 AAAI 2019 Gaussian Transformer 一種自然語言推理方法
AAAI 2019 Gaussian Transformer 一種自然語言推理方法
自然語言推理 (Natural Language Inference, NLI) 是一個活躍的研究領域,許多基于循環神經網絡(RNNs),卷積神經網絡(CNNs),self-attention 網絡 (SANs) 的模型為此提出。盡管這些模型取得了不錯的表現,但是基于 RNNs 的模型難以并行訓練,基于 CNNs 的模型需要耗費大量的參數,基于 self-attention 的模型弱于捕獲文本中的局部依賴。為了克服這個問題,我們向 self-attention 機制中引入高斯先驗 (Gaussian prior) 來更好的建模句子的局部結構。接著,我們為 NLI 任務提出了一個高效的、不依賴循環或卷積的網絡結構,名為 Gaussian Transformer。它由用于建模局部和全局依賴的編碼模塊,用于收集多步推理的高階交互模塊,以及一個參數輕量的對比模塊組成。實驗結果表明,我們的模型在SNLI 和 MultiNLI 數據集上取得了當時最高的成績,同時大大減少了參數數量和訓練時間。此外,在 HardNLI 數據集上的實驗表明我們的方法較少受到標注的人工痕跡(Annotation artifacts) 影響。
