 如何優化深度學習模型
如何優化深度學習模型
看過了各式各樣的教程之后,你現在已經了解了神經網絡的工作原理,并且也搭建了貓狗識別器。你嘗試做了了一個不錯的字符級RNN。你離建立終端只差一個pip install tensorflow命令了對嗎?大錯特錯。
深度學習的一個非常重要的步驟是找到正確的超參數,超參數是模型無法學習的。
在本文中,我將向你介紹一些最常見的(也是重要的)超參數,這些參數是你抵達Kaggle排行榜#1的必經之路。此外,我還將向你展示一些強大的算法,可以幫助你明智地選擇超參數。
深度學習中的超參數
超參數就像是模型的調節旋鈕。
如果您將AV接收機設置為立體聲,那么配備低音揚聲器的7.1級杜比全景聲(Dolby Atmos)家庭影院系統將對你毫無用處,盡管它的超低音揚聲器可以產生低于人耳可聽范圍的聲音。
同樣,如果你將超參數關閉,帶有萬億參數的inception_v3網絡甚至不會讓你在MNIST數據集上測試通過。
所以現在,讓我們然后在學會如何調“旋鈕”之前先看看這些“旋鈕”。
學習率
學習率可以說是最重要的超參數,粗略地說,它可以控制神經網絡“學習”的速度。
那么,為什么我們不把學習率設置得非常大,體驗飆車的樂趣呢?
事情不是那么簡單。請記住,在深度學習中,我們的目標是盡量最小化損失函數。如果學習率太高,我們的損失函數將開始在某點來回震蕩,不會收斂。
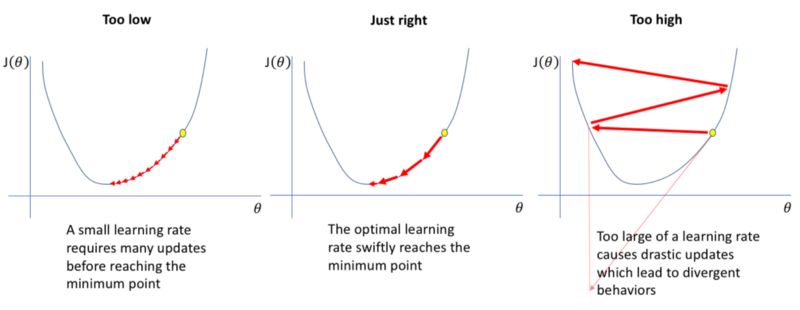
如果學習率太小,模型將花費太長時間來收斂,如上所述。
動量
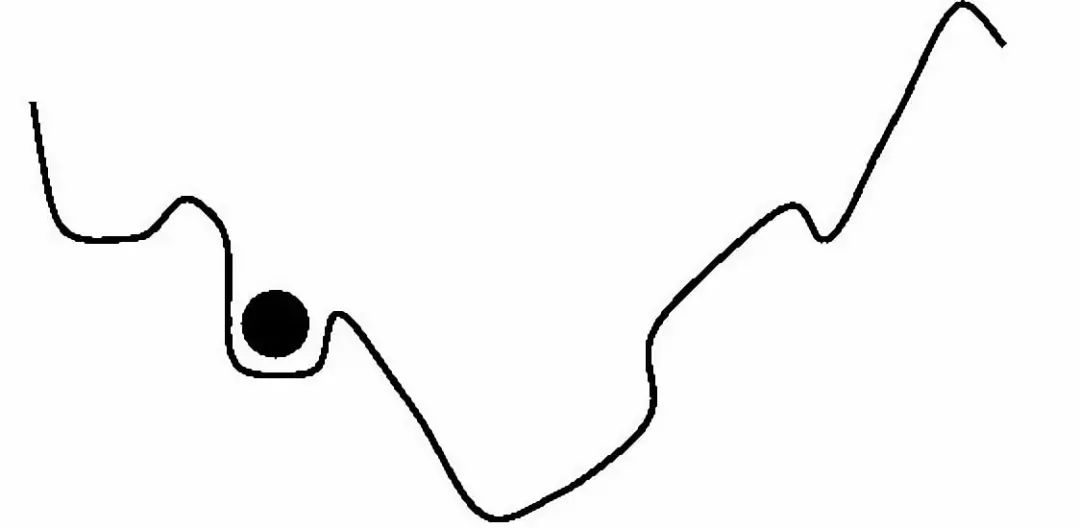
由于本文側重于超參數優化,我不打算解釋動量的概念。但簡而言之,動量常數可以被認為是在損失函數表面滾動的球的質量。
球越重,下落越快。但如果它太重,它可能會卡住或超過目標。
丟棄
如果你了解這個概念,我會直接帶你去看Amar Budhiraja關于丟棄(dropout)的文章。
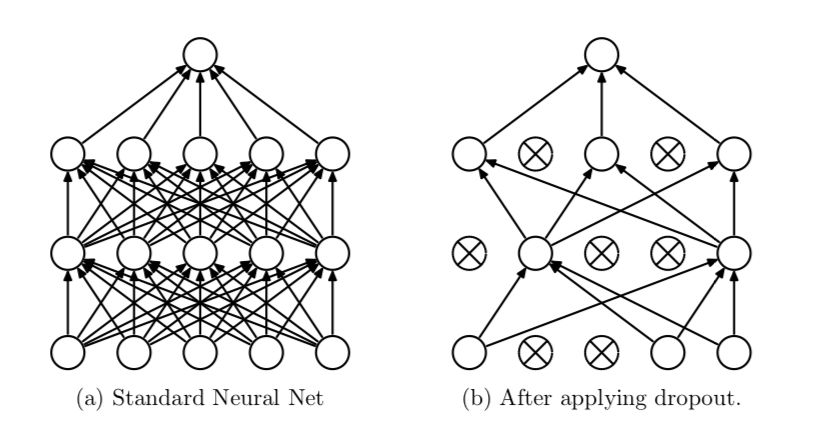
