") 如何有效處理大規(guī)模用戶數(shù)據(jù)進(jìn)行廣告推薦?
如何有效處理大規(guī)模用戶數(shù)據(jù)進(jìn)行廣告推薦?
如何有效處理大規(guī)模用戶數(shù)據(jù)進(jìn)行廣告推薦?對于互聯(lián)網(wǎng)企業(yè)的發(fā)展和進(jìn)步至關(guān)重要。這也是為何快手成立西雅圖實驗室并實現(xiàn)新一代GPU廣告模型訓(xùn)練平臺的原因之一。快手新創(chuàng)建的“Persia”GPU廣告模型訓(xùn)練平臺比起傳統(tǒng)CPU訓(xùn)練平臺,單機(jī)訓(xùn)練速度提升可達(dá)幾百倍,在約一小時內(nèi)即可訓(xùn)練百T級別數(shù)據(jù)量,并能通過設(shè)計算法得到相對于傳統(tǒng)訓(xùn)練平臺精度更高的模型,對企業(yè)收入、計算資源的節(jié)約和新模型開發(fā)效率產(chǎn)生直觀的提升。
大模型GPU分布式運(yùn)算存儲
近年來,GPU訓(xùn)練已在圖像識別、文字處理等應(yīng)用上取得巨大成功。GPU訓(xùn)練以其在卷積等數(shù)學(xué)運(yùn)算上的獨(dú)特效率優(yōu)勢,極大地提升了訓(xùn)練機(jī)器學(xué)習(xí)模型,尤其是深度神經(jīng)網(wǎng)絡(luò)的速度。然而,在廣告模型中,由于大量的稀疏樣本存在(比如用戶id),每個id在模型中都會有對應(yīng)的Embedding向量,因此廣告模型常常體積十分巨大,以至于單GPU無法存下模型。目前往往將模型存在內(nèi)存中,由CPU進(jìn)行這部分巨大的Embedding層的運(yùn)算操作。這既限制了訓(xùn)練的速度,又導(dǎo)致實際生產(chǎn)中無法使用比較復(fù)雜的模型——因為使用復(fù)雜模型會導(dǎo)致對給定輸入CPU計算時間過長,無法及時響應(yīng)請求。
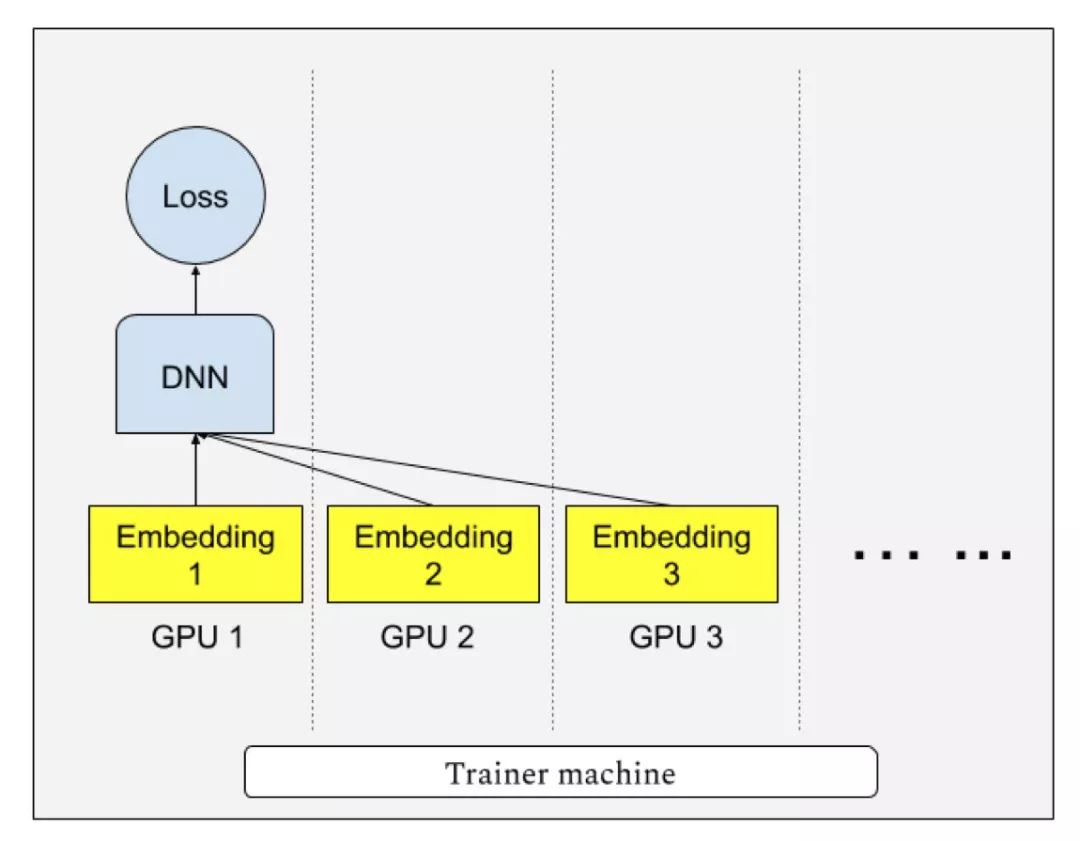