1 引言
1.1 任務簡介
自然語言推理 (Natural Language Inference, NLI) ,又叫文本蘊含識別 (Recognizing Textual Entailment, RTE), 研究的是文本間的語義推理關系, 具體來講, 就是識別兩句話之間的蘊含關系,例如,蘊含、矛盾、中性。形式上是,NLI 是一個本文對分類問題。
1.2 動機
這里簡要介紹一下我們提出 Gaussian Self-attention 的動機。我們觀察到,在句子中,與當前詞的語義關聯比較大的詞往往出現在這個單詞的周圍, 但是普通的 Self-attention, 并沒有有效地體現這一點。如圖1所示,在句子 ”I bought a newbookyesterday with a new friend in New York. ” 中,共出現了三個 ”new”,但對于當前詞 book 來說,只有第一個new 才是有意義的。但是普通的 self-attention(在不使用 position-encoding 的情況下),卻給這三個 ”new” 分配了同樣大小的權重,如圖1(a)所示。我們的想法是,應當鼓勵 self-attention 給鄰近的詞更大的權重,為此,我們 在原始的權重上乘以一個按臨近位置分布的高斯先驗概率,如圖 1(b),改變 self-attention 的權重分布,如圖 1(c),從而更加有效地建模句子的局部結構。
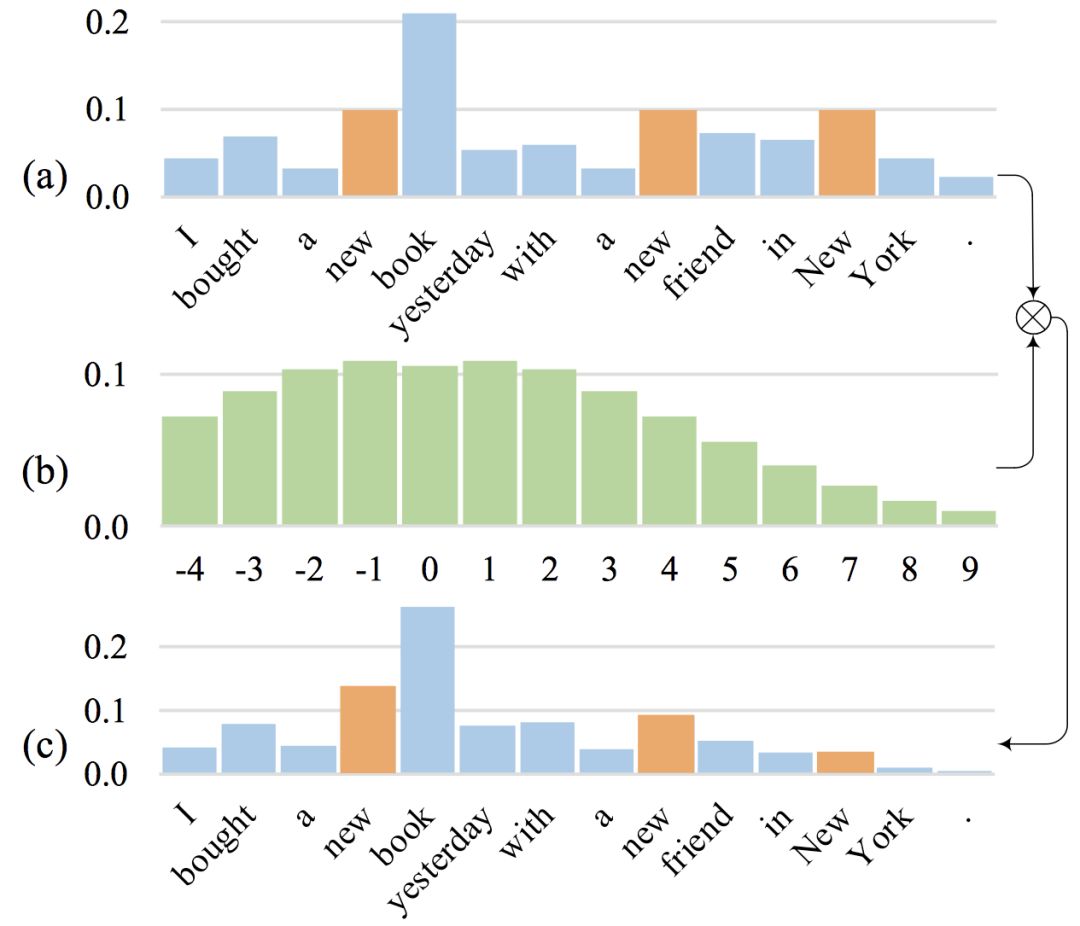
圖 1. Gaussian self-attention 示例
事實上,RNNs 和 CNNs 能夠自然而然地賦予臨近的單詞更大的權重,例如,RNNs 會傾向忘記遠處的單詞,CNNs 會忽略所有不在當前窗口內的單詞。在這篇文章中,我們把 Gaussian self-attention 應用到了 Transformer 網絡上, 并在自然語言推理 (Natural language Inference)這一任務上進行了驗證,實驗表明我們所提出的基于 Gaussian self-attention 的 Gaussian Transformer 效果優于許多較強的基線方法。同時,該方法也保留了原始 Transformer 的并行訓練,參數較少的優點。
2 模型簡介
