 GBDT算法原理以及實例理解
GBDT算法原理以及實例理解
寫在前面:去年學習GBDT之初,為了加強對算法的理解,整理了一篇筆記形式的文章,發出去之后發現閱讀量越來越多,漸漸也有了評論,評論中大多指出來了筆者理解或者編輯的錯誤,故重新編輯一版文章,內容更加翔實,并且在GitHub上實現了和本文一致的GBDT簡易版(包括回歸、二分類、多分類以及可視化),供大家交流探討。感謝各位的點贊和評論,希望繼續指出錯誤~Github:
簡介:
GBDT 的全稱是 Gradient Boosting Decision Tree,梯度提升樹,在傳統機器學習算法中,GBDT算的上TOP3的算法。想要理解GBDT的真正意義,那就必須理解GBDT中的Gradient Boosting 和Decision Tree分別是什么?
1. Decision Tree:CART回歸樹
首先,GBDT使用的決策樹是CART回歸樹,無論是處理回歸問題還是二分類以及多分類,GBDT使用的決策樹通通都是都是CART回歸樹。為什么不用CART分類樹呢?因為GBDT每次迭代要擬合的是梯度值,是連續值所以要用回歸樹。
對于回歸樹算法來說最重要的是尋找最佳的劃分點,那么回歸樹中的可劃分點包含了所有特征的所有可取的值。在分類樹中最佳劃分點的判別標準是熵或者基尼系數,都是用純度來衡量的,但是在回歸樹中的樣本標簽是連續數值,所以再使用熵之類的指標不再合適,取而代之的是平方誤差,它能很好的評判擬合程度。
回歸樹生成算法:
輸入:訓練數據集D:輸出:回歸樹f(x).在訓練數據集所在的輸入空間中,遞歸的將每個區域劃分為兩個子區域并決定每個子區域上的輸出值,構建二叉決策樹:(1)選擇最優切分變量jj與切分點s,求解
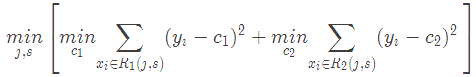
遍歷變量j,對固定的切分變量j掃描切分點s,選擇使得上式達到最小值的對(j,s).
(2)用選定的對(j,s)劃分區域并決定相應的輸出值:
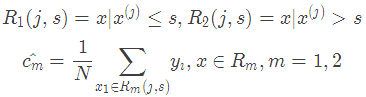
(3)繼續對兩個子區域調用步驟(1)和(2),直至滿足停止條件。
(4)將輸入空間劃分為M個區域 ,生成決策樹:
,生成決策樹:
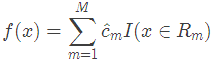
2. Gradient Boosting:擬合負梯度
梯度提升樹(Grandient Boosting)是提升樹(Boosting Tree)的一種改進算法,所以在講梯度提升樹之前先來說一下提升樹。
先來個通俗理解:假如有個人30歲,我們首先用20歲去擬合,發現損失有10歲,這時我們用6歲去擬合剩下的損失,發現差距還有4歲,第三輪我們用3歲擬合剩下的差距,差距就只有一歲了。如果我們的迭代輪數還沒有完,可以繼續迭代下面,每一輪迭代,擬合的歲數誤差都會減小。最后將每次擬合的歲數加起來便是模型輸出的結果。
提升樹算法:
(1)初始化
(2)對m=1,2,…,M?(a)計算殘差

(b)擬合殘差 學習一個回歸樹,得到
學習一個回歸樹,得到
(c) 更新
(3)得到回歸問題提升樹
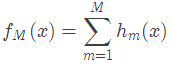
上面偽代碼中的殘差是什么?在提升樹算法中,假設我們前一輪迭代得到的強學習器是
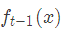
損失函數是
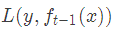
我們本輪迭代的目標是找到一個弱學習器
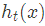
最小化本輪的損失
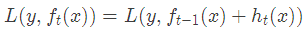
當采用平方損失函數時
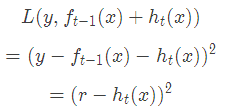
這里,
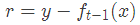
是當前模型擬合數據的殘差(residual)。所以,對于提升樹來說只需要簡單地擬合當前模型的殘差。??回到我們上面講的那個通俗易懂的例子中,第一次迭代的殘差是10歲,第二次殘差4歲...