“Persia”系統(tǒng)實現(xiàn)了多GPU分散存儲模型,每個GPU只存儲模型一部分,并進(jìn)行多卡協(xié)作查找Embedding向量訓(xùn)練模型的模式。這既解決了CPU運(yùn)算速度過慢的問題,又解決了單GPU顯存無法存下模型的問題。當(dāng)模型大小可以放入單個GPU時,“Persia”也支持切換為目前在圖像識別等任務(wù)中流行的AllReduce分布訓(xùn)練模式。據(jù)研究人員透露,對于一個8GPU的計算機(jī),單機(jī)數(shù)據(jù)處理速度可達(dá)原CPU平臺單機(jī)的640倍。
由于普遍使用的傳統(tǒng)異步SGD有梯度的延遲問題,若有n臺計算機(jī)參與計算,每臺計算機(jī)的梯度的計算實際上基于n個梯度更新之前的模型。在數(shù)學(xué)上,對于第t步的模型xt,傳統(tǒng)異步SGD則更新為:
xt+1←xt ? learning rate × g(xt?τt),
其中g(shù)(xt?τt) 是訓(xùn)練樣本的損失函數(shù)在τt個更新之前的模型上的 梯度。而τt的大小一般與計算機(jī)數(shù)量成正比:當(dāng)計算機(jī)數(shù)量增多,xt?τt與xt相差就越大,不可避免地導(dǎo)致模型質(zhì)量的降低。“Persia”的訓(xùn)練模式解決了這種梯度延遲的問題,因此模型質(zhì)量也有所提升。
同時,“Persia”訓(xùn)練系統(tǒng)還支持對Embedding運(yùn)算在GPU上進(jìn)行負(fù)載均衡,使用“貪心算法”將不同Embedding均勻分散在不同GPU上,以達(dá)到均勻利用GPU的目的。給定k個 GPU,當(dāng)模型具有m個Embedding層:e1, e2, …, em,對應(yīng)負(fù)載分別為l1, l2, …, lm,“Persia”將會嘗試將Embedding分為k組S1, S2, …, Sk,并分別存放在對應(yīng)GPU上,使得每組∑i∈Sjli, ?j大致相等。
訓(xùn)練數(shù)據(jù)分布式實時處理
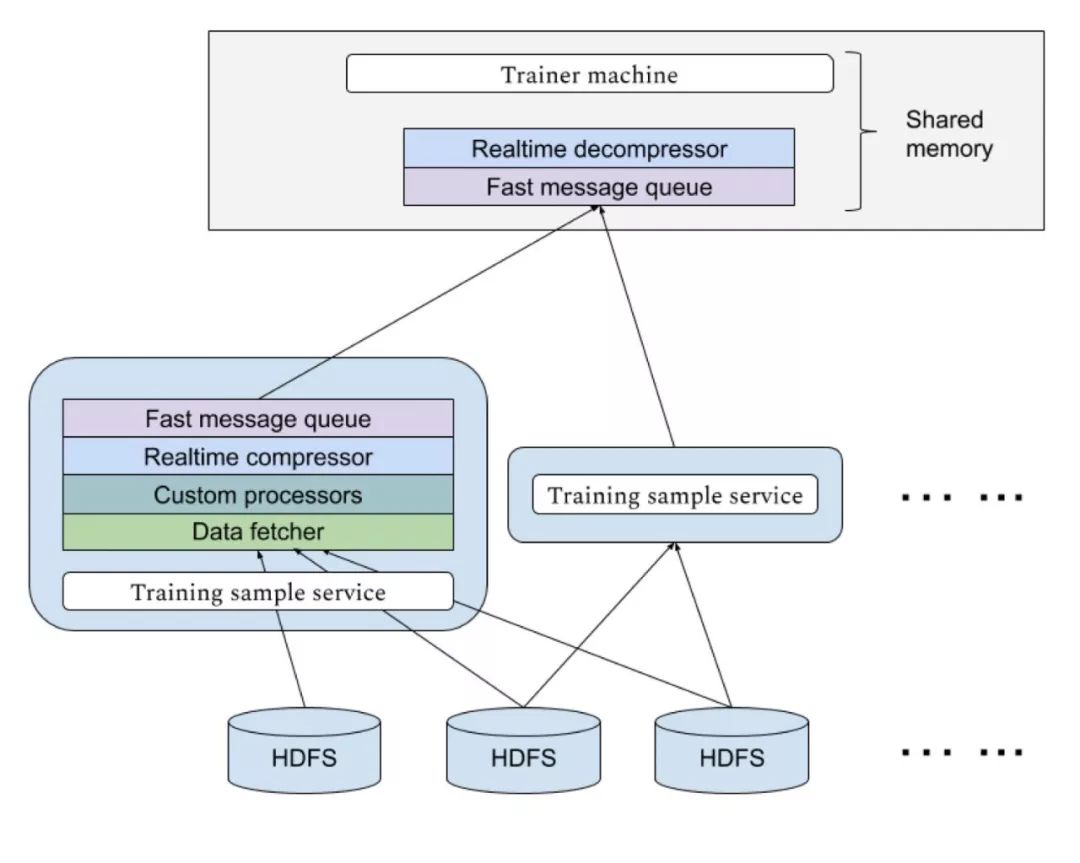
