 圖像分類的5種技術,總結并歸納算法、實現方式,并進行實驗驗證
圖像分類的5種技術,總結并歸納算法、實現方式,并進行實驗驗證
本文為你介紹圖像分類的5種技術,總結并歸納算法、實現方式,并進行實驗驗證。
圖像分類問題就是從固定的一組分類中,給輸入圖像分配標簽的任務。這是計算機視覺的核心問題之一,盡管它看似簡單,卻在實際生活中有著各種各樣的應用。
傳統方式:功能描述和檢測。
也許這種方法對于一些樣本任務來說是比較好用的,但實際情況卻要復雜得多。
因此,我們將使用機器學習來為每個類別提供許多示例,然后開發學習算法來查看這些示例,并了解每個類的視覺外觀,而不是試圖直接在代碼中指定每一個大家感興趣的類別是什么樣的。
然而,圖像分類問題就是一個非常復雜的工作,它總是借用諸如卷積神經網絡(CNN)這樣的深度學習模型來完成。但我們也知道,通常我們在課堂中學習到的,諸如KNN(鄰近算法)和SVM(支持向量機)這樣的許多算法,在數據挖掘問題上做得非常好,但似乎它們有時也不是圖像分類問題的最佳選擇。
因此,我們想要比較一下我們在課堂中學到的算法與CNN和遷移學習算法的性能。
目標
我們的目標是:
將KNN、SVM和BP神經網絡,與通常用于工業中圖像分類問題的算法進行比較,例如CNN和遷移學習。
獲得深度學習的經驗。
通過Google的TensorFlow來探索機器學習框架。
算法和工具
我們在這個項目中使用的5種方法分別是KNN、SVM、BP神經網絡、CNN,以及遷移學習。
整個項目主要分為3種方法。
第一種方法:使用KNN、SVM和BP神經網絡,這是我們在課堂上學到的算法,功能強大而且易于實施。我們主要使用sklearn來實現這些算法。
第二種方法:雖然傳統的多層感知器(MLP)模型成功地應用于圖像識別,但由于節點之間的完全連通性受到維度災難的影響,因此不能很好地擴展到更高分辨率的圖像。所以在這一部分我們使用Google的TensorFlow深度學習框架來構建一個CNN。
第三種方法:重新訓練預先訓練的深層神經網絡的最后一層(稱為Inception V3),同樣也是由TensorFlow來實現。Inception V3是為ImageNet大型視覺識別挑戰而進行的訓練,數據從2012年開始采集。這是計算機視覺中的標準任務,其中模型嘗試將整個圖像分為1000個類別,如“斑馬”、“斑點狗”和“洗碗機”。為了重新訓練這個預先訓練網絡,我們需要確保我們自己的數據集尚未被預先訓練。
如何實現
第一種方法:
預處理數據集,并用sklearn來運行KNN、SVM和BP神經網絡。
首先,我們使用openCV包定義了兩種不同的預處理函數:第一個稱為圖像特征向量,調整圖像大小,然后將圖像平坦化為行像素列表。第二個稱為提取顏色直方圖,使用cv2.normalize從HSV顏色間距中提取3D顏色直方圖,然后平坦化結果。
然后,我們構造需要解析的幾個參數,因為我們要測試這個部分的準確性,不僅是針對整個數據集的,還要測試具有不同數量標簽的子數據集,我們將數據集構造為解析到我們程序中的參數。與此同時,我們還構造了用于k-NN方法的相鄰數作為解析參數。
做好這些之后,我們開始提取數據集中的每個圖像特征并將其放入數組中。我們使用cv2.imread來讀取每個圖像,通過從圖像名稱中提取字符串來拆分標簽。在我們的數據集中,我們使用相同的格式設置名稱:“類標簽”.“圖像號”.jpg,因此我們可以輕松地提取每個圖像的類標簽。然后我們使用之前定義的2個函數來提取2種特征,并附加到數組rawImages和特征中,而我們之前提取的標簽則附加到數組標簽。
下一步是使用從sklearn包導入的函數train_test_split拆分數據集。具有后綴RI、RL的集合是rawImages和標簽對的拆分結果,另一個是特征和標簽對的拆分結果。我們使用數據集的85%作為訓練集,15%作為測試集。
