") Chip Huyen總結(jié)ICLR 2019年的8大趨勢 RNN正在失去研究的光芒
Chip Huyen總結(jié)ICLR 2019年的8大趨勢 RNN正在失去研究的光芒
ICLR 2019過去有幾天了,作為今年上半年表現(xiàn)最為亮眼的人工智能頂會共收到1591篇論文,錄取率為31.7%。
為期4天的會議,共有8個邀請演講主題,內(nèi)容包括:算法公平性的進展、對抗機器學(xué)習(xí)、發(fā)展自主學(xué)習(xí):人工智能,認知科學(xué)和教育技術(shù)、用神經(jīng)模型學(xué)習(xí)自然語言界面等等。
當然,除此之外,還有一大堆的poster。這些都彰顯了ICLR的規(guī)格之高,研究者實力之強大。
透過現(xiàn)象看本質(zhì),一位來自越南的作家和計算機科學(xué)家Chip Huyen總結(jié)了ICLR 2019年的8大趨勢。他表示。會議組織者越來越強調(diào)包容性,在學(xué)術(shù)研究方面RNN正在失去研究的光芒......
1.包容性。
組織者強調(diào)了包容性在人工智能中的重要性,確保前兩次主要會談的開幕詞邀請講話是關(guān)于公平和平等的。
但是還是有一些令人擔憂的統(tǒng)計數(shù)據(jù):
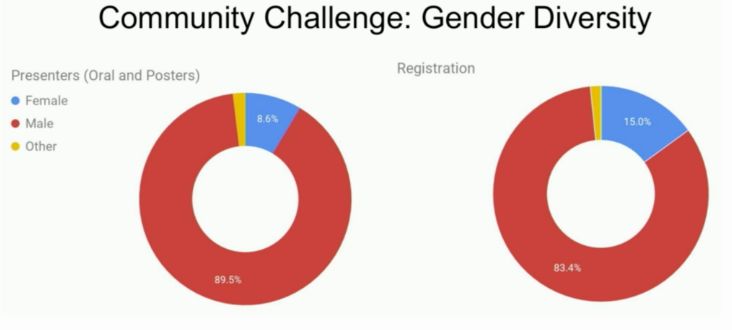
只有8.6%的演講者和15%的參與者是女性。
在所有的LGBTQ+(Lesbian Gay Bisexual Transgender Queer:性別獨角獸群體)研究人員中,有2/3的研究人員并不是專業(yè)的。
所有8位特邀演講者都是白人。
不幸的是,這位AI研究人員仍然感到毫無歉意。雖然其他所有的研討會的訂閱量爆滿,但在Yoshua Bengio出現(xiàn)之前,AI賦能社會(AI for Social Good)研討會一直空無一人。在我在ICLR的眾多談話中,沒有人提到過差異性,除了有一次我大力聲討地問為什么我被邀請參加這場似乎不適合我的技術(shù)活動?一位好朋友說:“有點冒犯的回答是,因為你是一個女人。”
原因之一是這個話題不是“技術(shù)性的”,因此在上面花時間將無助于你在研究領(lǐng)域的職業(yè)發(fā)展。另一個原因是仍然存在一些反對的偏見。有一次,一位朋友告訴我,不要理睬一位在群聊中嘲笑我的人,因為“那人喜歡取笑那些談?wù)撈降群筒町愋缘娜恕!蔽矣幸恍┡笥眩麄儾粫诰W(wǎng)上討論任何關(guān)于差異性的話題,因為他們不想“與這種話題聯(lián)系在一起”。
2.無監(jiān)督表征學(xué)習(xí)與遷移學(xué)習(xí)
無監(jiān)督表示學(xué)習(xí)的一個主要目標是從未標記的數(shù)據(jù)中發(fā)現(xiàn)有用的數(shù)據(jù),以便用于后續(xù)任務(wù)。在自然語言處理中,無監(jiān)督的表示學(xué)習(xí)通常是通過語言建模來完成的。然后將學(xué)習(xí)到的表示用于諸如情感分析、名字分類識別和機器翻譯等任務(wù)。
去年發(fā)表的一些最令人興奮的論文是關(guān)于自然語言處理中的無監(jiān)督學(xué)習(xí)的,首先是ApacheElmo(Peters等人)、DB2ULMFiT(Howard等人)、ApacheOpenAI的GPT(Radford等人)、IBMBert(Devlin等人),當然還有,比較激進的202GPT-2(Radford等人)。
完整的GPT-2模型是在 ICLR演示的,它的表現(xiàn)非常好。您可以輸入幾乎任何提示,它將撰寫文章的其余部分。它可以撰寫B(tài)uzzFeed文章(美國新聞RSS訂閱,類似于今日頭條)、小說、科學(xué)研究論文,甚至是虛構(gòu)單詞的定義。但這聽起來還不完全是人類的感覺。該團隊正在研究GPT-3,會比現(xiàn)在更好。我迫不及待地想看看它能產(chǎn)生什么。
雖然計算機視覺社區(qū)是第一個將遷移學(xué)習(xí)用于工作的社區(qū),但基礎(chǔ)任務(wù)-在ImageNet上訓(xùn)練分類模型-仍然受到監(jiān)督。我不斷從兩個社區(qū)的研究人員那里聽到的一個問題是:“我們?nèi)绾尾拍塬@得為圖像工作的無監(jiān)督學(xué)習(xí)?”