快手“Persia”的高速GPU訓(xùn)練,需要大量數(shù)據(jù)實時輸入到訓(xùn)練機(jī)中,由于不同模型對樣本的需求不同,對于每個新實驗需要的數(shù)據(jù)格式可能也不同。快手“Persia”系統(tǒng)具備基于Hadoop集群的實時數(shù)據(jù)處理系統(tǒng),可以應(yīng)不同實驗需求從HDFS中使用任意多計算機(jī)分布式讀取數(shù)據(jù)進(jìn)行多級個性化處理傳送到訓(xùn)練機(jī)。傳輸使用高效消息隊列,并設(shè)置多級緩存。傳輸過程實時進(jìn)行壓縮以節(jié)約帶寬資源。
未來:分布式多機(jī)訓(xùn)練
未來,快手“Persia”系統(tǒng)即將展開分布式多GPU計算機(jī)訓(xùn)練。有別于成熟的計算機(jī)視覺等任務(wù),由于在廣告任務(wù)中模型大小大為增加,傳統(tǒng)分布式訓(xùn)練方式面臨計算機(jī)之間的同步瓶頸會使訓(xùn)練效率大為降低。“Persia”系統(tǒng)將支持通訊代價更小,并且系統(tǒng)容災(zāi)能力更強(qiáng)的去中心化梯度壓縮訓(xùn)練算法。
快手FeDA智能決策實驗室負(fù)責(zé)人劉霽介紹,該算法結(jié)合新興的異步去中心化訓(xùn)練 (Asynchronous decentralized parallel stochastic gradient descent, ICML 2018)和梯度壓縮補(bǔ)償算法(Doublesqueeze: parallel stochastic gradient descent with double-pass error-compensated compression, ICML 2019), 并有嚴(yán)格理論保證。據(jù)預(yù)計,快手“Persia”系統(tǒng)在多機(jī)情景下在單機(jī)基礎(chǔ)上將有數(shù)倍到數(shù)十倍效率提升。
-
cpu
+關(guān)注
關(guān)注
68文章
10877瀏覽量
212129 -
gpu
+關(guān)注
關(guān)注
28文章
4752瀏覽量
129041 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8424瀏覽量
132761
原文標(biāo)題:單機(jī)訓(xùn)練速度提升高達(dá)640倍,快手開發(fā)GPU廣告模型訓(xùn)練平臺
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論