但我們做一個快速復習,dropout是Geoff Hinton提出的一種正則化技術,它將神經網絡中的激活函數隨機地設置為0,概率為p。這有助于防止神經網絡過擬合數據而不是學習它。
p是一個超參數。
架構——神經網絡的層數,每層神經元的個數等
另一個(最近的)想法是使神經網絡的架構本身成為一個超參數。
雖然我們通常不會讓機器弄清楚我們模型的架構(否則AI研究人員會丟失他們的工作),但是神經架構搜索(Neural Architecture Search)等一些新技術已經實現了這個想法并取得了不同程度的成功。
如果你聽說過AutoML,那么Google基本上就是這樣做的:將所有內容都設置為超參數,然后扔大量TPU在這個問題上讓它自行解決。
但是對于我們絕大多數只想在黑色星期五銷售之后用經濟型機器分類貓狗的人來說,現在是時候該弄清楚如何使這些深度學習模型真正起作用了。
超參數優化算法
網格搜索
這是獲得良好超參數的最簡單方法。它實際上就是暴力解決。
算法:從一組給定的超參數中嘗試一堆超參數,看看哪種方法效果最好。
優點:五年級學生都很容易實現,而且可以輕松并行化。
缺點:正如你可能猜到的那樣,它的計算成本非常高(因為所有暴力算法都是如此)。
我是否應該使用它:可能不會。網格搜索非常低效。即使你想保持簡單,你也最好使用隨機搜索。
隨機搜索
正如它的本意,隨機搜索。完全隨機化。
算法:在一些超參數空間上從均勻分布中嘗試一堆隨機超參數,看看哪種方法效果最好。
優點:可以輕松并行化。就像網格搜索一樣簡單,但性能稍好一點,如下圖所示:
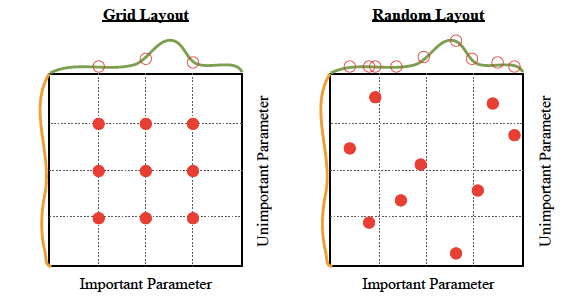
缺點:雖然它提供了比網格搜索更好的性能,但它仍然只是計算密集型。
我是否應該使用它:如果瑣碎的并行化和簡單性是最重要的,那就去吧。但是,如果你愿意花費時間和精力,那么通過使用貝葉斯優化,你的模型效果將大大提升。
貝葉斯優化