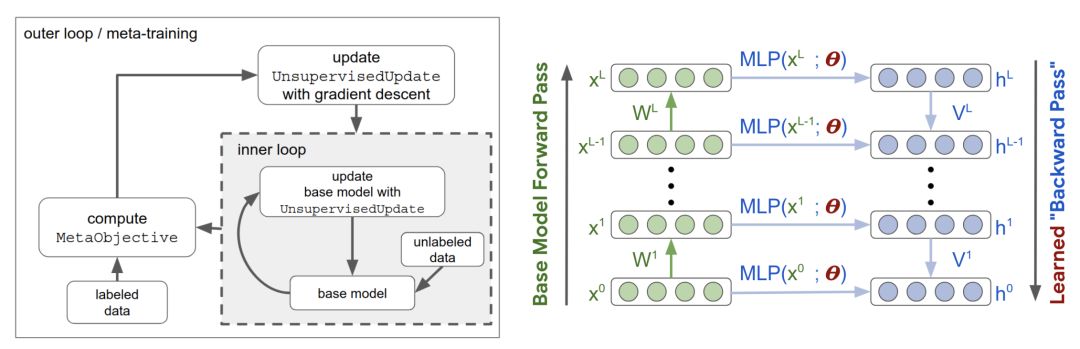
盡管大多數(shù)大牌研究實驗室已經(jīng)在進行這方面的研究,但在ICLR上只有一篇論文:“元學(xué)習(xí)無監(jiān)督學(xué)習(xí)的更新規(guī)則”(Metz et al.)。他們的算法不升級權(quán)值,而是升級學(xué)習(xí)規(guī)則。
然后,在少量的標記樣本上對從學(xué)習(xí)規(guī)則中學(xué)習(xí)到的表示進行調(diào)整,以完成圖像分類任務(wù)。他們找到了學(xué)習(xí)規(guī)則,在MNIST和FashionMNIST數(shù)據(jù)集上達到了70%的準確率。作者不打算發(fā)布代碼,因為“它與計算有關(guān)”。在256個GPU上,外層循環(huán)需要大約100k的訓(xùn)練步驟和200個小時。
我有一種感覺,在不久的將來,我們將看到更多這樣的研究。可用于無監(jiān)督學(xué)習(xí)的一些任務(wù)包括:自動編碼、預(yù)測圖像旋轉(zhuǎn)(Gidaris等人的這篇論文是2018年ICLR的熱門文章),預(yù)測視頻中的下一幀。
3.機器學(xué)習(xí)的“復(fù)古”
機器學(xué)習(xí)中的思想就像時尚:它們繞著一個圈走。在海報展示會上走來走去,就像沿著記憶小路在漫步。即使是備受期待的ICLR辯論最終也是由先驗與結(jié)構(gòu)結(jié)束,這是對Yann LeCun和 Christopher Manning去年討論的回溯,而且與貝葉斯主義者和頻率論者之間的由來的辯論相似。
麻省理工學(xué)院媒體實驗室的語言學(xué)習(xí)和理解項目于2001年終止,但基礎(chǔ)語言學(xué)習(xí)今年卷土重來,兩篇論文都是基于強化學(xué)習(xí):
DOM-Q-Net:基于結(jié)構(gòu)化語言(Jia等人)的RL-一種學(xué)習(xí)通過填充字段和單擊鏈接導(dǎo)航Web的RL算法,給定一個用自然語言表示的目標。
BabyAI:一個研究扎根語言學(xué)習(xí)樣本效率的平臺(Chevalier-Boisveret等人)-這是一個與OpenAI訓(xùn)練兼容的平臺,具有一個手動操作的BOT代理,它模擬人類教師來指導(dǎo)代理學(xué)習(xí)一種合成語言。
AnonReviewer4很好地總結(jié)了我對這兩篇論文的看法:
“…這里提出的方法看起來非常類似于語義解析文獻中,已經(jīng)研究過一段時間的方法。然而,這篇論文只引用了最近深入的RL論文。我認為,讓作者熟悉這些文學(xué)作品將會使他們受益匪淺。我認為語義解析社區(qū)也會從這個…中受益。但這兩個社區(qū)似乎并不經(jīng)常交談,盡管在某些情況下,我們正在解決非常相似的問題。”
確定性有限自動機(DFA)也在今年的深度學(xué)習(xí)領(lǐng)域中占據(jù)了一席之地,它有兩篇論文:
表示形式語言的:有限自動機(FA)與遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的比較(Michalenko等人)。
學(xué)習(xí)遞歸策略網(wǎng)絡(luò)的有限狀態(tài)表示(Koulet等人)
