我們通過調整系統中參數,使得它的輸出仍然是輸入I,那么我們就可以自動地獲取得到輸入I的一系列層次特征,即S1,…, Sn。
對于深度學習來說,其思想就是對堆疊多個層,也就是說這一層的輸出作為下一層的輸入。通過這種方式,就可以實現對輸入信息進行分級表達了。
另外,前面是假設輸出嚴格地等于輸入,這個限制太嚴格,我們可以略微地放松這個限制,例如我們只要使得輸入與輸出的差別盡可能地小即可,這個放松會導致另外一類不同的Deep Learning方法。上述就是Deep Learning的基本思想。
淺層學習和深度學習
20世紀80年代末期,用于人工神經網絡的反向傳播算法(也叫Back Propagation算法或者BP算法)的發明,給機器學習帶來了希望,掀起了基于統計模型的機器學習熱潮。這個熱潮一直持續到今天。人們發現,利用BP算法可以讓一個人工神經網絡模型從大量訓練樣本中學習統計規律,從而對未知事件做預測。這種基于統計的機器學習方法比起過去基于人工規則的系統,在很多方面顯出優越性。這個時候的人工神經網絡,雖也被稱作多層感知機(Multi-layer Perceptron),但實際是種只含有一層隱層節點的淺層模型。
20世紀90年代,各種各樣的淺層機器學習模型相繼被提出,例如支撐向量機(SVM,Support Vector Machines)、 Boosting、最大熵方法(如LR,Logistic Regression)等。這些模型的結構基本上可以看成帶有一層隱層節點(如SVM、Boosting),或沒有隱層節點(如LR)。這些模型無論是在理論分析還是應用中都獲得了巨大的成功。相比之下,由于理論分析的難度大,訓練方法又需要很多經驗和技巧,這個時期淺層人工神經網絡反而相對沉寂。
2006年,加拿大多倫多大學教授、機器學習領域的泰斗Geoffrey Hinton和他的學生RuslanSalakhutdinov在《科學》上發表了一篇文章,開啟了深度學習在學術界和工業界的浪潮。這篇文章有兩個主要觀點:1)多隱層的人工神經網絡具有優異的特征學習能力,學習得到的特征對數據有更本質的刻畫,從而有利于可視化或分類;2)深度神經網絡在訓練上的難度,可以通過“逐層初始化”(layer-wise pre-training)來有效克服,在這篇文章中,逐層初始化是通過無監督學習實現的。
當前多數分類、回歸等學習方法為淺層結構算法,其局限性在于有限樣本和計算單元情況下對復雜函數的表示能力有限,針對復雜分類問題其泛化能力受到一定制約。深度學習可通過學習一種深層非線性網絡結構,實現復雜函數逼近,表征輸入數據分布式表示,并展現了強大的從少數樣本集中學習數據集本質特征的能力。(多層的好處是可以用較少的參數表示復雜的函數)
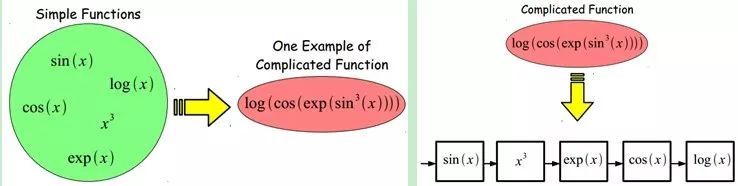
深度學習的實質,是通過構建具有很多隱層的機器學習模型和海量的訓練數據,來學習更有用的特征,從而最終提升分類或預測的準確性。因此,“深度模型”是手段,“特征學習”是目的。區別于傳統的淺層學習,深度學習的不同在于:1)強調了模型結構的深度,通常有5層、6層,甚至10多層的隱層節點;2)明確突出了特征學習的重要性,也就是說,通過逐層特征變換,將樣本在原空間的特征表示變換到一個新特征空間,從而使分類或預測更加容易。與人工規則構造特征的方法相比,利用大數據來學習特征,更能夠刻畫數據的豐富內在信息。
深度學習與神經網絡
深度學習是機器學習研究中的一個新的領域,其動機在于建立、模擬人腦進行分析學習的神經網絡,它模仿人腦的機制來解釋數據,例如圖像,聲音和文本。深度學習是無監督學習的一種。
深度學習的概念源于人工神經網絡的研究。含多隱層的多層感知器就是一種深度學習結構。深度學習通過組合低層特征形成更加抽象的高層表示屬性類別或特征,以發現數據的分布式特征表示。