在實現上, 我們可以通過一系列化簡 (具體細節請參看我們的論文原文), 把 Gaussian self-attention 轉化為 Transformer 中的一次矩陣加法操作, 如圖 2 所示, 從而節省了運算量。 此外,我們發現,與使用原始的 Gaussian 分布作為先驗概率相比,適當的抑制到單詞自身的 attention可以對最終的實驗結果有少許的提升,如圖 3(b) 所示。
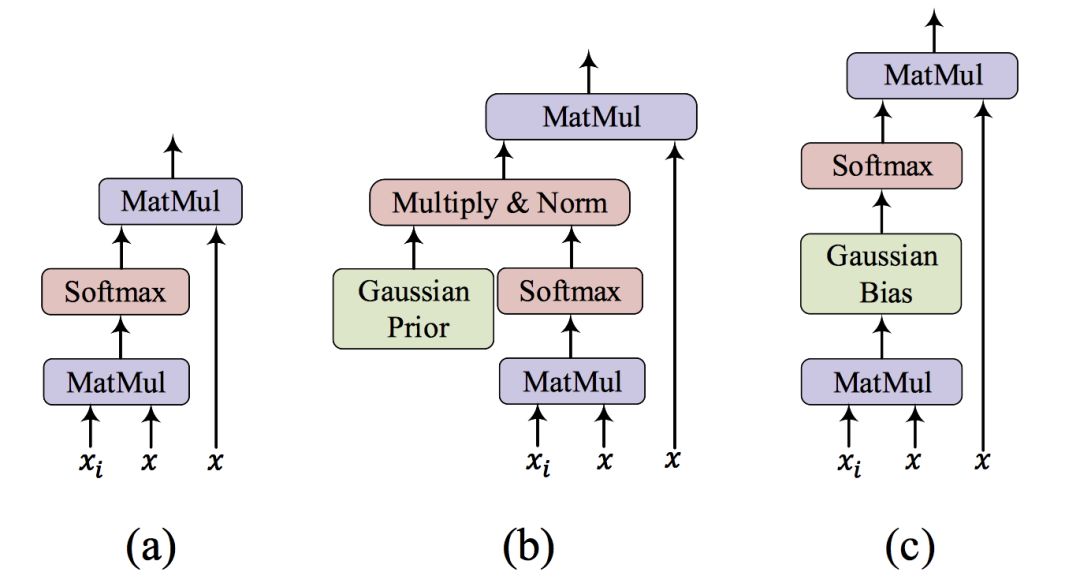
圖 2. Attention 示例: (a) 原始的 dot-product attention;(b)&(c) Gaussian self-attention 的兩種實現
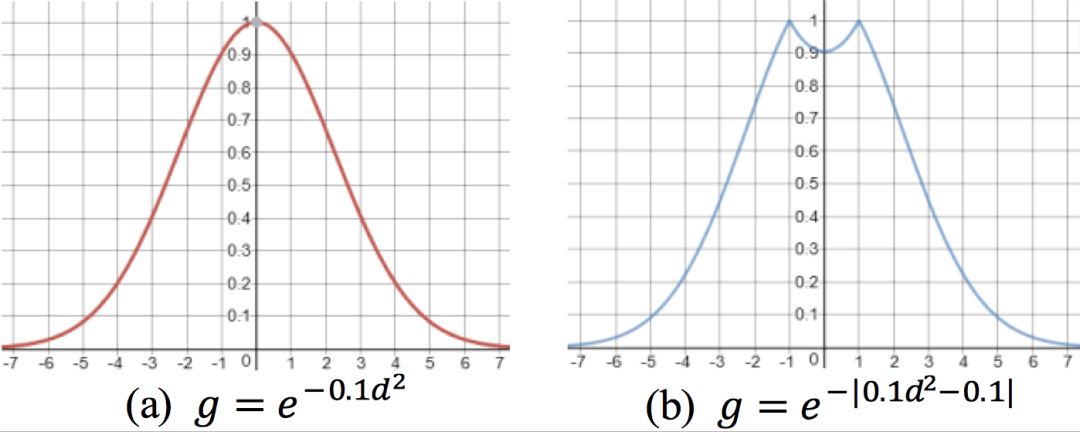
圖 3. 先驗概率示例: (a) 原始的 Gaussian prior;(b) 抑制到自身的 Gaussian prior 變種
圖 4 展示了我們模型的整體框架。 如圖所示, 模型自底向上大致分為四個部分:Embedding模塊、編碼 (Encoding) 模塊、交互 (Interaction) 模塊和對比 (Comparison) 模塊。
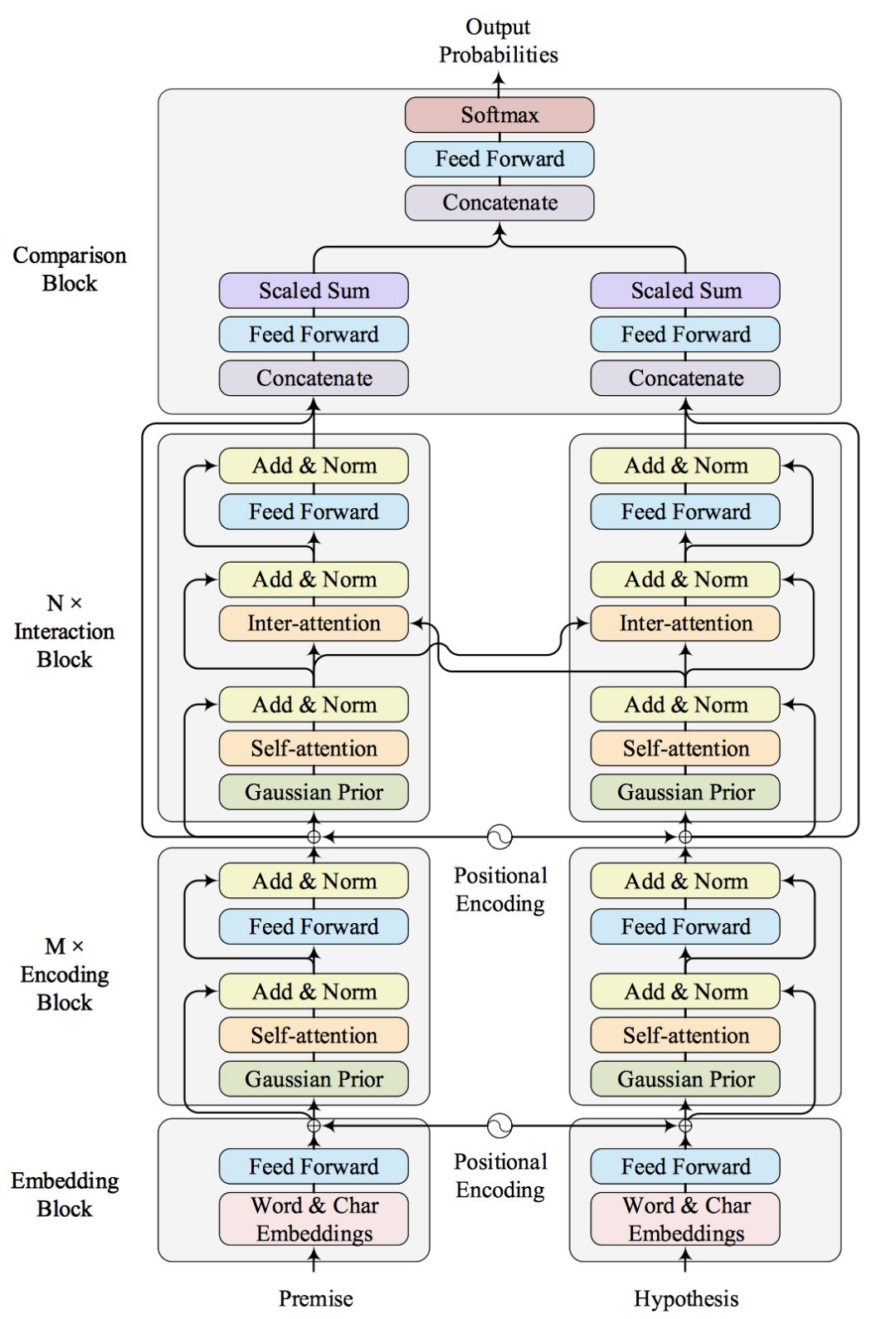
圖 4. Gaussian Transformer 整體框架