當損失函數是平方損失和指數損失函數時,梯度提升樹每一步優化是很簡單的,但是對于一般損失函數而言,往往每一步優化起來不那么容易,針對這一問題,Freidman提出了梯度提升樹算法,這是利用最速下降的近似方法,其關鍵是利用損失函數的負梯度作為提升樹算法中的殘差的近似值。那么負梯度長什么樣呢?第t輪的第i個樣本的損失函數的負梯度為:
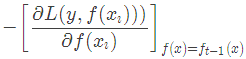
此時不同的損失函數將會得到不同的負梯度,如果選擇平方損失
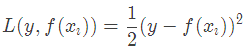
負梯度為
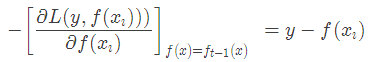
此時我們發現GBDT的負梯度就是殘差,所以說對于回歸問題,我們要擬合的就是殘差。??那么對于分類問題呢?二分類和多分類的損失函數都是log loss,本文以回歸問題為例進行講解。
3. GBDT算法原理
上面兩節分別將Decision Tree和Gradient Boosting介紹完了,下面將這兩部分組合在一起就是我們的GBDT了。
GBDT算法:(1)初始化弱學習器
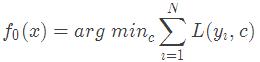
(2)對m=1,2,…,M有:
(a)對每個樣本i=1,2,…,N,計算負梯度,即殘差
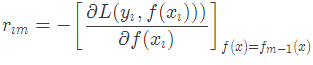
(b)將上步得到的殘差作為樣本新的真實值,并將數據 作為下棵樹的訓練數據,得到一顆新的回歸樹
作為下棵樹的訓練數據,得到一顆新的回歸樹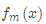 ,其對應的葉子節點區域為
,其對應的葉子節點區域為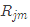 ,
, 。其中J為回歸樹t的葉子節點的個數。
。其中J為回歸樹t的葉子節點的個數。
(c)對葉子區域j =1,2,..J計算最佳擬合值