最后,我們運用KNN、SVM和BP神經網絡函數來評估數據。對于KNN,我們使用KNeighborsClassifier;對于SVM,我們使用SVC;對于BP神經網絡,我們使用MLPClassifier。
第二種方法:
使用TensorFlow構建CNN。TensorFlow的目的是讓你構建一個計算圖(使用任何類似Python的語言),然后用C ++來執行圖形操作,這比直接用Python來執行相同的計算要高效得多。
TensorFlow還可以自動計算優化圖形變量所需的梯度,以便使模型更好地運行。這是因為圖形是簡單數學表達式的組合,因此可以使用導數的鏈式規則來計算整個圖形的梯度。
TensorFlow圖由以下部分組成:
用于將數據輸入圖表的占位符變量。
要進行優化的變量,以便使卷積網絡更好地得以運行。
卷積網絡的數學公式。
可用于指導變量優化的成本衡量標準。
一種更新變量的優化方法。
CNN架構由不同層的堆疊形成,其通過可微函數將輸入量轉換成輸出量(例如類別分數)。
所以在我們的實現操作中,第一層是保存圖像,然后我們構建了3個具有2×2最大池和修正線性單元(ReLU)的卷積層。
輸入是一個具有以下尺寸的四維張量:
圖像編號。
每個圖像的Y軸。
每個圖像的X軸。
每個圖像的通道。
輸出是另一個四維張量,具有以下尺寸:
圖像號,與輸入相同。
每個圖像的Y軸。如果使用的是2×2池,則輸入圖像的高度和寬度除以2。
每個圖像的X軸。同上。
由卷積濾波器產生的通道。
然后我們在網絡末端構建了2個完全連接的層。輸入是形狀為[num_images,num_inputs]的2維張量。輸出是形狀為[num_images,num_outputs]的2維張量。
然而,為了連接卷積層和完全連接層,我們需要一個平坦層,將4維張量減小到2維,從而可以用作完全連接層的輸入。
CNN的最后端始終是一個softmax層,它將來自全連接層的輸出歸一化,使得每個元素被限制在0和1之間,而所有元素總和為1。
為了優化訓練結果,我們需要一個成本衡量標準,并盡量減少每次迭代。我們在這里使用的成本函數是交叉熵(從tf.nn.oftmax_cross_entropy_with_logits()調用),并對所有圖像分類采用交叉熵的平均值。優化方法是tf.train.AdamOptimizer(),它是Gradient Descent的高級形式。這是一個調整的參數學習率。
第三種方法:
Retrain Inception V3物體識別模型有數百萬個參數,可能需要幾周才能完全訓練。遷移學習是一種技術,可以通過為一組類別(如ImageNet)采用訓練有素的模型來快速完成此項工作,并從新類別的現有權重中進行訓練。雖然它不如全訓練運行得那么好,但對于許多應用來說,這是非常有效的,并且可以在筆記本電腦上運行,只要運行三十分鐘即可,無需GPU。對于這部分的實現,我們可以按照下邊的說明進行操作:
https://www.tensorflow.org/tutorials/image_retraining
首先,我們需要獲得預先訓練的模型,刪除舊的頂層,并在我們擁有的數據集上訓練一個新的模型。在一個沒有貓品種的原始ImageNet類中,要對完整的網絡進行訓練。遷移學習的神奇之處在于,經過訓練以區分某些對象的較低層可以重用于許多識別任務,而無需任何更改。然后我們分析磁盤上的所有圖像,并計算其中每個圖像的瓶頸值(bottleneck values)。點擊這里查看bottleneck的詳細信息(https://www.tensorflow.org/tutorials/image_retraining)。每個圖像在訓練過程中被重復使用多次,所以計算每個瓶頸值都需要花費大量的時間,因此可以加快緩存這些瓶頸值,從而不必重復計算。
