 一種基于少樣本目標類別圖像的圖像翻譯模型
一種基于少樣本目標類別圖像的圖像翻譯模型
【導讀】在已有的圖像翻譯研究中,模型需要使用大量的多類別圖像數據,在一定程度上限制了模型的具體應用。本文提出了一種基于少樣本目標類別圖像的圖像翻譯模型,該模型在翻譯準確度、內容保留程度、圖像真實度和分布匹配度四個指標上都超越了現有模型的效果。
摘要
無監督的圖像翻譯方法通過在不同的非結構化圖像數據集上進行學習,將指定類別的圖像轉換為另一類別的圖像。現有方法雖然取得了一定進展,但在模型訓練期間需要大量的源類別和目標類別的圖像,限制了這類方法的實際應用。
本文通過將一個新的神經網絡架構和對抗學習相結合,提出了一種少樣本的無監督圖像翻譯算法。該模型能夠使用少量樣本圖像,針對新出現的圖像類別進行圖片生成。作者將該模型與幾種現有方法進行了比較,結果表明,這種基于少樣本的無監督圖像翻譯算法非常有效。該論文的代碼已開源,相關項目地址如下:
https://nvlabs.github.io/FUNIT
簡介
人類非常擅長通過學習、類比推理等方法,將現有的知識泛化推廣到一些未見過的問題上。例如,即使對于沒見過老虎的人來說,當看到一只站立的老虎,他也能根據對其他動物的觀察經驗,聯想到老虎躺著的樣子。近來無監督的圖像翻譯研究在不同圖像類別間的翻譯中取得了長足的進步,但現有方法依然很難依據先驗知識和少量新類別的樣本圖像,對圖像進行泛化。
當前的圖像翻譯方法需要大量各類別的圖像用于翻譯模型的訓練。針對這些問題,本研究提出一種少樣本無監督圖像翻譯框架(Few-shot UNsupervised Image-to-image Translation, FUNIT),旨在只利用少量的目標類圖像,通過學習到的圖像翻譯模型,將源圖像類別圖像范圍為到目標類別的圖像。
該模型的假設如下:人類基于少樣本的生成能力來源于過去的視覺知識,且在之前看過的不同種類的物體越多,該泛化生成能力越強。基于此,本研究使用了一個包含多種類別圖像的數據集訓練FUNIT模型,用來模擬過去所學習的多類別視覺知識。模型的目標為,只利用目標類別的少量樣本圖像,實現從源類別到目標類別的圖像翻譯任務。
研究假設,通過在訓練中學習從少量新類別圖像中提取該圖像類別的外觀模式,模型能夠學習一個通用的外觀模式提取器,并將該模式應用于未見過的類別圖像實現圖像翻譯。本文的實驗數據證明,訓練集類別數的增加對于少樣本圖像翻譯模型的性能提升是有幫助的。
本文模型結構基于對抗生成網絡(Generative Adversarial Networks, GAN)。作者將 GAN 和新的網絡架構耦合,獲得了較好的實驗效果。通過在不同數據集上的實驗將模型與幾種基線方法進行對比分析,作者對模型的效果進行了驗證,發現在各種性能指標上FUNIT框架的表現都更好。
方法
本文所提出的FUNIT框架旨在基于少量的目標類別圖像,將源類別圖像映射為一些模型未學習過的目標類別的圖像。具體來說,在模型訓練階段,本文所使用的圖像來自一組圖像類別的數據集合(如各種動物類別的圖像集),稱之為源類別,用于訓練多層級無監督的圖像翻譯模型FUNIT。
