") 谷歌發(fā)布Translatotron語音翻譯系統(tǒng)
谷歌發(fā)布Translatotron語音翻譯系統(tǒng)
今天,谷歌發(fā)布Translatotron語音翻譯系統(tǒng),這是第一個(gè)可以直接將一個(gè)人的聲音從一種語言轉(zhuǎn)換成另一種語言,同時(shí)保持說話人的聲音和節(jié)奏的翻譯模型。
讓說不同語言的人更容易地、直接地相互交流,這是語音到語音的翻譯系統(tǒng)(Speech-to-speech translation)的目的,這樣的系統(tǒng)在過去幾十年里取得了不錯(cuò)的進(jìn)展。
今天,谷歌發(fā)布Translatotron語音翻譯系統(tǒng),這是第一個(gè)可以直接將一個(gè)人的聲音從一種語言轉(zhuǎn)換成另一種語言,同時(shí)保持說話人的聲音和節(jié)奏的翻譯模型。
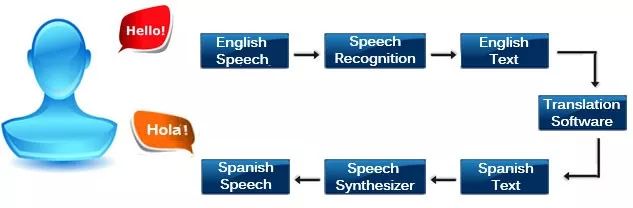
傳統(tǒng)上,語音翻譯系統(tǒng)通常有3個(gè)獨(dú)立的部分:自動語音識別將源語音轉(zhuǎn)錄為文本,機(jī)器翻譯將轉(zhuǎn)錄的文本翻譯成目標(biāo)語言,最后,文本到語音合成(TTS)系統(tǒng)將翻譯文本轉(zhuǎn)換成目標(biāo)語言的語音。
許多商業(yè)語音到語音翻譯的產(chǎn)品都采用這樣的系統(tǒng),包括Google Translate。但是,這類系統(tǒng)依賴于中間文本,準(zhǔn)確率不高,而且效率較低。
谷歌的新工具Translatotron舍棄了將語音翻譯為文本再返回語音的步驟,而是采用端到端的技術(shù),直接將說話者的聲音翻譯成另一種語言。這使它能夠快速地翻譯,但更重要的是,能夠更容易反映說話人的語調(diào)和節(jié)奏。

在論文《基于序列到序列模型的直接語音到語音翻譯》(Direct speech-to-speech translation with a sequence-to-sequence model)中,谷歌的研究人員提出一種基于單個(gè)注意力序列到序列模型的直接語音到語音翻譯的新實(shí)驗(yàn)系統(tǒng),該系統(tǒng)不依賴于中間文本表示。
這個(gè)系統(tǒng)被稱為Translatotron,避免了將任務(wù)劃分為獨(dú)立的階段,比級聯(lián)系統(tǒng)更有優(yōu)勢,包括推理速度快、自然地避免了識別和翻譯之間的復(fù)合錯(cuò)誤,能夠在翻譯后保留原說話者的聲音,以及能夠更好地處理不需要翻譯的單詞(如名稱和專有名詞)。
Translatotron:不依賴中間文本,直接翻譯語音
語音翻譯端到端模型的出現(xiàn)始于2016年,當(dāng)時(shí)研究人員證明了使用單個(gè)序列到序列模型進(jìn)行語音到文本翻譯的可行性。2017年,我們證明了這種端到端模型可以超越級聯(lián)模型(cascade models)。