與我們迄今為止看到的其他方法不同,貝葉斯優化使用了算法的先前迭代的知識。使用網格搜索和隨機搜索,每個超參數猜測都是獨立的。但是,使用貝葉斯方法,每次我們選擇并嘗試不同的超參數時,表現都在一點點提升。
貝葉斯超參數調整背后的想法歷史悠久且細節豐富。所以為了避免太多坑,我會在這里給你一個要點。但如果你感興趣,一定要仔細閱讀高斯過程和貝葉斯優化。
請記住,我們使用這些超參數調整算法的原因是,單獨實際評估多個超參數選擇是不可行的。例如,假設我們想要手動找到一個好的學習率。這將涉及設置學習率,訓練模型,評估它,選擇不同的學習率,再次訓練你從頭開始模型,重新評估它,并繼續循環。
問題是,“訓練你的模型”可能需要幾天時間(取決于問題的復雜性)才能完成。因此,在會議提交截止日期之前,您只能嘗試一些學習率。而你知道什么,你甚至沒有開始設置動量。糟糕極了。
算法:貝葉斯方法試圖建立一個函數(更準確地說,是關于可能函數的概率分布),用于估計模型對于某個超參數選擇的好壞程度。通過使用這種近似函數(在文獻中稱為代理函數),您不必在設置、訓練、評估的循環上花費太多時間,因為你可以優化代理函數的超參數。
例如,假設我們想要最小化此函數(將其視為模型損失函數的代理):
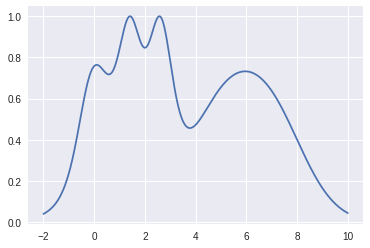
代理函數來自于高斯過程(注意:還有其他方法來模擬代理函數,但我將使用高斯過程)。就像我提到的那樣,我不會做任何數學上的重要推導,但是所有關于貝葉斯和高斯的討論歸結為:
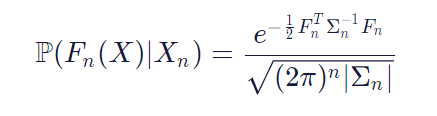
公式看上去很復雜。但是,讓我們試著理解它。
左側告訴你涉及概率分布(假設存在P)。在括號內看,我們可以看到它是P的概率分布,這是一個任意的函數。為什么?請記住,我們正在定義所有可能函數的概率分布,而不僅僅是特定函數。本質上,左側表示將超參數映射到模型的度量的真實函數(如驗證準確性,對數似然,測試錯誤率等)的概率為Fn(X),給定一些樣本數據Xn等于右側的式子。
現在我們有了優化函數,就開始進行優化吧。
以下是在開始優化過程之前高斯過程的樣子?