這里,本文假設在不同類別間不存在處于同一姿態的動物的圖像。在測試時,本文使用少量取自類別的圖像樣本,稱之為目標類別,這一類別在模型訓練時未使用。模型利用這些少量的目標類別圖像樣本,能夠實現從源類別到目標類別的圖像翻譯本文提出的模型主要包括兩部分:一個少樣本圖像翻譯器 G 和一個多任務對抗判別器 D 。
少樣本圖像翻譯器 G
少樣本圖像翻譯器 G 由一個內容編碼器Ex,一個類編碼器Ey和一個解碼器Fx構成。其中內容編碼器由多個 2D 卷積層和多個殘差塊(residual blocks)組成,用于將輸入的內容圖像x映射為內容潛在編碼 zx ,其中 zx 是一個空間特征映射。類編碼器包含多個2D卷積層并對卷積結果取均值。
而解碼器是由多個采用自適應實例正則化方法(AdaIN)的殘差塊和多個卷積層結構組成。對于每個樣本,AdaIN方法對每個通道的樣本激活值進行正則化,以獲得其零均值和單元方差,之后通過一個仿射變換來縮放激活值。
如下圖1所示,該仿射變換具有空間不變性,因此僅可以用于得到全局的外觀特征信息。內容編碼器能夠提取到不隨類別改變的隱層表征信息,而類別編碼器學習特定類別的隱層表征。文本通過AdaIN層將類編碼饋送到解碼器,并使用類別圖像來控制所生成的圖像全局外觀,使用內容圖像決定圖像的局部結構。
圖1 訓練:訓練集數據由各種不同類別圖像構成(源類別),用于訓練一個圖像翻譯模型。部署:展示了所提出的模型基于少量目標類別圖像進行圖像翻譯的表現。FUNIT 中生成器的輸入由兩部分構成:1)內容圖像;2)目標類別圖像集。旨在通過輸入與目標類相似的圖像來實現少樣本圖像翻譯。
不同于現有的圖像翻譯研究中使用的條件圖像生成器,這里G同時采用一張內容圖像x和K個目標類別圖像作為輸入,并生成輸出圖像。假定內容圖像屬于類別cx,而每個K類圖像屬于類別cy。另外,K是個很小的數字,且cx與cy屬于不同類別。如下圖2所示。
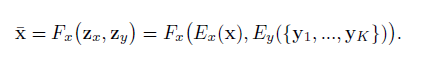
圖2 仿射變換表達式
G將一張輸入的內容圖像映射到屬于類別cy的輸出圖像,二者在圖像結構上有一定的相似度。以S和T分別代表源圖像和目標圖像集,在訓練期間從兩個集合中隨機抽取圖像供G學習,在測試期間G從目標集中抽取一些未見過的類別圖像,并將源圖像集數據類別映射到目標類圖像上。
多任務對抗判別器 D
判別器D的訓練是同時在幾種對抗二分類任務上進行的,其用于判別輸入圖像是源類別的真實圖像還是生成的目標類別圖像。由于這里存在S個源圖像類別,因此D將對應生成S個輸出。當更新D時,根據輸出的結果,相應地懲罰D。當更新G時,只有當輸出結果為假時才選擇懲罰D。經驗上來說,通過這種方法處理后的判別器D能夠在S多分類任務上表現得更好。
此外,FUNIT框架所采用的損失函數如圖3所示:由GAN模型損失、內容圖像重構損失和特征匹配損失構成。