最近有許多工作進(jìn)一步改進(jìn)了端到端語音到文本翻譯模型的方法,包括同樣來自谷歌的利用弱監(jiān)督數(shù)據(jù)的工作(https://arxiv.org/abs/1811.02050)。
Translatotron更進(jìn)一步,證明了單個(gè)序列到序列模型可以直接將一種語言的語音翻譯成另一種語言的語音,而不需要像級聯(lián)系統(tǒng)那樣依賴于任何一種語言的中間文本表示。
Translatotron基于一個(gè)sequence-to-sequence網(wǎng)絡(luò),它將源聲譜圖(spectrograms)作為輸入,生成目標(biāo)語言翻譯內(nèi)容的聲譜圖。
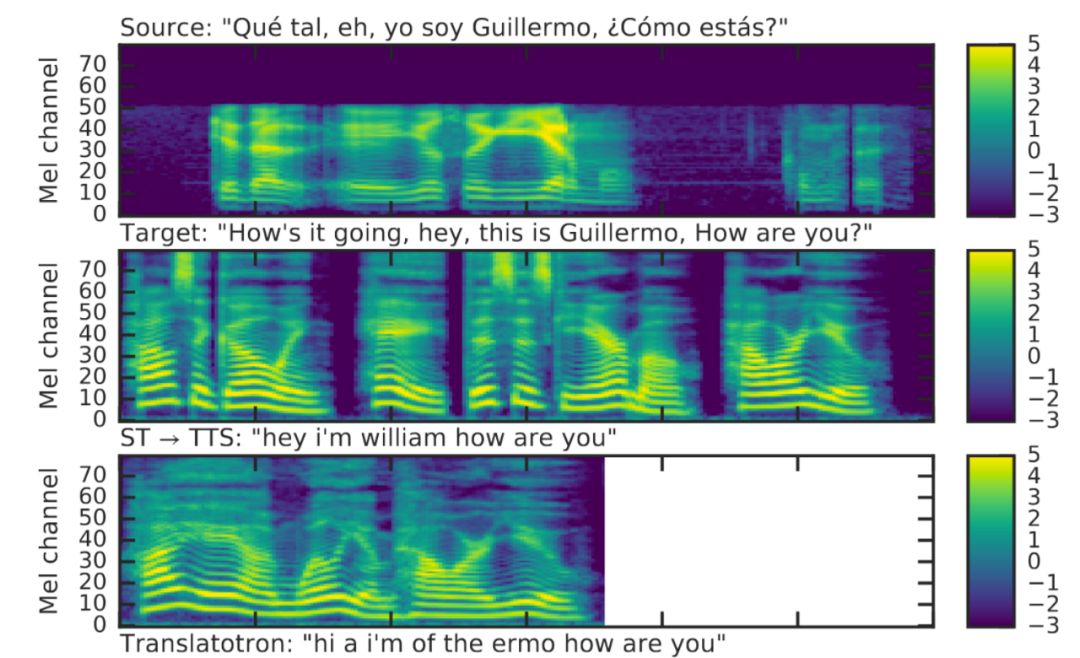
輸入和生成的聲譜圖
此外,Translatotron還使用了另外兩個(gè)單獨(dú)訓(xùn)練的組件:一個(gè)神經(jīng)聲音編碼器(neuralvocoder),可以將輸出聲譜圖轉(zhuǎn)換為時(shí)域波形;另外,還可以選擇使用一個(gè)speaker encoder,用于在合成翻譯語音時(shí)保持源speaker的語音特征。
在訓(xùn)練過程中,序列到序列模型使用一個(gè)多任務(wù)目標(biāo)預(yù)測源和目標(biāo)轉(zhuǎn)錄文本,同時(shí)生成目標(biāo)聲譜圖。然而,推理過程中不需要使用轉(zhuǎn)錄文本或其他中間文本表示。
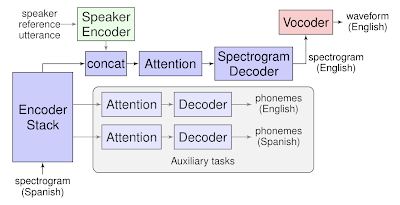
Translatotron的模型結(jié)構(gòu)
性能
谷歌通過測量BLEU分?jǐn)?shù)來驗(yàn)證Translatotron的翻譯質(zhì)量。該分?jǐn)?shù)是通過語音識別系統(tǒng)轉(zhuǎn)錄的文本計(jì)算的。雖然結(jié)果落后于傳統(tǒng)的級聯(lián)系統(tǒng),但已經(jīng)證明了端到端直接語音到語音轉(zhuǎn)換的可行性。
對比Translatotron到基線級聯(lián)方法的直接語音到語音翻譯輸出,在這種情況下,兩個(gè)系統(tǒng)都提供合適的翻譯并使用相同的規(guī)范語音很自然的說話。
保持聲音特征
通過結(jié)合揚(yáng)聲器編碼器網(wǎng)絡(luò),Translatotron還能夠在翻譯的語音中,保留原始說話者的聲音特征,這使得翻譯的語音聽起來更自然,不那么刺耳。
此功能利用了之前針對TTS的演講者驗(yàn)證和演講者調(diào)整的Google研究。揚(yáng)聲器編碼器在演講者驗(yàn)證任務(wù)上進(jìn)行預(yù)訓(xùn)練,學(xué)習(xí)從簡短的示例話語對揚(yáng)聲器特性進(jìn)行編碼。在該編碼上調(diào)節(jié)頻譜圖解碼器,即使內(nèi)容是在不同的語言中,也可以合成具有類似揚(yáng)聲器特性的語音。