Deep learning本身算是machine learning的一個分支,簡單可以理解為neural network的發展。大約二三十年前,neural network曾經是ML領域特別火熱的一個方向,但是后來確慢慢淡出了,原因包括以下幾個方面:
1)比較容易過擬合,參數比較難tune,而且需要不少trick;
2)訓練速度比較慢,在層次比較少(小于等于3)的情況下效果并不比其它方法更優;
所以中間有大約20多年的時間,神經網絡被關注很少,這段時間基本上是SVM和boosting算法的天下。但是,一個癡心的老先生Hinton,他堅持了下來,并最終(和其它人一起Bengio、Yann.lecun等)提成了一個實際可行的deep learning框架。
Deep learning與傳統的神經網絡之間有相同的地方也有很多不同:
二者的相同在于deep learning采用了神經網絡相似的分層結構,系統由包括輸入層、隱層(多層)、輸出層組成的多層網絡,只有相鄰層節點之間有連接,同一層以及跨層節點之間相互無連接,每一層可以看作是一個logistic regression模型;這種分層結構,是比較接近人類大腦的結構的。
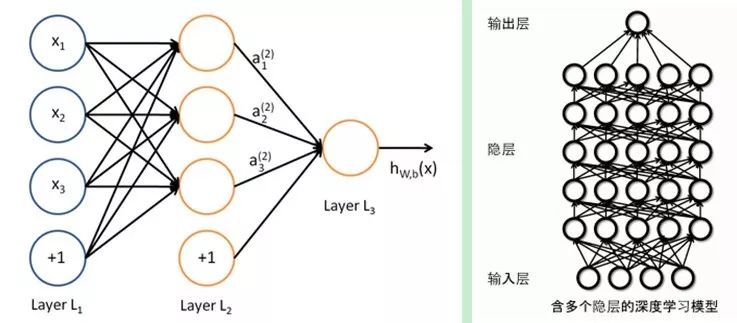
而為了克服神經網絡訓練中的問題,DL采用了與神經網絡很不同的訓練機制。傳統神經網絡中,采用的是back propagation的方式進行,簡單來講就是采用迭代的算法來訓練整個網絡,隨機設定初值,計算當前網絡的輸出,然后根據當前輸出和label之間的差去改變前面各層的參數,直到收斂(整體是一個梯度下降法)。而deep learning整體上是一個layer-wise的訓練機制。
深度學習的訓練過程
使用自下上升非監督學習(就是從底層開始,一層一層的往頂層訓練)
采用無標定數據(有標定數據也可)分層訓練各層參數,這一步可以看作是一個無監督訓練過程,是和傳統神經網絡區別最大的部分(這個過程可以看作是feature learning過程):
具體的,先用無標定數據訓練第一層,訓練時先學習第一層的參數(這一層可以看作是得到一個使得輸出和輸入差別最小的三層神經網絡的隱層),由于模型capacity的限制以及稀疏性約束,使得得到的模型能夠學習到數據本身的結構,從而得到比輸入更具有表示能力的特征;在學習得到第n-1層后,將n-1層的輸出作為第n層的輸入,訓練第n層,由此分別得到各層的參數;
自頂向下的監督學習(就是通過帶標簽的數據去訓練,誤差自頂向下傳輸,對網絡進行微調)
基于第一步得到的各層參數進一步fine-tune整個多層模型的參數,這一步是一個有監督訓練過程;第一步類似神經網絡的隨機初始化初值過程,由于DL的第一步不是隨機初始化,而是通過學習輸入數據的結構得到的,因而這個初值更接近全局最優,從而能夠取得更好的效果;所以deep learning效果好很大程度上歸功于第一步的feature learning過程。
CNNs卷積神經網絡
卷積神經網絡是人工神經網絡的一種,已成為當前語音分析和圖像識別領域的研究熱點。它的權值共享網絡結構使之更類似于生物神經網絡,降低了網絡模型的復雜度,減少了權值的數量。該優點在網絡的輸入是多維圖像時表現的更為明顯,使圖像可以直接作為網絡的輸入,避免了傳統識別算法中復雜的特征提取和數據重建過程。卷積網絡是為識別二維形狀而特殊設計的一個多層感知器,這種網絡結構對平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。
CNNs是受早期的延時神經網絡(TDNN)的影響。延時神經網絡通過在時間維度上共享權值降低學習復雜度,適用于語音和時間序列信號的處理。