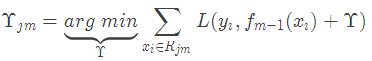
(d)更新強學習器
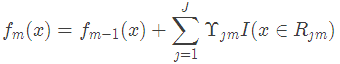
(3)得到最終學習器
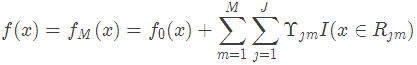
4. 實例詳解
==本人用python以及pandas庫實現GBDT的簡易版本,在下面的例子中用到的數據都在github可以找到,大家可以結合代碼和下面的例子進行理解,歡迎star~==??Github:https://github.com/Freemanzxp/GBDT_Simple_Tutorial
數據介紹:
如下表所示:一組數據,特征為年齡、體重,身高為標簽值。共有5條數據,前四條為訓練樣本,最后一條為要預測的樣本。
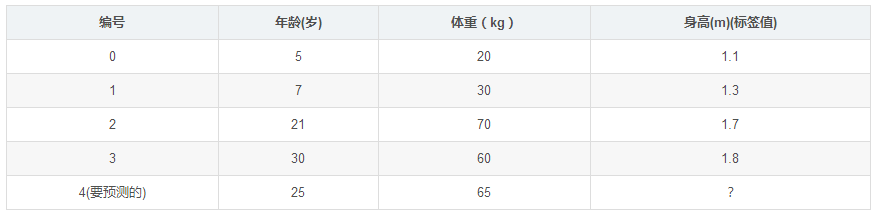
訓練階段:
參數設置:
學習率:learning_rate=0.1
迭代次數:n_trees=5
樹的深度:max_depth=3
1.初始化弱學習器:
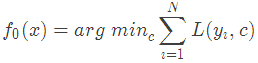
損失函數為平方損失,因為平方損失函數是一個凸函數,直接求導,倒數等于零,得到c。
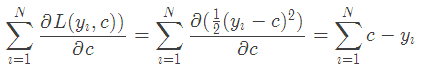
令導數等于0
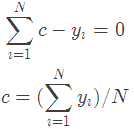
所以初始化時,c取值為所有訓練樣本標簽值的均值。c=(1.1+1.3+1.7+1.8)/4=1.475,此時得到初始學習器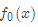
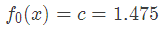
2.對迭代輪數m=1,2,…,M:??由于我們設置了迭代次數:n_trees=5,這里的M=5。??計算負梯度,根據上文損失函數為平方損失時,負梯度就是殘差殘差,再直白一點就是y與上一輪得到的學習器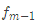 的差值