這兩篇論文背后的主要動機是,由于RNN中隱藏狀態(tài)的空間是巨大的,是否有可能將狀態(tài)數(shù)量減少到有限的狀態(tài)?我猜測DFA是否能有效地代表語言的RNN,但我真的很喜歡在訓(xùn)練期間學(xué)習(xí)RNN,然后將其轉(zhuǎn)換為DFA以供參考的想法,正如Koul等人的論文中所介紹的那樣。最終的有限表示只需要3個離散的記憶狀態(tài)和10場觀察的乒乓球游戲。有限狀態(tài)表示也有助于解釋RNN。
4.RNN正在失去研究的光芒
2018年至2019年提交(論文)主題的相對變化表明,RNN的下降幅度最大。這并不奇怪,因為盡管RNN對于序列數(shù)據(jù)是直觀的,但它們有一個巨大的缺點:它們不能被并行化,因此不能利用自2012年以來推動研究進展的最大因素:計算能力。RNN在CV或RL中從未流行過,而對于NLP,它們正被基于注意力的體系結(jié)構(gòu)所取代。
這是不是意味著RNN已經(jīng)over了?不一定。今年的兩個最佳論文獎之一是“有序神經(jīng)元:將樹結(jié)構(gòu)集成到遞歸神經(jīng)網(wǎng)絡(luò)中”。(Shen等人)。除了本文和上面提到的兩篇關(guān)于自動機的文章之外,今年又有9篇關(guān)于RNN的論文被接受,其中大多數(shù)都深入研究了RNN的數(shù)學(xué)基礎(chǔ),而不是發(fā)現(xiàn)新的RNN應(yīng)用方向。
RNN在行業(yè)中仍然非常活躍,特別是對于交易公司等處理時間序列數(shù)據(jù)的公司來說,不幸的是,這些公司通常不會發(fā)布它們的工作成果。即使RNN現(xiàn)在對研究人員沒有吸引力,說不定它可能會在未來卷土重來。
5.GAN持續(xù)火熱
盡管與去年相比GAN的相對增長略有下降, 但論文數(shù)量實際上從去年的約70篇漲到了今年的100多篇。Ian Goodfellow做了一個關(guān)于GAN的特邀報告,更是受其信徒大力推崇。以至于到了最后一天, 他不得不遮住胸前的徽章, 這樣人們才不會因為看到他的名字而激動不已。
第一個海報展示環(huán)節(jié)全是關(guān)于GAN的最新進展,涵蓋了全新的GAN架構(gòu)、舊架構(gòu)的改進、GAN分析、以及從圖像生成到文本生成再到語音合成的GAN應(yīng)用。
衍生出了PATE-GAN, GANSynth, ProbGAN, InstaGAN, RelGAN, MisGAN, SPIGAN, LayoutGAN, KnockoffGAN等等不同的GAN網(wǎng)絡(luò)。總而言之,只要提到GAN我就好像變成了一個文盲,迷失在林林總總的GAN網(wǎng)絡(luò)中。值得一提的是,Andrew Brock沒有把他的大規(guī)模GAN模型叫做giGANtic讓我好生失望。
GAN的海報展示環(huán)節(jié)也揭示了在GAN問題上,ICLR社區(qū)是多么的兩極分化。我聽到有些人小聲嘟囔著“我已經(jīng)等不及看到這些GAN的完蛋啦”,“只要有人提到對抗(adversarial)我的腦瓜仁就疼”。當然,據(jù)我分析,他們也可能只是嫉妒而已。
6.缺乏生物啟發(fā)式深度學(xué)習(xí)
想想之前的輿論充斥著對基因測序和CRISPR 嬰兒(基因編輯嬰兒)的焦慮,而令我感到驚訝的是在ICLR上竟然沒有幾篇關(guān)于生物深度學(xué)習(xí)的論文。事實上,關(guān)于這一主題滿打滿算也就六篇:
兩篇關(guān)于受生物啟發(fā)的架構(gòu)