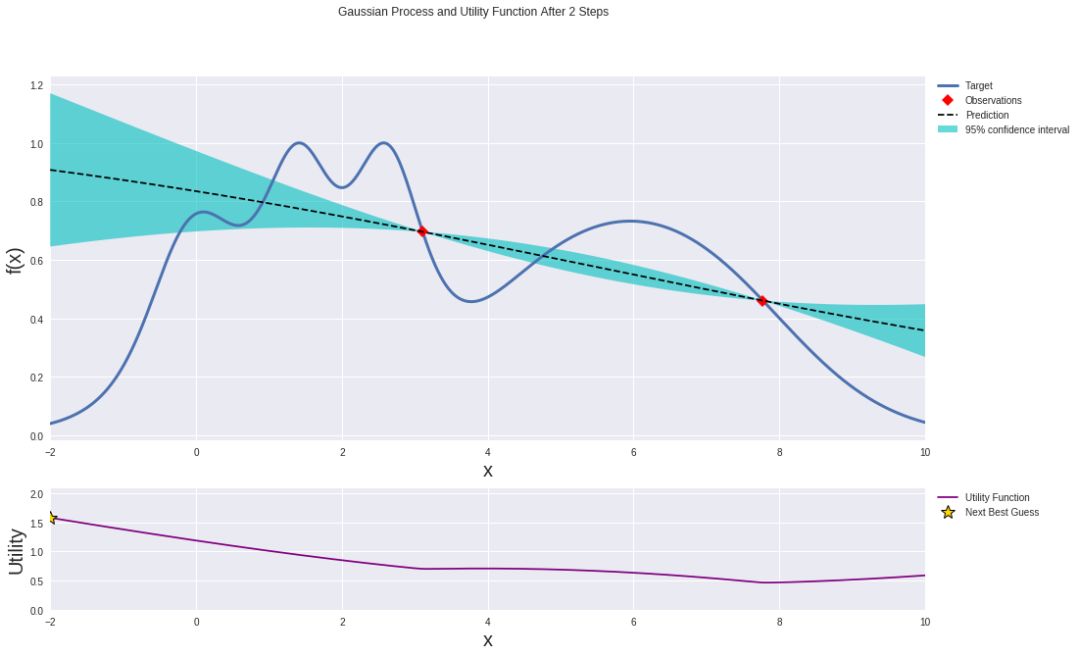
在利用兩個數據點迭代之前的高斯過程。
使用你最喜歡的優化器(大佬們一般喜歡最大化預期改善),但其實只需跟著信號(或梯度)引導,你還沒有反應過來的時候就已經得到局部最小值。
經過幾次迭代后,高斯過程在近似目標函數方面變得更好:
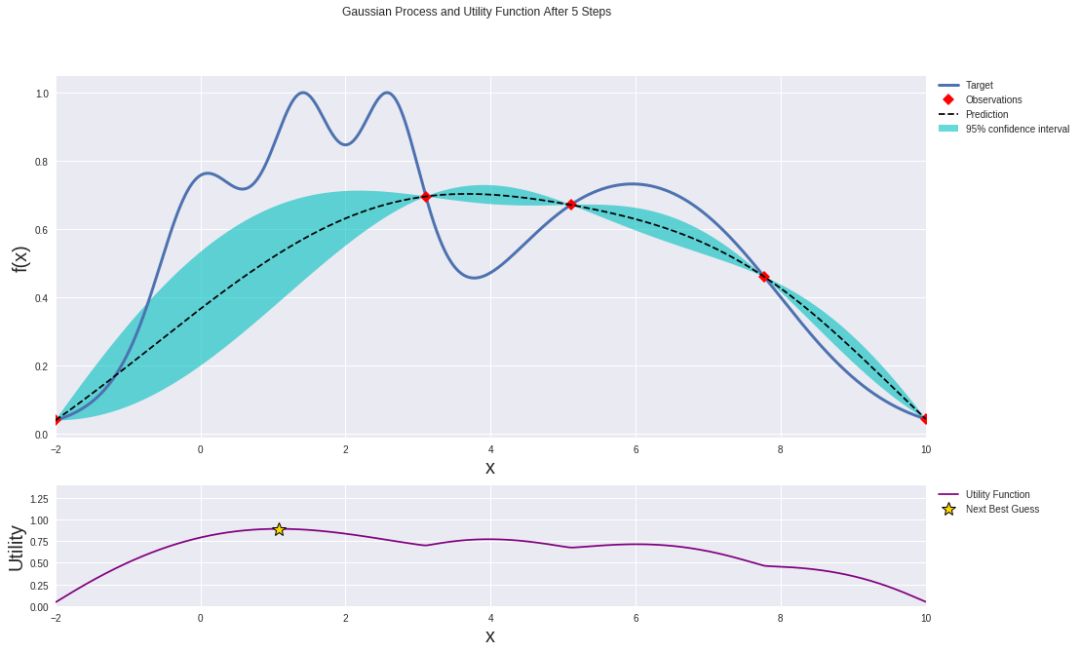
在利用兩個數據點迭代三次之后的高斯過程。
無論你使用哪種方法,你現在都找到了代理函數最小化時的參數。那些最小化代理函數的參數居然是最優超參數(的估計)哦!好極了。
最終結果應如下所示:
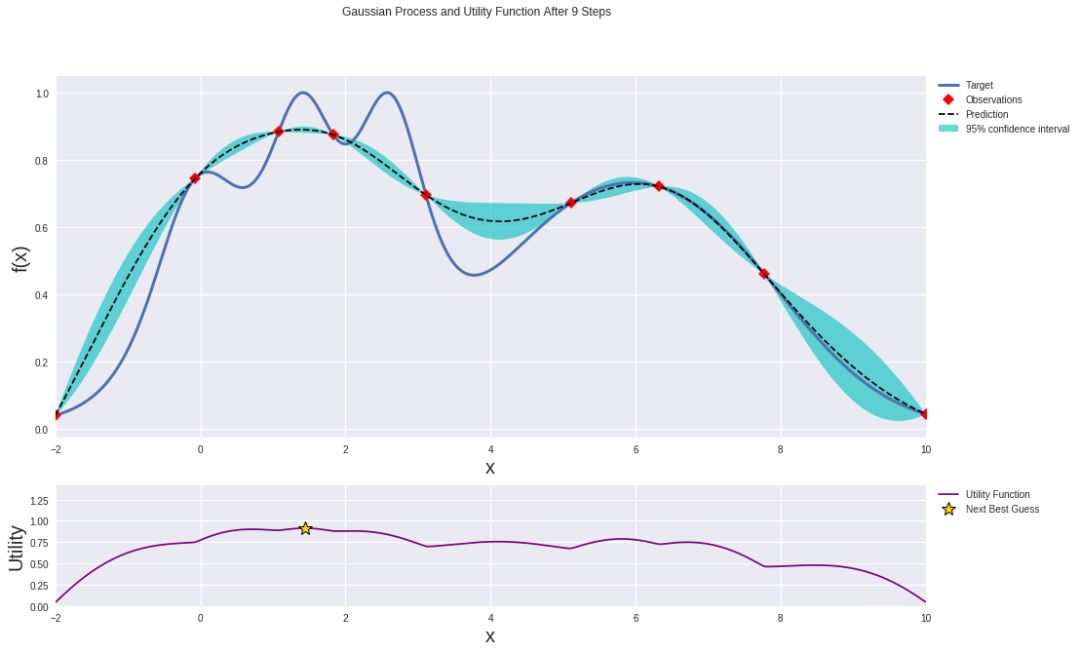
在利用兩個數據點迭代七次之后的高斯過程。
使用這些“最佳”超參數你的神經網絡上進行訓練,你應該會看到一些改進。但是,你也可以使用這些新信息重新一次又一次地重做整個貝葉斯優化過程。你可以想跑多少次這一貝葉斯循環就跑多少次,但還是要謹慎行事。你實際上在“跑錢”。你不要忘了AWS又不是免費的。
優點:貝葉斯優化比網格搜索和隨機搜索提供更好的結果。
缺點:并行化并不容易。
我應該使用它嗎:在大多數情況下,是的!唯一的例外是如果:
你是一個深度學習專家,你不需要一個微不足道的近似算法幫忙。
你擁有龐大的計算資源,并可以大規模并行化網格搜索和隨機搜索。
如果你是一個頻率論者/反貝葉斯統計書呆子。
尋找良好學習率的可選方法
我們到目前為止看到的所有方法有一個隱含主題:自動化機器學習工程師的活兒。這確實很有用很厲害——直到你的老板聽說了之后決定用4個RTX Titan卡取代你。呵呵。你本應該堅持用手動搜索的。
