 利用2.5GPU年的算力在7個數據集上訓練了12000多個模型
利用2.5GPU年的算力在7個數據集上訓練了12000多個模型
基于無監督的方式理解高維數據并將信息濃縮為有用的表示一直是深度學習領域研究的關鍵問題。其中一種方法是利用非耦合表示(disentangled representations)模型來捕捉場景中獨立變化的特征。如果能夠實現對于各種獨立特征的描述,機器學習系統就可以用于真實環境中的導航,機器人或無人車利用這種方法可以將環境解構成一系列元素,并利用通用的知識去理解先前未見過的場景。
雖然非監督解耦方法已被廣泛應用于好奇驅動的探索、抽象推理、視覺概念學習和域適應的強化學習中,但最近進展卻無法讓我們清晰了解不同方法的性能和方法的局限。為了深入探索這一問題,谷歌的研究人員在ICML2019上發表了一篇大規模深入研究非監督非耦合表示的論文”Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations”,對近年來絕大多數的非監督解耦表示方法進行探索、利用2.5GPU年的算力在7個數據集上訓練了12000多個模型。基于大規模的實驗結果,研究人員對這一領域的一些假設產生了質疑,并為解耦學習的未來發展方向給出了建議。與此同時,研究人員還同時發布了研究中所使用的代碼和上萬個預訓練模型,并封裝了disentanglement_lib供研究者進行實驗復現和更深入的探索。
理解非耦合表示
為了更好地理解非耦合表示的本質,讓我一起來看看下面動圖中每個獨立變化的元素。下面的每一張圖代表了一個可以被編碼到矢量表示中的因子,它可以獨立控制圖像中每個語義元素的屬性。例如第一個可以控制地板的顏色,第二個則控制墻的顏色,最后一個則控制圖片的視角。
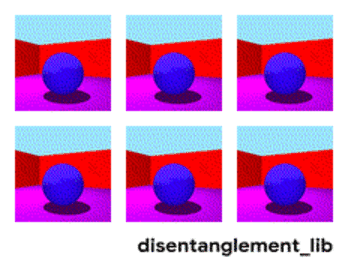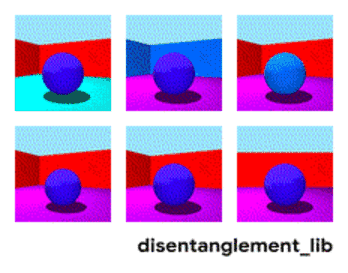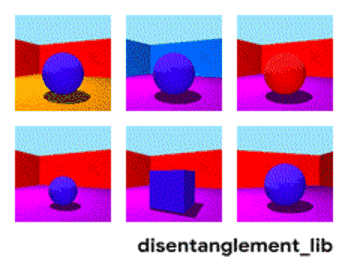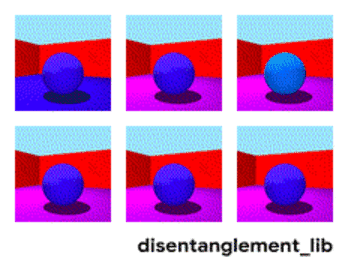
解耦表示的目標在于建立起一個能夠獨立捕捉這些特征的模型,并將這些特征編碼到一個表示矢量中。下面的10個小圖展示了基于FactorVAE方法學習十維表示矢量的模型,圖中展示 了每一維對于圖像對應信息的捕捉。從各個圖中可以看出模型成功地解耦了地板、墻面的顏色,但是左下角的兩個圖片可以看到物體的顏色和大小的表示卻依然相關沒有解耦。
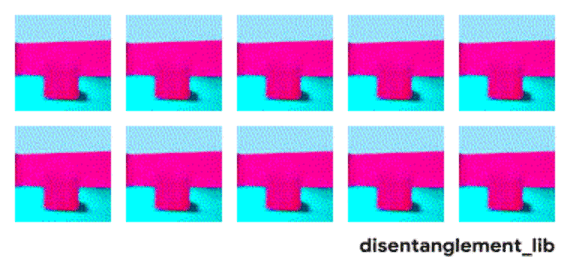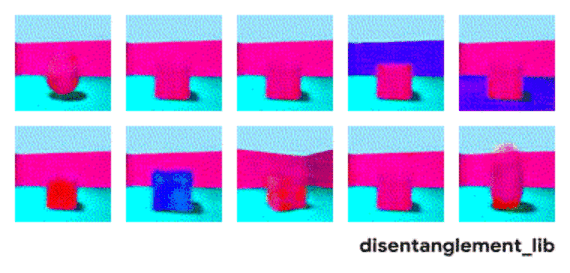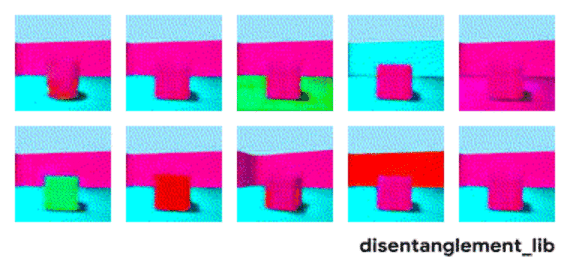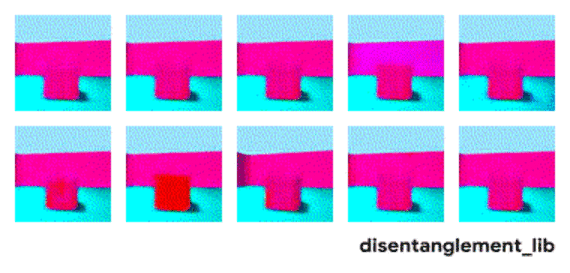