的差值
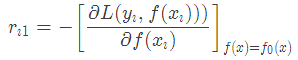
殘差在下表列出:
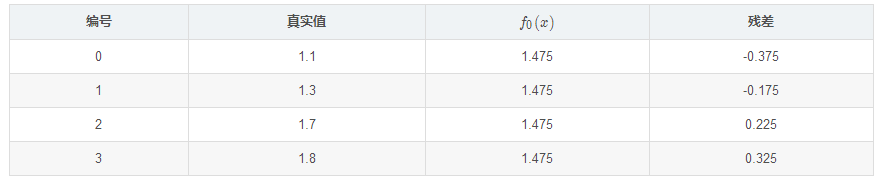
此時將殘差作為樣本的真實值來訓練弱學習器 ,即下表數據:
,即下表數據:
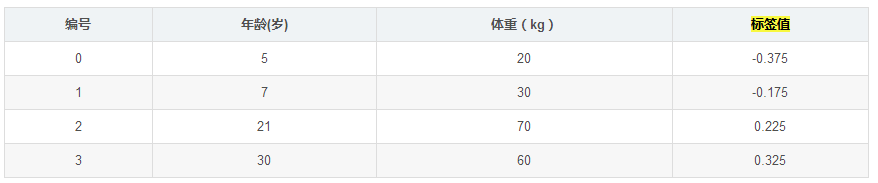
接著,尋找回歸樹的最佳劃分節點,遍歷每個特征的每個可能取值。從年齡特征的5開始,到體重特征的70結束,分別計算分裂后兩組數據的平方損失(Square Error), 左節點平方損失,
左節點平方損失, 右節點平方損失,找到使平方損失和
右節點平方損失,找到使平方損失和 最小的那個劃分節點,即為最佳劃分節點。
最小的那個劃分節點,即為最佳劃分節點。
例如:以年齡7為劃分節點,將小于7的樣本劃分為到左節點,大于等于7的樣本劃分為右節點。
左節點包括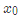 ,右節點包括樣本
,右節點包括樣本 ,
,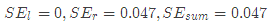 ,所有可能劃分情況如下表所示:
,所有可能劃分情況如下表所示:
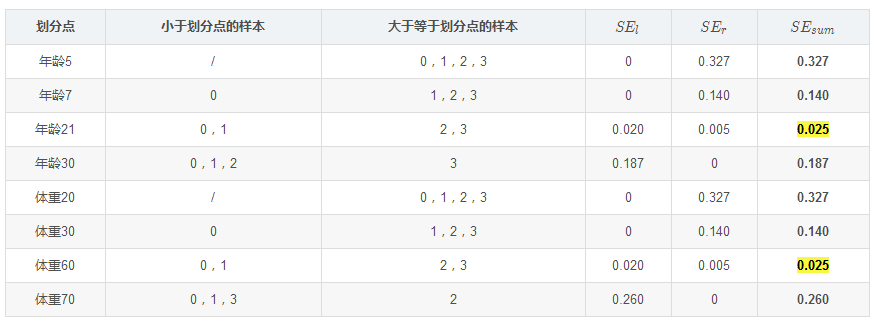
以上劃分點是的總平方損失最小為0.025有兩個劃分點:年齡21和體重60,所以隨機選一個作為劃分點,這里我們選年齡21??現在我們的第一棵樹長這個樣子:
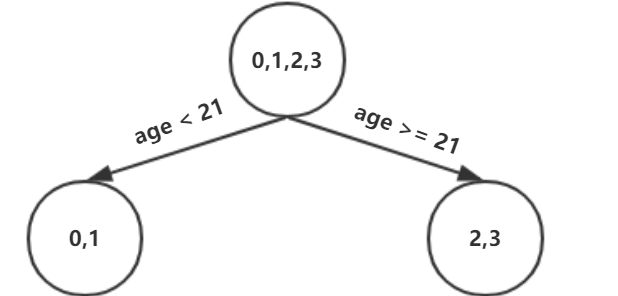
我們設置的參數中樹的深度max_depth=3,現在樹的深度只有2,需要再進行一次劃分,這次劃分要對左右兩個節點分別進行劃分:
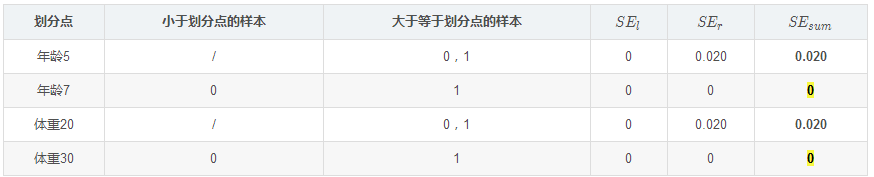
對于左節點,只含有0,1兩個樣本,根據下表我們選擇年齡7劃分