不過不要擔心啊,還是有些關于讓研究者少干點活但是多拿點錢的活躍研究呢。其中一個效果非常好的想法是學習率范圍測試,據我所知,這首先出現在Leslie Smith的論文中。
這篇論文實際上是關于一種隨時間調度(改變)學習率的方法。LR(Learning Rate,學習率)范圍測試只是個作者一不小心遺落在一旁的大寶貝。
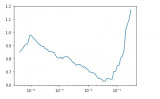
當你使用那種學習速率可以從最小值取到最大值的學習速率計劃時(例如循環學習速率或具有熱重啟動的隨機梯度下降),作者建議在每次迭代之后將學習速率從小數值線性增加到大數值(例如,1e-7到1e-1),評估每次迭代時的損失,并在對數刻度上繪制損失(或測試誤差,或準確度)與學習率的關系。你的圖像看起來應該是這樣的:
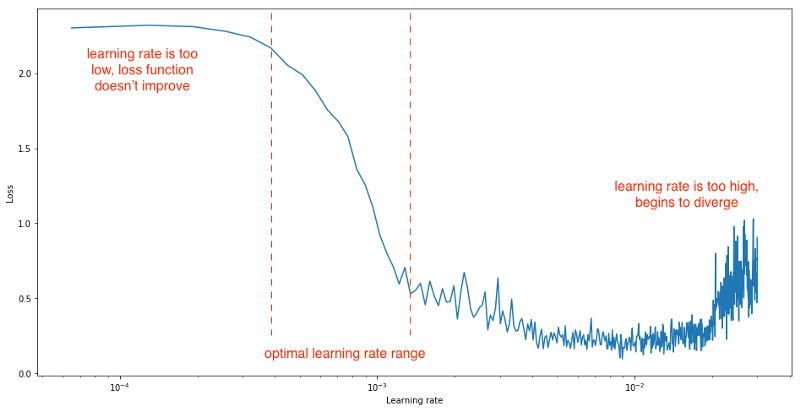
如圖所示,你可以設置學習率在最小和最大學習率之間變化,這可以通過在圖像上肉眼觀察最陡梯度區域來找到。
Colab Notebook上畫的LR范圍測試圖(CIFAR10上訓練的DenseNet):
ColabNotebook
https://colab.research.google.com/gist/iyaja/988df5818fd887cc7542074ea2bfb74e/fastai-imagefolder-playground.ipynb
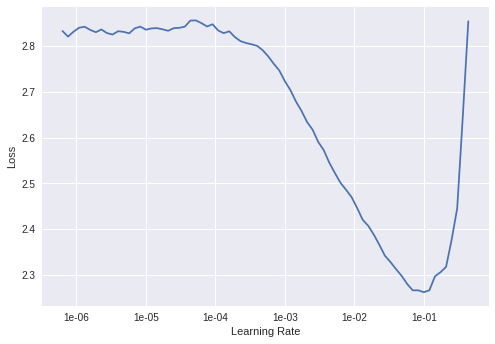
在CIFAR10數據集上訓練的DenseNet 201的學習率范圍測試