大規模研究的發現
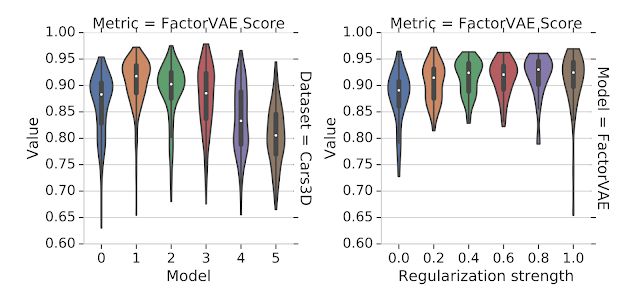
在直觀地理解了解耦表示之后,讓我們來看看科學家在研究中發現了什么。這一領域基于變分自編碼器提出了各種各樣的非監督方法來學習非耦合表示,同時給出了許多不同的性能度量方法,但卻缺乏一個大規模的性能測評和對比研究。為此研究人員構建了一個大規模、公平性、可復現的實驗基準,并系統的測試了六種不同的模型(BetaVAE, AnnealedVAE, FactorVAE, DIP-VAE I/II and Beta-TCVAE)和解耦性能度量方法(BetaVAE score, FactorVAE score, MIG, SAP, Modularity and DCI Disentanglement),在7個數據集上進行了12800個模型的訓練后,研究人員們有了顛覆過去的發現:首先,是非監督學習的方式。研究人員在大量的實驗后發現沒有可靠的證據表明模型可以通過無監督的方式學習到有效的解耦表示,隨機種子和超參數對于結構的影響甚至超過了模型的選擇。換句話說,即使你訓練的大量模型中有部分是解耦的,但這些解耦表示在不基于基準標簽的情況下是無從確認和識別的。此外好的超參數在不同的數據集上并不一致,這意味著沒有歸納偏置(inductive biases)是無法實現非監督解耦學習的(需要把對數據集的假設考慮進模型中)。對于實驗中評測的模型和數據集,研究人員表示無法驗證解耦對于downstream tasks任務有利的假設(這一假設認為基于解耦表示可以利用更少的標簽來進行學習)。下圖展示了研究中的一些發現,可以看到隨機種子在運行中的影響超過了模型的選擇(左)和正則化(右)的強度(更強的正則化并沒有帶來更多的解耦性能)。這意味著很差超參數作用下的好模型也許比很好超參數作用下的壞模型要好得多。
未來研究方向
基于這些全新的發現和研究結果,研究人員為解耦表示領域提出了四個可能的方向:1.在沒有歸納偏置的條件下給出非監督解耦表示學習的理論結果是不可能的,未來的研究應該更多地集中于歸納偏置的研究以及隱式和顯示監督在學習中所扮演的角色;2.為橫跨多數據集的非監督模型尋找一個有效的歸納偏置將會成為關鍵的開放問題;3.應該強調解耦學習在各個特定領域所帶來的實際應用價值,潛在的應用方向包括機器人、抽象推理和公平性等;4.在各種多樣性數據集上的實驗應該保證可重復性。
代碼和工具包
為了讓其他研究人員更好的復現結構,論文同時還發布了 disentanglement_lib工具包,其中包含了實驗所需的模型、度量、訓練、預測以及可視化代碼工具。可以在命令行中用不到四行代碼就能復現是論文中所提到的模型,也可以方便地改造來驗證新的假設。最后 disentanglement_lib庫易于拓展和集成,易于創建新的模型,并用公平的可復現的比較進行檢驗。由于復現所有的模型訓練需要2.5GPU年的算力,所以研究人員同時開放了論文中提到的一萬多個預訓練模型可以配合前述工具使用。如果想要使用這個工具可以在這里找到源碼:
https://github.com/google-research/disentanglement_lib
其中包含了以下內容:模型:BetaVAE, FactorVAE, BetaTCVAE, DIP-VAE度量:BetaVAE score, FactorVAE score, Mutual Information Gap, SAP score, DCI, MCE數據集:dSprites, Color/Noisy/Scream-dSprites, SmallNORB, Cars3D, and Shapes3D預訓練模型:10800 pretrained disentanglement models依賴包:TensorFlow, Scipy, Numpy, Scikit-Learn, TFHub and Gin
git clone https://github.com/google-research/disentanglement_lib.git #下載gitcd disentanglement_lib #轉到源碼目錄pip install .[tf_gpu] #安裝依賴文件dlib_tests #驗證安裝
隨后下載對應的數據文件:
dlib_download_data#在.bashrc寫入路徑export DISENTANGLEMENT_LIB_DATA=
隨后就可以愉快地復現實驗了,其中?是0-12599間的模型序號:dlib_reproduce --model_num=進行評測:dlib_aggregate_results
相信這篇文章的研究結果和代碼工具將為接下來的研究提供更為明確的方向和便捷的途徑,促進非耦合表示學習領域的發展。
-
谷歌
+關注
關注
27文章
6176瀏覽量
105677 -
gpu
+關注
關注
28文章
4760瀏覽量
129131 -
數據集
+關注
關注
4文章
1208瀏覽量
24748
原文標題:耗時2.5GPU年訓練12800個模型,谷歌研究人員揭示非耦合表示的奧秘
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
在Ubuntu上使用Nvidia GPU訓練模型
索尼發布新的方法,在ImageNet數據集上224秒內成功訓練了ResNet-50
ICML 2019最佳論文新鮮出爐!
利用ImageNet訓練了一個能降噪、超分和去雨的圖像預訓練模型
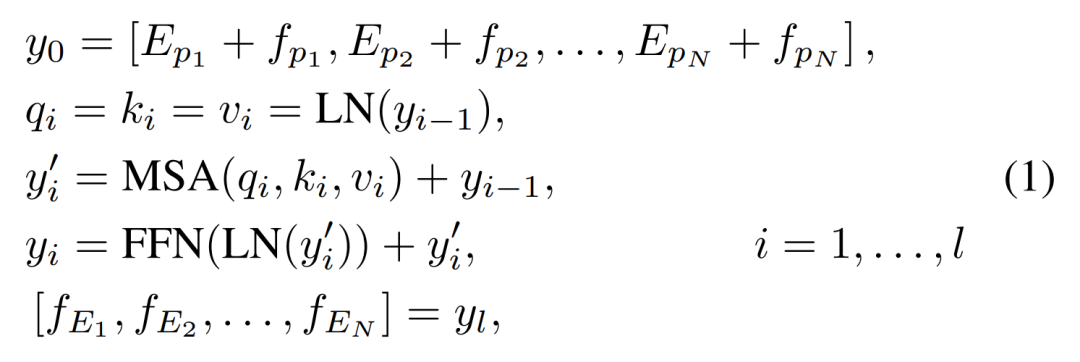

【一文看懂】大白話解釋“GPU與GPU算力”






 工商網監
工商網監
評論