該腳本將運行4000個訓練步驟。每個步驟從訓練集中隨機選擇十個圖像,從緩存中發現其瓶頸,并將它們饋送到最后一層以獲得預測。然后將這些預測與實際標簽進行比較,從而通過反向傳播過程更新最終層的權重。
開始實驗
數據集
牛津IIIT寵物數據集(http://www.robots.ox.ac.uk/~vgg/data/pets/)
有25個品種的狗和12個品種的貓。每個品種有200張圖像。
我們在項目中只使用了10個貓品種。
我們在這里使用的類型是['Sphynx'(加拿大無毛貓,也稱斯芬克斯貓),'Siamese'(暹羅貓),'Ragdoll'(布偶貓),'Persian'(波斯貓),'Maine-Coon'(緬因貓),'British-shorthair'(英國短毛貓),'Bombay'(孟買貓),'Birman'(緬甸貓),'Bengal'(孟加拉貓)]。
所以我們在數據集中共有2000張圖像,彼此的尺寸各不同。但是我可以將它們調整為固定大小,如64 x 64或128 x 128。
預處理
在這個項目中,我們主要使用OpenCV進行圖像數據的處理,比如將圖像讀入數組,并重新形成我們需要的尺寸。
改進圖像訓練結果的一個常見方法是以隨機方式變形,裁剪或增亮訓練輸入,這具有擴展訓練數據的有效大小的優點,而這歸功于相同圖像的所有可能的變化,并且傾向于幫助網絡學習應對在分類器的現實使用中將發生的所有失真問題。
詳情請參閱鏈接:https://github.com/aleju/imgaug
評估
第一種方法:
第一部分:預處理數據集,并用sklearn應用KNN、SVM和BP神經網絡。
在程序中有很多參數可以調整:在image_to_feature_vector函數中,我們設置的尺寸是128x128,我們之前也嘗試過像8x8,64x64,256x256這樣的大小。從而我們發現圖像尺寸越大,精度越好。但是,大的圖像尺寸也會增加執行時間和內存消耗。所以我們終于決定圖像尺寸為128x128,因為它不是太大,但同時也可以保證精度。
在extract_color_histogram函數中,我們將每個通道的bin數設置為32,32,32。像上一個函數一樣,我們也嘗試了8,8,8和64,64,64,并且更高的數字可以產生更高的結果,但同時也伴隨著更高的執行時間。所以我們認為32,32,32是最合適的。
而至于數據集,我們嘗試了3種數據集。第一個是具有400個圖像,2個標簽的子數據集。第二個是具有1000個圖像,5個標簽的子數據集。最后一個是具有1997個圖像,10個標簽的整個數據集。并且我們將不同的數據集解析為程序中的參數。
在KNeighborsClassifier中,我們只更改了鄰居數,并將結果存儲為每個數據集的最佳K。然后將我們設置的所有其他參數初始為默認值。
在MLPClassifier中,我們設置了一個含有50個神經元的隱藏層。我們測試了多個隱藏層,但最終結果似乎沒有什么明顯的變化。最大迭代時間為1000,容差為1e-4,以確保其收斂。并將L2懲罰參數α設置為默認值,隨機狀態為1,求解器為“sgd”,學習速率為0.1。
在SVC中,最大迭代時間為1000,類的權重值為“平衡”。
我們的程序的運行時間不是很長,從2個標簽數據集到10個標簽數據集需要大約3到5分鐘。
第二種方法:
用TensorFlow構建CNN。
計算模型的梯度是需要很長時間的,因為這個模型使用的是大型數據集的整體。因此,我們在優化器的每次迭代中僅僅使用少量的圖像。批量大小通常為32或64。數據集分為包含1600張圖像的訓練集,包含400張圖像的驗證集和包含300張圖像的測試集。
有很多參數是可以進行調整的。