Embedding 模塊的作用是把自然語言文本轉化為機器方便處理的向量化表示, 我們使用了單詞和字符級別的 Embedding,以及 Positional Encoding。
Encoding 模塊與原始的 Transformer 的 Encoder 非常類似,只是我們增加了前文引入的 Gaussian self-attention 以便更好的建模句子的局部結構。 但事實上, 句子中也存在長距離依賴, 僅僅建模句子的局部結構是不夠的。為了捕獲句子的全局信息,我們堆疊了 M 個 Encoding 模塊。這種方式類似于多層的 CNNs 網絡,層數較高的卷積層的 receptive ?eld 要大于底層的卷積。
Interaction 模塊用于捕獲兩個句子的交互信息。 這一部分與原始的 Transformer 的 Decoder 部分類似, 區別是我們去掉了 Positional Mask 和解碼的部分。 通過堆疊 N 個 Interaction 模塊,我們可以捕獲高階交互的信息。
Comparison 模塊主要負責對比兩個句子,分別從句子的 Encoding 和 Interaction 兩個角度對比,這里我們沒有使用以前模型中的復雜結構,從而節省了大量的參數。
3 實驗與分析
3.1 實驗結果
首先,我們驗證各個模塊的有效性,如圖 5 所示,采用多層的 Encoding 模塊和多層的 Interaction 模塊的效果要優于使用單層的模型,證明了前面所提到的全局信息和高階交互的有效性。其次,我們想要驗證一下 Gaussian prior 的有效性。如表 1 所示,我們發現 Gaussian prior 及其變種的性能要優于其他諸如 Zipf prior 等方法,也要優于原始的 Transformer。最后, 我們在 SNLI、MultiNLI 和 HardNLI 的測試集上與其他前人的方法進行了橫向比較。如表 2、 3、4、5 和 6 所示,我們的方法在 Accuracy、模型參數量、訓練與預測一輪同樣的數據的時間上都優于基線方法。
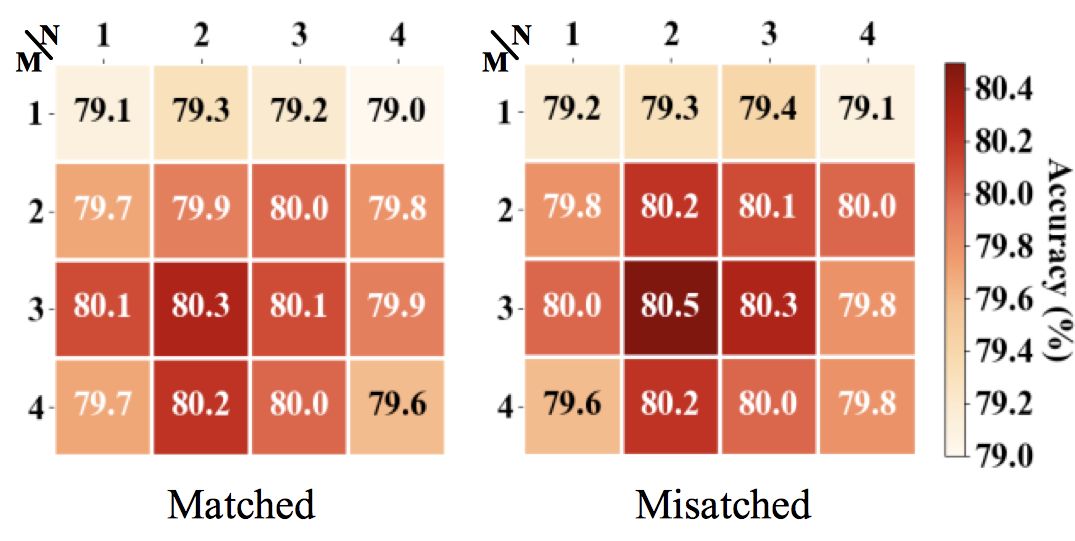
圖 5. MultiNLI 開發集上的 Accuracy 熱圖。
表1.MultiNLI 開發集上各 Gaussian transformer 變種的 Accuracy
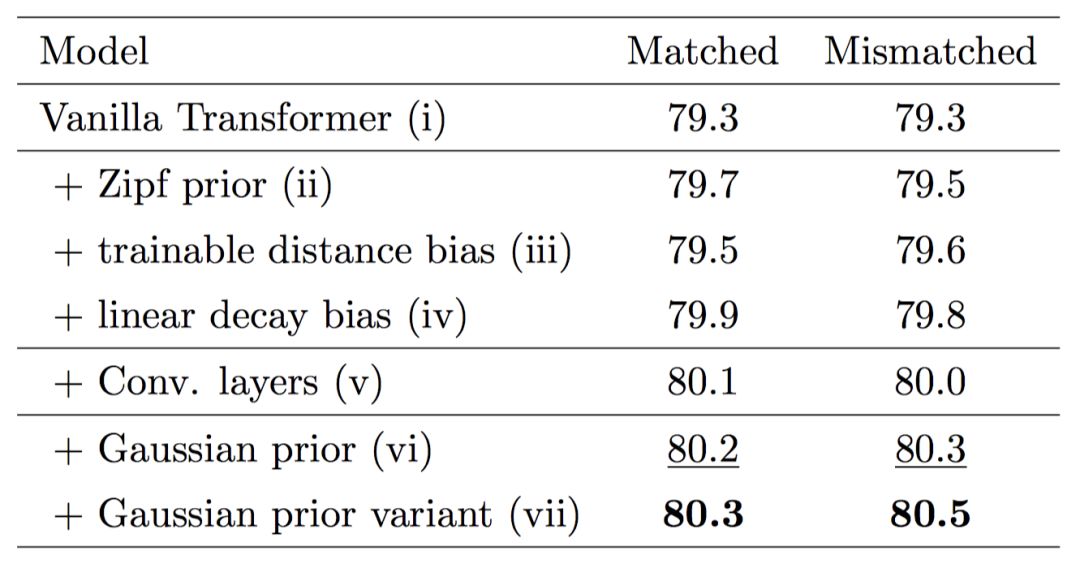
表2.SNLI 測試集上 Gaussian Transformer 與其他模型的橫向比較