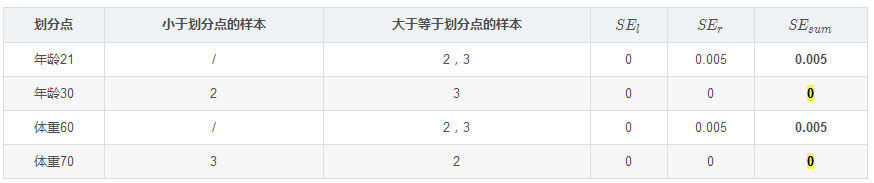
對于右節點,只含有2,3兩個樣本,根據下表我們選擇年齡30劃分(也可以選體重70)
現在我們的第一棵樹長這個樣子:
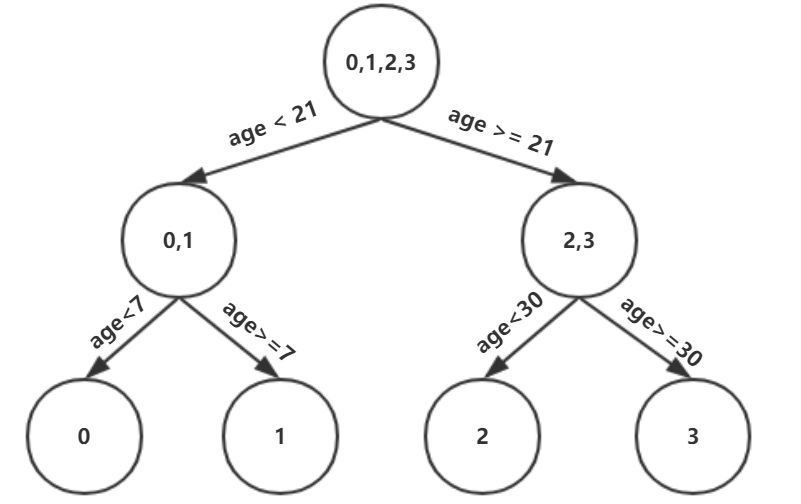
此時我們的樹深度滿足了設置,還需要做一件事情,給這每個葉子節點分別賦一個參數Υ,來擬合殘差。
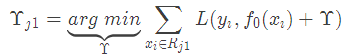
這里其實和上面初始化學習器是一個道理,平方損失求導,令導數等于零,化簡之后得到每個葉子節點的參數Υ,其實就是標簽值的均值。這個地方的標簽值不是原始的 y,而是本輪要擬合的標殘差 。
。
根據上述劃分結果,為了方便表示,規定從左到右為第1,2,3,4個葉子結點
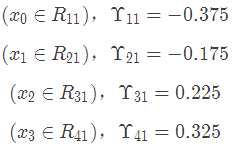
此時的樹長這個樣子:
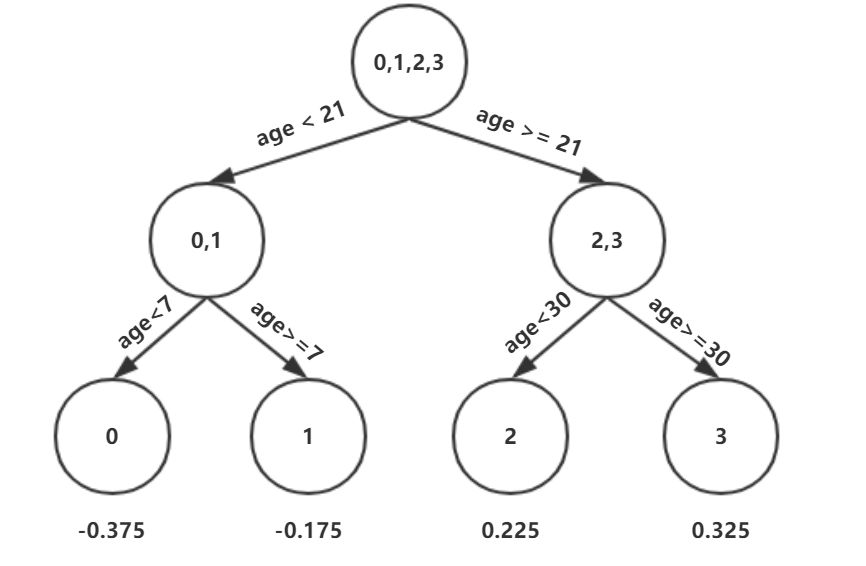
此時可更新強學習器,需要用到參數學習率:learning_rate=0.1,用lr表示。
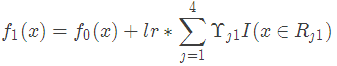
為什么要用學習率呢?這是Shrinkage的思想,如果每次都全部加上(學習率為1)很容易一步學到位導致過擬合。
重復此步驟,直到m>5結束,最后生成5棵樹。下面將展示每棵樹最終的結構,這些圖都是GitHub上的代碼生成的,感興趣的同學可以去一探究竟
Github:https://github.com/Freemanzxp/GBDT_Simple_Tutorial第一棵樹:
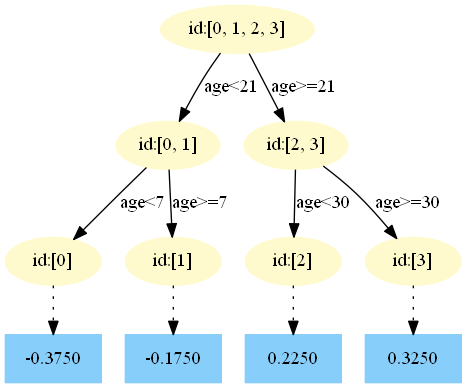
第二棵樹:
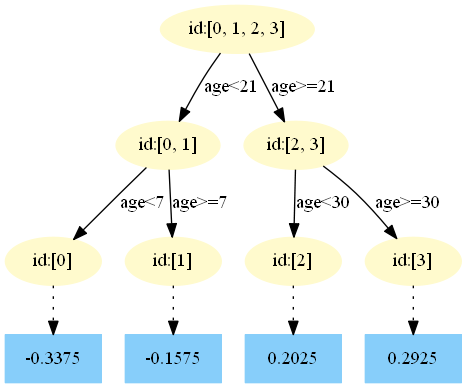
第三棵樹:
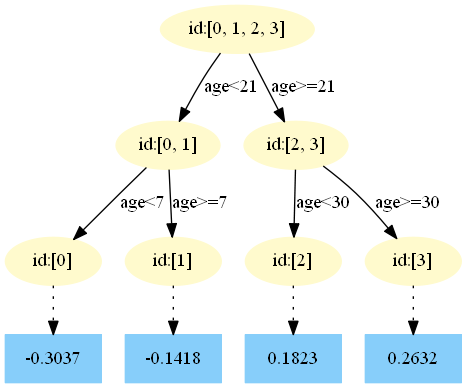
第四棵樹:
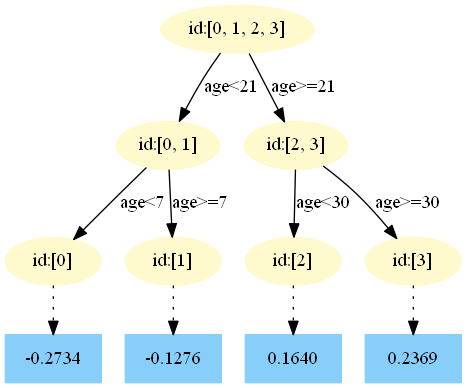