CNNs是第一個真正成功訓練多層網絡結構的學習算法。它利用空間關系減少需要學習的參數數目以提高一般前向BP算法的訓練性能。CNNs作為一個深度學習架構提出是為了最小化數據的預處理要求。在CNN中,圖像的一小部分(局部感受區域)作為層級結構的最低層的輸入,信息再依次傳輸到不同的層,每層通過一個數字濾波器去獲得觀測數據的最顯著的特征。這個方法能夠獲取對平移、縮放和旋轉不變的觀測數據的顯著特征,因為圖像的局部感受區域允許神經元或者處理單元可以訪問到最基礎的特征,例如定向邊緣或者角點。
卷積神經網絡的歷史
1962年Hubel和Wiesel通過對貓視覺皮層細胞的研究,提出了感受野(receptive field)的概念,1984年日本學者Fukushima基于感受野概念提出的神經認知機(neocognitron)可以看作是卷積神經網絡的第一個實現網絡,也是感受野概念在人工神經網絡領域的首次應用。神經認知機將一個視覺模式分解成許多子模式(特征),然后進入分層遞階式相連的特征平面進行處理,它試圖將視覺系統模型化,使其能夠在即使物體有位移或輕微變形的時候,也能完成識別。
通常神經認知機包含兩類神經元,即承擔特征抽取的S-元和抗變形的C-元。S-元中涉及兩個重要參數,即感受野與閾值參數,前者確定輸入連接的數目,后者則控制對特征子模式的反應程度。許多學者一直致力于提高神經認知機的性能的研究:在傳統的神經認知機中,每個S-元的感光區中由C-元帶來的視覺模糊量呈正態分布。如果感光區的邊緣所產生的模糊效果要比中央來得大,S-元將會接受這種非正態模糊所導致的更大的變形容忍性。我們希望得到的是,訓練模式與變形刺激模式在感受野的邊緣與其中心所產生的效果之間的差異變得越來越大。為了有效地形成這種非正態模糊,Fukushima提出了帶雙C-元層的改進型神經認知機。
Van Ooyen和Niehuis為提高神經認知機的區別能力引入了一個新的參數。事實上,該參數作為一種抑制信號,抑制了神經元對重復激勵特征的激勵。多數神經網絡在權值中記憶訓練信息。根據Hebb學習規則,某種特征訓練的次數越多,在以后的識別過程中就越容易被檢測。也有學者將進化計算理論與神經認知機結合,通過減弱對重復性激勵特征的訓練學習,而使得網絡注意那些不同的特征以助于提高區分能力。上述都是神經認知機的發展過程,而卷積神經網絡可看作是神經認知機的推廣形式,神經認知機是卷積神經網絡的一種特例。
卷積神經網絡的網絡結構
卷積神經網絡是一個多層的神經網絡,每層由多個二維平面組成,而每個平面由多個獨立神經元組成。
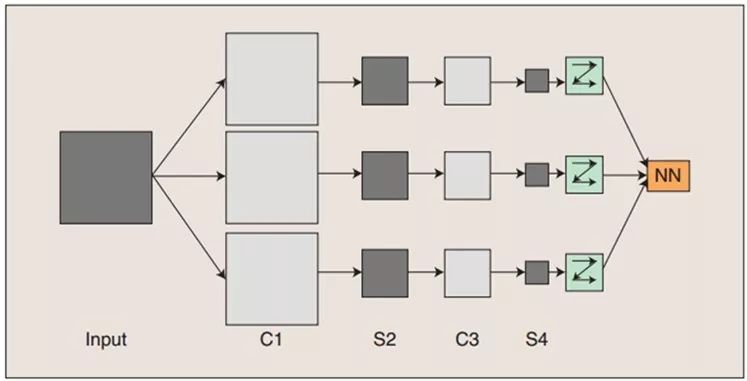
卷積神經網絡的概念示范:輸入圖像通過和三個可訓練的濾波器和可加偏置進行卷積,濾波過程如圖一,卷積后在C1層產生三個特征映射圖,然后特征映射圖中每組的四個像素再進行求和,加權值,加偏置,通過一個Sigmoid函數得到三個S2層的特征映射圖。這些映射圖再進過濾波得到C3層。這個層級結構再和S2一樣產生S4。最終,這些像素值被光柵化,并連接成一個向量輸入到傳統的神經網絡,得到輸出。
一般地,C層為特征提取層,每個神經元的輸入與前一層的局部感受野相連,并提取該局部的特征,一旦該局部特征被提取后,它與其他特征間的位置關系也隨之確定下來;S層是特征映射層,網絡的每個計算層由多個特征映射組成,每個特征映射為一個平面,平面上所有神經元的權值相等。特征映射結構采用影響函數核小的sigmoid函數作為卷積網絡的激活函數,使得特征映射具有位移不變性。
此外,由于一個映射面上的神經元共享權值,因而減少了網絡自由參數的個數,降低了網絡參數選擇的復雜度。卷積神經網絡中的每一個特征提取層(C-層)都緊跟著一個用來求局部平均與二次提取的計算層(S-層),這種特有的兩次特征提取結構使網絡在識別時對輸入樣本有較高的畸變容忍能力。
卷積神經網絡訓練過程