根據經驗,如果你沒有做任何花哨的學習率安排的話,那么只需將你的恒定學習率設置為低于繪圖上最小值的數量級即可。在這種情況下大約就是1e-2。
這種方法最酷地方在于,它很好用很省時省心省計算力,它幾乎不需要任何額外的計算。
其他算法——即網格搜索、隨機搜索和貝葉斯優化——要求你運行與訓練良好神經網絡目標相關的整個項目。LR范圍測試只是執行簡單定期的訓練循環,并保持跟蹤一些變量。
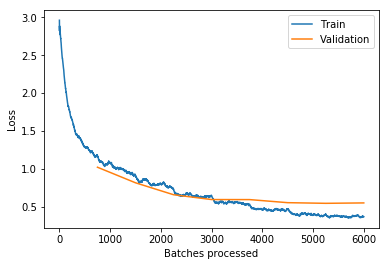
最佳學習率擬合的模型的損失與batch大小圖
LR范圍測試已經由fast.ai團隊實施過了。你一定要看看他們實現LR范圍測試的庫(他們稱之為學習速率查找器)以及許多其他算法。
對于更復雜的深度學習實踐者
當然,所有這些算法——盡管它們都很好——并不總是在實踐中起作用。在訓練神經網絡時還有許多其他因素需要考慮,例如你將如何預處理數據,定義模型,你還需要真的搞定足夠跑這一整個流程的計算力。
Nanonets提供易于使用的API來訓練和部署自定義深度學習模型。它能負責所有的繁重工作,包括數據擴充,轉移學習,以及超參數優化!
Nanonets在其龐大的GPU集群上使用貝葉斯搜索來找到正確的超參數集,你壓根不用擔心得在最新的顯卡上再大花一筆錢啦。
一旦找到最佳模型,Nanonets就會把它放在云端,以便你使用其Web界面測試模型,或使用兩行代碼將其集成到你的程序中。
跟不完美模型說拜拜吧。
結論
在本文中,我們討論了超參數和一些優化它們的方法。但這一切意味著什么?
隨著人們越來越努力地使AI技術民主化,自動超參數調整可能是朝著正確方向邁出的一步。它允許像你我這樣的普通人在沒有數學博士學位的情況下構建厲害的深度學習應用程序。