第五棵樹:
4.得到最后的強學習器:
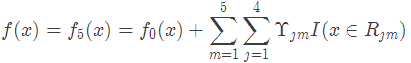
5.預測樣本5:

在 中,樣本4的年齡為25,大于劃分節點21歲,又小于30歲,所以被預測為0.2250。
中,樣本4的年齡為25,大于劃分節點21歲,又小于30歲,所以被預測為0.2250。
在 中,樣本4的…此處省略…所以被預測為0.2025
中,樣本4的…此處省略…所以被預測為0.2025
==為什么是0.2025?這是根據第二顆樹得到的,可以GitHub簡單運行一下代碼==
在 中,樣本4的…此處省略…所以被預測為0.1823
中,樣本4的…此處省略…所以被預測為0.1823
在 中,樣本4的…此處省略…所以被預測為0.1640
中,樣本4的…此處省略…所以被預測為0.1640
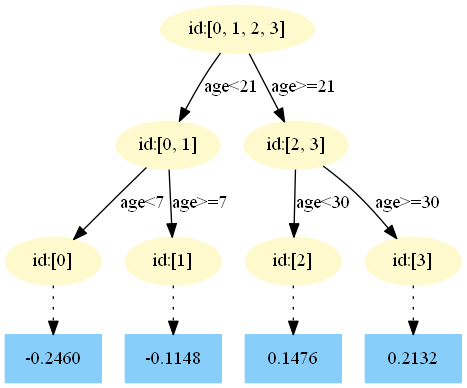
在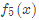 中,樣本4的…此處省略…所以被預測為0.1476
中,樣本4的…此處省略…所以被預測為0.1476
最終預測結果:
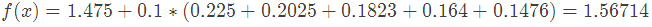
-
計算
+關注
關注
2文章
450瀏覽量
38833 -
GBDT
+關注
關注
0文章
13瀏覽量
3906
原文標題:GBDT算法原理以及實例理解
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GBDT算法原理和模型訓練
對于PID控制/算法的理解
基于GBDT個人信用評估方法
SparkMLlib GBDT算法工業大數據實戰
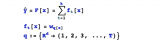
SparkMLlib GBDT算法工業大數據的實戰案例
邏輯回歸與GBDT模型各自的原理及優缺點

GBDT是如何用于分類的





 工商網監
工商網監
評論