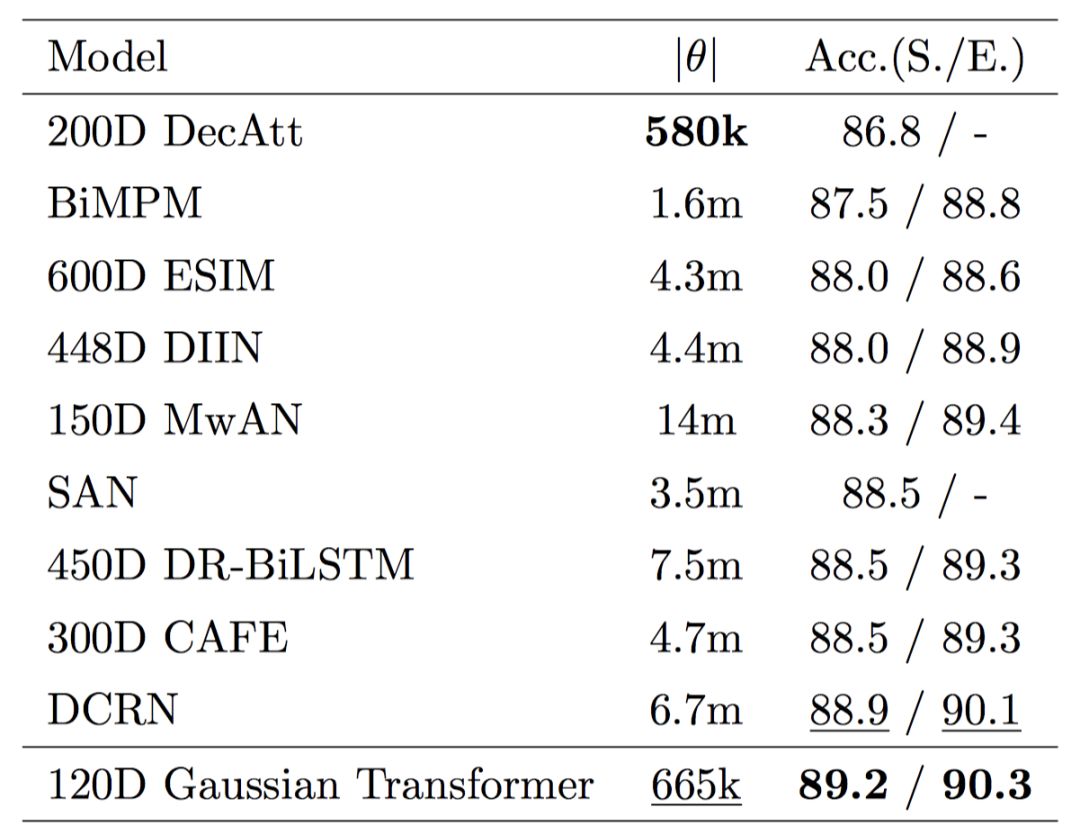
表3.MultiNLI 測試集上 Gaussian Transformer 與其他模型的橫向比較
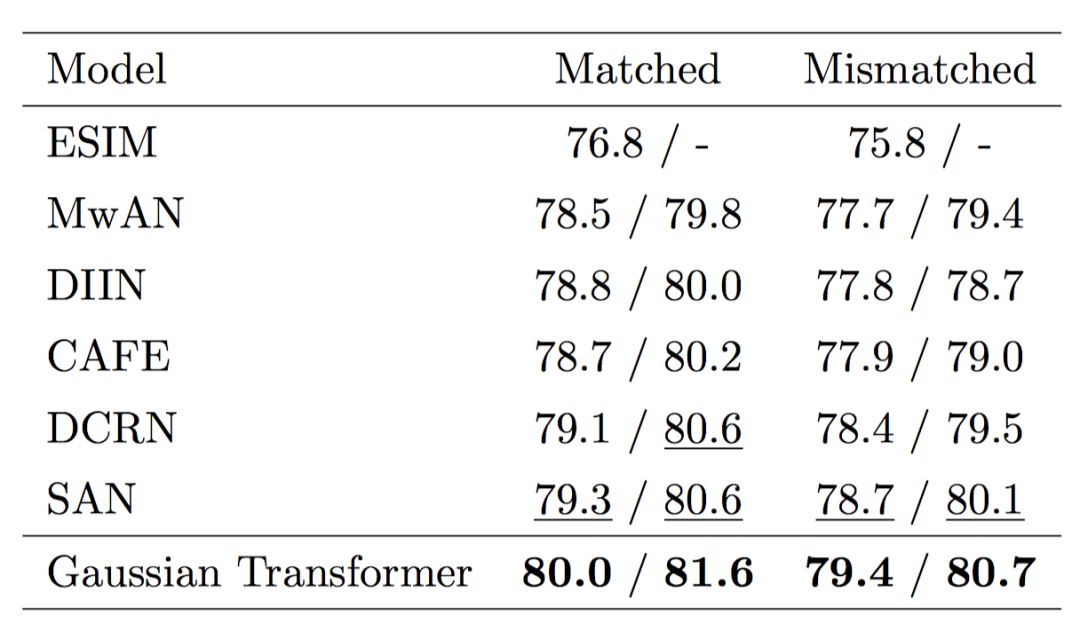
表4.在 SNLI 數據集上訓練或預測一輪所需的時間對比

表5.當引入外部資源時,各個模型的性能比較
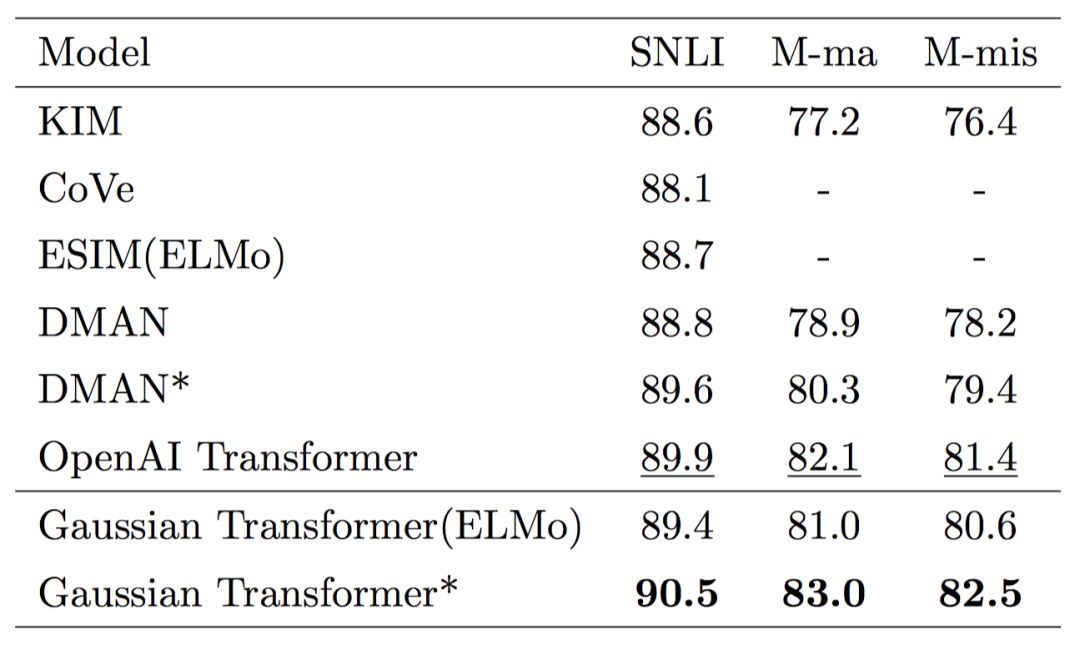
表6.HardNLI 上的對比結果
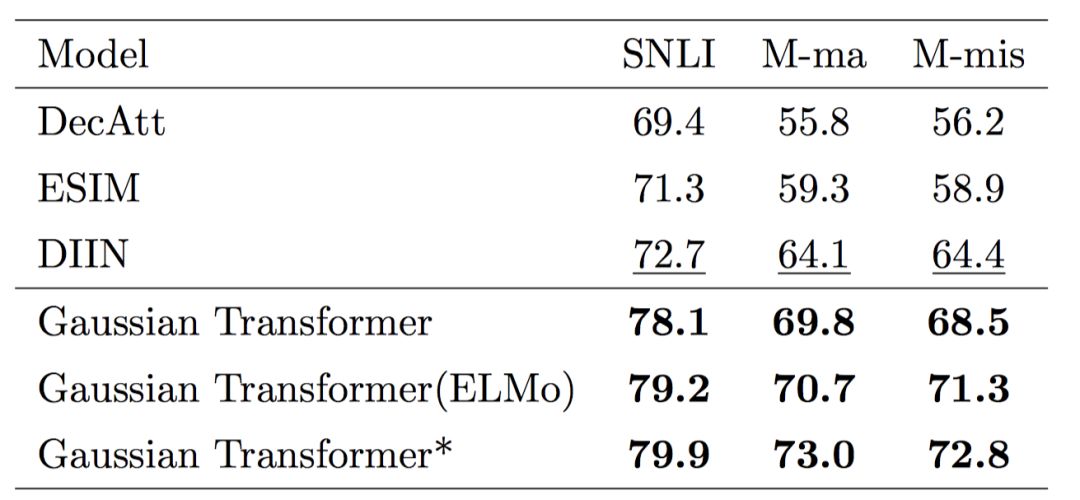
3.2 分析
Q:原始的 Transformer 中已經有了 Positional encoding,已經能夠捕獲單詞的位置信息,為什么還要用 Gaussian Prior ?
A:Positional Encoding 僅僅使模型具有了感知單詞位置的能力;而 Gaussian Prior 告訴模型哪些單詞更重要,即對于當前單詞來說,臨近的單詞比遙遠的單詞更重要,這一先驗來自于人的觀察。
Q:為什么 Gaussian Transformer 在時間和參數量上優于其他的方法?
A:Gaussian Transformer 沒有循環和卷積結構,從而能夠并行計算,同時我們在設計模型時,盡量保持模型簡化,摒棄了以往方法中的復雜結構 (例如,在 Comparison block 中的簡化),使我們的模型更加輕量。
4 結論
針對自然語言推理任務的前人工作的不足,我們提出了基于 Gaussian self-attention 的 Gaussian Transformer 模型。實驗表明所提出的模型在若干自然語言推理任務上取得了State-of-the-Art的實驗結果。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100773
原文標題:AAAI 2019 Gaussian Transformer: 一種自然語言推理的輕量方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度視頻自然語言描述方法
什么是自然語言處理_自然語言處理常用方法舉例說明

一種注意力增強的自然語言推理模型aESIM


PyTorch教程-16.4。自然語言推理和數據集
PyTorch教程-16.5。自然語言推理:使用注意力

自然語言處理的概念和應用 自然語言處理屬于人工智能嗎
一種基于自然語言的軌跡修正方法





 工商網監
工商網監
評論