神經網絡用于模式識別的主流是有指導學習網絡,無指導學習網絡更多的是用于聚類分析。對于有指導的模式識別,由于任一樣本的類別是已知的,樣本在空間的分布不再是依據其自然分布傾向來劃分,而是要根據同類樣本在空間的分布及不同類樣本之間的分離程度找一種適當的空間劃分方法,或者找到一個分類邊界,使得不同類樣本分別位于不同的區域內。這就需要一個長時間且復雜的學習過程,不斷調整用以劃分樣本空間的分類邊界的位置,使盡可能少的樣本被劃分到非同類區域中。
卷積網絡在本質上是一種輸入到輸出的映射,它能夠學習大量的輸入與輸出之間的映射關系,而不需要任何輸入和輸出之間的精確的數學表達式,只要用已知的模式對卷積網絡加以訓練,網絡就具有輸入輸出對之間的映射能力。卷積網絡執行的是有導師訓練,所以其樣本集是由形如:(輸入向量,理想輸出向量)的向量對構成的。所有這些向量對,都應該是來源于網絡即將模擬的系統的實際“運行”結果。它們可以是從實際運行系統中采集來的。在開始訓練前,所有的權都應該用一些不同的小隨機數進行初始化。“小隨機數”用來保證網絡不會因權值過大而進入飽和狀態,從而導致訓練失敗;“不同”用來保證網絡可以正常地學習。實際上,如果用相同的數去初始化權矩陣,則網絡無能力學習。
訓練算法與傳統的BP算法差不多。主要包括4步,這4步被分為兩個階段:
第一階段,向前傳播階段:
a)從樣本集中取一個樣本(X,Yp),將X輸入網絡;
b)計算相應的實際輸出Op。
在此階段,信息從輸入層經過逐級的變換,傳送到輸出層。這個過程也是網絡在完成訓練后正常運行時執行的過程。在此過程中,網絡執行的是計算(實際上就是輸入與每層的權值矩陣相點乘,得到最后的輸出結果):Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二階段,向后傳播階段
a)算實際輸出Op與相應的理想輸出Yp的差;
b)按極小化誤差的方法反向傳播調整權矩陣。
卷積神經網絡的優點
卷積神經網絡CNN主要用來識別位移、縮放及其他形式扭曲不變性的二維圖形。由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯式的特征抽取,而隱式地從訓練數據中進行學習;再者由于同一特征映射面上的神經元權值相同,所以網絡可以并行學習,這也是卷積網絡相對于神經元彼此相連網絡的一大優勢。卷積神經網絡以其局部權值共享的特殊結構在語音識別和圖像處理方面有著獨特的優越性,其布局更接近于實際的生物神經網絡,權值共享降低了網絡的復雜性,特別是多維輸入向量的圖像可以直接輸入網絡這一特點避免了特征提取和分類過程中數據重建的復雜度。
流的分類方式幾乎都是基于統計特征的,這就意味著在進行分辨前必須提取某些特征。然而,顯式的特征提取并不容易,在一些應用問題中也并非總是可靠的。卷積神經網絡,它避免了顯式的特征取樣,隱式地從訓練數據中進行學習。這使得卷積神經網絡明顯有別于其他基于神經網絡的分類器,通過結構重組和減少權值將特征提取功能融合進多層感知器。它可以直接處理灰度圖片,能夠直接用于處理基于圖像的分類。
卷積網絡較一般神經網絡在圖像處理方面有如下優點:
a)輸入圖像和網絡的拓撲結構能很好的吻合;
b)特征提取和模式分類同時進行,并同時在訓練中產生;c)權重共享可以減少網絡的訓練參數,使神經網絡結構變得更簡單,適應性更強。
-
傳感器
+關注
關注
2552文章
51320瀏覽量
755304 -
機器學習
+關注
關注
66文章
8429瀏覽量
132852 -
深度學習
+關注
關注
73文章
5511瀏覽量
121350
原文標題:深度學習詳解
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Lucky!永磁同步電機直、交軸電感Ld,Lq計算終于找到了!
如何處理PSoc Creatorlicenceerror這個屏幕?
如何處理這個USB_RENUMn引腳呢?
基站阻塞和基站失步的概念區分及處理方法
示波器如何處理有噪聲的信號?
如何處理重現使用仿真發現的死鎖漏洞






 工商網監
工商網監
評論