首先是學習率。只要它足夠小,可以收斂和足夠大得不會使程序太慢,一個好的學習率還是很容易找到的。我們選擇了1×10 ^ -4。
第二個是我們向網絡提供的圖像的大小。我們嘗試了64 * 64和128 * 128。事實證明,圖像越大,我們得到的準確性越高,但代價是運行時間也相應地增加。
然后是層和它們的形狀。但實際上有太多的參數可以調整,所以想要找到這些參數的最佳值是一件非常困難的工作。
根據網上的許多資源,我們了解到,建立網絡的參數的選擇幾乎都取決于經驗。
起初我們試圖建立一個相對復雜的網絡,其參數如下所示:
我們使用3個卷積層和2個完全連接的層,而這些都是相對復雜的。
但是,結果是——過度擬合。只有經過一千次迭代,我們的程序才能獲得100%的訓練精度,而只有30%的測試精度。起初我很困惑為什么我們會得到一個過度擬合的結果,并且我試圖隨機調整參數,但是結果卻始終沒有變好。幾天后,我碰巧看到一篇文章,談到中國研究人員進行的一個深入學習項目(https://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a)。他們指出,他們進行的研究是有問題的。“一個技術性的問題是,想要訓練和測試像AlexNet這樣的CNN,而結果不會過度擬合,僅僅使用不到2000個例子是不足以做到的。”所以,這個時候我才意識到,首先我們的數據集實際上是很小的,其次就是我們的網絡太復雜了。
要記得我們的數據集是剛好包含2000張圖像。
然后我嘗試減少內核的數量層和大小。我嘗試了很多參數,下圖就是我們使用的最終結構。
我們只使用2個小形狀的卷積層和2個完全連接的層。可結果并不是很理想,4000次迭代后得到的結果仍然是過度擬合,但是測試結果比以前好了10%。
我們仍然在尋找一種處理方法,但是顯而易見的原因是我們的數據集不足,而我們沒有足夠的時間進行更好的改進。
最終結果就是,經過5000次迭代之后,我們大概達到了43%的精度,而運行時間卻超過半個小時。
PS:實際上,由于這個結果,我們感到有些不安。 所以我們發現了另一個標準的數據集—CIFAR-10(https://www.cs.toronto.edu/~kriz/cifar.html)。
CIFAR-10數據集由10個類別的60000個32x32彩色圖像組成,每個類別有6000張圖像。里面含有50000個訓練圖像和10000個測試圖像。
我們使用上面構造的相同網絡,經過10小時的訓練,我們在測試集上得到了78%的準確度。
第三種方法:
重新訓練Inception V3,與此相同,我們隨機選擇幾個圖像進行訓練,并選擇另一批圖像進行驗證。
有很多參數是可以進行調整的。
首先是訓練步驟,默認值是4000,如果我們可以早些得到一個合理的結果,我們嘗試更多或嘗試一個較小的。
學習率是控制訓練過程中最后一層更新的大小的。直觀地說,如果越小,那么學習將需要更長的時間,但最終可以幫助提高整體精度。**train batch**size會在一個訓練步驟中控制檢查了的圖像的數量,并且由于學習率是應用到每個批次中的,所以如果你想要讓更大的批次來獲得相同的整體效果的話,我們將需要減少它們的數量。
因為深入學習任務繁重,運行時間通常相對較長,所以我們不希望經過數小時的訓練之后得知,我們的模式實際上是很糟糕的。因此我們經常檢驗驗證的準確性。這樣我們也可以避免過度擬合。通過分割可以將80%的圖像放入主要訓練集中,保持10%作為訓練期間的驗證,頻繁運行,然后將最終10%的圖像用作測試集,以預測分類器在現實世界的表現。
結果
第一種方法:預處理數據集,并用sklearn來運行KNN、SVM和BP神經網絡。
結果如下圖所示。因為SVM的結果非常差,甚至低于隨機猜測,所以我們沒有提供其運行結果。