谷歌提供了諸多使用示例,如下面的例子,Translatotron將西班牙語對話轉(zhuǎn)換為英語,下面的音頻分別是西班牙語輸入、真人參考翻譯,以及Translatotron的翻譯。
(由于微信智能插入一個(gè)音頻,請點(diǎn)擊原文鏈接聽更多語音。)
Translatotron的翻譯:
更多示例:
https://google-research.github.io/lingvo-lab/translatotron/#conversational
在這個(gè)例子中,Translatotron提供比基線級聯(lián)模型更準(zhǔn)確的平移,同時(shí)能夠保留原始說話者的聲音特征。保留原始說話者聲音的Translatotron輸出訓(xùn)練的數(shù)據(jù),少于使用規(guī)范聲音的數(shù)據(jù),因此它們產(chǎn)生的翻譯略有不同。
結(jié)論
谷歌聲稱,Translatotron是第一個(gè)可以直接將一種語言的語音,翻譯成另一種語言的語音的端到端模型。它還能夠在翻譯的語音中保留源說話者的聲音。谷歌希望這項(xiàng)工作可以作為未來端到端語音轉(zhuǎn)語音翻譯系統(tǒng)研究的起點(diǎn)。
-
編碼器
+關(guān)注
關(guān)注
45文章
3663瀏覽量
135030 -
谷歌
+關(guān)注
關(guān)注
27文章
6183瀏覽量
105785 -
語音
+關(guān)注
關(guān)注
3文章
385瀏覽量
38093
原文標(biāo)題:同聲傳譯被攻陷!谷歌發(fā)布Translatotron直接語音翻譯系統(tǒng)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于語音識別的智能會議系統(tǒng)具備哪些交互功能
谷歌與三星聯(lián)合發(fā)布Android XR操作系統(tǒng)
谷歌正式發(fā)布Gemini 2.0 性能提升近兩倍
谷歌計(jì)劃12月發(fā)布Gemini 2.0模型
阿里國際發(fā)布翻譯大模型Marco
谷歌推出Gemini Live,開啟AI語音聊天新紀(jì)元
車載語音識別系統(tǒng)語音數(shù)據(jù)采集標(biāo)注案例

車載語音識別系統(tǒng)語音數(shù)據(jù)采集標(biāo)注案例
開源項(xiàng)目!設(shè)計(jì)一款智能手語翻譯眼鏡
谷歌發(fā)布多模態(tài)AI新品,加劇AI巨頭競爭
谷歌發(fā)布用于輔助編程的代碼大模型CodeGemma
谷歌發(fā)布全新AI模型Genie
谷歌發(fā)布開源AI大模型Gemma

恩智浦發(fā)布新一代智能語音技術(shù)組合的語音識別引擎





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論