 一種基于模型的元強化學習算法用于提高快速適應性
一種基于模型的元強化學習算法用于提高快速適應性
人類具有適應環境變化的強大能力:我們可以迅速地學會住著拐杖走路、也可以在撿起位置物品時迅速地調整自己的力量輸出,甚至小朋友在不同地面上行走都能輕松自如地切換自己的步態和行走模式。這樣的適應能力對于在復雜多變的環境中生存活動十分重要。但這些看似是人類與生俱來的能力,機器人拼盡全力也未必能實現。
絕大部分的機器人都被部署在固定環境中重復執行固定的動作,但面對未知的全新情況機器人就會失效,甚至是運行環境的些許變化,比如一陣風來了、負載質量改變或意外的擾動都會給機器人帶來難以處理的困難。為了縮小機器人與人類對于環境適應能力間的差距,研究人員認為機器人預測狀態與實際觀測狀態間如果存在較大的誤差,那么這個誤差應該要引導機器人更新自身模型,以更好地描述當前狀態,也就是快速的環境適應性。
有一個形象的例子來解釋這種適應性,很多小伙伴在開車時,特別在北方的冬天都遇到過車輛側滑的情況,駕駛員發現預測車的行駛狀況與實際不符,本來該直走的車怎么橫著開了!這時駕駛員就根據這個誤差迅速調整自身操作來糾正車輛行駛狀態。這個過程就是我們期望機器人能夠學會的快速適應能力。
對于一個要面對錯綜復雜真實世界的機器人來說,從先前經驗中迅速、靈活地調整自身狀態和行為適應環境是十分重要的。為了實現這個目標,研究人員開發了一種基于模型的元強化學習算法用于提高快速適應性。先前的工作主要基于試錯的方法和無模型的元強化學習方法來處理這一問題,而在本文的研究人員將這一問題拓展到了極端情況,機器人在面對新情況時需要實時在線、在幾個時間周期內迅速完成適應,所以實現這一目標的難度可想而知。基于模型的元學習方法不像先前方法基于目標的獎勵來優化,而是利用每一時刻預測與觀測間的誤差作為數據輸入來處理模型。這種基于模型的方法使機器人在使用少量數據的情況下實現對環境的實時更新。

這一方法利用了最近的觀測數據來對模型進行更新,但真正的挑戰在于如何基于少量的數據對復雜、非線性、大容量的模型(例如神經網絡)進行自適應控制。簡單的隨機梯度下降方法對于需要快速適應的方法效率很低,神經網絡需要大量的數據來訓練模型才能實現有效的更新。所以為了實現快速的自適應調整,研究人員提出了新的方法。首先利用自適應目標對進行(元)訓練,而后在使用時利用少量的數據進行精細訓練以實現快速適應性調整。在不同情況下訓練出的元模型將學會如何去適應,機器人就可以利用元模型在每一個時間步長上進行適應性更新以處理當前所面對的環境,以實現快速在線適應的目標。
元訓練
機器人的運動離不開對狀態的估計。在任意時刻下我們都可以對當前狀態St,施加一定的行為at,從而得到下一時刻的狀態St+1,這一狀態的變化主要由狀態轉移函數決定。在真實世界中,我們無法精確建立狀態轉移動力學過程,但可以利用學習到的動力學模型進行近似,這樣就可以基于觀測數據進行預測。上圖中的規劃器就可以利用這一估計的動力學模型來進行行為調整。在訓練時模型會選取最近的(M+K)連續的數據點序列,首先利用M個數據來更新模型的權重,隨后利用身下的K個點來優化跟新后的模型對于新狀態的預測能力。模型的損失函數可以表達為在先前K個點上進行適應后,在未來K個點上的預測誤差。這意味著訓練模型可以利用鄰近的數據點迅速調整權重使自身可以進行較好的動力學預測。

為了測試這種方法對于環境突變的適應能力,研究人員首先在仿真機器人系統中進行了實驗。研究人員在相同擾動下的環境中多所有主體進行了元訓練,而在主體從未見過的環境及變化中進行測試。下面的獵豹模型在隨機浮動的擾動上進行訓練,隨后在水上浮動的情況下進行了測試,機器人展現了快速適應環境變化的能力。右圖顯示了在斷腿的情況下機器人的適應性:


機器人面對環境變化后的適應能力,圖中展示了基于模型的方法和基于在線自適應的方法
對于多足機器人來說,在不同腿配置的情況下進行了訓練,而在不同腿部損傷情況下進行了測試。這種基于模型的元強化學習方法使得機器人具有快速適應能力,更多的比較測試詳見文末論文。
硬件實驗
為了更好地驗證算法在真實世界中的有效性,研究人員使用了具有高度隨機性和動力學特性微型6足機器人。
快速制造技術和多種定制化的設計,使得每一個機器人的動力學特性都獨一無二。它的零部件性能會隨著使用逐漸退化,同時也能在不同地面上快速移動。這使機器人控制算法面臨著會隨時變化的環境狀況,十分適合用于驗證算法。研究人員首先在不同的地面狀況下對機器人進行元訓練,隨后測試了機器在新情況下的在線適應能力。在斷腿、新地表、斜坡路況、負載變化、錯誤標定擾動等情況下都表現良好。可以看到不同情況下最右邊的在線適應方法更為穩定,適應不同情況的能力更強。腿斷了也能盡力走直線了:
加上負載也不會走的歪歪扭扭:
位姿錯誤標定也能及時更新糾正:
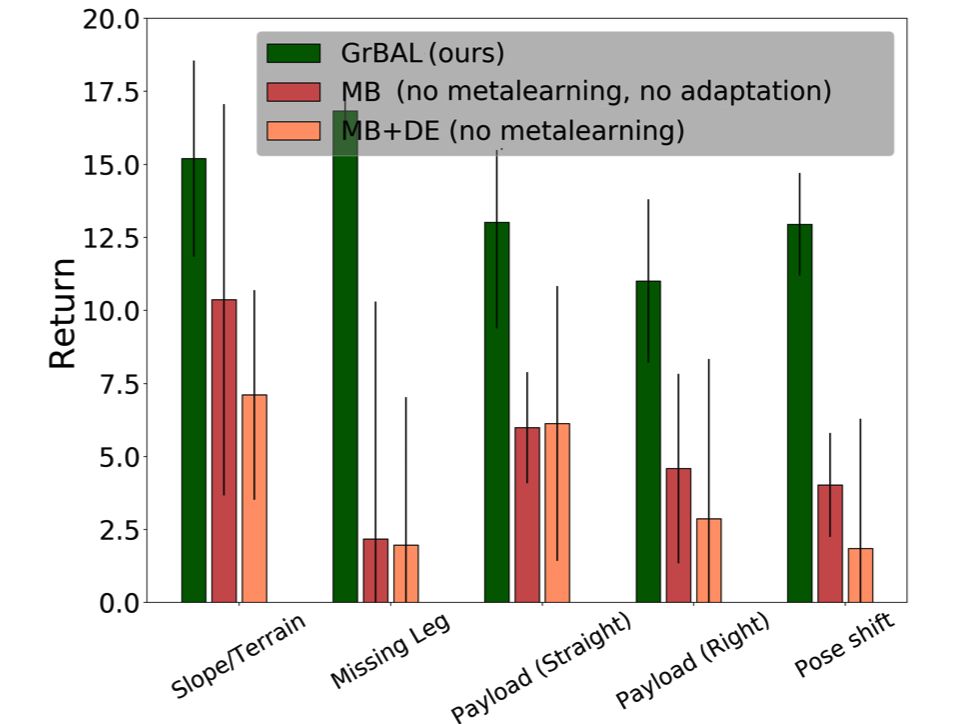
在和標準基于模型的方法(MB)、動力學評測的方法(MB+DE)比較中都顯示了這種方法的優勢。在各個指標上都取得了遠超傳統方法的結果。
在未來研究人員計劃對模型進行改進,使它的能力隨著時間逐漸增長而不是每次都需要從預訓練模型進行精調。并能夠記住在學習過程中學到的技能,將在線適應的學習到的新能力作為未來遇到新情況時的先驗技能提高模型表現。
-
機器人
+關注
關注
211文章
28418瀏覽量
207097 -
算法
+關注
關注
23文章
4612瀏覽量
92894 -
強化學習
+關注
關注
4文章
266瀏覽量
11254
原文標題:伯克利提出高效在線適應算法,讓機器人擁有快速適應環境變化的新能力
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于MPEG心理聲學模型II的自適應音頻水印算法
深度強化學習實戰
一種適用于室內復雜環境的高精度、環境自適應性強的定位算法
一種新的具適應性的程序結構
深度強化學習到底是什么?它的工作原理是怎么樣的
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述






 工商網監
工商網監
評論