一篇關(guān)于學(xué)習(xí)設(shè)計 RNA (Runge et al.)
三篇關(guān)于蛋白質(zhì)操縱
關(guān)于基因組學(xué)的論文為零。也沒有關(guān)于這一專題的研討會。盡管這一現(xiàn)象令人遺憾, 但也為對生物學(xué)感興趣的深度學(xué)習(xí)研究人員或?qū)ι疃葘W(xué)習(xí)感興趣的生物學(xué)家提供了巨大的機會。
7.強化學(xué)習(xí)仍舊是最受歡迎的主題。
會議上的報告表明,RL社區(qū)正在從model-free 方法向sample-efficient model-based和meta-learning算法轉(zhuǎn)移。這種轉(zhuǎn)變可能是受TD3和SAC在Mujoco平臺的連續(xù)控制任務(wù),以及R2D2在Atari離散控制任務(wù)上的極高得分所推動的。
基于模型的算法(即從數(shù)據(jù)中學(xué)習(xí)環(huán)境模型,并利用它規(guī)劃或生成更多數(shù)據(jù)的算法)終于能逐漸達到其對應(yīng)的無模型算法的性能,而且只需要原先十分之一至百分之一的經(jīng)驗。
這一優(yōu)勢使他們適合于實際任務(wù)。盡管學(xué)習(xí)得到的單一模擬器很可能存在缺陷,但可以通過更復(fù)雜的動力學(xué)模型,例如集成模擬器,來改善它的缺陷。
另一種將RL應(yīng)用到實際問題的方法是允許模擬器支持任意復(fù)雜的隨機化(arbitrarily complex randomizations):在一組不同的模擬環(huán)境上訓(xùn)練的策略可以將現(xiàn)實世界視為另一個隨機化(randomization),并力求成功
元學(xué)習(xí)(Meta-learning)算法,可實現(xiàn)在多個任務(wù)之間的快速遷移學(xué)習(xí),也已經(jīng)在樣本效率(smaple-efficiency)和性能方面取得了很大的進步(Promp(Rothfuss等人)
這些改進使我們更接近“the ImageNet moment of RL”,即我們可以復(fù)用從其他任務(wù)中學(xué)到的控制策略,而不是每個任務(wù)都從頭開始學(xué)習(xí)。
大部分已被接受的論文,連同整個Structure and Priors in RL研討會,都致力于將一些有關(guān)環(huán)境的知識整合到學(xué)習(xí)算法中。雖然早期的深度RL算法的主要優(yōu)勢之一是通用性(例如,DQN對所有Atari游戲都使用相同的體系結(jié)構(gòu),而無需知道某個特定的游戲),但新的算法表明,結(jié)合先驗知識有助于完成更復(fù)雜的任務(wù)。例如,在Transporter Network(Jakab et al.)中,使用的先驗知識進行更具信息量的結(jié)構(gòu)性探索。
綜上所述,在過去的5年中,RL社區(qū)開發(fā)了各種有效的工具來解決無模型配置下的RL問題。現(xiàn)在是時候提出更具樣本效率(sample-efficient)和可遷移性(transferable)的算法來將RL應(yīng)用于現(xiàn)實世界中的問題了。
趣聞軼事:Sergey Levine可能是這屆ICLR發(fā)表論文最多的人了,一共15篇。。。
8.大部分論文都會很快被人遺忘