雖然你可能會認為,讓模型重度依賴于計算立會導致只有那些能夠承受如此計算力的人群獲得最好的模型,但像AWS和Nanonets這樣的云服務有助于實現我們普通民眾對強大機器計算力的訪問、使深度學習更容易普及。
但更重要的是,我們真正在這里做什么——用數學來解決更多的數學。這很有意思,不僅因為聽起來很酷炫啦,還因為它真的很容易被錯誤解釋。
從打孔卡和excel表時代,到我們”優化優化函數的函數以優化函數“的時代,我們已經走過了漫長的道路。但是,我們依然無法建造能夠自己“思考”的機器。
這一點都不令人沮喪,因為如果人類用這么少的東西就能夠做到這個高度的話,當我們的愿景變成我們實際可以看到的東西時,想象一下未來會怎樣吧!
我們坐在一張襯墊網椅上,盯著一個空白的終端屏幕——每個按鍵都能給我們一個可以擦干凈磁盤的sudo指令。
我們會整天坐在那里一動不動——因為下一個重大突破和我們可能只差一條pip install哦。
-
參數
+關注
關注
11文章
1846瀏覽量
32331 -
ai技術
+關注
關注
1文章
1285瀏覽量
24376
原文標題:如何優化深度學習模型
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
labview調用yolo 目標檢測速度太慢?yolov4:速度和精度的完美結合,性能和精度碾壓yolov3
晶心科技和Deeplite攜手合作高度優化深度學習模型解決方案

深度神經網絡模型的壓縮和優化綜述

什么是深度學習中優化算法
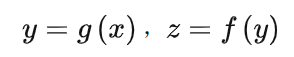
如何優化深度學習模型?





 工商網監
工商網監
評論