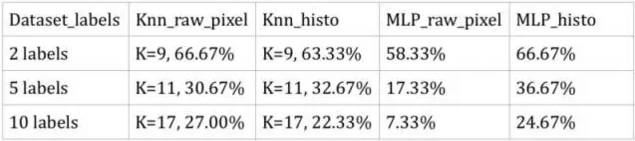
從結果我們可以看出:
在k-NN中,原始像素精度和直方圖精度相對相同。在含有5個標簽的子數據集中,直方圖精度比原始像素高出那么一點,但是在所有原始像素中,原始像素顯示出更好的結果。
在神經網絡MLP分類器中,原始像素精度遠低于直方圖精度。而對于整個數據集(含有10個標簽)來說,原始像素精度甚至低于隨機猜測。
所有這兩種sklearn方法都沒有給出非常好的性能,在整個數據集(含有10個標簽的數據集)中識別正確類別的準確度只有約24%。這些結果表明,使用sklearn方法進行圖像識別的效果不夠好。他們在具有多種類別的復雜圖像的分類中并不具備良好的性能。但是,與隨機猜測相比,他們確實做了一些改進,但這還遠遠不夠。
基于此結果,我們發現為了提高準確性,必須采用一些深度學習的方法。
第二種方法:使用TensorFlow構建如上所述的CNN,由于過度擬合,我們無法獲得良好的效果。
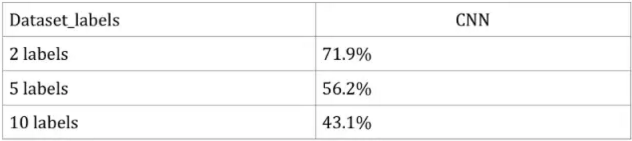
訓練通常需要半小時的時間來進行,但是由于結果過度擬合,我們認為這個運行時間并不重要。與方法1進行比較,我們可以看到:雖然CNN的結果過度擬合,但我們仍然會得到一個比方法1更好的結果。
第三種方法:重新訓練 Inception V3。
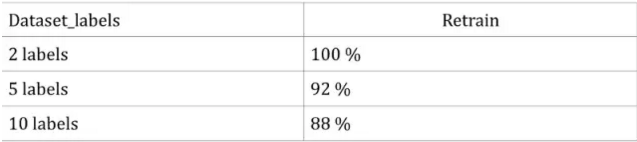
整個訓練進度不超過10分鐘。而我們可以取得非常好的成績。基于此,我們實際上可以看到深度學習和遷移學習的巨大能量。
演示:
目標
基于上述的比較,我們可以得出這樣的結論:
KNN、SVM和BP神經網絡是不能夠很好地完成諸如圖像分類這樣的特定任務的。
雖然我們在CNN部分得到的結果過度擬合,但仍然比在課堂中學到的處理圖像分類問題的其他方法要好得多。
遷移學習在圖像分類問題上具有非常高的效率。無需GPU即可在短時間內準確快捷地完成訓練。即使你有一個小的數據集,它也可以很好地防止過度擬合。
我們學到了一些非常重要的圖像分類任務經驗。這樣的任務與我們上課時所做的其他任務完全不同。數據集相對較大而不稀疏,網絡復雜,因此如果不使用GPU,運行時間會相當長。
裁剪或調整圖像大小使其更小。
隨機選擇一個小批量進行每次迭代訓練。
在驗證集中隨機選擇一個小批量進行驗證,在訓練過程中經常報告驗證的得分情況。
嘗試使用圖像增強將一組輸入圖像轉換為一組新的,更大的,略有更改的圖像。
對于圖像分類任務,我們需要一個比200 x 10的更大的數據集,CIFAR10數據集包含6萬張圖像。
更復雜的網絡需要更多的數據集來進行訓練。
注意過度擬合。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100766 -
圖像分類
+關注
關注
0文章
90瀏覽量
11918 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
原文標題:計算機視覺怎么給圖像分類?KNN、SVM、BP神經網絡、CNN、遷移學習供你選(附開源代碼)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
上海 武漢 深圳招聘:圖像算法 電機控制算法 ADAS算法 咨詢:微信473421885
十速單片機學習歸納總結(五):呼吸燈實驗 精選資料分享
視頻圖像動態跟蹤算法的設計與實現
一種多分類的AdaBoost算法
一種旋正圖像使用中心點進行指紋分類的方法

實例:如何建立一個線性分類器并進行優化
利用Winpcap實現網絡流媒體識別算法并對其性能進行分析和驗證

如何使用壓縮傳感和LDPC碼進行圖像水印的算法研究分析






 工商網監
工商網監
評論