當我問一位著名的研究人員,他對今年被接受的論文有何看法時,他笑著說:“大部分論文都會在會議結(jié)束后被遺忘”。在一個和機器學(xué)習(xí)一樣快速發(fā)展的領(lǐng)域里,可能每過幾周甚至幾天曾經(jīng)的最好記錄就會被打破,正因此對于論文還沒發(fā)表就已經(jīng)out了這一現(xiàn)象也就見怪不怪了。例如,根據(jù)Borealis Ai對ICLR 2018的統(tǒng)計,“每八篇里面有七篇論文的結(jié)果,在ICLR會議開始之前就已經(jīng)被超越了。”
在會議期間我經(jīng)常聽到的一個評論是,接受/拒絕決定的隨機性。盡管我不會指明有哪些,但在過去幾年中,確實有一些如今被談?wù)撟疃?引用最多的論文在最初提交給會議的時候被拒了。而許多被接受的論文仍將持續(xù)數(shù)年而不被引用。
作為這個領(lǐng)域的研究者,我經(jīng)常面臨生存危機。不管我有什么想法,似乎別人都已經(jīng)在做了,越來越好,越來越快。如果一篇論文對任何人都毫無用處,那么發(fā)表它又有什么意義呢?救救我吧!!!
結(jié)論
當然還有一些其他的趨勢需要提及:
優(yōu)化和正則化:Adam與SGD之爭仍在繼續(xù)。許多新技術(shù)已經(jīng)被提出了,其中一些非常令人興奮。現(xiàn)在似乎每個實驗室都在開發(fā)自己的優(yōu)化器 - 甚至我們團隊也在開發(fā)新的優(yōu)化器并且很快就會發(fā)布了。
評估指標(evaluation metrics):隨著生成模型越來越流行,我們不可避免地需要制定一些指標來評估生成的結(jié)果。生成的結(jié)構(gòu)化數(shù)據(jù)的度量指標至今還問題重重,而生成的非結(jié)構(gòu)化數(shù)據(jù)(如開放域?qū)υ捄虶AN生成的圖像)的度量更是未知的領(lǐng)域。
-
人工智能
+關(guān)注
關(guān)注
1792文章
47425瀏覽量
238965 -
rnn
+關(guān)注
關(guān)注
0文章
89瀏覽量
6895
原文標題:ICLR 2019八大趨勢:RNN正在失去光芒,強化學(xué)習(xí)仍最受歡迎
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
華為正式發(fā)布2025智能光伏十大趨勢
華為發(fā)布2025智能光伏十大趨勢
2025年全球半導(dǎo)體八大趨勢,萬年芯蓄勢待發(fā)

RNN的應(yīng)用領(lǐng)域及未來發(fā)展趨勢
RNN與LSTM模型的比較分析
RNN的基本原理與實現(xiàn)
LSTM神經(jīng)網(wǎng)絡(luò)與傳統(tǒng)RNN的區(qū)別
rnn是什么神經(jīng)網(wǎng)絡(luò)
rnn神經(jīng)網(wǎng)絡(luò)模型原理
RNN神經(jīng)網(wǎng)絡(luò)適用于什么
rnn神經(jīng)網(wǎng)絡(luò)基本原理
什么是RNN (循環(huán)神經(jīng)網(wǎng)絡(luò))?
2024年影響連接器的五大趨勢
華為發(fā)布2024智能光伏十大趨勢
華為發(fā)布2024數(shù)據(jù)中心能源十大趨勢,引領(lǐng)未來變革






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論