圖3 FUNIT 框架的損失函數表達式
GAN模型損失的計算如圖4:

圖4 GAN 模型的損失表達式
重構損失的數學表達式如圖5:

圖5 重構損失表達式
而圖像特征匹配損失旨在最小化目標類圖像特征與翻譯輸出結果圖像之間特征匹配度,如圖6:

圖6 特征匹配損失表達式
實驗
實驗部分使用如下四種數據集:
動物面孔數據集:從ImageNet數據集中抽取149種卡通動物類別,共含117574張圖像。
鳥類數據集數據集:包含48527張攻擊555種北美鳥類圖像數據。
花卉數據集:102類共8189張包含花的圖像。
事務數據集:來自256種共31395張食物圖像數據。
基準方法分別使用的是StarGAN-Fair-K、 StarGAN-Fair-K 、CycleGAN-Unfair-K、UNIT-Unfair-K和MUNIT-Unfair-K 五種,分別通過翻譯準確率(translation accuracy)、內容保留程度(content preservation)、圖像真實度(photorealism)和 分布匹配度(Distribution matching)四種指標來評估各種方法的性能。
總體結果FUNIT與基準方法在不同數據集的實驗結果如下圖7所示。

圖7各方法的性能對比
可以看到,FUNIT框架在少樣本無監督圖像翻譯任務上所有的性能指標都超過了所有基準方法的表現:在Animal Faces數據集的1-shot和5-shot設置上分別達到82.36和96.05的Top-5測試精度,在North American Birds數據集上分別達到60.19和75.75的Top-5測試精度。圖8對FUNIT-5模型在少樣本圖像翻譯任務上的結果進行了可視化。
圖8 FUNIT-5模型的少樣本無監督圖像翻譯結果的可視化展示。從上到下,分別采用是動物面孔、鳥類、花卉和食物數據集樣本。
可以看到FUNIT模型能夠成功地實現從源圖像到新類別圖像的翻譯。此外,在圖9還提供了一些可視化的對比結果。
圖9少樣本圖像翻譯性能的結果對比
用戶研究本文在Amazon Mechanical Turk (AMT)平臺上通過人類評估法來進一步驗證了圖像翻譯結果的可信度和真實度,結果如圖10所示。

圖10用戶偏好得分結果
用戶偏好得分評估結果表明,相比于其他方法,FUNIT-5模型的翻譯結果與目標類圖像的相似度更高,可靠性更強。
訓練集源類別數量下圖11展示了在動物數據集上,當類別數量發生變化時,FUNIT-5模型的性能表現變化。這里只展示了類別數從69到119以間隔10變化時模型的表現。
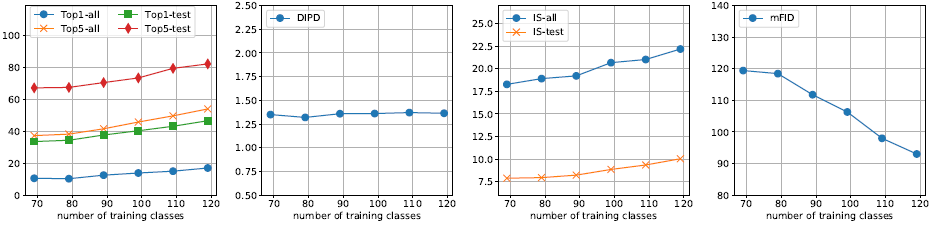
圖11少樣本圖像翻譯性能vs 動物面孔數據集目標類別數
可以看到,FUNIT模型的翻譯性能與目標類別數呈正相關關系,即類別數越多,翻譯性能越好。此外,研究中還進行了參數分析(parameter analysis)、消融實驗(ablation study)、隱層插值(latent interpolation)、失敗樣本分析(failure cases)等評估,具體信息可以查閱原論文的說明。
總結
本文介紹了首個少樣本無監督圖像翻譯框架FUNIT,該模型利用少量的目標類別圖像,實現了從源類別圖像到目標圖像的翻譯,并展示了該框架的性能與目標類別數的關系。FUNIT由三部分構成:1)內容編碼器:用于學習類別不變編碼;2)類編碼器:用于學習特定類別編碼;以及3)解碼器。
總的來說,FUNIT框架能夠實現非常出色的圖像翻譯,但當目標類別與源圖像有顯著差異時,也會存在一些失敗的情況。在失敗樣本中,FUNIT方法僅對源圖像的顏色進行了變更,而改變圖像的其他外觀特征,這也是未來研究的方向。
-
編碼器
+關注
關注
45文章
3643瀏覽量
134525 -
圖像數據
+關注
關注
0文章
52瀏覽量
11280 -
數據集
+關注
關注
4文章
1208瀏覽量
24703
原文標題:四大指標超現有模型!少樣本的無監督圖像翻譯效果逆天| 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種改進的矩不變自動閾值算法
一種基于圖像平移的目標檢測框架
序列圖像運動目標檢測的一種快速算法
一種圖像拼接的運動目標檢測方法
基于強監督部件模型的遙感圖像目標檢測
一種融合圖像紋理結構信息的LDA扣件檢測模型
一種圖像去霧新算法
一種改進的基于LRC-SNN的圖像重建與識別算法

一種基于改進的DCGAN生成SAR圖像的方法







 工商網監
工商網監
評論